






时间紧迫学识浅薄,略微简陋请多包涵。
目录
一、链表
链表由一系列结点(链表中每一个元素称为结点)组成,结点可以在运行时动态生成。每个结点包括两个部分:一个是存储数据元素的数据域,另一个是存储下一个结点地址的指针域域。 相比于线性表顺序结构,操作复杂。
1、不带头结点的单链表
我们就以学生为例写一个单链表
先定义一个结构体,在结构体中定义一个指针,用来指向下一个节点,褡裢子
struct node
{
int num;
char name[32];
struct node *next;
};
在构建链表的时候每个节点都需要申请空间,我们可以提前构建一个函数来完成这个功能。
struct node *create_node()
{
struct node *pnew = NULL;
pnew = (struct node*)malloc(sizeof(struct node));
assert(pnew!=NULL);
pnew->next = NULL;
return pnew;
}准备工作完成就可以开始创建链表了,我们先用头插法创建
struct node* create_list_by_head()
{
struct node *head = NULL, *pnew = NULL;
int x;
scanf("%d", &x);
while(getchar()!='\n');
while(x)
{
//1、创建新的节点, 并且赋值
pnew = create_node();
pnew->data = x;
//2、加入链表
pnew->next = head;
head = pnew;
scanf("%d", &x);
while(getchar()!='\n');
}
return head;
}
我们还可以使用尾插法创建链表
struct node* create_list()
{
struct node *head = NULL; //头指针:保存第一个节点的地址
struct node *pnew = NULL; //保存新的节点地址
struct node *tail = NULL; //标记最后一个节点的地址
int x;
scanf("%d", &x);
while(getchar()!='\n');
while(x)
{
//1、创建新的节点,并赋值
pnew = (struct node*)malloc(sizeof(struct node));
if(NULL == pnew)
{
printf("malloc error, %s, %d\n",__FILE__,__LINE__);
break;
}
pnew->data = x;
pnew->next = NULL;
//2、加入链表
if(NULL == head)
{
head = pnew;
tail = pnew;
}
else
{
tail->next = pnew;
tail = pnew;
}
scanf("%d", &x);
while(getchar()!='\n');
}
return head;
}创建完基本链表的结构之后,我们还可以设计个插入函数,在需要信息补填的时候使用。
插入的时候需要先定位到插入位置,还要确定你要插入的位置是否合法,所以下面设计两个函数,一个测试链表长度,一个查找定位
int list_len(struct node *head)
{
int len = 0;
while(head!=NULL)
{
len++;
head = head->next;
}
return len;
}struct node *list_search_by_index(struct node *head, int index)
{
//入参检查链表是否为空
if(NULL == head)
{
return NULL;
}
int len = list_len(head);
if(index<1 || index>len)
{
printf("param error! %s, %d\n", __FILE__, __LINE__);
return NULL;
}
//正确的话进行插入
struct node *p = head;
for(int i=1; i<index; i++)
{
p = p->next;
}
return p;
}可以轻松定位之后就是插入函数
struct node *list_insert_by_index(struct node *head, int index, int data)
{
//入参检查输入数据是否有问题
int len = list_len(head);
#if 0
if(index<1 || index>len+1)
{
printf("param error!%s, %d\n", __FILE__,__LINE__);
return head;
}
#endif
if(index<1)
{
index = 1;
}
if(index>len+1)
{
index = len+1;
}
//正确的话就开始插入操作
struct node *pnew = NULL, *psearch = NULL;
pnew = create_node();
pnew->data = data;
if(1 == index) //头插
{
pnew->next = head;
head = pnew;
}
else if (len+1 == index) //尾插
{
psearch = list_search_by_index(head, len);
psearch->next = pnew;
}
else //中间插入
{
psearch = list_search_by_index(head, index-1);
pnew->next = psearch->next;
psearch->next = pnew;
}
return head;
}有了插入,我们还可以加个删除模块
删除我们要单独考虑头部,
具体删除思路:(1)保存删除节点地址(2)将删除节点从链表中移除 (3)释放内存
void list_del_by_index(struct node **phead, int index)
{
//入参检查
if(phead == NULL)
{
return ;
}
if(*phead == NULL)
{
return ;
}
int len = list_len(*phead);
if(index<1 || index>len)
{
return ;
}
//删除开始
struct node *pdel = NULL;
if(1 == index)
{
pdel = *phead;
*phead = (*phead)->next;
free(pdel);
}
else
{
struct node *psearch = list_search_by_index(*phead, index-1);
pdel = psearch->next;
psearch->next = pdel->next;
free(pdel);
}
return ;
}为了查看链表方便,还可以写个排序函数和遍历函数
struct node*list_sort(struct node *head)
{
struct node *new_head = NULL;
struct node *pmax = NULL;
while(head!=NULL)
{
//(1)从旧链表中找出最大值
pmax = find_max_from_oldlist(head);
//(2)将最大值从旧链表中移下来
head = remove_max_from_oldlist(head, pmax);
//(3)将最大值通过头插法加入新的链表
new_head = add_newlist(new_head, pmax);
}
return new_head;
}void show_list(struct node *head)
{
if(NULL == head)
{
printf("空链表!\n");
}
else
{
struct node *p = head;
while(p!=NULL)
{
printf("[%d|%p]-->", p->data, p->next);
p = p->next;
}
printf("\n");
}
}基本的链表操作都有了,再写个释放函数释放链表,清理程序运行中出现的 多余的空间浪费
struct node*list_free(struct node *head)
{
struct node *pdel = NULL;
while(head != NULL)
{
pdel = head;
head = head->next;
free(pdel);
}
return head;
}就这样一个基本的不带头结点的单链表函数的体系就构建完成了
2、带头节点的单链表
- 和不带头结点的单链表的区别:使用链表的时候不需要考虑操作位置在头结点的情况,而且在主函数中有个头结点,单链表本身也有了明显的标识。
- 将链表保存到文件中
基本的操作没问题了,但是单链表再怎么操作,程序结束后就会消失。所以我们可以构建一个函数,将单链表的数据写到文件中,方便下次使用
int read_file(struct node *head)
{
FILE *fp = NULL;
fp = fopen("./data.txt", "rb");
assert(fp!=NULL);
int ret;
struct node *pnew = NULL;
while(1)
{
pnew = create_node();
ret = fread(pnew, sizeof(struct node), 1, fp);
if(0 == ret) //到达文件结尾
{
break;
}
//加入head指向的链表中
pnew->next = head->next;
head->next = pnew;
}
free(pnew); //释放最后一个申请的空间
fclose(fp);
return 0;
}3.从文件中读链表
int write_file(struct node *head)
{
int ret;
FILE *fp = NULL;
fp = fopen("./data.txt", "wb");
assert(fp != NULL);
struct node *p = head->next;
while(p!=NULL)
{
ret = fwrite(p, sizeof(struct node), 1, fp);
if(ret<1)
{
perror("fwrite");
fclose(fp);
return -1;
}
p = p->next;
}
fclose(fp);
return 0;
}
3、双向链表
struct node
{
int num;
char name[32];
struct node *pre; //前驱指针
struct node *next; //后驱指针
};双向链表相对于单链表多了一个指针pre可以指向前一个结点,相对于单链表而言在查找和删除等操作上会简单很多
首先让我们创建个链表
struct node*create_node()
{
struct node *pnew = NULL;
pnew = (struct node*)malloc(sizeof(struct node));
assert(pnew!=NULL);
pnew->pre = NULL;
pnew->next = NULL;
return pnew;
}
void create_list(struct node *head)
{
struct node *pnew = NULL;
char ch;
printf("是否创建链表?");
scanf("%c", &ch);
while(getchar()!='\n');
while(ch=='Y'||ch=='y')
{
//1、创建新的节点,并且赋值
pnew = create_node();
printf("请输入学号:");
scanf("%d", &pnew->num);
while(getchar()!='\n');
printf("请输入姓名:");
scanf("%s", pnew->name);
while(getchar()!='\n');
//2、加入链表
if(head->next == NULL) //空链表
{
head->next = pnew;
pnew->pre = head;
}
else //非空链表,头插法
{
pnew->next = head->next;
head->next->pre = pnew;
head->next = pnew;
pnew->pre = head;
}
printf("是否继续?");
scanf("%c", &ch);
while(getchar()!='\n');
}
return ;
}
然后做个遍历函数展示链表内容
void show_list(struct node *head)
{
if(head->next == NULL)
{
printf("空链表!\n");
return ;
}
printf("正向遍历:\n");
struct node *p = head->next;
struct node *q = NULL;
while(p!=NULL)
{
printf("[%d|%s|%p|%p]-->",p->num, p->name, p->pre, p->next);
q = p;
p = p->next;
}
printf("\n逆向遍历:\n");
while(q != head)
{
printf("%d|%s|%p|%p-->", q->num, q->name, q->pre, q->next);
q = q->pre;
}
printf("\n");
}然后是查找,和单链表一样,下面挂个 插入
void list_insert_by_num(struct node *head,int num, struct node *pnew)
{
struct node *psearch = NULL;
psearch = list_search_by_num(head, num);
if(psearch == NULL)
{
printf("插入失败,学号%d不存在!\b", num);
return ;
}
psearch->pre->next = pnew;
pnew->pre = psearch->pre;
pnew->next = psearch;
psearch->pre = pnew;
return ;
}插入玩,再来个删除
void list_del_by_num(struct node *head, int num)
{
struct node *pdel = NULL;
pdel = list_search_by_num(head, num);
if(NULL == pdel)
{
printf("删除失败, 学号%d不存在!\n", num);
return ;
}
if(pdel->next == NULL)
{
pdel->pre->next = NULL;
}
else
{
pdel->pre->next = pdel->next;
pdel->next->pre = pdel->pre;
}
free(pdel);
return ;
}再来个排序基本功能就全了
void list_sort(struct node *head)
{
//1、将头结点和后面的链表断开
struct node *head1 = head->next;
head->next = NULL;
//2、对head1链表进行排序
struct node* new_head = NULL;
struct node* pmax = NULL;
struct node* p = NULL;
while(head1!=NULL)
{
//(1)找到最大值
pmax = head1;
p = head1;
while(p!=NULL)
{
if(p->num > pmax->num)
{
pmax = p;
}
p = p->next;
}
//(2) 将最大值从head1中移除
if(pmax == head1)
{
head1 = head1->next;
}
else
{
p = head1;
while(p->next != pmax)
{
p = p->next;
}
p->next = pmax->next;
}
pmax->pre = NULL;
pmax->next = NULL;
//(3)头插法加入new_head链表
if(new_head == NULL)
{
new_head = pmax;
}
else
{
pmax->next = new_head;
new_head->pre = pmax;
new_head = pmax;
}
}
//3、将new_head的头挂到到头结点的后面
head->next = new_head;
new_head->pre = head;
return ;
}
构建程序的话,最后再加个释放函数就好了
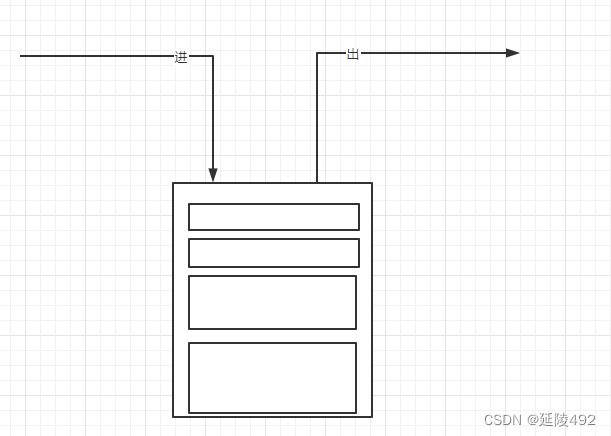
二、栈结构
特点: 先进后出, 后进先出
一般使用顺序结构或者链式来实现
关键词:栈顶、栈底
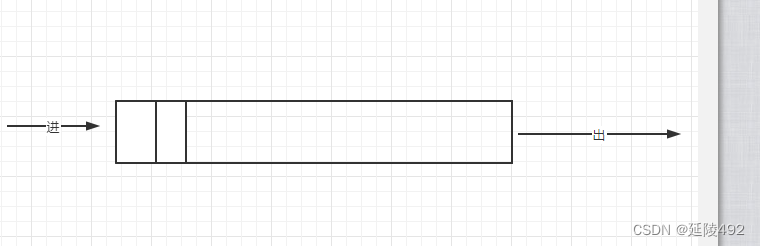
三、队列
特点:先进先出, 后进后出
实现: 顺序结构 链式结构
关键词:队头、队尾
四、树和二叉树
1、定义
树是n(n>=0)个结点的有限集。当n = 0时,称为空树。在任意一棵非空树中应满足:有且仅有一个特定的称为根的结点。
显然,树的定义是递归的,即在树的定义中又用到了自身,树是一种递归的数据结构。树作为一种逻辑结构,同时也是一种分层结构,具有以下两个特点:1.树的根结点没有前驱,除根结点外的所有结点有且只有一个父节点。
2.树中所有结点可以有零个或多个后继。因此n个结点的树中有n-1条边。
2、遍历方式
先创建一个二叉树
struct node*create_tree()
{
struct node *root = NULL, *pnew = NULL;
int x;
scanf("%d", &x);
while(getchar()!='\n');
while(x)
{
pnew = (struct node*)malloc(sizeof(struct node));
assert(pnew != NULL);
pnew->data = x;
pnew->left = NULL;
pnew->right = NULL;
if(NULL == root)
{
root = pnew;
}
else
{
struct node *p = root, *q = NULL;
while(p!=NULL)
{
q = p;
if(pnew->data < p->data)
{
p = p->left;
}
else
{
p = p->right;
}
}
if(pnew->data < q->data)
{
q->left = pnew;
}
else
{
q->right = pnew;
}
}
scanf("%d", &x);
while(getchar()!='\n');
}
return root;
}先序遍历:
先访问根节点->然后先序遍历左子树->最后先序遍历右子树
void pre_print(struct node *root)
{
if(NULL!=root)
{
printf("%d ", root->data);
pre_print(root->left);
pre_print(root->right);
}
}
中序遍历:
先中序遍历左子树->再访问根节点->最后中序遍历右子树
void mid_print(struct node *root)
{
if(NULL != root)
{
mid_print(root->left);
printf("%d ", root->data);
mid_print(root->right);
}
}后序遍历:
先后序遍历左子树->再后序遍历右子树->最后访问根节点
void tail_print(struct node *root)
{
if(NULL!= root)
{
tail_print(root->left);
tail_print(root->right);
printf("%d ", root->data);
}
}老师说的一题还挺有意思挂上来给大家看看
已知其中的两种遍历结果(先序和中序 或者 中序和后序), 推倒原始有序二叉树,并写出第三种遍历结果.
先序: ABDEFCGH
中序: DBFEAGHC
后序: DFEBHGCA
五、哈希表
散列表(Hash table,也叫哈希表),是根据关键码值(Key value)而直接进行访问的数据结构。也就是说,它通过把关键码值映射到表中一个位置来访问记录,以加快查找的速度。这个映射函数叫做散列函数,存放记录的数组叫做散列表。
给定表M,存在函数f(key),对任意给定的关键字值key,代入函数后若能得到包含该关键字的记录在表中的地址,则称表M为哈希(Hash)表,函数f(key)为哈希(Hash) 函数
(取自百度)
#include <stdio.h>
#include <stdlib.h>
#include <assert.h>
#define LEN 11
struct node
{
int data;
struct node *next;
};
void hash_init(struct node *hash_table[])
{
for(int i=0; i<LEN; i++)
{
hash_table[i] = NULL;
}
}
int hash_func(int key)
{
return key%LEN;
}
void hash_insert(struct node *hash_table[], int key)
{
int index;
//1、通过哈希函数定位插入到哪一条链表
index = hash_func(key);
//2、创建新的节点,加入指定链表
struct node *pnew = NULL;
pnew = (struct node*)malloc(sizeof(struct node));
assert(pnew!=NULL);
pnew->data = key;
pnew->next = NULL;
pnew->next = hash_table[index];
hash_table[index] = pnew;
return;
}
void hash_show(struct node *hash_table[])
{
for(int i=0; i<LEN; i++)
{
if(hash_table[i] == NULL)
{
printf("第%d条链表为空\n", i);
}
else
{
struct node*p = hash_table[i];
printf("第%d条链表的数据为:", i);
while(p!=NULL)
{
printf("%d ", p->data);
p = p->next;
}
printf("\n");
}
}
}
struct node *hash_search(struct node* hash_table[], int key)
{
int index = hash_func(key);
struct node *p = hash_table[index];
while(p!=NULL)
{
if(p->data == key)
{
return p;
}
p = p->next;
}
return NULL;
}
int main()
{
struct node *hash_table[LEN];
hash_init(hash_table);
hash_insert(hash_table, 20);
hash_insert(hash_table, 30);
hash_insert(hash_table, 70);
hash_insert(hash_table, 15);
hash_insert(hash_table, 8);
hash_insert(hash_table, 12);
hash_insert(hash_table, 18);
hash_insert(hash_table, 63);
hash_insert(hash_table, 19);
hash_show(hash_table);
return 0;
}六、算法
1、选择排序
冲数组中找到最大的放到前面顺着排
void sel(int a[],int n)
{
int i,j,temp,min=0,x=0,max;
for(i=0;i<n;i++)
{
x=i;
min=a[i];
for(j=i+1;j<n;j++){ if(min >= a[j]) {min=a[j];x=j;}}
if(a[x]<a[i])
{
temp=a[i];
a[i]=a[x];
a[x]=temp;
}
printf("a[%d]=%d\t",i,a[i]);
}
}
2、冒泡排序
大的放最后,反复排序排 ,n-1次
void maopao(int a[],int n)
{
int temp=0;
for(int i=n-1;i>0;i--)
for(int j=0;j<i;j++)
if(a[j]>a[j+1]){temp=a[j];a[j]=a[j+1];a[j+1]=temp;}
for(int i=0;i<n;i++) printf("a[%d]=%d\t",i,a[i]);
}
3、快速排序
以第n个为分界线,n左边的是有序区,右边是无序区,无序区读取一个放入有序区比较,有序区大于该数的整体后移一个位子。
void insert(int a[],int n)
{
int i=2,temp;
if(a[1]<a[0]){temp=a[1];a[1]=a[0];a[0]=temp;}
while(i!=n)
{
for(int j=0;j<i;j++)
if(a[i]<a[j])
{
temp=a[i];
int n=1;
while(i-n+1!=j)
{a[i]=a[i-n];n++;}
a[j]=temp;
}
i++;
}
for(i=0;i<n;i++) printf("a[%d]=%d\t",i,a[i]);
}
七、I/O
1、open
int open(const char *pathname, int flags);
int open(const char *pathname, int flags, mode_t mode);
头文件:#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
函数作用: 打开文件
参数说明:
pathname: 文件路径 flags:打开标志 mode: 设置权限
返回值:
成功返回新的文件描述符, 失败返回-1
ps: 如果使用O_CREAT标志, 要使用第三个参数
int main()
{
int fd;
//fd = open("./file.txt", O_RDONLY);//读的方式打开
//fd = open("./file.txt", O_CREAT|O_WRONLY|O_TRUNC, 0777);//写的方式打开,如果之前没有则新建,如果之前有则清空。
fd = open("./file.txt", O_CREAT|O_APPEND|O_WRONLY, 0777);//写的方式打开,文件描述符指向文末。
if(fd<0)
{
perror("open");
return -1;
}
printf("打开成功!\n");
return 0;
}
ps:一般只写标志会和以下两个组合使用: O_CREAT|O_WRONLY|O_TRUNC,表示的含义为:
如果文件不存在,根据第三个参数创建文件,然后以只写的标志打开文件
如果文件存在, 以只写的方式打开文件,并且清空文件中的内容3、以追加的方式打开文件,如果文件不存在打开失败
ps:一般追加标志会和以下标志结合使用: O_CREAT|O_APPEND|O_WRONLY
2、write
ssize_t write(int fd, const void *buf, size_t count);
头文件:#include <unistd.h>
功能说明:以字节的方式往文件写入数据
参数说明:
fd: 文件描述符
buf: 要写数据的起始地址
count :写的字节数
返回值: 成功返回正确写进去的字节数,失败返回-1
struct student
{
int num;
char name[32];
double score;
};
int main()
{
int fd, ret;
fd = open("./file.txt", O_CREAT|O_WRONLY|O_TRUNC, 0777);
if(fd<0)
{
perror("open");
return -1;
}
struct student s1 = {1001, "admin", 89.97};
ret = write(fd, &s1, sizeof(struct student));
if(ret < 0)
{
perror("write");
return -1;
}
printf("写入成功!\n");
return 0;
}
3、read
ssize_t read(int fd, void *buf, size_t count);
头文件:#include <unistd.h>
功能描述: 按照字节读取数据
参数说明:
fd: 文件描述符
buf: 存放数据内存的起始地址
count : 读取的字节数
返回值: 成功返回正确读取的字节数,失败返回-1
struct student
{
int num;
char name[32];
double score;
};
int main()
{
int fd, ret;
//1、打开文件
fd = open("./file.txt", O_RDONLY);
if(fd<0)
{
perror("open");
return -1;
}
struct student s;
//2、操作文件
ret = read(fd, &s, sizeof(struct student));
if(ret<0)
{
perror("read");
return -1;
}
printf("%d\t%s\t%.2lf\n", s.num, s.name, s.score);
//3、关闭文件
close(fd);
return 0;
}read函数返回值,有三种情况:
(1)>0 :返回实际读到的字节数
(2) =0 :到达文件结尾
(3) -1 : 失败
4、lseek
off_t lseek(int fildes, off_t offset, int whence);
头文件:#include <sys/types.h>
#include <unistd.h>
功能描述: 可以改变当前文件偏移量(文件开始处到文件当前位置的字节数)
参数说明:
fildes: 文件描述符
offset: 移动偏移量
whence : 移动的起始位置
返回值:成功返回指定文件的读写位置,失败返回-1.
#include <stdio.h>
#include <fcntl.h>
#include <unistd.h>
#include <sys/stat.h>
#include<sys/types.h>
static char buf1[] = "abcdefghij";
static char buf2[] = "ABCDEFGHIJ";
static int flag=5;
int main(void)
{
int fd,size;
fd = open("./file.txt", O_WRONLY|O_CREAT|O_TRUNC,0777);//打开或者创建一个文本文档
if (fd < 0)
{
printf("creat error\n");
return -1;
}
size = sizeof (buf1) - 1;
if (write(fd, buf1, size) != size)//写入准备好的第一个字符数组的内容
{
printf("buf1 write error\n");
return -1;
}
/*此时文档中内容为abcdefghij*/
if (lseek(fd, flag, SEEK_SET) == -1)//从文章头往后偏移flag(数值可以根据自己设置)个字节
{
printf("lseek error\n");
return -1;
}
size = sizeof( buf2) - 1;
if (write(fd, buf2, size) != size)//写入第二个字符数组的内容
{
printf("buf2 write error\n");
return -1;
}
/*此时文档中内容为abcdeABCDEFGHIJ
如果flag>=10,文档中的内容为abcdefghiABCDEFGHIJ*/
return 0;
}
5、access
int access(const char *pathname, int mode);
头文件: #include <unistd.h>
功能描述: 判断文件状态
参数说明:
pathname: 欲打开文件路径字符串
mode : 文件权限参数(R_OK:是否有读权限;W_OK:是否有写权限;X_OK:是否有可执行权限;F_OK:文件是否存在)
返回值:满足文件权限参数返回0
int ret;
ret =access("文件名或者沿着某个路径可以找到的文件的路径",R_OK);//R_OK和其他三个个参数可以任意交换
if(ret==0) printf("该文件有读(写/执行/存在)权限");6、fcntl
int fcntl(int fd, int cmd);
int fcntl(int fd, int cmd, long arg);
int fcntl(int fd, int cmd, struct flock *lock);
头文件:#include <sys/types.h>
#include <unistd.h>
功能描述: 可以用来对已打开的文件描述符进行各种控制操作以改变已打开文件的的各种属性
参数说明:
fd: 文件描述符
cmd: 指定函数的操作
arg : 另一个文件描述符
*lock : 文件锁操作结构体
cmd的参数可以是:
返回值:成功返回0,失败返回-1.
八、访问文件的C库函数
头文件:#include<stdio.h>
FILE *fopen(const char *path, const char *mode);//文件打开
int fclose(FILE *fp);//文件关闭
int fgetc(FILE *stream);//按字符读
int fputc(FILE *stream);//按字符写
char *fgets(char *s, int size, FILE *stream);//按字符串读
int fputs(const char *s, FILE *stream);//按字符串写
size_t fread(void *ptr, size_t size, size_t nmemb, FILE *stream);//按数据块读
size_t fwrite(const void *ptr, size_t size, size_t nmemb, FILE *stream);//按数据块写
int fprintf(FILE *stream, const char *format, ...);//格式化输入
int fscanf(FILE *stream, const char *format, ...);//格式化输出
int fseek(FILE *stream, long offset, int whence);//随机存取
long ftell(FILE *stream);//获得当前指针指向位置
参数说明:fp、stream:文件指针
path:文件路径名
mode:文件打开模式:r,r+,w,w+,a,a+
*s、*ptr:存放读出来的数据的地址
size:一次读取多少字节
size(fread):数据块大小
nmemb:要读取的数据块的数目
*format:字符串格式
offset:移动偏移量
whence:移动的起始位置


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









