




应用层
在介绍传输层的UDP协议之前,我们先来介绍一下应用层,因为我们工作中,大部分都是在应用层和传输层进行编程
-
应用层在上一篇网络初识的时候其实已经介绍过了。这里再回忆一下,主要就是拿到网络数据包后决定这个网络数据包用来干什么。就像你网上买一个刷子。你拿到手后你就要决定怎么来应用这把刷子,可以用来刷玻璃,也可以用来刷碗。
-
每一层都有对应的网络协议,有了协议我们才能相邻层之间来传输数据。下层传递给上层数据包的时候,我们上层按照这一层相关协议格式解析数据包。
-
那么我们应用层也是一样的,如果想要解析传输层传上来的数据包。就要按照应用层协议解析,解析的过程会把网络传输中二进制的字节流(序列化)组装成遵守协议格式的数据(反序列化)。(这个过程好比我们网上买了一个床一般是拆散发过来的,我们用户收到后需要按照商家给的组装格式说明组装成一张完整的床)
-
除了可以按照应用层本身有的协议格式解析。我们程序员也可以自定义协议来解析数据包。如何设计自定义协议呢?
-
比如我们要开发外卖平台的某个功能,其实就是客户端和服务来实现,实际上就是前端和后端交换接口的设计,这个时候会开会让前端和后端都来。讨论下面内容
- 根据需求,需要交互的数据有那些
- 组织数据的格式是什么。

- 以实现外外卖平台主页功能的例子来说明,我们打开外卖平台的主页。通常会看到那些数据?肯定有:商家名称,商家距离,商家评分,图片等等数据吧。(这些数据一般都是按照客户的需求来收集的,例如客户的需求是尽量先显示距离点餐用户近的商家,那么我们就会先会收集离点餐用户距离近的商家数据)
- 那么这些数据用什么格式来组织呢?(这个就由我们程序员怎么方便怎么来设计了)
第一个常见的方案就是使用xml格式来组织数据(这种格式使用成对的标签来组织数据)

-
优点
- 可读性较高,通过标签文本我们可以明显看出标签内的数据是属于哪一个方面的数据。比如1234的标签就是userID(用户ID)的数据。
- 可扩展性较强,对比HTML语言只能使用官方提供的标签,而XML可以自定义标签。
-
缺点就是传输效率较低。因为我们传输数据需要使用网络,网络传输数据就要使用带宽,网络带宽是服务器最贵的硬件资源。XML这种成对的标签就会导致比单标签的多一倍的内容。所以比较耗网络带宽,带宽满了就传输效率较慢,传输效率就比较低
第二个常见的方案格式就是JSON,这也是我们工作中常用的方案

- 他的格式就是这样用,用一个单标签来组织数据,区分了这个数据是属于哪个标签。与XML相比单标签保证了可读性的同时,JSON不再使用双标签,那么在传输的时候就要比XML少一个标签,那么使用的网络带宽就比较少,网络带宽没被占满,那么传输速度就快了。这样他的传输效率就比较高
第三个常见的方案就是google protobuf,他在节省网络带宽方面进一步做了优化,在性能要求高的场景下常用
- 他的数据组织格式是一个二进制数据的格式,这个我们就暂时不研究了。
- 优点:非常节省网络带宽,把这些数据都压缩成了二进制。
- 缺点:可读性很差,二进制格式非常难以区分那部分的二进制是属于那部分的数据
传输层
介绍了应用层,我们接下来介绍一下传输层。而传输层有一个很重要的协议叫做UDP协议,接下来介绍他的内容和原理。
UDP协议的特性
- 无连接。也就是发送端和接收端之间并不会相互保存对端的信息。
- 不可靠。使用UDP协议发送数据包,UDP协议把数据包发送出去后就不会管这个数据包了,不关心他是否丢失或是否到达。
- 面向数据报。使用UDP协议读写网卡中的数据,必须是以数据报为基本单位。这里数据报传输就是好比传快递,无论大小UDP必须打包成数据报箱子的快递。而TCP面向字节流,他就是多大多小都能按照适合的长度来打包,大的用大箱子,小的用小箱子。但是一定注意:他不是无限制大小传输((有MSS, 最大报文长度)只是可以发送任意大小的数据包.不需要像UDP一样发送固定大小的数据包。毕竟再大也不能超过网络带宽传输的大小/mark>
- 全双工:也就是在同一个时间,既可以进行读操作,也可以进行写操作。好比我们双向车道,既可以往x方向开车,也可以往y方向开车。
UDP数据报的格式
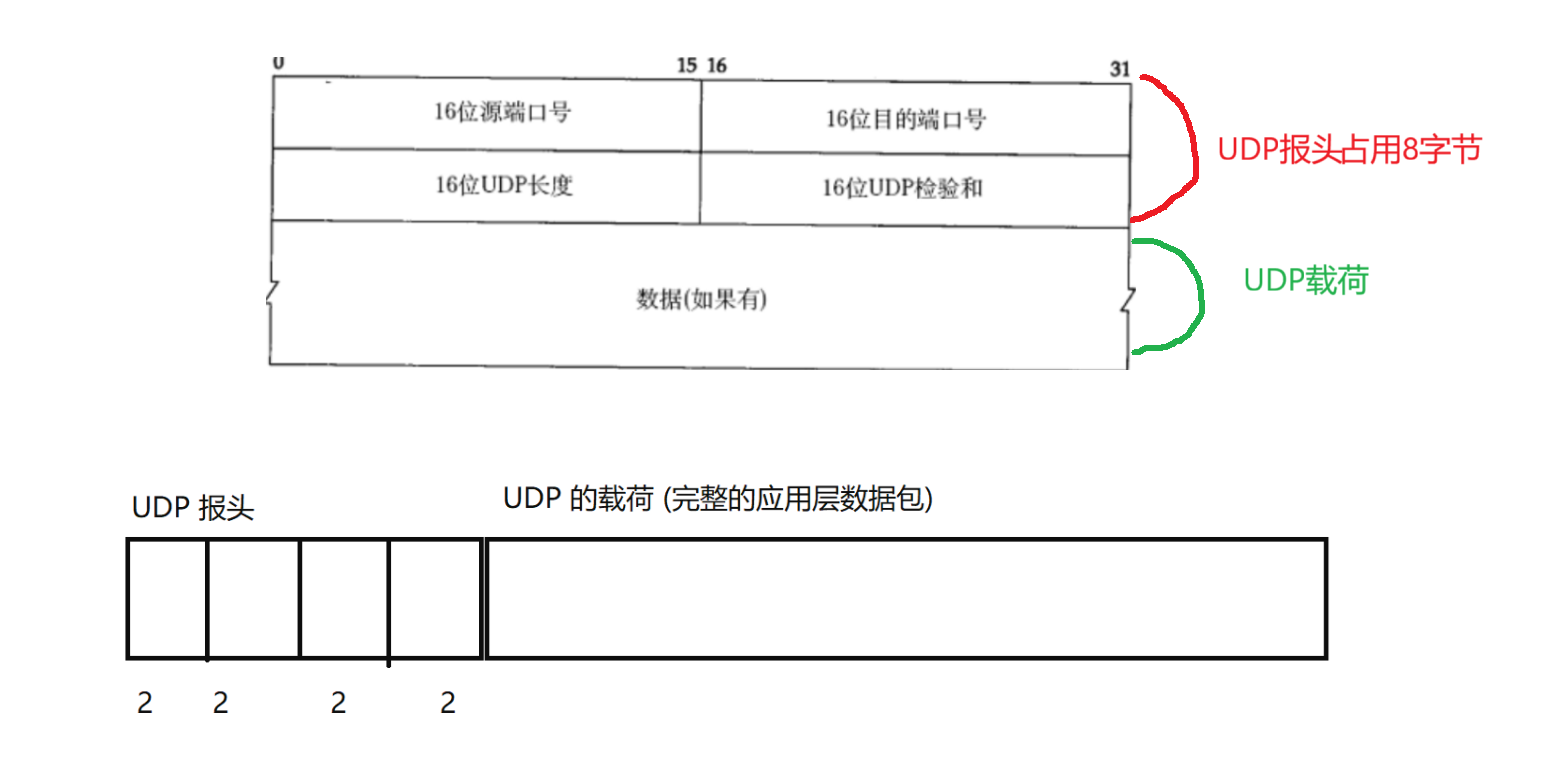
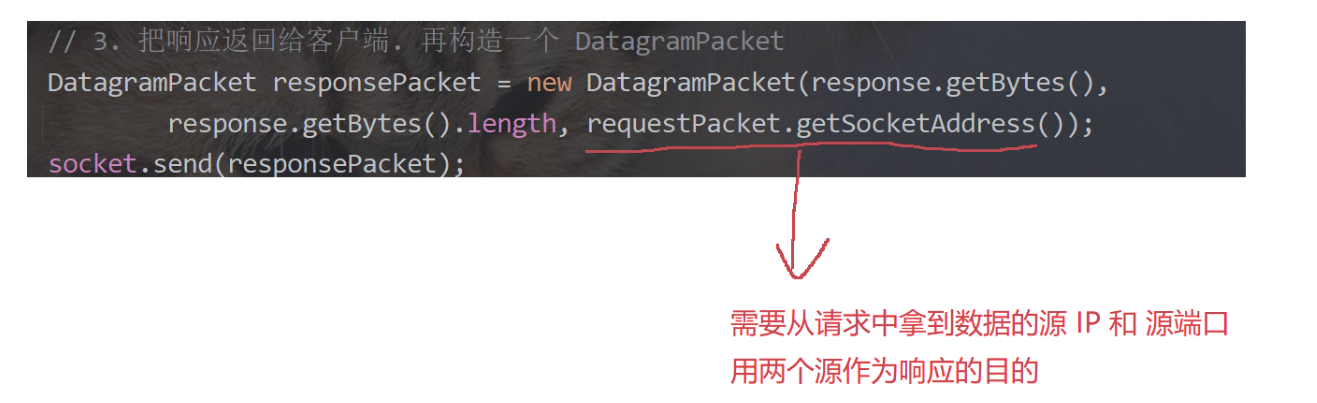
- 其中16位源端口号和16位目的端口的作用:UDP服务器从UDP客户端发送的请求数据报中拿到源IP和源端口,构造响应数据包把他们作为目的IP和目的端口的,这个时候需要这个源IP和源端口来返回给指定的主机(源IP负责找到)上的指定程序(源端口负责找到)
- 注意我们端口号的内存占用2个字节16个bit位,那么我们表示最大范围也就是2个字节全为1的时候表示的数字65535。其中0-1023是知名协议使用的端口号,1024-65535由操作系统自动分配的端口号,可以用于其他的进程和自定义协议使用。
- 这个时候端口号还有两个问题要介绍:
- 一个进程是否可以绑定多个端口号?答案是可以的,其实是socket绑定到一个端口号。这是因为我们一个进程(服务器上)通常可以提供不同的服务,如业务端口,管理端口等。
- 一个端口号不能被多个进程绑定,因为端口号是网络中区分不同进程的标识。
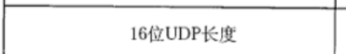
- 这是UDP数据报的总长度,UDP报头固定是8个字节。
- 这个总长度是16位二进制标识的数字,这个数字的单位是字节,那么算出这个数字减去报头固定的8个字节,剩下的就是载荷所有的部分,16位表示的最大数字是65535字节(二进制位全为1),意味着我们整个UDP数据包最大的能存储64kb
- 这个能存储数据的长度,如果是在互联网最早期还是完全够用的。那个时候1MB的内存都非常高了。但是到了现在,我们随便拍一张照片都是随随便便的几MB,那么这个时候64KB就完全不够看了。那么这个时候问题来了,如果说我们现在使用UDP协议传数据包。该如何传大于64kb的数据呢?
- 方案1:因为我们传输层是从应用层拿数据包进行封装传输的。这个时候我们从应用层拿这个大于64kb的数据肯定不行,这个时候就需要在应用层进行拆包让UDP传输后又在对端的应用层进行组包,就好像你一囫囵个的跑步机是无法让快递直接一个快递传输的,这个时候就需要把囫囵个的跑步机拆成多个零件分成两个快递传输(拆包),那么你收到的快递就是2个,这个时候你需要打开两个快递进行组装跑步机(组包)。不过这个方案也是有很大的缺点的,那就是网络传输中很有可能出现丢包和顺序错乱的情况(UDP不可靠不会重传和排序),这个时候就需要我们自己在应用层写代码实现,在应用层实现这个代码逻辑是非常复杂的
- 方案2:那就是换成TCP协议,TCP协议是面向字节流传输的,也就是说传输数据没有限制,不过需要注意的是预估你传输的一个完整的数据包是从那个字节到那个字节(不然会出现粘包问题,TCP详细讲)

- 这个比较我们传输的UDP数据包中的数据是否出错。因为我们网络传输中非常有可能出现数据被修改的情况(有可能给你改少,有可能会给你改多)。那么如何来解决这个问题呢? 我们UDP在发送数据包之前会把数据都带入到一个数学公式里面计算。得到这个叫做检验和的东西。然后进行传输,传输到对应的主机应用层后,那么我们主机会把UDP数据包里面的数据重新带入到同样的公式里面去,如果得出的结果和这个校验和一样,那么说明我们的数据并没有发生修改。只要是数据修改了,那么得出的结果大概率是不一样的。(小概率会出现数据被修改但是结果一样的情况)

















 690
690

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









