






目录
1.5.2 词汇表、向量化器(Vocabulary, Vectorizer, and DataLoader)
1.5.3 分类模型(The Surname Classifier Model)
1.5.4 训练(The Training Routine)
2.1.1 卷积层(Convolutional Layer)
2.1.4 全连接层(Fully Connected Layer)
2.2.6 膨胀/空洞卷积(Dilated Convolution)
2.3.2 词汇表、向量化器(Vocabulary, Vectorizer, and DataLoader)
2.3.3 分类模型(The SurnameClassifier)
2.3.4 训练(The Training Routine)
实验前言
本篇文章一共进行两个实验,分别是基于MLP实现姓氏分类和基于CNN实现姓氏分类,因篇幅原因,数据集和代码部分未完整给出,有想要完整代码和数据集的读友,可以评论区留言或后台私A信。另外要感谢董老师提供的代码、资料以及指导。
本人水平有限,希望各位读友点点小赞。
实验环境
- Python 3.6.7
- torch框架
一、基于多层感知机(MLP)实现姓氏分类
1.1 MLP原理
多层感知机(Multilayer Perceptron,MLP)是一种基本的人工神经网络模型,通常用于解决分类和回归问题。它由多个神经元层组成,每一层都与下一层全连接,信息通过网络从输入层传递到输出层。每个神经元接收上一层的输出,并将其加权和传递给下一层,最终得到输出结果。
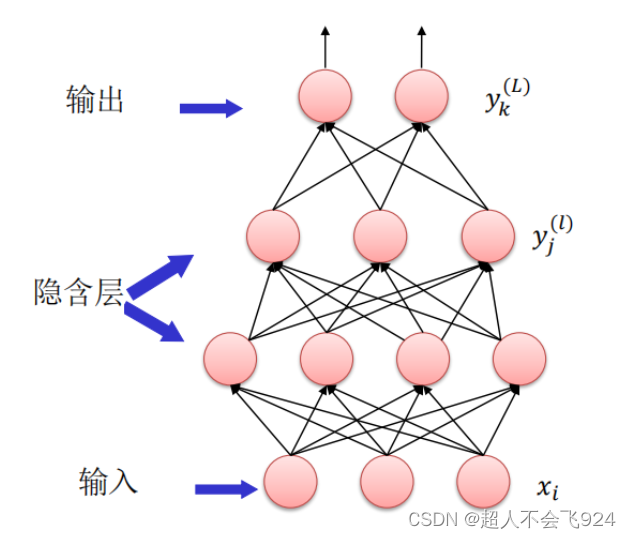
MLP的每个神经元都包含一个激活函数,通常是非线性的,以使得网络可以学习非线性模式。常见的激活函数包括Sigmoid、Tanh等。MLP通过反向传播算法来训练,该算法使用梯度下降来调整网络中的权重,以最小化损失函数。通过反复迭代训练数据,MLP可以逐渐调整其参数,使其能够更好地拟合训练数据,并在未见过的数据上进行泛化。
MLP是一种灵活且强大的模型,可以应用于各种问题领域,如图像识别、自然语言处理、推荐系统等。
1.2 激活函数
1.2.1 激活函数性质
激活函数需要具备以下几点性质:
1. 连续并可导(允许少数点上不可导)的非线性函数。可导的激活函数可以直接利用数值优化的方法来学习网络参数。
2. 激活函数及其导函数要尽可能的简单,有利于提高网络计算效率。
3. 激活函数的导函数的值域要在一个合适的区间内,不能太大也不能太小,否则会影响训练的效率和稳定性。
1.2.2 sigmoid函数
sigmoid 是神经网络历史上最早使用的激活函数之一。它取任何实值并将其压缩在0和1之间。数学上,sigmoid 的表达式如下:
从结果中很容易看出,sigmoid 是一个光滑的、可微的函数。
1.2.3 tanh函数
tanh 激活函数是 sigmoid 在外观上的不同变体,输出范围在(-1, 1)之间,输出值为零中心,这意味着数据的平均值更接近于零,有助于加快收敛速度,tanh的表达式如下:
tanh在特征相差明显时的效果会很好,在循环过程中会不断扩大特征效果。与sigmod的区别是 tanh 是0 的均值,因此在实际应用中tanh会比sigmod更好。
在具体应用中,tanh函数相比于Sigmoid函数往往更具有优越性,这主要是因为Sigmoid函数在输入处于[-1,1]之间时,函数值变化敏感,一旦接近或者超出区间就失去敏感性,处于饱和状态。
1.3 前向传播
MLP的前向传播过程即从输入层到输出层的计算过程。它涉及到权重和偏置的计算、激活函数的应用等。具体步骤如下:
假设网络有层,其中第
层的输入
为,权重矩阵为
,偏置向量为
,激活函数为
,则第
层的输出
计算如下:
1.4 反向传播
反向传播算法是用于训练MLP模型的关键步骤。通过计算梯度来调整权重和偏置,以最小化预测结果与真实结果之间的误差。具体步骤如下:
-
损失计算:首先计算网络的输出与真实标签之间的损失。常用的损失函数包括均方误差(MSE)和交叉熵(Cross-Entropy)。
-
计算输出层的梯度:
- 损失函数对输出层的输入
的梯度:
- 损失函数对输出层的输入
-
计算隐藏层的梯度:
- 损失函数对第
层输入的梯度
- 损失函数对第
其中, 表示元素乘积(Hadamard乘积),
是激活函数的导数。
-
计算梯度:
- 对于权重
和偏置
的梯度:
- 对于权重
-
更新权重和偏置:
- 使用梯度下降法更新参数:
其中,是学习率。
1.5 MLP实现姓氏分类
1.5.1 数据集(The SurnameDataset)
姓氏数据集,它收集了来自18个不同国家的10,000个姓氏,这些姓氏是作者从互联网上不同的姓名来源收集的。该数据集将在本实验的几个示例中重用,并具有一些使其有趣的属性。第一个性质是它是相当不平衡的。排名前三的课程占数据的60%以上:27%是英语,21%是俄语,14%是阿拉伯语。剩下的15个民族的频率也在下降——这也是语言特有的特性。第二个特点是,在国籍和姓氏正字法(拼写)之间有一种有效和直观的关系。有些拼写变体与原籍国联系非常紧密(比如“O ‘Neill”、“Antonopoulos”、“Nagasawa”或“Zhu”)。
为了创建最终的数据集,从一个比课程补充材料中包含的版本处理更少的版本开始,并执行了几个数据集修改操作。第一个目的是减少这种不平衡——原始数据集中70%以上是俄文,这可能是由于抽样偏差或俄文姓氏的增多。为此,我们通过选择标记为俄语的姓氏的随机子集对这个过度代表的类进行子样本。接下来,我们根据国籍对数据集进行分组,并将数据集分为三个部分:70%到训练数据集,15%到验证数据集,最后15%到测试数据集,以便跨这些部分的类标签分布具有可比性。
代码如下:
class SurnameDataset(Dataset):
def __init__(self, surname_df, vectorizer):
"""
参数:
surname_df (pandas.DataFrame): 数据集
vectorizer (SurnameVectorizer): 从数据集实例化的向量化器
"""
self.surname_df = surname_df
self._vectorizer = vectorizer
# 拆分数据集为训练集、验证集和测试集
self.train_df = self.surname_df[self.surname_df.split=='train']
self.train_size = len(self.train_df)
self.val_df = self.surname_df[self.surname_df.split=='val']
self.validation_size = len(self.val_df)
self.test_df = self.surname_df[self.surname_df.split=='test']
self.test_size = len(self.test_df)
self._lookup_dict = {'train': (self.train_df, self.train_size),
'val': (self.val_df, self.validation_size),
'test': (self.test_df, self.test_size)}
self.set_split('train')
# 类别权重
class_counts = surname_df.nationality.value_counts().to_dict()
def sort_key(item):
return self._vectorizer.nationality_vocab.lookup_token(item[0])
sorted_counts = sorted(class_counts.items(), key=sort_key)
frequencies = [count for _, count in sorted_counts]
self.class_weights = 1.0 / torch.tensor(frequencies, dtype=torch.float32)
@classmethod
def load_dataset_and_make_vectorizer(cls, surname_csv):
"""加载数据集并从头创建一个新的向量化器
参数:
surname_csv (str): 数据集的位置
返回:
SurnameDataset的一个实例
"""
surname_df = pd.read_csv(surname_csv)
train_surname_df = surname_df[surname_df.split=='train']
return cls(surname_df, SurnameVectorizer.from_dataframe(train_surname_df))
@classmethod
def load_dataset_and_load_vectorizer(cls, surname_csv, vectorizer_filepath):
"""加载数据集和相应的向量化器。用于向量化器已被缓存以供重用的情况
参数:
surname_csv (str): 数据集的位置
vectorizer_filepath (str): 已保存的向量化器的位置
返回:
SurnameDataset的一个实例
"""
surname_df = pd.read_csv(surname_csv)
vectorizer = cls.load_vectorizer_only(vectorizer_filepath)
return cls(surname_df, vectorizer)
@staticmethod
def load_vectorizer_only(vectorizer_filepath):
"""从文件加载向量化器的静态方法
参数:
vectorizer_filepath (str): 序列化向量化器的位置
返回:
SurnameVectorizer的一个实例
"""
with open(vectorizer_filepath) as fp:
return SurnameVectorizer.from_serializable(json.load(fp))
def save_vectorizer(self, vectorizer_filepath):
"""使用json将向量化器保存到磁盘
参数:
vectorizer_filepath (str): 保存向量化器的位置
"""
with open(vectorizer_filepath, "w") as fp:
json.dump(self._vectorizer.to_serializable(), fp)
def get_vectorizer(self):
""" 返回向量化器 """
return self._vectorizer
def set_split(self, split="train"):
""" 使用数据框中的列选择数据集的拆分 """
self._target_split = split
self._target_df, self._target_size = self._lookup_dict[split]
def __len__(self):
return self._target_size
def __getitem__(self, index):
"""PyTorch数据集的主要入口点方法
参数:
index (int): 数据点的索引
返回:
一个包含数据点的字典:
特征 (x_surname)
标签 (y_nationality)
"""
row = self._target_df.iloc[index]
surname_vector = self._vectorizer.vectorize(row.surname)
nationality_index = self._vectorizer.nationality_vocab.lookup_token(row.nationality)
return {'x_surname': surname_vector,
'y_nationality': nationality_index}
def get_num_batches(self, batch_size):
"""给定批量大小,返回数据集中的批次数量
参数:
batch_size (int)
返回:
数据集中的批次数量
"""
return len(self) // batch_size
def generate_batches(dataset, batch_size, shuffle=True,
drop_last=True, device="cpu"):
"""
一个包装PyTorch DataLoader的生成器函数。它将确保每个张量在正确的设备位置上。
"""
dataloader = DataLoader(dataset=dataset, batch_size=batch_size,
shuffle=shuffle, drop_last=drop_last)
for data_dict in dataloader:
out_data_dict = {}
for name, tensor in data_dict.items():
out_data_dict[name] = data_dict[name].to(device)
yield out_data_dict
1.5.2 词汇表、向量化器(Vocabulary, Vectorizer, and DataLoader)
class Vocabulary(object):
"""用于处理文本并提取词汇以进行映射的类"""
def __init__(self, token_to_idx=None, add_unk=True, unk_token="<UNK>"):
"""
初始化Vocabulary实例。
参数:
token_to_idx (dict): 一个现有的将标记映射到索引的字典
add_unk (bool): 一个指示是否添加UNK标记的标志
unk_token (str): 要添加到词汇表中的UNK标记
"""
if token_to_idx is None:
token_to_idx = {}
self._token_to_idx = token_to_idx
# 创建从索引到标记的反向映射
self._idx_to_token = {idx: token for token, idx in self._token_to_idx.items()}
self._add_unk = add_unk
self._unk_token = unk_token
self.unk_index = -1
# 如果要求,将UNK标记添加到词汇表中
if add_unk:
self.unk_index = self.add_token(unk_token)
def to_serializable(self):
"""返回一个可序列化的字典。"""
return {'token_to_idx': self._token_to_idx,
'add_unk': self._add_unk,
'unk_token': self._unk_token}
@classmethod
def from_serializable(cls, contents):
"""从序列化字典实例化Vocabulary。"""
return cls(**contents)
def add_token(self, token):
"""基于标记更新映射字典。
参数:
token (str): 要添加到Vocabulary中的项
返回:
index (int): 对应于标记的整数
"""
try:
index = self._token_to_idx[token]
except KeyError:
index = len(self._token_to_idx)
self._token_to_idx[token] = index
self._idx_to_token[index] = token
return index
def add_many(self, tokens):
"""将标记列表添加到Vocabulary中。
参数:
tokens (list): 字符串标记列表
返回:
indices (list): 与标记对应的索引列表
"""
return [self.add_token(token) for token in tokens]
def lookup_token(self, token):
"""检索与标记相关联的索引,如果标记不存在,则使用UNK索引。
参数:
token (str): 要查找的标记
返回:
index (int): 与标记相关的索引
注意:
UNK功能需要unk_index >= 0(已添加到Vocabulary中)
"""
if self.unk_index >= 0:
return self._token_to_idx.get(token, self.unk_index)
else:
return self._token_to_idx[token]
def lookup_index(self, index):
"""返回与索引相关联的标记。
参数:
index (int): 要查找的索引
返回:
token (str): 与索引相关的标记
引发:
KeyError: 如果索引不在Vocabulary中
"""
if index not in self._idx_to_token:
raise KeyError("索引(%d)不在Vocabulary中" % index)
return self._idx_to_token[index]
def __str__(self):
"""返回Vocabulary的字符串表示形式。"""
return "<Vocabulary(size=%d)>" % len(self)
def __len__(self):
"""返回Vocabulary中唯一标记的数量。"""
return len(self._token_to_idx)
class SurnameVectorizer(object):
"""协调Vocabularies并将它们应用于实际用途的向量化器"""
def __init__(self, surname_vocab, nationality_vocab):
"""
参数:
surname_vocab (Vocabulary): 将字符映射到整数的词汇表
nationality_vocab (Vocabulary): 将国籍映射到整数的词汇表
"""
self.surname_vocab = surname_vocab
self.nationality_vocab = nationality_vocab
def vectorize(self, surname):
"""
将姓氏向量化为一种折叠的one-hot编码。
参数:
surname (str): 姓氏
返回:
one_hot (np.ndarray): 一个折叠的one-hot编码
"""
vocab = self.surname_vocab
one_hot = np.zeros(len(vocab), dtype=np.float32)
for token in surname:
one_hot[vocab.lookup_token(token)] = 1
return one_hot
@classmethod
def from_dataframe(cls, surname_df):
"""从数据集DataFrame实例化向量化器。
参数:
surname_df (pandas.DataFrame): 姓氏数据集
返回:
SurnameVectorizer的实例
"""
surname_vocab = Vocabulary(unk_token="@")
nationality_vocab = Vocabulary(add_unk=False)
for index, row in surname_df.iterrows():
for letter in row.surname:
surname_vocab.add_token(letter)
nationality_vocab.add_token(row.nationality)
return cls(surname_vocab, nationality_vocab)
@classmethod
def from_serializable(cls, contents):
surname_vocab = Vocabulary.from_serializable(contents['surname_vocab'])
nationality_vocab = Vocabulary.from_serializable(contents['nationality_vocab'])
return cls(surname_vocab=surname_vocab, nationality_vocab=nationality_vocab)
def to_serializable(self):
"""返回一个可序列化的字典。"""
return {'surname_vocab': self.surname_vocab.to_serializable(),
'nationality_vocab': self.nationality_vocab.to_serializable()}
1.5.3 分类模型(The Surname Classifier Model)
第一个线性层将输入向量映射到中间向量,并对该向量应用非线性。第二线性层将中间向量映射到预测向量。在最后一步中,可选地应用softmax操作,以确保输出和为1;这就是所谓的“概率”。它是可选的原因与我们使用的损失函数的数学公式有关——交叉熵损失。我们研究了“损失函数”中的交叉熵损失。回想一下,交叉熵损失对于多类分类是最理想的,但是在训练过程中软最大值的计算不仅浪费而且在很多情况下并不稳定。
代码如下:
import torch.nn as nn
import torch.nn.functional as F
class SurnameClassifier(nn.Module):
"""用于姓氏分类的两层多层感知器"""
def __init__(self, input_dim, hidden_dim, output_dim):
"""
参数:
input_dim (int): 输入向量的大小
hidden_dim (int): 第一个线性层的输出大小
output_dim (int): 第二个线性层的输出大小
"""
super(SurnameClassifier, self).__init__()
self.fc1 = nn.Linear(input_dim, hidden_dim) # 第一个线性层
self.fc2 = nn.Linear(hidden_dim, output_dim) # 第二个线性层
def forward(self, x_in, apply_softmax=False):
"""分类器的前向传播
参数:
x_in (torch.Tensor): 输入数据张量。x_in的形状应为 (batch, input_dim)
apply_softmax (bool): 是否应用softmax激活的标志
如果与交叉熵损失一起使用,应设置为False
返回:
结果张量。张量的形状应为 (batch, output_dim)
"""
intermediate_vector = F.relu(self.fc1(x_in)) # 通过第一个线性层并应用ReLU激活函数
prediction_vector = self.fc2(intermediate_vector) # 通过第二个线性层
if apply_softmax:
prediction_vector = F.softmax(prediction_vector, dim=1) # 如果需要,应用softmax激活函数
return prediction_vector
1.5.4 训练(The Training Routine)
虽然我们使用了不同的模型、数据集和损失函数,但是训练例程是相同的。
部分代码如下:
# 设置参数
args = Namespace(
# 数据和路径信息
surname_csv="data/surnames/surnames_with_splits.csv",
vectorizer_file="vectorizer.json",
model_state_file="model.pth",
save_dir="model_storage/ch4/surname_mlp",
# 模型超参数
hidden_dim=300,
# 训练超参数
seed=1337,
num_epochs=100,
early_stopping_criteria=5,
learning_rate=0.001,
batch_size=64,
# 运行时选项
cuda=False,
reload_from_files=False,
expand_filepaths_to_save_dir=True,
)
# 扩展文件路径
if args.expand_filepaths_to_save_dir:
args.vectorizer_file = os.path.join(args.save_dir, args.vectorizer_file)
args.model_state_file = os.path.join(args.save_dir, args.model_state_file)
print("扩展的文件路径: ")
print("\t{}".format(args.vectorizer_file))
print("\t{}".format(args.model_state_file))
# 检查 CUDA 可用性
if not torch.cuda.is_available():
args.cuda = False
args.device = torch.device("cuda" if args.cuda else "cpu")
print("使用 CUDA: {}".format(args.cuda))
# 设置随机种子以保证可重复性
def set_seed_everywhere(seed, cuda):
torch.manual_seed(seed)
if cuda:
torch.cuda.manual_seed_all(seed)
set_seed_everywhere(args.seed, args.cuda)
# 处理目录
def handle_dirs(dirpath):
if not os.path.exists(dirpath):
os.makedirs(dirpath)
handle_dirs(args.save_dir)训练中最显著的差异与模型中输出的种类和使用的损失函数有关。在这个例子中,输出是一个多类预测向量,可以转换为概率。正如在模型描述中所描述的,这种输出的损失类型仅限于CrossEntropyLoss和NLLLoss。由于它的简化,我们使用了CrossEntropyLoss。
THE TRAINING LOOP
示例显示了使用不同的key从batch_dict中获取数据。除了外观上的差异,训练循环的功能保持不变。利用训练数据,计算模型输出、损失和梯度。然后,使用梯度来更新模型。
scheduler = optim.lr_scheduler.ReduceLROnPlateau(optimizer=optimizer,
mode='min', factor=0.5,
patience=1)
# 初始化训练状态
train_state = make_train_state(args)
epoch_bar = tqdm(desc='training routine', # 迭代轮次
total=args.num_epochs,
position=0)
dataset.set_split('train')
train_bar = tqdm(desc='split=train',
total=dataset.get_num_batches(args.batch_size),
position=1,
leave=True)
dataset.set_split('val')
val_bar = tqdm(desc='split=val',
total=dataset.get_num_batches(args.batch_size),
position=1,
leave=True)
try:
for epoch_index in range(args.num_epochs):
train_state['epoch_index'] = epoch_index
# Iterate over training dataset
# 设置: 批处理生成器, 将损失和准确率设为0, 设置训练模式
dataset.set_split('train')
batch_generator = generate_batches(dataset,
batch_size=args.batch_size,
device=args.device)
running_loss = 0.0
running_acc = 0.0
classifier.train()
for batch_index, batch_dict in enumerate(batch_generator):
# the training routine is these 5 steps:
# --------------------------------------
# 步骤 1. 清零梯度
optimizer.zero_grad()
# 计算输出
y_pred = classifier(batch_dict['x_surname'])
# 计算损失
loss = loss_func(y_pred, batch_dict['y_nationality'])
loss_t = loss.item()
running_loss += (loss_t - running_loss) / (batch_index + 1)
# 计算准确率
loss.backward()
# step 5. use optimizer to take gradient step
optimizer.step()
# -----------------------------------------
# compute the accuracy
acc_t = compute_accuracy(y_pred, batch_dict['y_nationality'])
running_acc += (acc_t - running_acc) / (batch_index + 1)
# update bar
train_bar.set_postfix(loss=running_loss, acc=running_acc,
epoch=epoch_index)
train_bar.update()
train_state['train_loss'].append(running_loss)
train_state['train_acc'].append(running_acc)
# Iterate over val dataset
# setup: batch generator, set loss and acc to 0; set eval mode on
dataset.set_split('val')
batch_generator = generate_batches(dataset,
batch_size=args.batch_size,
device=args.device)
running_loss = 0.
running_acc = 0.
classifier.eval()
for batch_index, batch_dict in enumerate(batch_generator):
# 计算输出
y_pred = classifier(batch_dict['x_surname'])
# 计算损失
loss = loss_func(y_pred, batch_dict['y_nationality'])
loss_t = loss.to("cpu").item()
running_loss += (loss_t - running_loss) / (batch_index + 1)
# 计算准确率
acc_t = compute_accuracy(y_pred, batch_dict['y_nationality'])
running_acc += (acc_t - running_acc) / (batch_index + 1)
val_bar.set_postfix(loss=running_loss, acc=running_acc,
epoch=epoch_index)
val_bar.update()
train_state['val_loss'].append(running_loss)
train_state['val_acc'].append(running_acc)
# 更新训练状态并根据验证损失调整学习率
train_state = update_train_state(args=args, model=classifier,
train_state=train_state)
scheduler.step(train_state['val_loss'][-1])
if train_state['stop_early']:
break
train_bar.n = 0
val_bar.n = 0
epoch_bar.update()
except KeyboardInterrupt:
print("Exiting loop")1.5.5 评估(Evaluation)
为了要了解模型的性能,需要对性能进行定量和定性的度量,现在通过以下代码,打印损失和准确率。
# 加载最佳模型
classifier.load_state_dict(torch.load(train_state['model_filename']))
# 将模型和数据集转移到GPU或CPU
classifier = classifier.to(args.device)
dataset.class_weights = dataset.class_weights.to(args.device)
# 定义损失函数
loss_func = nn.CrossEntropyLoss(dataset.class_weights)
# 设置数据集为测试集并迭代批次计算损失和准确率
dataset.set_split('test')
batch_generator = generate_batches(dataset,
batch_size=args.batch_size,
device=args.device)
running_loss = 0.
running_acc = 0.
classifier.eval()
for batch_index, batch_dict in enumerate(batch_generator):
# 计算输出
y_pred = classifier(batch_dict['x_surname'])
# 计算损失
loss = loss_func(y_pred, batch_dict['y_nationality'])
loss_t = loss.item()
running_loss += (loss_t - running_loss) / (batch_index + 1)
# 计算准确率
acc_t = compute_accuracy(y_pred, batch_dict['y_nationality'])
running_acc += (acc_t - running_acc) / (batch_index + 1)
# 更新训练状态的测试损失和准确率
train_state['test_loss'] = running_loss
train_state['test_acc'] = running_acc
# 打印测试损失和准确率
print("Test loss: {};".format(train_state['test_loss']))
print("Test Accuracy: {}".format(train_state['test_acc'])) 结果如下:
![]()
由结果可知,MLP的准确率为46.69%。
1.5.6 预测(Predict)
代码如下:
def predict_nationality(surname, classifier, vectorizer):
"""预测姓氏的国籍
Args:
surname (str): 要分类的姓氏
classifier (SurnameClassifer): 分类器的实例
vectorizer (SurnameVectorizer): 对应的向量化器
Returns:
包含最可能的国籍及其概率的字典
"""
# 将姓氏向量化
vectorized_surname = vectorizer.vectorize(surname)
vectorized_surname = torch.tensor(vectorized_surname).view(1, -1)
# 使用分类器进行预测,并应用softmax函数
result = classifier(vectorized_surname, apply_softmax=True)
# 获取概率值和索引
probability_values, indices = result.max(dim=1)
index = indices.item()
# 查找国籍
predicted_nationality = vectorizer.nationality_vocab.lookup_index(index)
probability_value = probability_values.item()
return {'nationality': predicted_nationality, 'probability': probability_value}
# 输入要分类的姓氏
new_surname = input("Enter a surname to classify: ")
# 将分类器移到CPU上
classifier = classifier.to("cpu")
# 使用预测函数进行预测
prediction = predict_nationality(new_surname, classifier, vectorizer)
# 打印结果
print("{} -> {} (p={:0.2f})".format(new_surname,
prediction['nationality'],
prediction['probability']))
预测结果如下:
作者小王输入自己的姓氏“王”,由结果可知,预测出最可能的国籍是韩国,预测大概出错了(😫)。
![]()
于是小王这次输入“Wang”,这次应该对了(😘)。预测出最可能的国籍是中国,及其对应的概率值为0.59。
![]()
二、基于卷积神经网络(CNN)实现姓氏分类
卷积神经网络(Convolutional Neural Network,CNN)是一种专门用于处理具有网格结构数据(如图像)的深度学习模型。CNN在计算机视觉领域取得了显著的成功,也被广泛应用于语音识别和自然语言处理等领域。
2.1 CNN基本结构
一个典型的卷积神经网络由以下几种层组成:卷积层(Convolutional Layer)、激活层(Activation Layer)、池化层(Pooling Layer)、全连接层(Fully Connected Layer)。
2.1.1 卷积层(Convolutional Layer)
卷积层通过滤波器(也称为卷积核)在输入数据上进行卷积操作,提取局部特征。每个滤波器都会在输入数据上滑动(即进行卷积运算),生成特征图(feature map)。
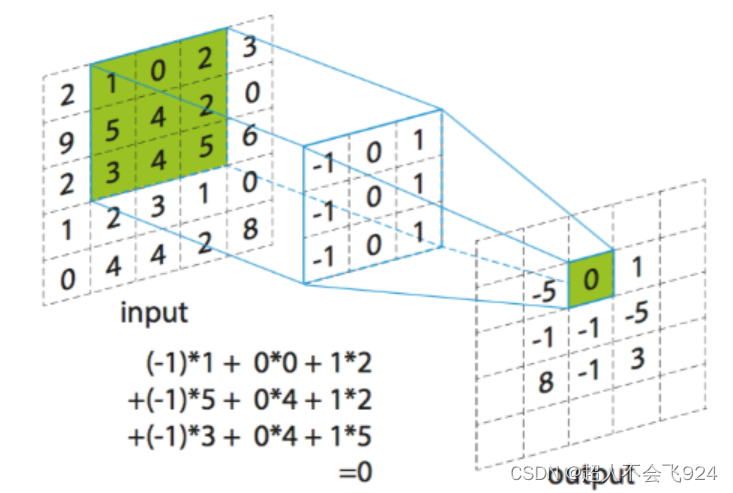
特点:
- 保留空间关系:卷积操作保留了输入数据的空间结构和关系。
- 参数共享:同一个卷积核在整个输入数据上滑动,所有位置共享相同的参数,这显著减少了参数数量。
- 局部连接:每个神经元仅与上一层的一个小局部区域连接,这使得模型具有较少的连接数和较低的计算复杂度。
2.1.2 激活层(Activation Layer)
常见的激活函数包括ReLU(Rectified Linear Unit)、Sigmoid和Tanh等。ReLU是最常用的激活函数,因为它能有效缓解梯度消失问题。

特点:
- 引入非线性:激活函数使网络能够学习和表示非线性特征,提升模型的表达能力。
2.1.3 池化层(Pooling Layer)
池化层通过对输入数据进行下采样,减少数据维度,降低计算复杂度。常见的池化操作有最大池化(Max Pooling)和平均池化(Average Pooling)。
- 最大池化(Max Pooling):取池化窗口内的最大值。
- 平均池化(Average Pooling):取池化窗口内的平均值。
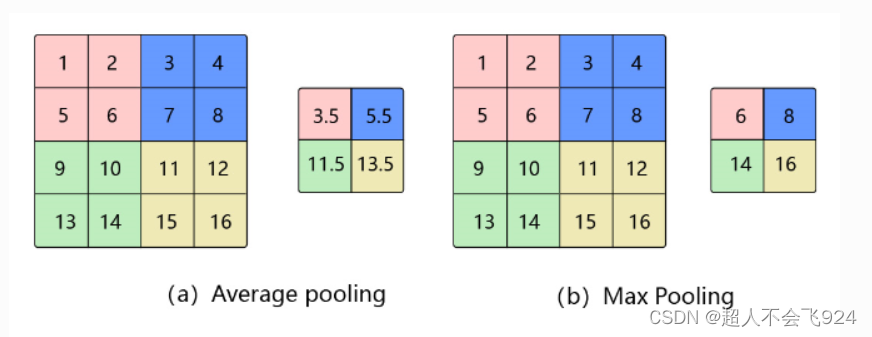
特点:
- 减少数据维度:池化操作减小特征图的尺寸,降低计算复杂度。
- 提取重要特征:最大池化保留局部区域内最显著的特征,有助于增强模型的抗噪声能力。
- 防止过拟合:通过降维减少参数数量,降低过拟合风险。
2.1.4 全连接层(Fully Connected Layer)
全连接层(也称密集层)将前一层的输出展平成一个向量,并与一组权重矩阵相乘,生成输出结果。每个神经元与上一层的所有神经元连接,综合各特征,完成最终的分类或回归任务。
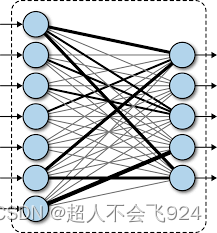
特点:
- 综合特征:全连接层结合前面卷积层和池化层提取的特征,形成更高层次的特征表示。
- 高度灵活:全连接层可用于任意类型的输出层,如二分类、多分类或回归。
卷积神经网络通过层级结构,逐层提取输入数据的特征,从而实现复杂的模式识别和分类任务。卷积层提取局部特征,激活层引入非线性,池化层降维并保留重要特征,全连接层综合特征并完成最终任务。通过合理设计和堆叠这些层,CNN能够高效处理和分析高维数据。
2.2 CNN主要参数
卷积神经网络(CNN)的各种参数对其性能和计算效率有重要影响。下面详细介绍卷积核、步长、填充、通道数、池化核、膨胀/空洞卷积这些参数:
2.2.1 卷积核(Kernels)
卷积核是一个小矩阵,用于在输入数据上滑动并进行卷积操作以提取特征。
参数:
- 大小:卷积核的尺寸,通常为 k×k(如 3x3、5x5 等)。
- 数量:每个卷积层可以有多个卷积核,每个卷积核生成一个特征图(feature map)。
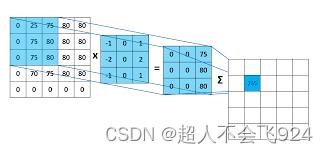
作用:卷积核通过滑动窗口的方式提取局部特征,并生成特征图,这些特征图保留了输入数据的空间信息。
2.2.2 步长(Stride)
步长是指卷积核在输入数据上滑动的步幅,即每次移动的像素数。
参数:
- 水平步长和垂直步长:可以分别设定水平和垂直方向的步长,通常步长在水平和垂直方向上相同,如 (1, 1)、(2, 2) 等。
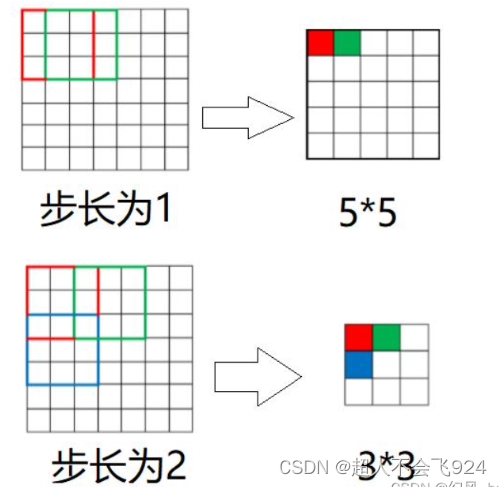
作用:步长决定了特征图的尺寸。较大的步长会导致特征图尺寸减小(压缩),而较小的步长则能更细致地提取特征但计算开销更大。
2.2.3 填充(Padding)
在输入数据的边缘添加额外的像素(通常是0),以控制输出特征图的尺寸。
类型:
- 无填充(Valid Padding):不添加额外像素,输出特征图尺寸减小。
- 填充(Same Padding):添加适当数量的像素,使输出特征图尺寸与输入相同。
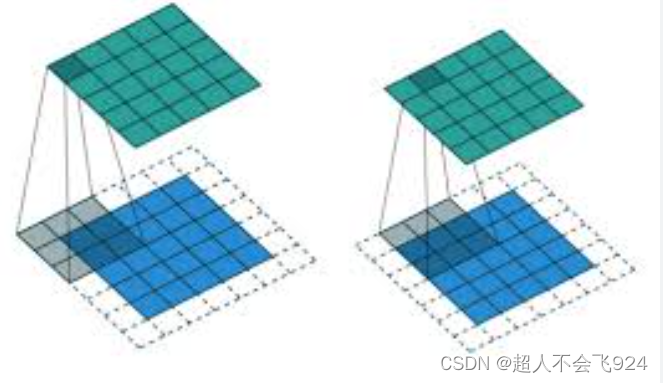
作用:填充有助于保留输入特征图的空间尺寸,避免卷积操作后特征图尺寸减小过快,特别是在深层网络中。
2.2.4 通道数(Channels)
输入数据或特征图的深度,即每个位置包含的特征数量。比如彩色图像,通常有三个通道(RGB)。
参数:
- 输入通道数:输入数据的通道数,如RGB图像有3个通道。
- 输出通道数:卷积层生成的特征图的通道数,通常等于卷积核的数量。
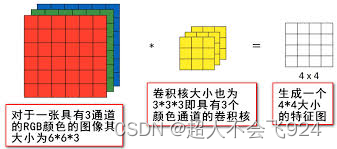
作用:通道数增加可以提取更多不同的特征,但会增加计算复杂度。
2.2.5 池化核(Pooling Kernels)
池化层用于对输入数据进行下采样,减少特征图的尺寸和计算复杂度。
参数:
- 大小:池化核的尺寸,常见的有2x2、3x3等。
- 步长:池化操作的滑动步幅,通常与池化核尺寸相同。
类型:
- 最大池化(Max Pooling):取池化窗口内的最大值。
- 平均池化(Average Pooling):取池化窗口内的平均值。
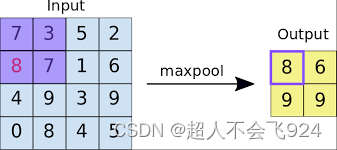
作用:池化层通过下采样减少数据的空间维度,保留重要特征,降低过拟合风险。
2.2.6 膨胀/空洞卷积(Dilated Convolution)
膨胀卷积是通过在卷积核元素之间引入间隔来扩展卷积核的感受野,不增加计算开销。
参数:
- 膨胀率(dilation rate):控制卷积核元素之间的间隔,如膨胀率为2时,卷积核元素之间有一个像素的间隔。
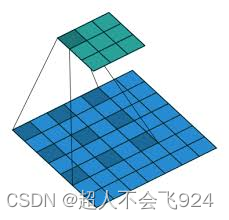
作用:膨胀卷积增加了感受野,使得卷积层能够捕捉更大范围的特征,同时保持计算复杂度不变。适用于需要大感受野的任务,如语义分割。
这些参数共同决定了CNN的结构和性能,通过合理的配置和优化,可以构建高效的卷积神经网络,解决各种复杂的任务。
2.3 CNN实现姓氏分类
为了证明CNN的有效性,让我们应用一个简单的CNN模型来分类姓氏。这项任务的许多细节与前面的MLP示例相同,但真正发生变化的是模型的构造和向量化过程。模型的输入,而不是我们在上一个例子中看到的收缩的onehot,将是一个onehot的矩阵。这种设计将使CNN能够更好地“view”字符的排列,并对在“示例:带有多层感知器的姓氏分类”中使用的收缩的onehot编码中丢失的序列信息进行编码。
2.3.1 数据集(The SurnameDataset)
使用数据集中最长的姓氏来控制onehot矩阵的大小有两个原因。首先,将每一小批姓氏矩阵组合成一个三维张量,要求它们的大小相同。其次,使用数据集中最长的姓氏意味着可以以相同的方式处理每个小批处理。
代码如下:
class SurnameDataset(Dataset):
def __init__(self, surname_df, vectorizer):
"""
Args:
surname_df (pandas.DataFrame): 数据集
vectorizer (SurnameVectorizer): 从数据集实例化的向量化器
"""
self.surname_df = surname_df
self._vectorizer = vectorizer
self.train_df = self.surname_df[self.surname_df.split=='train'] # 训练集DataFrame
self.train_size = len(self.train_df) # 训练集大小
self.val_df = self.surname_df[self.surname_df.split=='val'] # 验证集DataFrame
self.validation_size = len(self.val_df) # 验证集大小
self.test_df = self.surname_df[self.surname_df.split=='test'] # 测试集DataFrame
self.test_size = len(self.test_df) # 测试集大小
# 以字典形式存储数据集拆分
self._lookup_dict = {'train': (self.train_df, self.train_size),
'val': (self.val_df, self.validation_size),
'test': (self.test_df, self.test_size)}
self.set_split('train') # 设置当前拆分为训练集
# 类别权重
class_counts = surname_df.nationality.value_counts().to_dict() # 统计每个国籍的样本数
def sort_key(item):
return self._vectorizer.nationality_vocab.lookup_token(item[0])
sorted_counts = sorted(class_counts.items(), key=sort_key) # 按国籍词汇表的顺序对样本数进行排序
frequencies = [count for _, count in sorted_counts]
self.class_weights = 1.0 / torch.tensor(frequencies, dtype=torch.float32) # 计算类别权重
@classmethod
def load_dataset_and_make_vectorizer(cls, surname_csv):
"""加载数据集并从头开始创建新的向量化器
Args:
surname_csv (str): 数据集的位置
Returns:
SurnameDataset的实例
"""
surname_df = pd.read_csv(surname_csv) # 从CSV文件加载数据集
train_surname_df = surname_df[surname_df.split=='train'] # 获取训练集DataFrame
return cls(surname_df, SurnameVectorizer.from_dataframe(train_surname_df)) # 实例化SurnameDataset对象
@classmethod
def load_dataset_and_load_vectorizer(cls, surname_csv, vectorizer_filepath):
"""加载数据集和相应的向量化器。
在向量化器已经缓存以便重用的情况下使用
Args:
surname_csv (str): 数据集的位置
vectorizer_filepath (str): 保存的向量化器的位置
Returns:
SurnameDataset的实例
"""
surname_df = pd.read_csv(surname_csv) # 从CSV文件加载数据集
vectorizer = cls.load_vectorizer_only(vectorizer_filepath) # 加载向量化器
return cls(surname_df, vectorizer) # 实例化SurnameDataset对象
@staticmethod
def load_vectorizer_only(vectorizer_filepath):
"""从文件加载向量化器的静态方法
Args:
vectorizer_filepath (str): 序列化向量化器的位置
Returns:
SurnameDataset的实例
"""
with open(vectorizer_filepath) as fp:
return SurnameVectorizer.from_serializable(json.load(fp)) # 从文件加载向量化器
def save_vectorizer(self, vectorizer_filepath):
"""使用json保存向量化器到磁盘
Args:
vectorizer_filepath (str): 保存向量化器的位置
"""
with open(vectorizer_filepath, "w") as fp:
json.dump(self._vectorizer.to_serializable(), fp) # 将向量化器序列化为JSON并保存到文件中
def get_vectorizer(self):
"""返回向量化器"""
return self._vectorizer # 返回向量化器
def set_split(self, split="train"):
"""使用数据框中的列选择数据集的拆分"""
self._target_split = split # 设置目标拆分
self._target_df, self._target_size = self._lookup_dict[split] # 获取目标拆分的DataFrame和大小
def __len__(self):
return self._target_size # 返回数据集大小
def __getitem__(self, index):
"""PyTorch数据集的主要入口方法
Args:
index (int): 数据点的索引
Returns:
一个字典,包含数据点的特征(x_data)和标签(y_target)
"""
row = self._target_df.iloc[index] # 获取索引处的行数据
surname_matrix = \
self._vectorizer.vectorize(row.surname) # 使用向量化器将姓氏转换为矩阵形式
nationality_index = \
self._vectorizer.nationality_vocab.lookup_token(row.nationality) # 获取国籍的索引
return {'x_surname': surname_matrix,
'y_nationality': nationality_index} # 返回姓氏矩阵和国籍索引的字典
def get_num_batches(self, batch_size):
"""给定批量大小,返回数据集中的批次数
Args:
batch_size (int)
Returns:
数据集中的批次数
"""
return len(self) // batch_size # 返回数据集中的批次数
def generate_batches(dataset, batch_size, shuffle=True,
drop_last=True, device="cpu"):
"""
一个生成器函数,它封装了PyTorch DataLoader。
它将确保每个张量都位于正确的设备位置。
"""
dataloader = DataLoader(dataset=dataset, batch_size=batch_size,
shuffle=shuffle, drop_last=drop_last) # 创建DataLoader对象
for data_dict in dataloader:
out_data_dict = {}
for name, tensor in data_dict.items():
out_data_dict[name] = data_dict[name].to(device) # 将张量移到指定设备
yield out_data_dict # 生成数据字典
2.3.2 词汇表、向量化器(Vocabulary, Vectorizer, and DataLoader)
在本例中,尽管词汇表和DataLoader的实现方式与“示例:带有多层感知器的姓氏分类”中的示例相同,但Vectorizer的vectorize()方法已经更改,以适应CNN模型的需要。具体来说,该函数将字符串中的每个字符映射到一个整数,然后使用该整数构造一个由onehot向量组成的矩阵。重要的是,矩阵中的每一列都是不同的onehot向量。主要原因是,我们将使用的Conv1d层要求数据张量在第0维上具有批处理,在第1维上具有通道,在第2维上具有特性。
除了更改为使用onehot矩阵之外,我们还修改了矢量化器,以便计算姓氏的最大长度并将其保存为max_surname_length
代码如下:
class Vocabulary(object):
"""用于处理文本并提取词汇表进行映射的类"""
def __init__(self, token_to_idx=None, add_unk=True, unk_token="<UNK>"):
"""
Args:
token_to_idx (dict): 一个预先存在的标记到索引的映射字典
add_unk (bool): 一个指示是否添加UNK标记的标志
unk_token (str): 要添加到词汇表中的UNK标记
"""
if token_to_idx is None:
token_to_idx = {}
self._token_to_idx = token_to_idx
self._idx_to_token = {idx: token
for token, idx in self._token_to_idx.items()}
self._add_unk = add_unk
self._unk_token = unk_token
self.unk_index = -1
if add_unk:
self.unk_index = self.add_token(unk_token)
def to_serializable(self):
"""返回一个可序列化的字典"""
return {'token_to_idx': self._token_to_idx,
'add_unk': self._add_unk,
'unk_token': self._unk_token}
@classmethod
def from_serializable(cls, contents):
"""从序列化字典中实例化词汇表"""
return cls(**contents)
def add_token(self, token):
"""基于标记更新映射字典。
Args:
token (str): 要添加到词汇表中的项目
Returns:
index (int): 对应于标记的整数
"""
try:
index = self._token_to_idx[token]
except KeyError:
index = len(self._token_to_idx)
self._token_to_idx[token] = index
self._idx_to_token[index] = token
return index
def add_many(self, tokens):
"""将标记列表添加到词汇表中
Args:
tokens (list): 一组字符串标记
Returns:
indices (list): 与标记对应的索引列表
"""
return [self.add_token(token) for token in tokens]
def lookup_token(self, token):
"""检索与标记相关联的索引,如果标记不存在,则返回UNK索引。
Args:
token (str): 要查找的标记
Returns:
index (int): 与标记对应的索引
Notes:
对于UNK功能,unk_index需要>=0(已添加到词汇表中)
"""
if self.unk_index >= 0:
return self._token_to_idx.get(token, self.unk_index)
else:
return self._token_to_idx[token]
def lookup_index(self, index):
"""返回与索引相关联的标记
Args:
index (int): 要查找的索引
Returns:
token (str): 与索引相关联的标记
Raises:
KeyError: 如果索引不在词汇表中
"""
if index not in self._idx_to_token:
raise KeyError("索引 (%d) 不在词汇表中" % index)
return self._idx_to_token[index]
def __str__(self):
return "<词汇表(size=%d)>" % len(self)
def __len__(self):
return len(self._token_to_idx)
class SurnameVectorizer(object):
"""协调词汇表并将其用于向量化的向量化器"""
def __init__(self, surname_vocab, nationality_vocab, max_surname_length):
"""
Args:
surname_vocab (Vocabulary): 将字符映射到整数的词汇表
nationality_vocab (Vocabulary): 将国籍映射到整数的词汇表
max_surname_length (int): 最长姓氏的长度
"""
self.surname_vocab = surname_vocab
self.nationality_vocab = nationality_vocab
self._max_surname_length = max_surname_length
def vectorize(self, surname):
"""
Args:
surname (str): 姓氏
Returns:
one_hot_matrix (np.ndarray): 一个独热向量的矩阵
"""
one_hot_matrix_size = (len(self.surname_vocab), self._max_surname_length)
one_hot_matrix = np.zeros(one_hot_matrix_size, dtype=np.float32)
for position_index, character in enumerate(surname):
character_index = self.surname_vocab.lookup_token(character)
one_hot_matrix[character_index][position_index] = 1
return one_hot_matrix
@classmethod
def from_dataframe(cls, surname_df):
"""从数据框实例化向量化器
Args:
surname_df (pandas.DataFrame): 姓氏数据集
Returns:
SurnameVectorizer的实例
"""
surname_vocab = Vocabulary(unk_token="@")
nationality_vocab = Vocabulary(add_unk=False)
max_surname_length = 0
for index, row in surname_df.iterrows():
max_surname_length = max(max_surname_length, len(row.surname))
for letter in row.surname:
surname_vocab.add_token(letter)
nationality_vocab.add_token(row.nationality)
return cls(surname_vocab, nationality_vocab, max_surname_length)
@classmethod
def from_serializable(cls, contents):
surname_vocab = Vocabulary.from_serializable(contents['surname_vocab'])
nationality_vocab = Vocabulary.from_serializable(contents['nationality_vocab'])
return cls(surname_vocab=surname_vocab, nationality_vocab=nationality_vocab,
max_surname_length=contents['max_surname_length'])
def to_serializable(self):
return {'surname_vocab': self.surname_vocab.to_serializable(),
'nationality_vocab': self.nationality_vocab.to_serializable(),
'max_surname_length': self._max_surname_length}
2.3.3 分类模型(The SurnameClassifier)
在本例中使用的模型是使用我们在“卷积神经网络”中介绍的方法构建的。实际上,我们在该部分中创建的用于测试卷积层的“人工”数据与姓氏数据集中使用本例中的矢量化器的数据张量的大小完全匹配。它与我们在“卷积神经网络”中引入的Conv1d序列既有相似之处,也有需要解释的新添加内容。具体来说,该模型类似于“卷积神经网络”,它使用一系列一维卷积来增量地计算更多的特征,从而得到一个单特征向量。
然而,本例中的新内容是使用sequence和ELU PyTorch模块。序列模块是封装线性操作序列的方便包装器。在这种情况下,我们使用它来封装Conv1d序列的应用程序。ELU是类似于实验3中介绍的ReLU的非线性函数,但是它不是将值裁剪到0以下,而是对它们求幂。ELU已经被证明是卷积层之间使用的一种很有前途的非线性(Clevert et al., 2015)。
在本例中,我们将每个卷积的通道数与num_channels超参数绑定。我们可以选择不同数量的通道分别进行卷积运算。这样做需要优化更多的超参数。我们发现256足够大,可以使模型达到合理的性能。
代码如下:
import torch.nn as nn
import torch.nn.functional as F
class SurnameClassifier(nn.Module):
def __init__(self, initial_num_channels, num_classes, num_channels):
"""
Args:
initial_num_channels (int): 输入特征向量的大小
num_classes (int): 输出预测向量的大小
num_channels (int): 网络中使用的常数通道大小
"""
super(SurnameClassifier, self).__init__()
# 定义卷积神经网络模型
self.convnet = nn.Sequential(
nn.Conv1d(in_channels=initial_num_channels,
out_channels=num_channels, kernel_size=3),
nn.ELU(), # ELU激活函数
nn.Conv1d(in_channels=num_channels, out_channels=num_channels,
kernel_size=3, stride=2),
nn.ELU(),
nn.Conv1d(in_channels=num_channels, out_channels=num_channels,
kernel_size=3, stride=2),
nn.ELU(),
nn.Conv1d(in_channels=num_channels, out_channels=num_channels,
kernel_size=3),
nn.ELU()
)
# 定义全连接层
self.fc = nn.Linear(num_channels, num_classes)
def forward(self, x_surname, apply_softmax=False):
"""分类器的前向传播
Args:
x_surname (torch.Tensor): 输入数据张量。x_surname.shape应为(batch, initial_num_channels, max_surname_length)
apply_softmax (bool): softmax激活标志,如果与交叉熵损失一起使用,应为false
Returns:
结果张量。张量.shape应为(batch, num_classes)
"""
features = self.convnet(x_surname).squeeze(dim=2) # 将特征张量压缩到两个维度中
prediction_vector = self.fc(features) # 全连接层输出预测向量
if apply_softmax:
prediction_vector = F.softmax(prediction_vector, dim=1) # 应用softmax激活函数
return prediction_vector # 返回预测向量
2.3.4 训练(The Training Routine)
训练程序包括以下似曾相识的的操作序列:实例化数据集,实例化模型,实例化损失函数,实例化优化器,遍历数据集的训练分区和更新模型参数,遍历数据集的验证分区和测量性能,然后重复数据集迭代一定次数。对于这个例子,将不再详细描述具体的训练例程,因为它与“示例:带有多层感知器的姓氏分类”中的例程完全相同。但是,输入参数是不同的。
各部分代码如下:
def make_train_state(args):
"""
创建训练状态字典
Args:
args: 参数对象,包含模型训练相关的参数
Returns:
train_state (dict): 训练状态字典,包含模型训练过程中的各种状态信息
"""
return {
'stop_early': False, # 是否提前停止训练的标志
'early_stopping_step': 0, # 早停步数
'early_stopping_best_val': 1e8, # 最佳验证集损失初始值
'learning_rate': args.learning_rate, # 学习率
'epoch_index': 0, # 当前训练的epoch索引
'train_loss': [], # 训练集损失列表
'train_acc': [], # 训练集准确率列表
'val_loss': [], # 验证集损失列表
'val_acc': [], # 验证集准确率列表
'test_loss': -1, # 测试集损失
'test_acc': -1, # 测试集准确率
'model_filename': args.model_state_file # 模型文件名
}
def update_train_state(args, model, train_state):
"""
更新训练状态
Components:
- Early Stopping: 防止过拟合。
- Model Checkpoint: 如果模型性能更好,则保存模型。
Args:
args: 主要参数
model: 要训练的模型
train_state: 表示训练状态值的字典
Returns:
train_state (dict): 更新后的训练状态字典
"""
# 至少保存一个模型
if train_state['epoch_index'] == 0:
torch.save(model.state_dict(), train_state['model_filename'])
train_state['stop_early'] = False
# 如果性能提高,则保存模型
elif train_state['epoch_index'] >= 1:
loss_tm1, loss_t = train_state['val_loss'][-2:]
# 如果损失恶化
if loss_t >= train_state['early_stopping_best_val']:
# 更新步数
train_state['early_stopping_step'] += 1
# 损失减少
else:
# 保存最佳模型
if loss_t < train_state['early_stopping_best_val']:
torch.save(model.state_dict(), train_state['model_filename'])
# 重置早停步数
train_state['early_stopping_step'] = 0
# 是否早停?
train_state['stop_early'] = \
train_state['early_stopping_step'] >= args.early_stopping_criteria
return train_state
def compute_accuracy(y_pred, y_target):
# 获取预测的索引
y_pred_indices = y_pred.max(dim=1)[1]
# 计算正确预测的数量
n_correct = torch.eq(y_pred_indices, y_target).sum().item()
# 计算准确率
accuracy = n_correct / len(y_pred_indices) * 100
return accuracy
# 创建实验所需的文件路径
# Data and Path information
args = Namespace(
surname_csv="surnames_with_splits.csv", # 姓氏数据集的CSV文件路径
vectorizer_file="vectorizer.json", # 向量化器保存文件路径
model_state_file="model.pth", # 模型状态文件路径
save_dir="model_storage/ch4/cnn", # 实验结果保存目录路径
# Model hyper parameters
hidden_dim=100, # 隐藏层维度
num_channels=256, # 卷积层通道数
# Training hyper parameters
seed=1337, # 随机种子
learning_rate=0.001, # 学习率
batch_size=128, # 批量大小
num_epochs=10, # 迭代轮数 #为了减少实验轮数,将轮数从100调整为10
early_stopping_criteria=5, # 提前停止条件
dropout_p=0.1, # Dropout概率
# Runtime options
cuda=False, # 是否使用CUDA加速
reload_from_files=False, # 是否从文件中重新加载模型和向量化器
expand_filepaths_to_save_dir=True, # 是否将文件路径扩展到保存目录中
catch_keyboard_interrupt=True # 是否捕获键盘中断以提前停止训练
)
# 将文件路径扩展到保存目录中
if args.expand_filepaths_to_save_dir:
args.vectorizer_file = os.path.join(args.save_dir, args.vectorizer_file)
args.model_state_file = os.path.join(args.save_dir, args.model_state_file)
print("Expanded filepaths: ")
print("\t{}".format(args.vectorizer_file))
print("\t{}".format(args.model_state_file))
# 检查是否可以使用CUDA
if not torch.cuda.is_available():
args.cuda = False
# 设置设备
args.device = torch.device("cuda" if args.cuda else "cpu")
print("Using CUDA: {}".format(args.cuda))
# 设置随机种子
set_seed_everywhere(args.seed, args.cuda)
# 创建保存目录
handle_dirs(args.save_dir)
# 如果设置了从文件中重新加载模型和向量化器
if args.reload_from_files:
# 从检查点训练
dataset = SurnameDataset.load_dataset_and_load_vectorizer(args.surname_csv,
args.vectorizer_file)
else:
# 创建数据集和向量化器
dataset = SurnameDataset.load_dataset_and_make_vectorizer(args.surname_csv)
# 保存向量化器
dataset.save_vectorizer(args.vectorizer_file)
# 获取向量化器
vectorizer = dataset.get_vectorizer()
# 创建分类器
classifier = SurnameClassifier(initial_num_channels=len(vectorizer.surname_vocab),
num_classes=len(vectorizer.nationality_vocab),
num_channels=args.num_channels)
# 将分类器移动到设备
classifier = classifier.to(args.device)
# 将数据集的类别权重移动到设备
dataset.class_weights = dataset.class_weights.to(args.device)
# 定义损失函数
loss_func = nn.CrossEntropyLoss(weight=dataset.class_weights)
# 定义优化器
optimizer = optim.Adam(classifier.parameters(), lr=args.learning_rate)
# 定义学习率调度器
scheduler = optim.lr_scheduler.ReduceLROnPlateau(optimizer=optimizer,
mode='min', factor=0.5,
patience=1)
# 创建训练状态
train_state = make_train_state(args)
训练过程:
2.3.5 评估(Evaluation)
为了要了解模型的性能,需要对性能进行定量和定性的度量,现在通过以下代码,打印损失和准确率。
# 加载模型的参数
classifier.load_state_dict(torch.load(train_state['model_filename']))
# 将模型移动到指定的设备上(CPU 或 GPU)
classifier = classifier.to(args.device)
# 将数据集的类权重也移动到相同的设备上
dataset.class_weights = dataset.class_weights.to(args.device)
# 定义损失函数,使用数据集的类权重
loss_func = nn.CrossEntropyLoss(dataset.class_weights)
# 设置数据集为测试模式
dataset.set_split('test')
# 创建测试集的批生成器
batch_generator = generate_batches(dataset,
batch_size=args.batch_size,
device=args.device)
# 初始化测试损失和准确率
running_loss = 0.
running_acc = 0.
# 将模型设为评估模式
classifier.eval()
# 遍历测试集的每个批次
for batch_index, batch_dict in enumerate(batch_generator):
# 计算模型的输出
y_pred = classifier(batch_dict['x_surname'])
# 计算损失
loss = loss_func(y_pred, batch_dict['y_nationality'])
loss_t = loss.item()
running_loss += (loss_t - running_loss) / (batch_index + 1)
# 计算准确率
acc_t = compute_accuracy(y_pred, batch_dict['y_nationality'])
running_acc += (acc_t - running_acc) / (batch_index + 1)
# 存储测试损失和准确率到训练状态字典中
train_state['test_loss'] = running_loss
train_state['test_acc'] = running_acc
#打印损失和准确率
print("Test loss: {};".format(train_state['test_loss']))
print("Test Accuracy: {}".format(train_state['test_acc']))结果如下:

与 MLP 约 46.68% 的性能相比,该模型的测试集性能准确率约为52.6%
2.3.6 预测(Prediction)
在本例中,predict_nationality()函数的一部分发生了更改,没有使用视图方法重塑新创建的数据张量以添加批处理维度,而是使用PyTorch的unsqueeze()函数在批处理应该在的位置添加大小为1的维度。相同的更改反映在predict_topk_nationality()函数中。
def predict_nationality(surname, classifier, vectorizer):
"""预测新姓氏的国籍
Args:
surname (str): 要分类的姓氏
classifier (SurnameClassifer): 分类器的实例
vectorizer (SurnameVectorizer): 对应的向量化器
Returns:
包含最可能的国籍及其概率的字典
"""
# 将姓氏向量化
vectorized_surname = vectorizer.vectorize(surname)
# 将姓氏转换为张量,并增加一维作为批次维度
vectorized_surname = torch.tensor(vectorized_surname).unsqueeze(0)
# 使用分类器进行预测
result = classifier(vectorized_surname, apply_softmax=True)
# 获取预测结果中概率最高的值和对应的索引
probability_values, indices = result.max(dim=1)
index = indices.item()
# 根据索引查找预测的国籍
predicted_nationality = vectorizer.nationality_vocab.lookup_index(index)
# 获取预测的国籍对应的概率值
probability_value = probability_values.item()
return {'nationality': predicted_nationality, 'probability': probability_value}
# 获取用户输入的姓氏
new_surname = input("Enter a surname to classify: ")
# 将分类器移动到 CPU 上进行推理
classifier = classifier.cpu()
# 使用预定义的函数预测姓氏的国籍及其概率
prediction = predict_nationality(new_surname, classifier, vectorizer)
# 输出预测结果
print("{} -> {} (p={:0.2f})".format(new_surname,
prediction['nationality'],
prediction['probability']))
预测结果:
![]()
作者小王输入自己的姓氏“Wang”,由结果可知,预测出最可能的国籍是中国,及其对应的概率值为0.58。
接下来,输入“Wang”这个姓氏,预测出概率最高的五个国籍,代码如下:
def predict_topk_nationality(surname, classifier, vectorizer, k=5):
"""预测姓氏的前K个国籍
Args:
surname (str): 要分类的姓氏
classifier (SurnameClassifer): 分类器的实例
vectorizer (SurnameVectorizer): 对应的向量化器
k (int): 要返回的前K个国籍
Returns:
由字典组成的列表,每个字典表示一个国籍及其概率
"""
# 向量化姓氏
vectorized_surname = vectorizer.vectorize(surname)
vectorized_surname = torch.tensor(vectorized_surname).unsqueeze(dim=0)
# 使用分类器进行预测并应用 softmax 函数
prediction_vector = classifier(vectorized_surname, apply_softmax=True)
# 获取前K个最可能的国籍及其概率
probability_values, indices = torch.topk(prediction_vector, k=k)
# 结果的大小为 1 x k
probability_values = probability_values[0].detach().numpy()
indices = indices[0].detach().numpy()
results = []
for kth_index in range(k):
# 查找国籍对应的标签
nationality = vectorizer.nationality_vocab.lookup_index(indices[kth_index])
# 获取对应的概率值
probability_value = probability_values[kth_index]
results.append({'nationality': nationality,
'probability': probability_value})
return results
# 获取用户输入的姓氏
new_surname = input("Enter a surname to classify: ")
# 获取要显示的前K个预测结果
k = int(input("How many of the top predictions to see? "))
if k > len(vectorizer.nationality_vocab):
print("Sorry! That's more than the # of nationalities we have.. defaulting you to max size :)")
k = len(vectorizer.nationality_vocab)
# 进行预测
predictions = predict_topk_nationality(new_surname, classifier, vectorizer, k=k)
# 输出预测结果
print("Top {} predictions:".format(k))
print("===================")
for prediction in predictions:
print("{} -> {} (p={:0.2f})".format(new_surname,
prediction['nationality'],
prediction['probability']))
预测结果:

从这些概率中可以看出,"Wang" 作为姓氏,最有可能是中国姓氏,其次是韩国姓氏。
"Wang" 是中国非常常见的姓氏,拼音为 "Wáng"(王)或 "Wāng"(汪)。在中国,姓 "Wang" 的人很多,因此它具有最高的概率 0.58。
"Wang" 在韩国也是存在的姓氏,韩文为 "왕"。虽然在韩国不如在中国普遍,但仍然有一定的比例。因此它的概率为 0.22。其他国家的可能性则比较低。

















 1183
1183

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









