






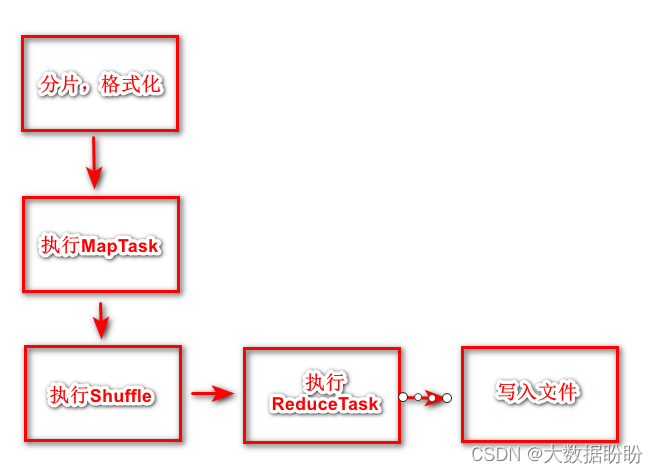
一、分片、格式化数据源
输入 Map 阶段的数据源,必须经过分片和格式化操作。
分片操作:指的是将源文件划分为大小相等的小数据块( Hadoop 2.x 中默认 128MB )
格式化操作:将划分好的分片( split )格式化为键值对<key,value>形式的数据,其中, key 代表偏移量, value 代表每一行内容。
二、执行 MapTask
执行自己编写的map函数,Map过程开始处理,MapTask会接收输入分片,通过不断的调用map方法对数据进行处理,处理完毕后,转换为新的<key,value>键值对输出.
三、执行 Shuffle 过程
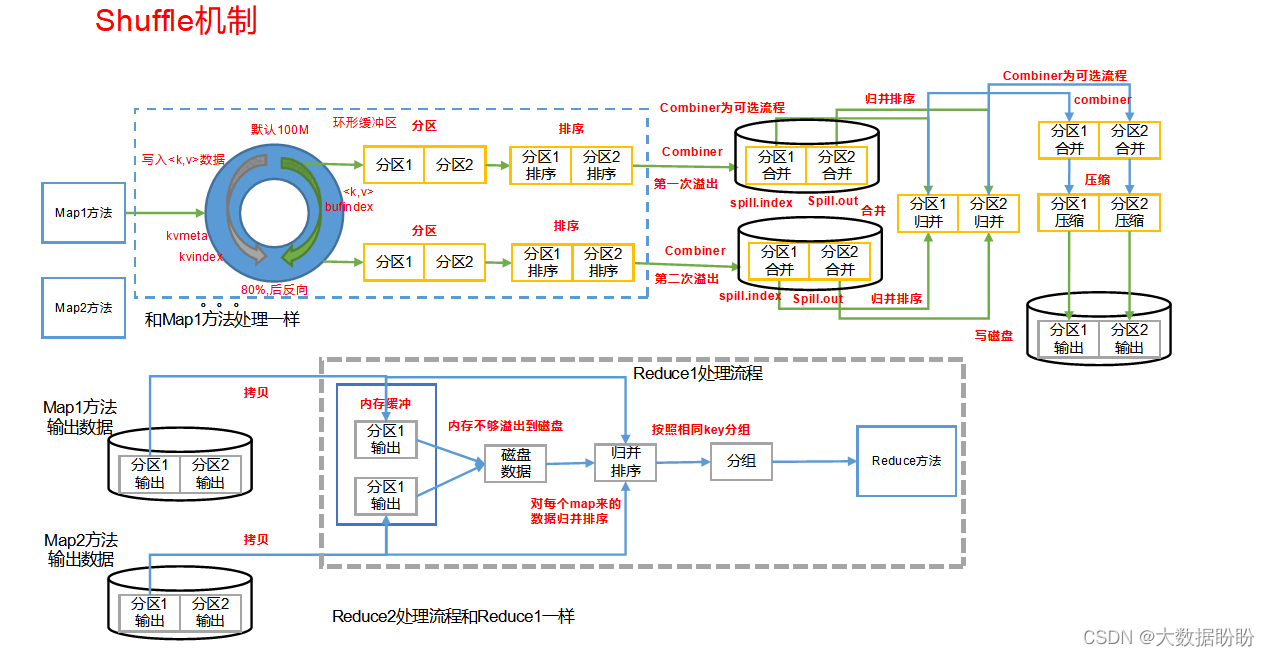
shuffle阶段主要负责将map端生成的数据传递给reduce端,因此shuffle分别在map端的过程和在reduce端的执行过程。
每个 Map 任务都有一个内存缓冲区(缓冲区大小 100MB ),输入的分片( split )数据经过 Map 任务处理后的中间结果会写入内存缓冲区中。
环形缓冲区到达一定阈值(环形缓冲区大小的80%)时,会将缓冲区中的数据溢出本地磁盘文件,这个过程会溢出多个文件,多个溢写文件会被合并成大的溢写文件。
在溢写之前,要进行分区和分区内排序,是快排,按照字典对key进行排序
combiner(归并)可选的 ,对数据进行压缩,进行分区归并排序,分区合并,然后分区压缩
分区输出通过reduce拉取放入内存缓冲区,如果不够写入磁盘,然后归并排序,按key分组到达reduce方法
四、执行 ReduceTask
输入 ReduceTask 的数据流是<key, {value list}>形式,用户可以自定义 reduce()方法进行逻辑处理,最终以<key, value>的形式输出。
五、写入文件
MapReduce 框架会自动把 ReduceTask 生成的<key, value>传入 OutputFormat 的 write 方法,实现文件的写入操作。

















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









