




本章是b站某up主视频的学习笔记,源视频地址见文章末尾
一、R-CNN(anchor free)
1.框架
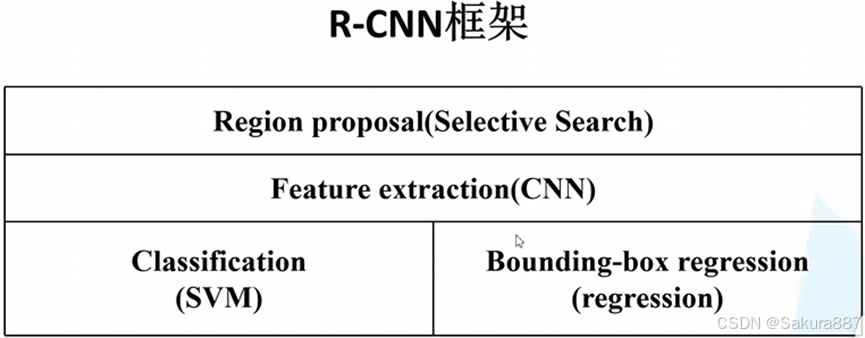
2.步骤
(1)生成候选区域:使用selective research方法分割图像来得到一些原始区域,然后利用一定的策略将这些区域合并。

(2) 对于每个候选区域,使用深度网络提取特征
将生成的候选区域(大约2000个)缩放到相同大小,输入训练好的CNN网络(不含全连接层),获取4096维的特征,得到2000*4096维的矩阵。

(3)将特征送入每一类的SVM分类器,判定类别
将2000*4096维特征与20个SVM(SVM是2分类,这里假设有20个类别)组成的权值矩阵4096*20相乘,得到2000*20维矩阵,每行表示每个候选框在20个类别的得分。之后对每一列进行NMS去除重复框。

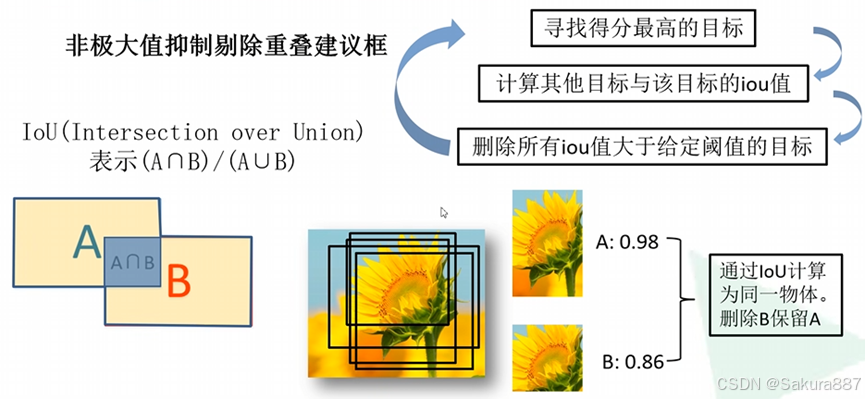

(4)使用回归器精细修正候选框位置
对上一步得到的候选框进一步筛选(将候选框与GT计算交并比,大于阈值的保留)。接着分别用20个回归器对上述20个类别中剩余的候选框进行回归(使用CNN输出的特征向量,非SVM的输出),最终得到每个类别的修正后的得分最高的bounding box。
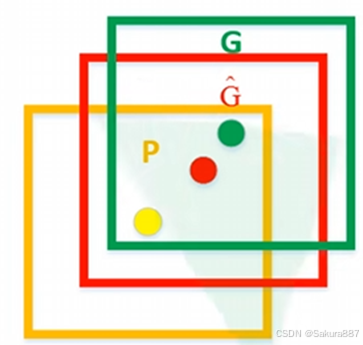
黄色为建议框(region proposal),绿色为实际框(ground truth),红色为黄色区域进行回归后的预测结果。可以用最小二乘法解决线性回归问题。
二、Fast R-CNN(anchor free)
分析R-CNN的过程,我们使用selective research方法得到2k个候选区域之后,还要将每个候选区域送入CNN中提取特征,而相邻候选区域很多地方是重叠的,因此重叠部分被提取了很多次特征,导致效率低下。因此不妨先提取整张图像的特征,然后将需要的部分取出来。
此外,R-CNN还存在着SVM的结构,我们希望将分类和回归都整合到网络中,因此将SVM舍去,用FCN进行分类。
1.框架

2.步骤
 (1)用selective search方法生成1k-2k个候选区域
(1)用selective search方法生成1k-2k个候选区域
(2)将整个图像输入到CNN得到特征图,将SS算法生成的候选框投影到特征图上获得相应的特征矩阵(就不需输入候选框重复计算)。注意不是2k个候选框都使用,而是从里面采样64个既包含正样本又包含负样本的候选框获取特征。
(3)将每个特征矩阵通过ROI pooling层缩放到7*7大小的特征图,接着将特征图展平通过一系列全连接层得到预测结果。
3.补充
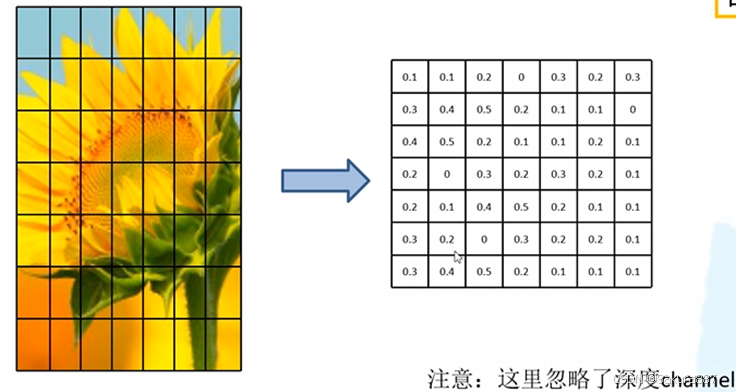
(1)ROI pooling layer
即将候选区的特征图划分为7*7的格网,对每个格网执行最大池化下采样,得到了7*7的特征图。
(2)分类器
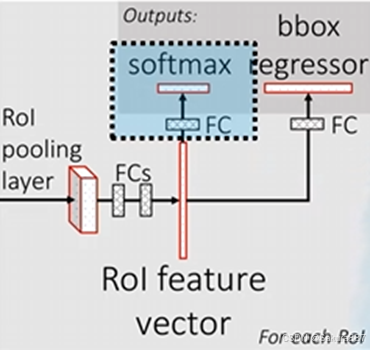
输出为N+1个类别的概率(N为检测目标的种类,1为背景)共N+1个节点

(3) 边界框回归器
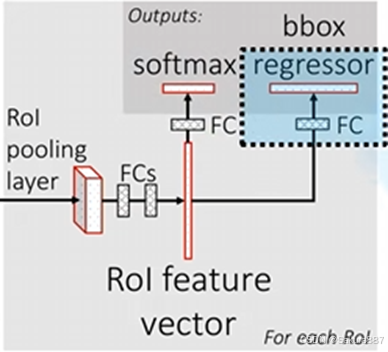
输出为N+1个类别的候选边界框回归参数(dx,dy,dw,dh)共(N+1)*4个节点


(4)损失计算:总损失=分类损失+边界框回归损失

三、Faster R-CNN (anchor based)
经过分析,使用selective research方法得到候选区域复杂度很高,而且得到2k个候选区域只有很少部分使用,因此开发出一个单独的网络,即RPN(Region Proposal Network)来生成候选区域。
1.框架
Faster R-CNN=RPN+ Fast R-CNN

2.步骤
(1)将图像输入到网络得到相应的特征图
(2)使用RPN结果生成候选框,将RPN生成的候选框投影到特征图上获得相应的特征矩阵
(3)将每个特征矩阵通过ROI pooling层缩放到7*7大小的特征图,接着将特征图展平通过全连接层得到预测结果
3.RPN
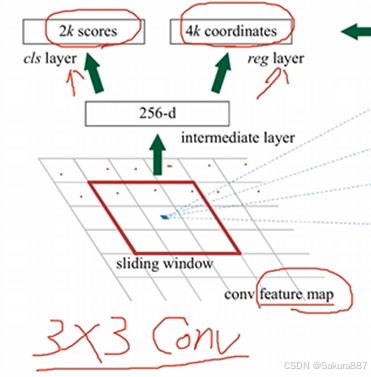
(1)过程:定义卷积核与特征图做卷积,计算出滑动窗口中心点对应到原图上的中心点,在原图上生成k个anchor,得到2k个score(每个anchor的背景概率和前景概率,不是哪个类别的概率)和4k个边界框回归参数(这些参数是RPN生成的)。
如下图所示,特征图滑动窗口中心映射到原图,在该位置生成k个黄色anchor。然后这些anchor通过边界框回归参数调整位置和形状获得候选框(所以要注意anchor和候选框是不一样的)。

(2)RPN网络的训练:并不是生成上万个anchor都用于训练,而是随机采样256个正负样本1:1的anchor进行训练。
正样本:与GT的IoU超过0.7 或者 与某个GT的IoU最大的anchor
负样本:与所有GT的IoU都小于0.3
(3)RPN的实现:原文中定义3*3卷积层,步长1,padding为1,因此可以遍历特征图的每个像素,得到和特征图相同大小的输出。然后并联两个1*1*2k(cls layer)和1*1*4k(reg layer)的卷积层得到score和边界框参数。
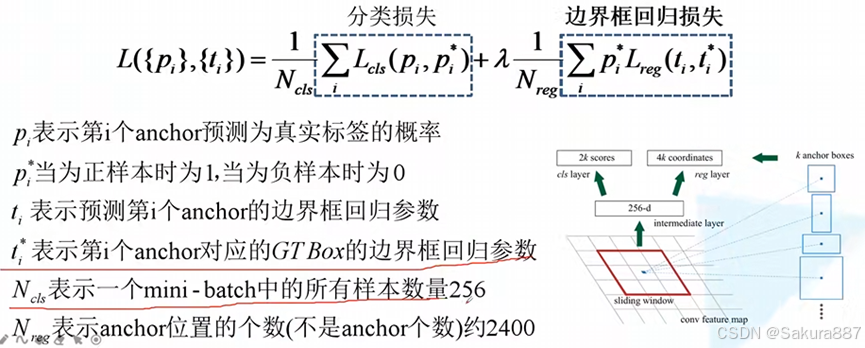
(4)RPN的损失函数


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









