




在高光谱图像(HSI)处理任务中,传统 Transformer 架构依赖的通道自注意力(CSA)或空间自注意力(SSA)存在明显局限性。高光谱图像作为 “图像立方体”,包含空间(宽、高)和光谱(数百至数千通道)三个维度,像素间的关联需在三维空间中建模。而 CSA 仅聚焦通道维度、SSA 仅聚焦空间维度,均将三维上下文信息压缩为二维相似矩阵,导致空间与光谱信息的联合分析缺失,无法充分挖掘高光谱图像立方体中隐藏的全局关联。此外,传统自注意力若直接扩展到三维空间,计算复杂度会呈立方增长,难以满足实际任务的效率需求。同时,高光谱图像的光谱具有连续性 —— 波长越接近的通道,反射信息相似度越高,但传统自注意力缺乏这种光谱位置先验,进一步限制了特征提取的准确性。
1. Volumetric Self-Attention原理
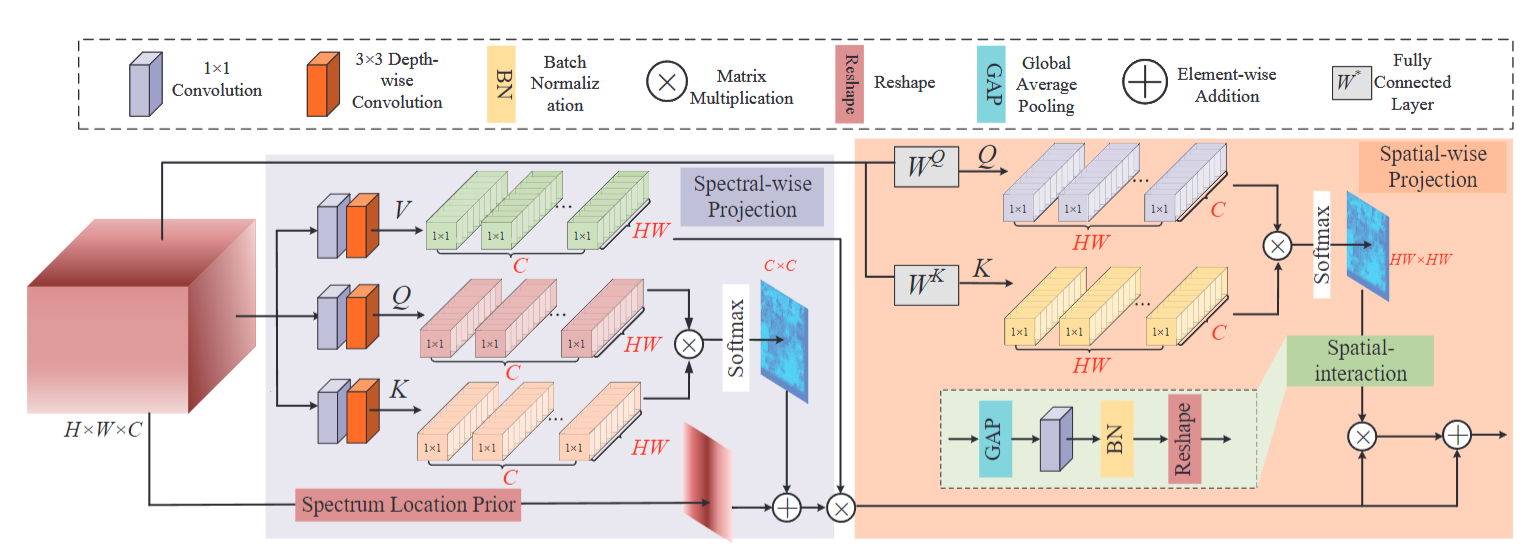
VolSA 的核心目标是在三维高光谱图像立方体中建模全面的 token 交互,的 token 交互,同时将计算复杂度从立方降至二次,并融入光谱位置先验提升特征表达能力。其原理可拆解为三部分:
双维度投影与交叉协方差计算:通过光谱维度投影(Spectral-wise Projection)和空间维度投影(Spatial-wise Projection),分别生成二维相似矩阵,再通过交叉协方差隐式构建三维上下文关联。光谱投影先将输入图像通过 1×1 点卷积和 3×3 深度卷积生成查询(Qspe)、键(Kspe)、值(Vspe),经点积交互生成通道间相似矩阵;空间投影则将输入线性投影为空间维度的Qspa和Kspa,生成像素间相似矩阵。两者结合可覆盖三维立方体中所有 token 的交互关系,且避免直接处理三维数据的高复杂度。
光谱位置先验融入:基于高光谱图像光谱连续性的特性,设计双向衰减矩阵Dnm(Dnm=γ∣n−m∣,、为光谱通道索引,γ为衰减系数),将其与光谱相似矩阵逐元素相乘。这使得目标 token 对波长相近的通道分配更高注意力权重,符合高光谱数据的物理特性,弥补了传统自注意力缺乏位置先验的缺陷。
多头注意力与特征融合:拆分为多个头(Multi-head),每个头独立计算光谱与空间相似矩阵,增强模型对不同子空间特征的捕捉能力;最后通过通道拼接(Hcat)融合多头输出,并通过线性投影(Wout)生成最终的三维关联特征,实现 “低复杂度 - 高关联度” 的平衡。
2. Volumetric Self-Attention习作思路
在目标检测任务中:VolSA 的核心优势在于能更精准地建模目标与背景的三维关联,提升复杂场景下的目标特征区分度。传统检测模型的注意力机制多聚焦于空间维度(如目标的形状、位置),而 VolSA 可同时融合通道维度信息(如目标与背景在特定通道下的特征响应差异、不同材质目标的通道特征区分),尤其适用于多模态等富含通道信息的检测场景 —— 例如在复杂场景目标检测中,可通过通道维度的精细关联捕捉目标(如金属构件、织物物体)与背景(如木质环境、塑料场景)在特定通道的独特差异,减少因空间外观相似导致的误检;同时,其二次复杂度设计保证了在处理高分辨率检测图像时的效率,避免因模型计算量过大导致检测速度下降,且位置先验能增强对目标局部细节(如目标边缘的通道渐变特征)的捕捉,提升小目标或模糊目标的检测精度。
在目标检测任务中:VolSA 可显著提升像素级分类的准确性,尤其适用于需结合空间与通道信息的精细分割场景。分割任务要求模型准确区分每个像素的类别,而 VolSA 的三维交互建模能力可同时关联像素的空间邻域信息(如分割边界的空间连续性)和通道信息(如不同类别区域在通道维度的特征响应差异)—— 例如在医学影像分割(如 MRI 多序列分割)中,能融合不同序列(通道)的组织特征与空间位置关联,精准分割病变区域与正常组织;在工业质检分割(如零件表面缺陷分类)中,可通过位置先验强化同类缺陷(如不同大小的划痕)在相似通道的特征一致性,减少因通道特征变异导致的类别混淆;此外,其全局三维关联建模能力可避免传统分割模型因局部感受野限制导致的分割边缘不连续问题,提升分割结果的完整性与平滑性。
3. YOLO与Volumetric Self-Attention的结合
将 VolSA 融入 YOLO 模型,可从两方面提升检测性能:一是增强 YOLO 对小目标、遮挡目标的特征捕捉能力 —— 通过三维(空间 + 通道)的全局关联,YOLO 能更充分利用目标在通道维度的独特特征,减少因空间信息不足导致的漏检;二是降低 YOLO 计算负担,其二次复杂度设计可在引入通道维度注意力的同时,避免模型推理速度大幅下降,兼顾检测精度与实时性需求。
4.Volumetric Self-Attention代码部分
YOLO11|YOLO12|改进| 掩码注意力Mask Attention,选择性强化图像关键区域特征、抑制无关背景信息,提高遮挡、小目标的检测能力_哔哩哔哩_bilibili
YOLOv11模型改进讲解,教您如何修改YOLOv11_哔哩哔哩_bilibili
代码获取:YOLOv8_improve/YOLOv11.md at master · tgf123/YOLOv8_improve
5. Volumetric Self-Attention到YOLOv11中
第一: 将下面的核心代码复制到D:\model\yolov11\ultralytics\change_model路径下,如下图所示。
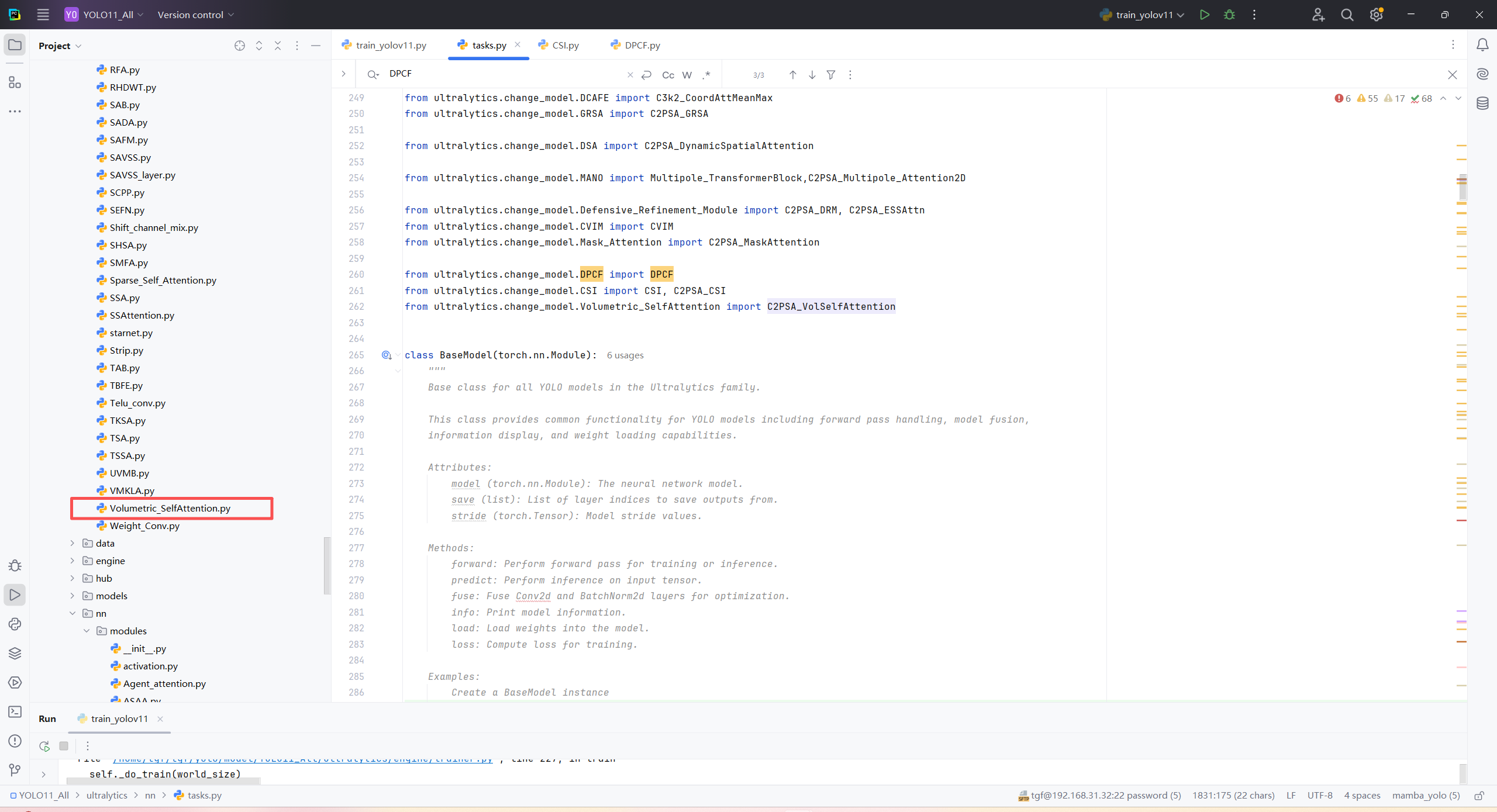
第二:在task.py中导入包
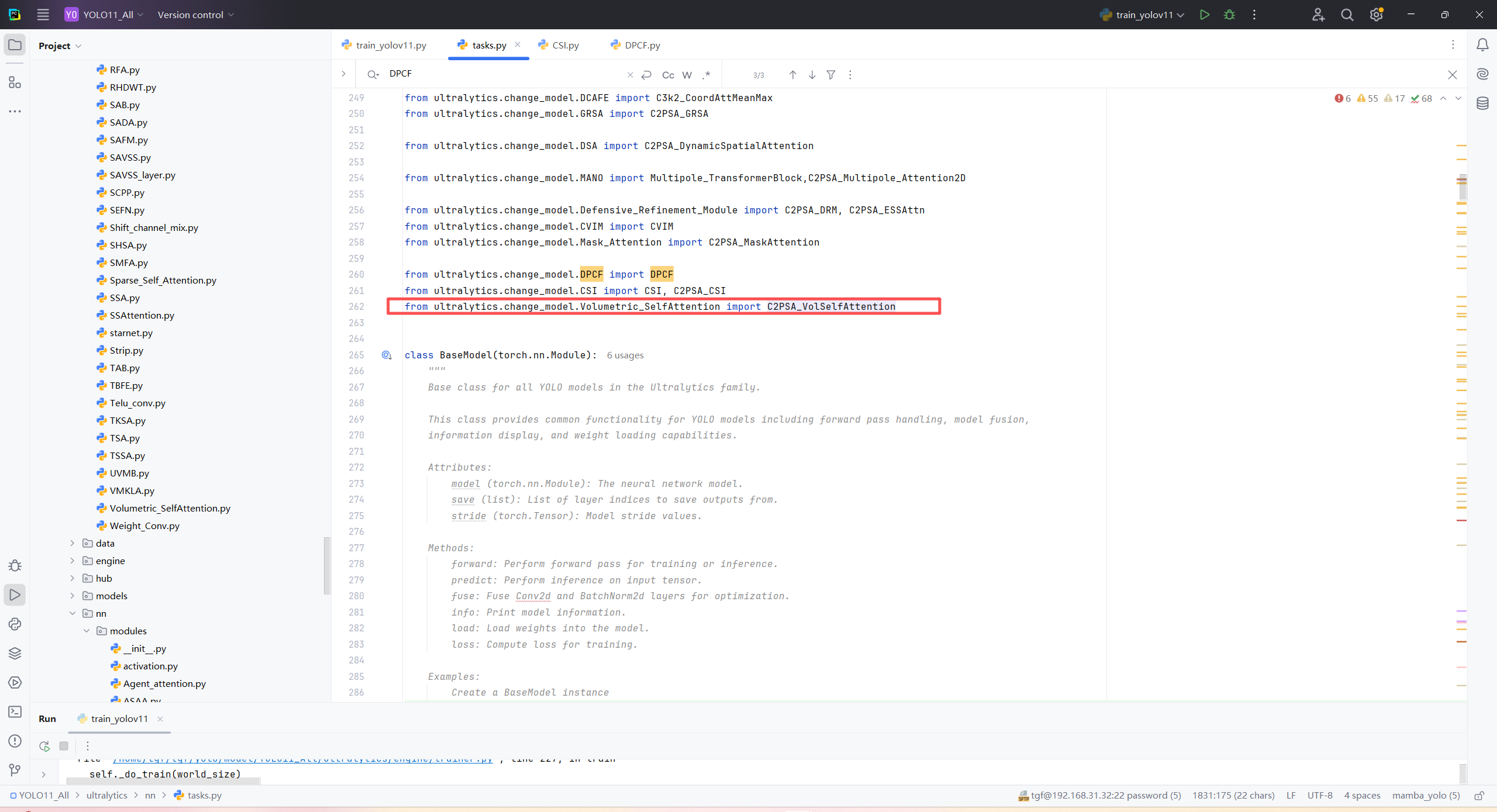
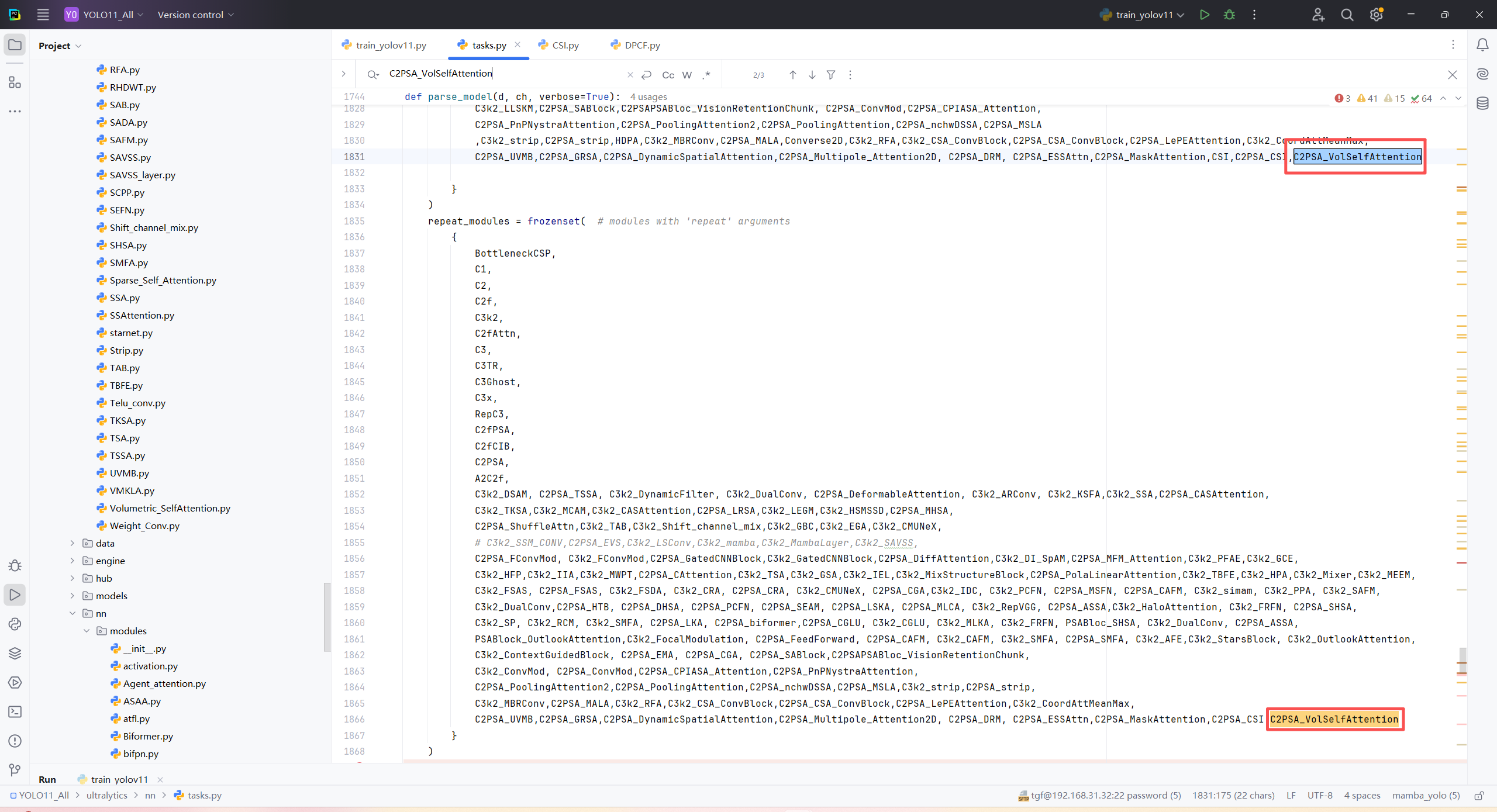
第三:在task.py中的模型配置部分下面代码
第四:将模型配置文件复制到YOLOV11.YAMY文件中
第五:运行代码
from ultralytics.models import NAS, RTDETR, SAM, YOLO, FastSAM, YOLOWorld
import torch
if __name__=="__main__":
# 使用自己的YOLOv8.yamy文件搭建模型并加载预训练权重训练模型
model = YOLO("/home/shengtuo/tangfan/YOLO11/ultralytics/cfg/models/11/yolo11_Volumetric_selfAttention.yaml")\
# .load(r'E:\Part_time_job_orders\YOLO\YOLOv11\yolo11n.pt') # build from YAML and transfer weights
results = model.train(data="/home/shengtuo/tangfan/YOLO11/ultralytics/cfg/datasets/VOC_my.yaml",
epochs=300,
imgsz=640,
batch=4,
# cache = False,
# single_cls = False, # 是否是单类别检测
# workers = 0,
# resume=r'D:/model/yolov8/runs/detect/train/weights/last.pt',
amp = False
)


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









