







目录
3.1.3 整型 short、int、long 和 long long
本章节将介绍C++中的内置变量类型。
内置的C++类型分为两种:基本类型和复合类型。而本章节将介绍基本类型,即整数和浮点数。
3.1 简单变量
程序通常都要存储信息,为了把信息存储在计算机中,程序必须要记录三种属性:
1. 信息要存储在哪里;
2. 要存储什么类型的值;
3. 存储何种类型的信息。
当我们声明一个变量的时候,声明中使用的类型描述了信息的类型和变量名:
int number = 114514; //int 是变量类型,number 是变量名上述语句告诉程序,我要存储一个整数类型(int)的值,并使用名称 number 来表示该指数的值(这里为 114514)。实际上的过程是:程序在内存中会找到一个足够大的空间以存储一个 int 类型的值,并且将这个内存单元标记为 number,然后将114514赋值到这个内存单元。在接下来的程序中我们就可以使用名称 number 来调用这个内存单元里存储的值。我们还可以使用 & 运算符来访问 number 的内存地址,但这是下一章的内容了。
3.1.1 变量名
我们在一般编程的时候,会使用各种各样的变量名称,例如:cnt、number、time等。它们都有一个共同的特点,那就是可以从变量名中了解到这个变量的大致用途,例如:cnt 表示计数器,number 表示存储一个数字,time 表示记录时间或次数。C++提倡使用有一定含义的变量名。尽量不使用例如 a、b、abc 这样的变量,因为这会让我们的程序变得晦涩难懂。
必须遵守几种简单的C++命名规则:
1. 在名称中只能使用字母字符、数字和下划线。
2. 名称的第一个字符不可以是数字。
3. 区分大写字符与小写字符。
4. 不能将C++关键字用作名称。
5. 以两个下划线开头或以下划线和大写字母开头的名称被保留给实现(编译器及其使用的资源)使用。以一个下划线开头的名称被保留给实现,用作全局标识符。
6. C++对于名称长度没有具体限制,名称中所有的字符都有意义。但是某些在线测试平台可能会对名称做出具体限制。
其中第五点表明,我们尽量不要使用下划线开头的变量名称,因为这可能带来不确定的后果。
下面介绍几个不合法的变量声明语句:
Int cnt; //是 int,不是Int
int double; //double 是关键字不可以用作名称
int 114514kun; //不能以数字开头
int kun-kun; //使用了非法字符 '-'如果我们想用两个单词组成一个变量名称,可以使用下划线将两个单词隔开:
int kun_kun;3.1.2 整型
整数就是没有小数部分的数字。如1,2,114514,-666 和 0 等,但是计算机的存储空间是有限的,它将整型描述为一种整数的子集。C++提供好几种子集的范围,以供我们根据程序选择最合适的整型。
不同的C++整型使用不同的内存量来存储整数。使用的内存量越大,可以表示的整数值的范围也越大。另外部分整型(signed 符号类型)可以表示负值,而另一些(unsigned 无符号类型)不能。宽度(width)用来描述存储整数时使用的内存量。使用的内存量越多,则越宽。
C++的基本整型(按照宽度递增的顺序排列)分别为:char、short、int、long 和 C++11 新增的 long long。其中每个类型都有有符号版本和无符号版本,共有十种可供选择的整型。由于 char 类型有一些特殊的属性(更常使用 char 来表示字符而不是数字),因此本章节优先介绍其他类型的变量。
3.1.3 整型 short、int、long 和 long long
这里先介绍什么叫位和字节,以方便接下来的理解。
计算机内存由一些叫做位(bit)的单元组成。每一个位都有两种状态:0 或者 1,不存在第三种状态。所以两位就有: 种组合(00,01,10,11),以此类推,n 位字节就有
种组合。
字节(byte)通常指的是 8 位的存储单元。从这个意义上来说,字节指的就是描述计算机内存量的度量单位。,这里的 B、KB、MB、GB 就是我们所熟知的内存单位,其中 B 指的就是字节 byte 的首字母。然而C++对于字节的定义与此不同。C++字节由至少能够容纳实现的基本字符的相邻位组成。换句话说,就是可能取值的数目必须大于或等于字符数目。例如:ASCII 字符集中一共定义了 128 个字符,其中包括大小写字母以及一些常用的标点符号。而
,所以可以使用 8 位来表示 ASCII 中的所有字符,例如:小写字母 a 在 ASCII 字符集中排第 97 位,a = 97 = 0110 0001;大写字母 A 在 ASCII 中排第65位,A = 65 = 0100 0001。但是某些国际编程可能需要使用根本更大的字符集,如 Unicode,因此有些实现可能使用 1字节 = 16位/32位。有些人使用术语八位组(octet)来表示8位字节(1 字节用 8 位来实现)。
当前很多系统都使用最小长度,即八位组,short 为16位,long 为32位。如果系统中每种类型的宽度都相同,那么使用起来将会非常方便。但是没有一种选择可以满足所有的计算机设计要求。C++提供了一种灵活的标准,它确保了最小长度,例如:
1. short 至少16位;
2. int 至少与 short 一样长;
3. long 至少为32位,且至少与 int 一样长;
4. long long 至少64位,且至少与 long 一样长。
可以像使用 int 一样,来使用这些类型名来声明变量:
short sorce;
int point;
long position;
long long answer;实际上 short 是 short int 的简称,而 long 是 long int 的简称,同理 long long 是 long long int 的简称。
short、int、long、long long 都是符号类型,这意味着每种类型的取值范围中,负值和正值几乎相同。例如,16位最多可以有 ,所以16位的 int 取值范围为 -32768 ~ +32767。
要知道系统中整数的最大长度,可以在程序中使用C++工具来检查类型的长度。首先 sizeof 运算符返回类型或变量的长度,单位为字节。但是“字节”的含义依赖于实现,因此不能确定类型或变量的位数。其次,头文件 climits 中包含了关于整型的限制信息。例如,INT_MAX 为 int 的最大值,CHAR_BIT 为字节的维数。
如下,程序清单3.1详细演示了有关整型及其相关函数的用法:
//程序清单3.1
#include <iostream>
#include <climits>
int main() {
using namespace std;
short n_short = SHRT_MAX;
int n_int = INT_MAX;
long n_long = LONG_MAX;
long long n_llong = LLONG_MAX;
cout << "每种类型的最大值:" << endl;
cout << "short = " << n_short << endl;
cout << "int = " << n_int << endl;
cout << "long = " << n_long << endl;
cout << "long long = " << n_llong << endl;
cout << endl;
cout << "每种类型所占的字节数:" << endl;
cout << "short = " << sizeof (short) << endl;
cout << "int = " << sizeof (int) << endl;
cout << "long = " << sizeof (n_long) << endl;
cout << "long long = " << sizeof n_llong << endl;
cout << endl;
cout << "short 的最小值为:" << SHRT_MIN << endl;
cout << "每个字节包含 " << CHAR_BIT << "位(bit)" << endl;
return 0;
}
运行结果:
每种类型的最大值:
short = 32767
int = 2147483647
long = 2147483647
long long = 9223372036854775807
每种类型所占的字节数:
short = 2
int = 4
long = 4
long long = 8
short 的最小值为:-32768
每个字节包含 8位(bit)
1. 运算符 sizeof 和头文件 climits
可以对类型名称或变量名使用 sizeof 运算符。对类型名称(如 short、int 等)使用括号将类型名称扩起:sizeof (int);但是对于变量名称,括号是可选的。但是这里建议不论是类型名称还是变量名称都是用括号扩起,这样可以减少错误的发生。
头文件 climits 定义了符号常量来表示类型的限制。如下表:
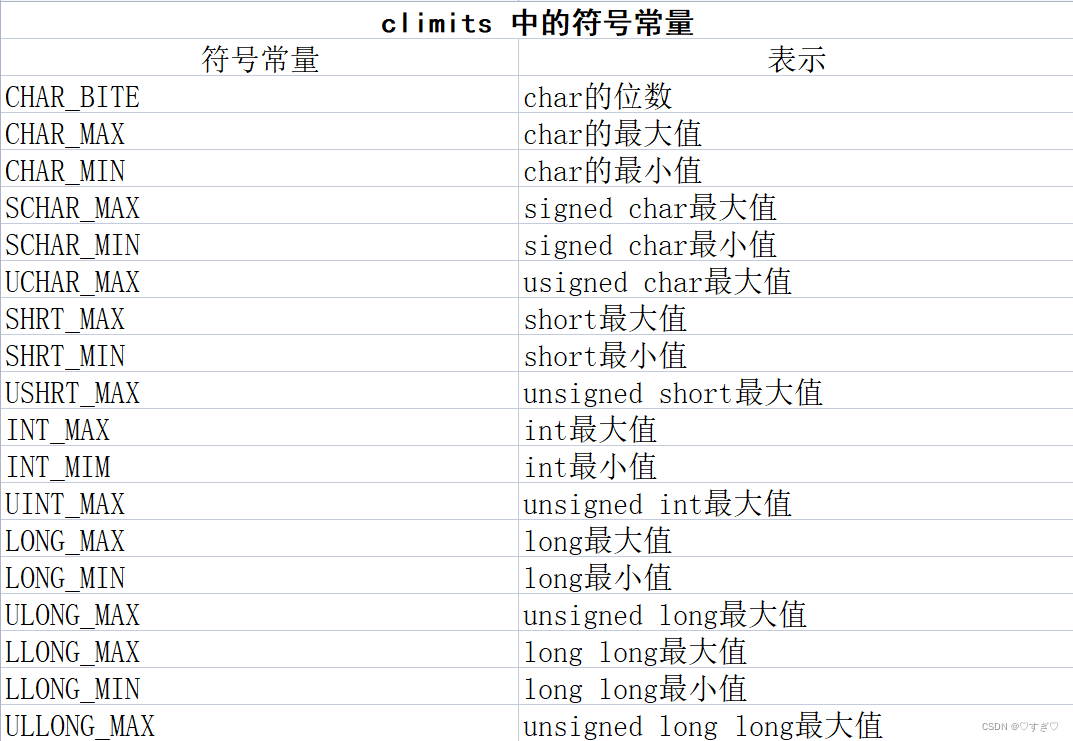
符号常量——预处理器方式:
#include <iostream>
#define INT_MAX 32767像上面这样带 # 号的语句,被称为预处理语句。其中第一句用于将指定头文件嵌入源文件中,第二句用于创建符号常量 INT_MAX,并将程序中的所有 INT_MAX 都替换为常量 32767。不论是第一条语句还是第二条语句都属于预处理语句,他们的执行都发生在程序的预处理阶段——程序被编译之前。
#define 编译指令是C语言遗留下来的,C++有一种更好的方式创建符号常量:使用关键字 const。这将在后一章节中详细讨论。
2. 初始化
初始化将变量的声明和赋值放在了一起:
int n_int = INT_MAX;也可以使用已经被赋值的变量或所有条件都已知的表达式来初始化新的变量:
int cnt = 5;
int number = cnt; //number = 5
int alpha = cnt + number + 4; //alpha = 14我们不可以在声明变量之后不初始化(赋值)就使用,这样可能会导致一些编译器无法识别的错误。需要知道的是:如果不对函数内部定义的变量进行初始化,该变量的值将是不确定的。这意味着该变量的值将是它创建之前,相应内存单元所保存的值。例如:在内存 0x114514 的位置曾经存储过一个整型,其值为 666,现在我又创建了一个名为 cnt 的整型变量,而 cnt 使用的内存地址也恰好为 0x114514,这时我不给 cnt 初始化就使用它,那么编译器不会报错,而是认为 cnt 中存储的就是值 666,程序运行的时候会使用值 666 来进行运算。犯了这个错误一般不容易被发现,所以要尽量避免。
3. C++11初始化方式
还有另一种初始化数组和结构的方式也可以用于单值变量:
//声明变量 cnt 并初始化其值为5
int cnt = {5};
//可以省略等号
int number {6};
//若大括号内为空,则初始化值为0
int alpha = {};
int beta {};3.1.4 无符号类型
前面的四种整型(short、int、long、long long)都有一种不能存储负值的无符号版本。如果short 的存储范围是 -32768~+32767,那么无符号版本的 short 可以存储的范围是 0~+65535。如果想要创建无符号版本的整型,只需要加上关键字 unsigned 即可:
unsigned short population;
unsigned int number;
unsigned long ticket;
unsigned long long sand;下面通过一段简单的程序,进一步加深对整型的认识:
//程序清单3.2
#include <iostream>
#include <climits>
int main() {
using namespace std;
//初始化 short_min 和 short_max 分别为 short 类型的最小和最大值
short short_min = SHRT_MIN;
short short_max = SHRT_MAX;
cout << "short min = " << short_min << endl;
cout << "short max = " << short_max << endl;
short_min = short_min - 1;
cout << "short min - 1 = " << short_min << endl;
short_max = short_max + 1;
cout << "short max + 1 = " << short_max << endl;
cout << endl;
//初始化ushort_min和short_max分别为无符号版本的short的最小和最大值
unsigned short ushort_max = USHRT_MAX;
unsigned short ushort_min = 0;
cout << "unsigned short max = " << ushort_max << endl;
cout << "unsigned short min = " << ushort_min << endl;
ushort_max = ushort_max + 1;
cout << "unsigned short max + 1 = " << ushort_max << endl;
ushort_min = ushort_min - 1;
cout << "unsigned short min - 1 = " << ushort_min << endl;
return 0;
}
运行结果:
short min = -32768
short max = 32767
short min - 1 = 32767
short max + 1 = -32768
unsigned short max = 65535
unsigned short min = 0
unsigned short max + 1 = 0
unsigned short min - 1 = 65535通过程序清单3.2我们可以看出,short 的取值范围是 -32768~+32767,unsigned short 的取值范围为 0~+65535。但是奇怪的是 short 的最大值再加一的得到的结果不是 +32768,而是-32768,这里就要引出一个概念:上溢,与之对应的就是下溢。当数值超过了类型的取值范围时,便会出现上溢或下溢。为了避免这种情况的发生,C++采取了一种方法:
可以将 short 的取值范围想象在一个数轴上,这个数轴的取值范围 -32768~+32767,现在将数轴的两端连接上,让数轴弯曲成一个首尾相接的环。现在我们从这个弯曲的数轴的原点出发,一直向着数增大的方向走,0 -> 1 -> 2 -> ...... -> 32765 -> 32767,现在我们到了 +32767,继续向前走就可以到达数轴两个端点连接的地方(因为数轴首尾相接变成了一个环),所以 32767 -> -32768 -> -32767 -> 32766 -> ... -> -1 -> 0。
同样无符号整形也是这样,只不过两端的值换成了 0 和 65535。
3.1.5 选择整型类型
C++提供了大量的整型,通常,int 被设置为对目标计算机而言最“自然”的长度。自然长度(natural size)指的是计算机处理起来效率最高的长度。如果没有特殊需求,和节省空间的要求下,尽量选择使用 int。
如果只需要使用一个字节,可使用 char 类型。
3.1.6 整型字面值
整型字面值(常量)是显示地书写的常量。C++能够以三种不同的计数方式来书写整数:基数为十、基数为八和基数为十六。C++使用前一两位来表示数字常量的基数:如果第一位为 1~9 ,十进制;如果第一位是 0,第二位为1~7,八进制;如果前两位为 0x 或 0X,十六进制。
//程序清单3.3
#include <iostream>
int main() {
using namespace std;
int binary_10 = 17;
int binary_8 = 017;
int binary_16 = 0x17;
cout << "binary_10 = " << binary_10 << " (17 in decimal)" << endl;
cout << "binary_8 = " << binary_8 << " (017 in octal)" << endl;
cout << "binary_16 = " << binary_16 << " (0x17 in hex)" << endl;
return 0;
}
运行结果:
binary_10 = 17 (17 in decimal)
binary_8 = 15 (017 in octal)
binary_16 = 23 (0x17 in hex)在默认情况下,cout 以十进制格式显示整数,而不管整数是如何在程序中表示的。但是不论把值书写为何种形式,都将以相同的方式存储在计算机中——被存储为二进制数。
//程序清单3.4
#include <iostream>
int main() {
using namespace std;
int binary_10 = 17;
int binary_8 = 17;
int binary_16 = 17;
cout << "binary_10 = " << binary_10 << " (decimal for 17)" << endl;
cout << oct;
cout << "binary_8 = " << binary_8 << " (octal for 17)" << endl;
cout << hex;
cout << "binary_16 = " << binary_16 << " (hex for 17)" << endl;
return 0;
}
运行结果:
binary_10 = 17 (decimal for 17)
binary_8 = 21 (octal for 17)
binary_16 = 11 (hex for 17)像程序清单3.4中的 cout << oct; 和 cout << hex; 语句并不会输出,这两个语句的作用是改变 cout 显示整数的方式。关键字 oct 和 hex 在命名空间 std 中,如果不引入 std 命名空间,那么需要写作 std::oct 和 std::hex。
3.1.7 C++如何确定常量的类型
在如下C++语句中:
cout << "今年是 " << 2023 << " 年" << endl;程序会自动将 2023 存储为 int 类型。除非使用特殊后缀来表示特定的值、或者值太大不能存储为 int 类型。否则程序会优先将数字存储为 int 类型。关于特殊后缀,有:l、L后缀表示该整数为 long 常量;u、U 后缀表示 unsigned int 常量;ul、uLUL 表示 unsigned long 常量;ll、LL 表示 long long 常量;ull、uLL、Ull、ULL 表示 unsigned long long 常量。
3.1.8 char 类型:字符和小数
最后一种整型:char类型。char 类型是专门为存储字符(如 ascii 字符)而设计的。一般来说,char 类型的大小只有一个字节,如果按八位组来算的话,那么 char 类型的范围是 -128 ~+127。无符号类型的 char 取值范围是 0 ~ +255。C++还支持 wchar_t 宽字符类型来表示和存储更多的值,如国际 Unicode 字符集中所使用的值。
在美国,最常用的字符集是 ascii 一般写作 ASCII(美国信息交换标准代码)。字符集中的字符使用数字编码(ASCII 码)表示。例如:A 在编码中为 65,a 在编码中为 97。
//程序清单3.5
#include <iostream>
int main() {
using namespace std;
//声明char类型的变量
char ch;
cout << "请输入一个字母:" << endl;
cin >> ch;
cout << "你输入的字母是:" << ch << endl;
cout << ch << "的ASCII值为:" << (int) ch << endl;
return 0;
}
运行结果:
请输入一个字母:
H
你输入的字母是:H
H的ASCII值为:72程序清单3.5中,通过运行结果的第二行可知和已经了解过的知识可知,存储在 ch 中的值是 H 所对应的 ASCII 值。但是用 cout 输出变量 ch,输出的不是记录在 ch 中的整数,而是这个整数在 ASCII 中所对应的字母(72 -> H)。会发生这样的事情还是因为 cout 和 cin 这两个智能工具。在输入时,cin 将字符转化为 ASCII 值;输出时,cout 将 ASCII 值转化为对应字符。
//程序清单3.6
#include <iostream>
int main() {
using namespace std;
//声明char类型的变量
char ch_char = 'H';
int ch_int = ch_char;
cout << ch_char << " 的ASCII值为:" << ch_int << endl;
ch_char = ch_char + 1;
ch_int = ch_char;
cout << ch_char << " 的ASCII值为:" << ch_int << endl;
cout << "使用cout.put()函数进行字符的输出:";
cout.put(ch_char);
cout.put('!');
return 0;
}
运行结果:
H 的ASCII值为:72
I 的ASCII值为:73
使用cout.put()函数进行字符的输出:I!程序清单3.6中更清晰地表明了其实存储在 char 类型变量里的是整数,因为可以对其做整数操作,如 ch_char = ch_char + 1;,这个语句将 ch_char 的值从72,变成了73。只是在使用 cout 输出 char 类型的变量时,会将存储在其中的整数转换为字符类型输出。
在最后,程序使用了 cout.put() 来显示变量 ch_char 和一个字符常量。
成员函数 cout.put()
函数 cout.put() 是一个重要的C++ OOP概念——成员函数——的第一个例子。类定义了如何表示和控制数据。成员函数归类所有,描述了操纵类数据的方法。例如类 ostream 有一个 put() 成员函数,用来输出字符。只能通过类的特定对象(这里是 cout 对象)来使用成员函数。要通过对象(如 cout)使用成员函数,必须用句点将对象名和函数名称(put())连接起来。句点(.)被称为成员运算符。cout.put() 的意思是,通过类 cout 来使用函数 put()。
cout.put() 提供了另一种显示字符的方法,可以代替 << 运算符。
char 字面值
在C++中,书写字符串常量的方法有很多种。对于常规字符,最简单的方法是将字符用单引号括起来。这种表示法代表的是字符的数值编码。例如:’A‘ => 65,'a' => 97,'5' => 53,' ' => 32,'!' => 33。
有些字符不能哦童工键盘直接输入到程序中,对于这些字符,C++提供了一种特殊的表示方法——转义序列。如下表:
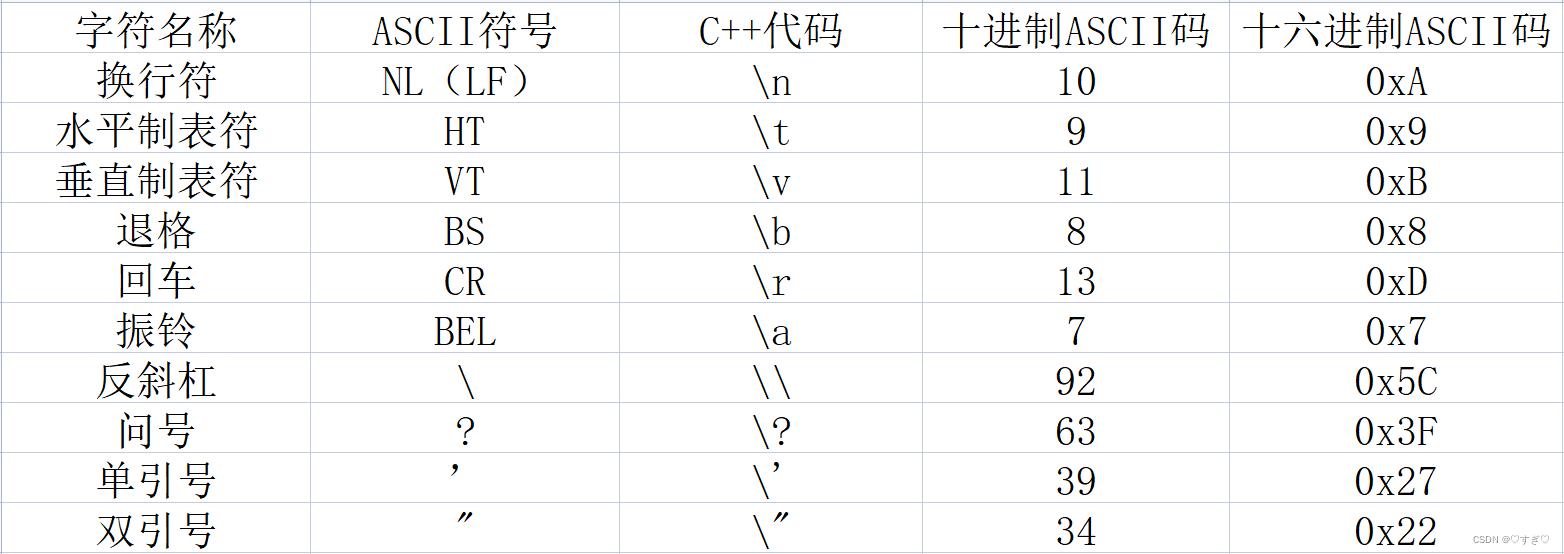
例如:换行符 \n 可以代替 endl 进行输出换行操作。
//下面三个句子,都能够起到一个输出换行的作用
cout << endl;
cout << '\n';
cout << "\n";通用字符名
C++有一种表达特殊字符的机制,它独立于任何特定的键盘,使用的是通用字符名(universal character name)。通用字符名的用法类似于转义序列,以 \u 或 \U 开头。\u 后是4个十六进制位,而 \U 后是8个十六进制位。这些位表示的是字符的 ISO 10646 码点(ISO 10646 是一种正在指定的国际标准,为大量字符提供数字编码),也可以看作是 Unicode 码点。
ISO 10646 小组和 Unicode 小组共同对多种语言文本进行标准化编码,给每个字符指定一个编号,而这个编号就是上文提到的码点。
例如:ö的 ISO 10646 码点是 00F6,则可以使用 \u00F6 来表示字符 ö。
int k\u00F6rper; //表示声明了一个名为 körper 的变量signed char 和 unsigned char
与 int 不同的是,char 在默认的情况下既不是没有符号,也不是有符号的。是否有符号由C++实现决定。其中 signed char 表示范围为 -128 ~+127,unsigned char 表示范围为 0~+255。如果要使用 char 来存储200这样大的值时,只能使用 unsigned char 来存储。
wchar_t 宽字符
有时候程序需要处理的字符集可能无法用一个8位的字节表示,如汉字系统。而类型 wchar_t(宽字符类型)可以表示扩展字符集。wchar_t 是整数类型,他有足够大的空间,可以表示系统使用的最大扩展字符集。
此时 cin 和 cout 就不适用于处理 wchar_t 类型。iostream 头文件中提供了作用相似的工具——wcin 和 wcout,可以用于处理 wchar_t 流。另外,可以通过加上前缀 L 来指示宽字符常量和宽字符串。
//将宽字符版本的字母 K 存储到temp中
wchar_t temp = L'K';
//显示宽字符版本的 Kun
wcout << L"Kun" << endl;C++11新增类型 char16_t 和 char32_t
随着编程人员日益熟悉 Unicode 编码,类型 wchar_t 显然不能够再满足需求,所以 char16_t 和 char32_t 应运而生。其中前者为无符号16位字符类型,后者为无符号32位字符类型。分别使用前缀 u 和 U 表示。
char16_t ch1 = u'I';
char32_t ch2 = U'L';3.1.9 bool类型
ANSI/ISO C++标准添加了一种名叫 bool 的新类型。在计算中,bool 类型的变量值可以是 true 也可以是 false。并且C++将非零值解释为 true,将零值解释为 false。
bool flag = true;字面值 true 和 false 可以通过提升转换为 int 类型,true 被转换为 1,false 被转换为 0。
int a = true; //a = 1
int b = false; // b = 0另外,任何数字值或指针值都可以被隐式地转换为 bool 值。任何非零值转换为 true,零值转换为 false。
bool start = -100; //start = true
bool final = 0; //final = false


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











