



1. 什么是warmup
- 定义:warmup是指在训练开始时使用较小的学习率,经过一段时间(如若干个epoch或steps)逐渐增加学习率,直到达到预设的学习率。这种策略可以帮助模型在初期避免大幅度的参数更新。
2. 为什么使用warmup
- 模型初始化:刚开始时,模型参数通常是随机初始化的,模型对数据的理解几乎为零。较大的学习率会导致模型在未充分理解数据的情况下,迅速做出较大的调整,容易导致“学偏”或发散。
- 逐步学习:使用小学习率可以让模型逐步适应数据特征,降低初期训练的不稳定性。随着训练的进行,模型对数据的理解加深,使用较大的学习率时更有可能稳定地收敛到有效的解。
- 局部最优:当接近目标时,使用小学习率能够减少对当前已知特征的“破坏”,从而更有效地找到局部最优解。
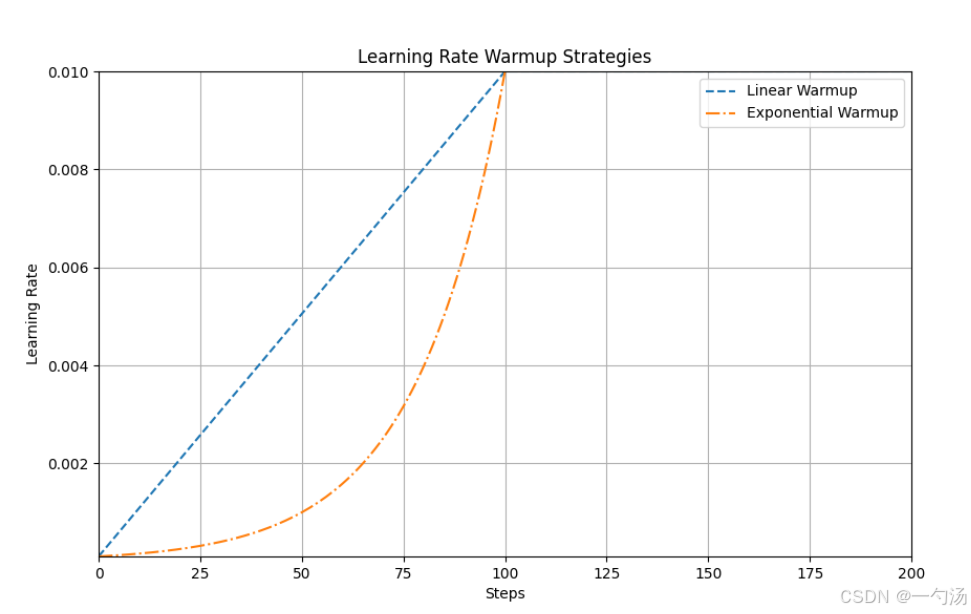
3.
在图中展示了两种学习率warmup策略:线性warmup和指数warmup。
-
线性warmup(以虚线表示):
- 从初始学习率(0.0001)开始,随着步骤的增加,学习率线性上升至目标学习率(0.01)。
- 在前100个步骤内,学习率逐渐增大,使模型在初期以较小的步伐适应数据,避免过拟合。
-
指数warmup(以点划线表示):
- 学习率同样从初始值开始,但其增长速率是指数级的。
- 在warmup阶段,学习率迅速提升,初期的学习速度较快,适合在模型已有一定知识的情况下进行快速收敛。
YOLOV8讲解与改进 一勺AI帅汤的个人空间-一勺AI帅汤个人主页-哔哩哔哩视频

















 3791
3791

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









