




目录
什么是HTTP
- HTTP中文全称超文本传输协议,工作在应用层。文本我们都知道就是这些英文或汉字这些文本,超文本的则是图片,连接,音视频这种内容。所以我们HTTP协议的功能非常的强大,可以传输这些超文本的内容
- HTTP采用一问一答的模型:类似你在餐厅点餐。你:“服务员,来份炸鸡!”(请求),服务员:“好的,马上来!”(响应),http协议就是这种一问一答的模式,客户端发出一个请求,然后服务器回一个响应。
- HTTP协议工作在应用层,前面我们在介绍传输层TCP协议和网络层IP协议的时候这两层的主要任务都是在想办法把数据包传输到应用层。就好比我们网上买一个手机,货车司机和快递小哥都在努力尽快把手机传输到我手上,送到了就可以了吗?当然我要用啊!如何用就是在应用层实现,HTTP是应用层的一个重要协议。
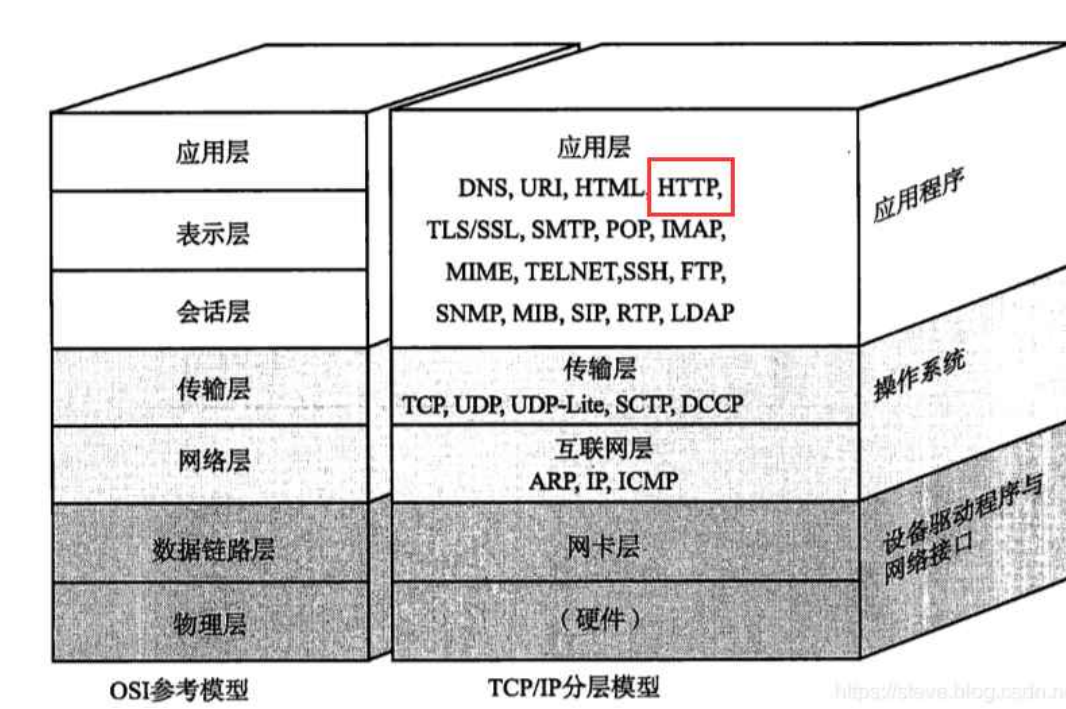
HTTP的工作流程
- (你)客户端->请求->服务器
- (你)客户端<-响应<-服务器
- 这里我们说了我们HTTP工作采用一问一答的模型
这里补充一点HTTP协议是原本是依赖TCP协议的, HTTP3.0开始,由于TCP传输效率太慢的问题HTTP3.0把TCP换成了UDP(前面说过传输效率很高),为了补充UDP可靠性的缺点,HTTP在应用层自己实现了可靠性。
HTTP协议格式
Fiddler抓包工具
- 为了学习HTTP协议格式,我们可以使用这个工具来抓取HTTP数据包查看HTTP数据包的具体格式。
- 那么如何理解这个抓包工具呢?他为啥可以进行抓取HTTP数据包呢?
- 因为抓包工具通过读取网卡的,从而让你看到当前的请求和响应的数据明细,本质上抓包工具相当于“代理”。那么什么又是代理呢?
正向代理和反向代理
- 正向代理是我们客户端这里要经过的,客户端往这服务区发送请求数据包。这个时候呢会经过正向代理转发。而反向代理则是服务器哪里的,请求发送过去后第一个拿到手的并不是服务,是反向代理。反向代理会转发给服务器。服务器返回响应数据包流程一样。
- 如此一来,正向代理和反向代理都拿到了发送的请求数据包和响应数据包,即都清楚请求和响应的具体内容和格式。
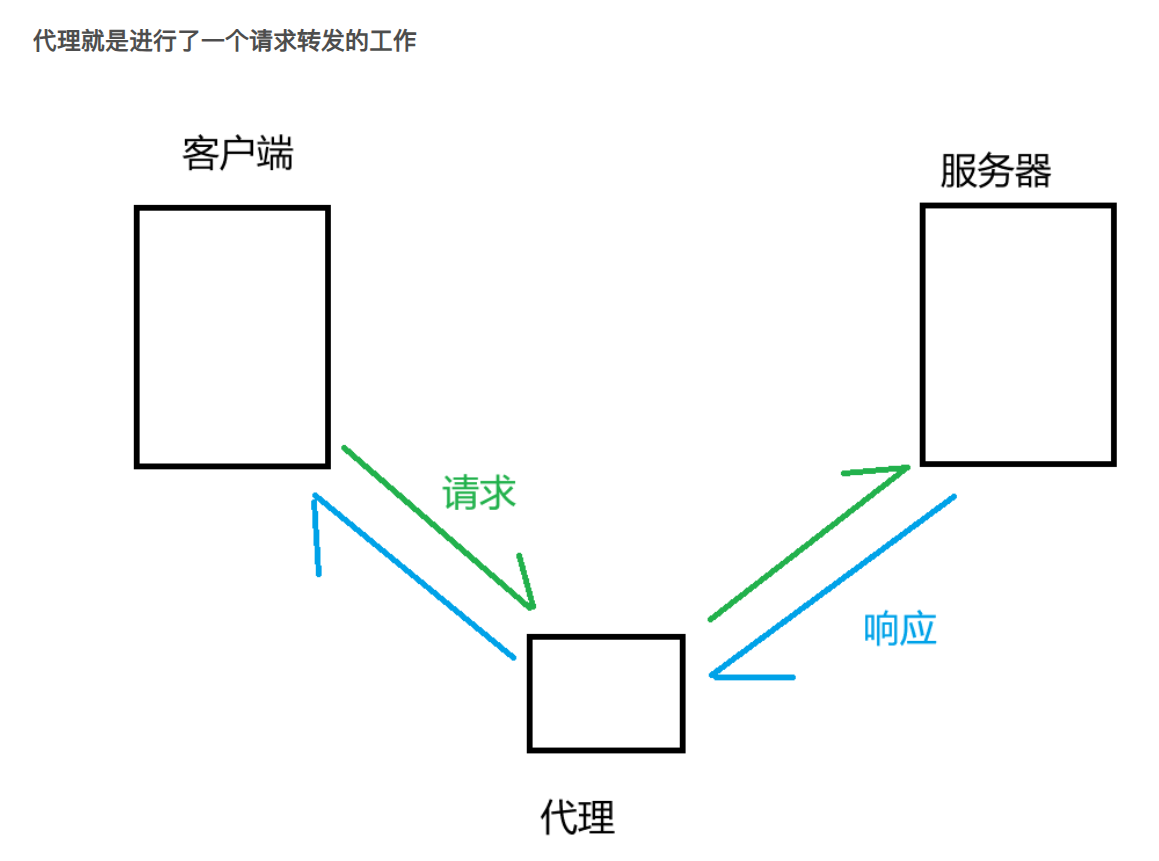
- 这就类似于我(客户端)买脉动懒得下楼就叫女朋友去帮我买脉动,这个时候我的女朋友就知道我的请求是什么。这个时候超市老板也是个懒人,我女朋友说要买脉动,他叫他儿子去拿。这个时候他儿子也知道我的请求和超市老板(服务器)的响应(返回一瓶脉动)
- 其中我的女朋友是正向代理,超市老板的儿子是反向代理。他们都知道具体的请求和响应
抓第一个HTTP数据包
- 安装好抓包工具后,我们打开b站发现有一个关于他的数据包。点击我们右侧的RAW标签界面,这是我们数据包原始内容格式界面。可以看到上面是请求,下面是响应。
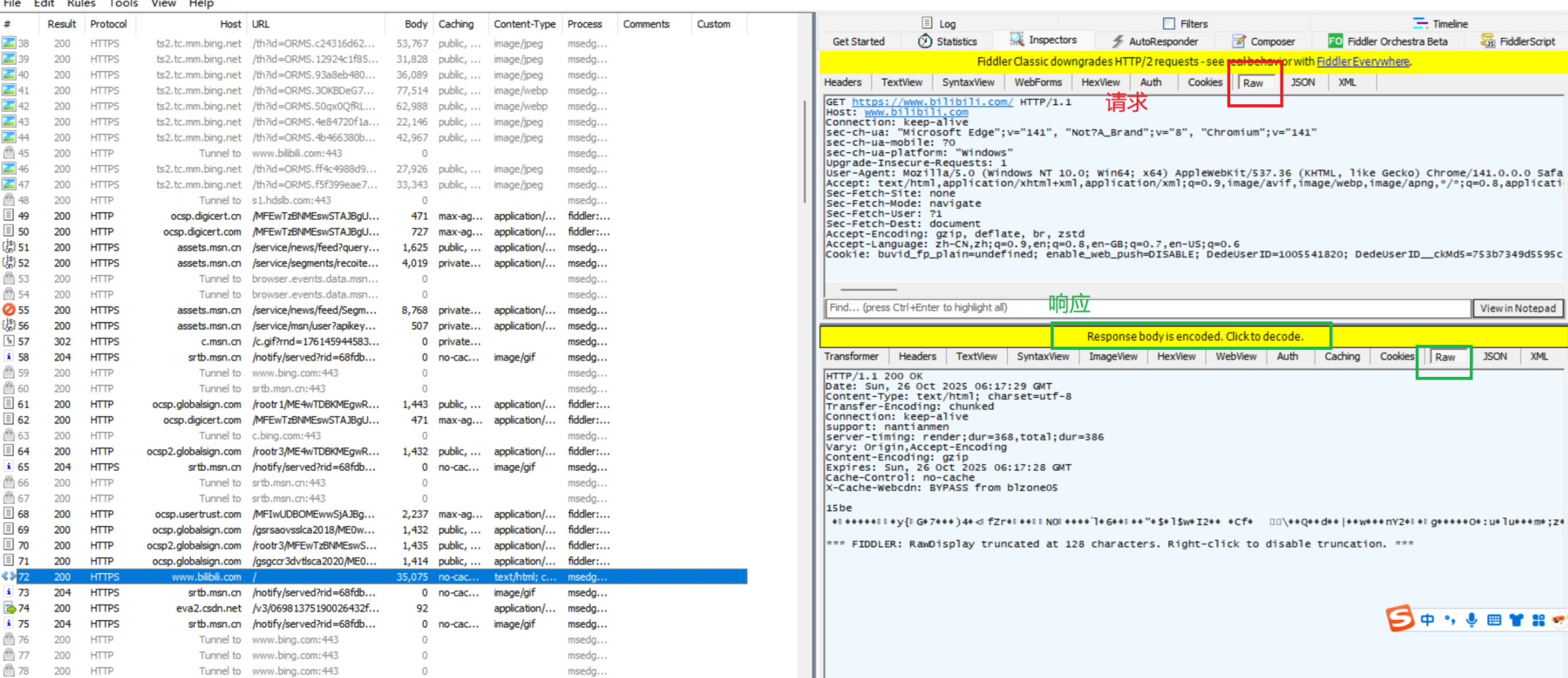
请求的格式
- 我们先看看b站的请求数据包的格式
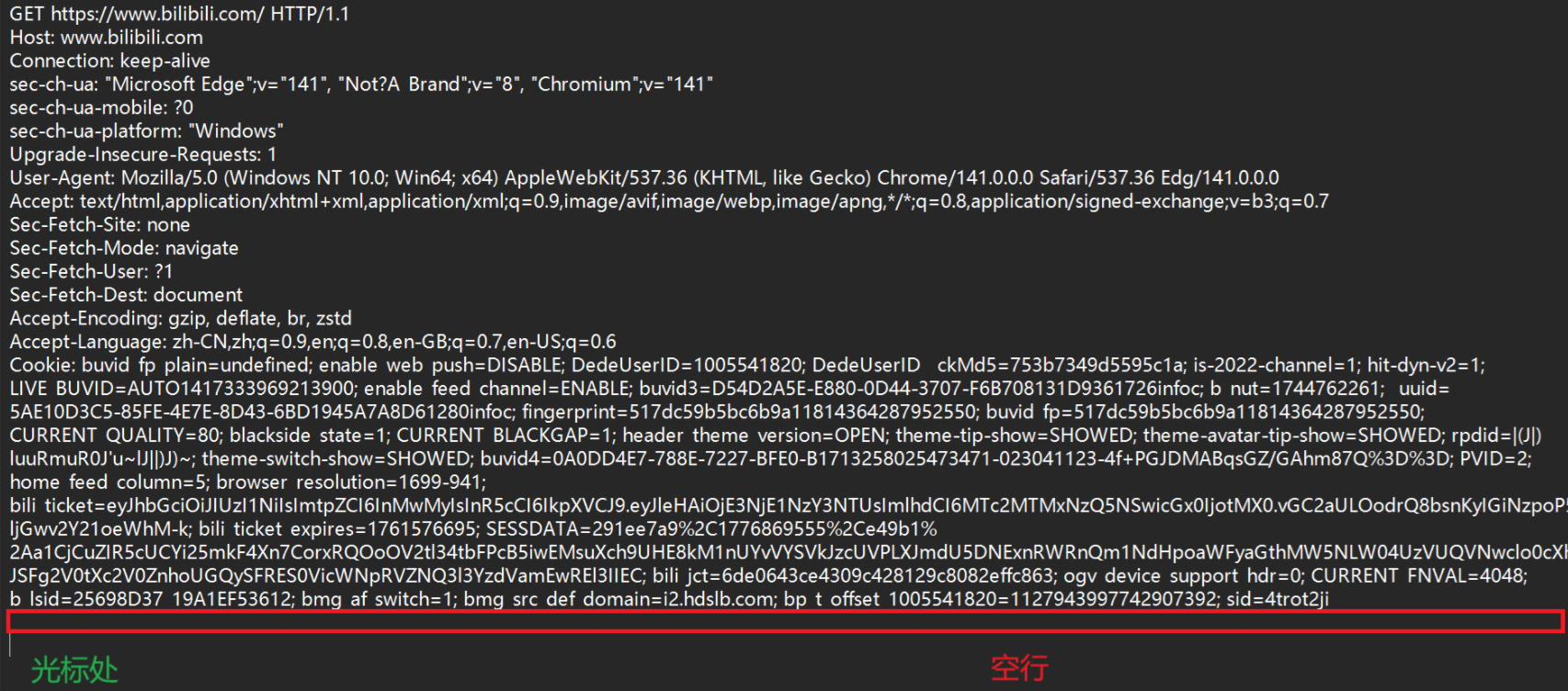
- 通过上面的格式可以总结出,请求数据包的格式是这样的。
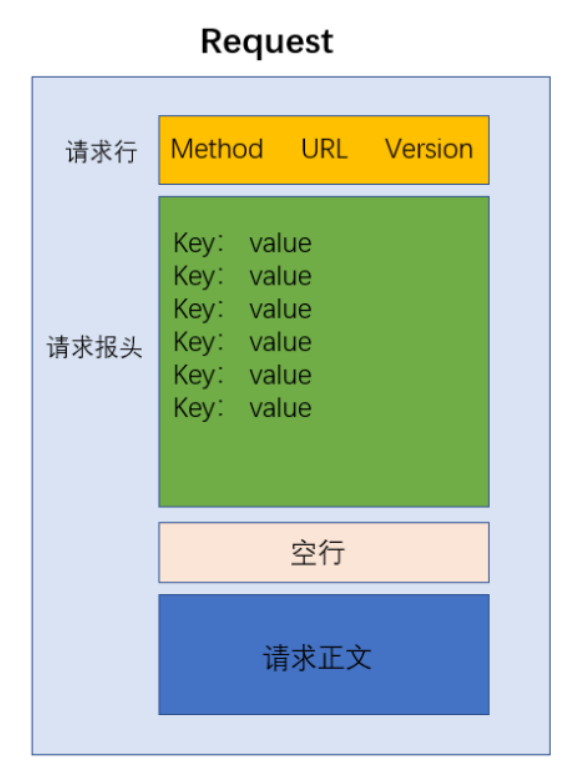
请求行

URL(唯一资源定位符)

- 我们在请求行中的URL对于这部分,这个东西相信对应上过网的同学很熟悉吧。通俗的名字就是叫做网址,用于定位网络上的某一资源。具体的格式应该是这样

- 其中的协议方案名就是我们的协议类型,这里不光有http, 现在都是常用https(后面会讲),登录信息认证一般不会出现了。
- 服务器地通常就是我们的域名,带着服务器的端口号标识服务器上的具体端口。这里的端口号如果没有写会默认加上一个车端口号,是协议的端口号,比如http就是80, https就是443
- 带层次的文件路径这个参数是为了让服务器管理资源方便,通过文件来组织这些资源。如果说我们客户端请求有这个东西,那么服务器就可以通过这个文件路径快速找到这个资源并返回给客户端。这个带层次的文件路径有可能是真实存在服务器上的硬盘资源。也可能服务器硬盘没有这个资源,但是通过这个层次文件通过一系列的逻辑代码也可以给你返回需要的资源。总之核心作用就是为了帮助服务器定位资源。
- 对于query string(查询字符串)则是我们客户端为了向服务器提交一些数据的内容。里面的格式是采用键值对组织?表示查询字符串从这里开始,&区分每个键值对。=区分键和值

- 这里要注意query string中的键值对是可以由程序员自己定义的。与之相反的是报头中中的键值对,他们是HTTP协议规定好了只能有那些键值对‘’。query string的内容通常是前后端交互接口的需要传输的内容,这些意思只有前后程序员知道。
- 对于片段标识符,他的核心作用就是为了一个页面中不同的片段内容。类似于我们优快云的目录功能,点击哪一个标题片段就可以自动定位到对应的片段内容。想体验的可以去Vue官网体验一下:

综上所述:IP地址,端口号,带层次的文件路径,查询字符串就可以描述出一个网络上的资源位置了
IP地址:描述网络中的服务器位置
端口号:描述服务器中对应的端口服务(进程)
带层次的文件路径:描述进程中的存储资源的位置
查询字符串:补充的信息(类似蛋炒饭请求补充不加葱花)
URL encode
- 对于我们的query string来说,很多时候需要转码。因为queryString键值对是程序员自定义的,在URL中(/,:,?,@)这些符号通常都有特定的含义(例如/是跟着协议名),如果不进行转码,浏览器把这些解析出错了,那就会报错了。这里不光针对这些特殊符号进行转码,还会对汉字也进行转码。因为保不齐那个汉字的utf-8/GBK的值就和我们URL中的特定符合的ASCII码一样,这就会同样解析出错。
- 那么到底如何转码呢?这里就是采用我们的URL encode了,把汉字/特殊符号的ASCII码转换成16进制并且前面加上一个%. 汉字通常是UTF-8,就把UTF-8的值转成16进制,前面加上%即可
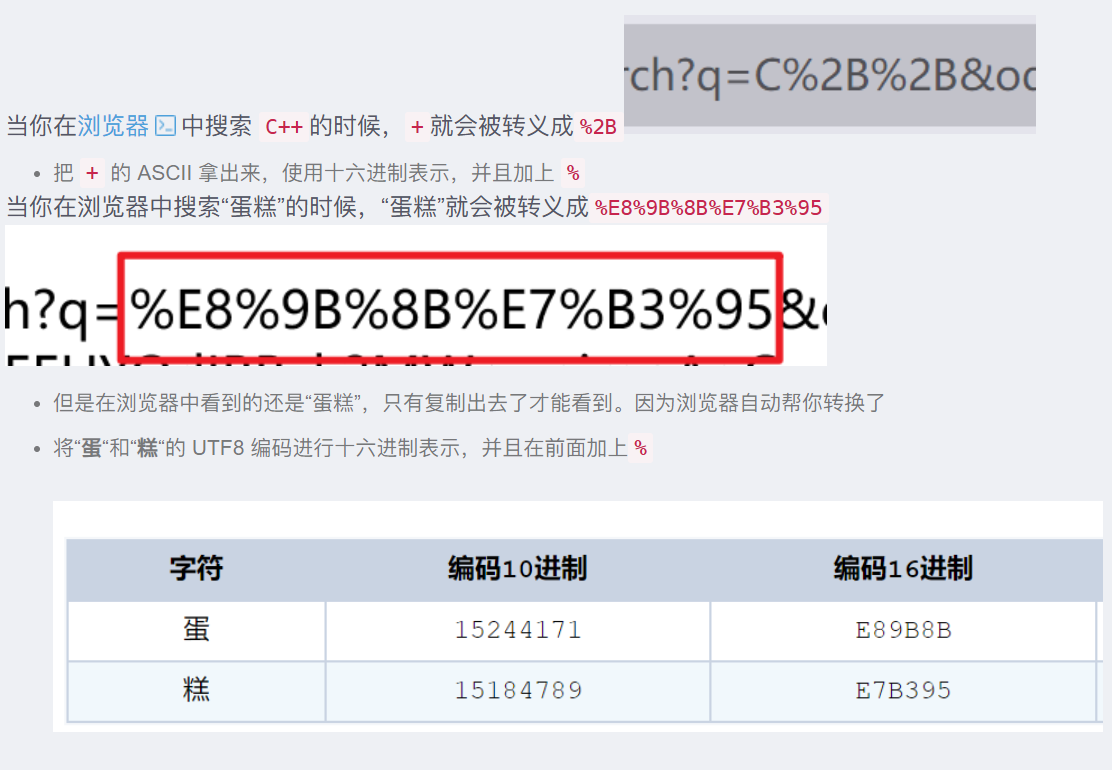
- 这里的 URL encode 是非常重要的。在实际开发中,当要构造一个 URL,尤其是 URL 的 query string 中要包含中文的时候,务必要进行编码!!!
请求方法

- 请求方法有很多我们只需了解最常用的即可
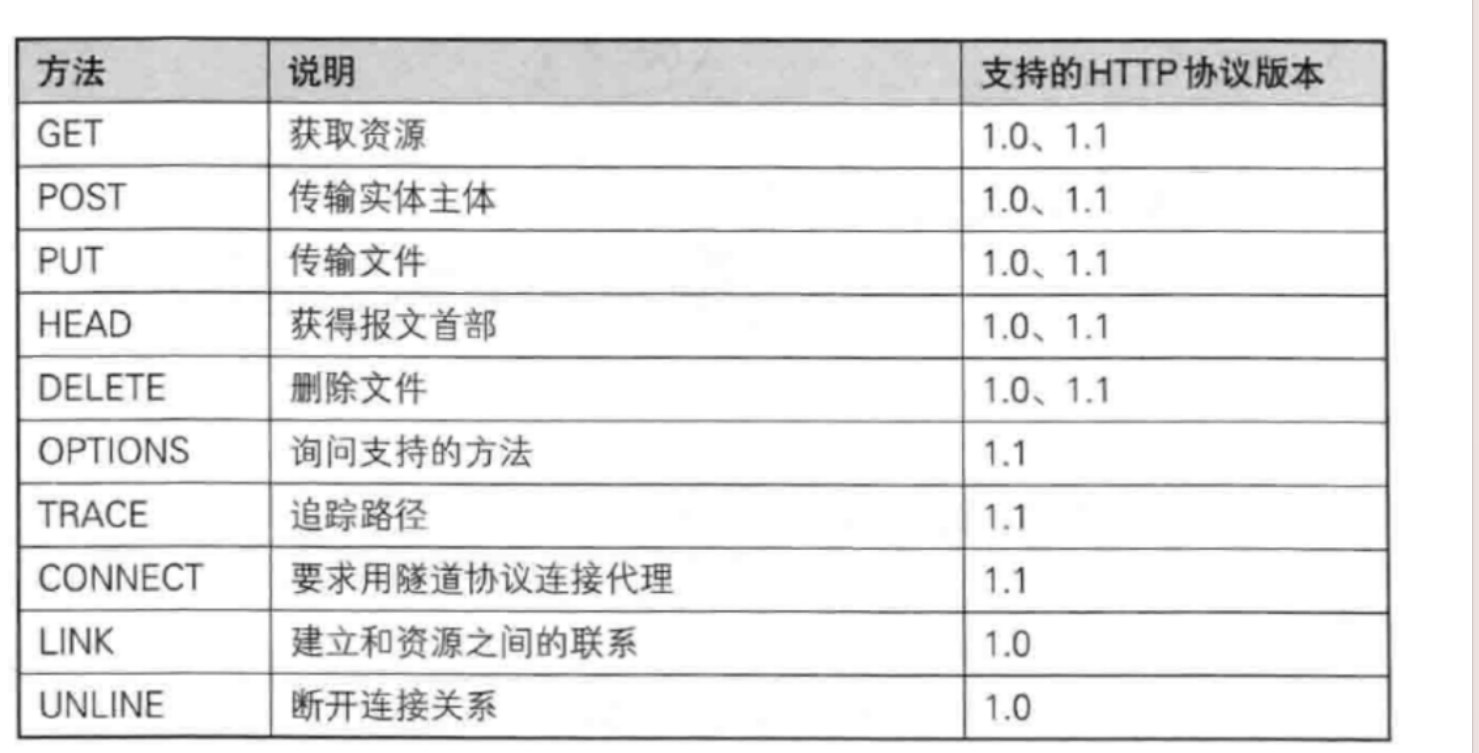
-
GET方法的意思很简单,就是表示获取服务器上的某一资源。他的特点就是是用get方法的请求通常没有body(正文)部分,这一点我们在上面抓取的b站的请求数据包就可以看出来。
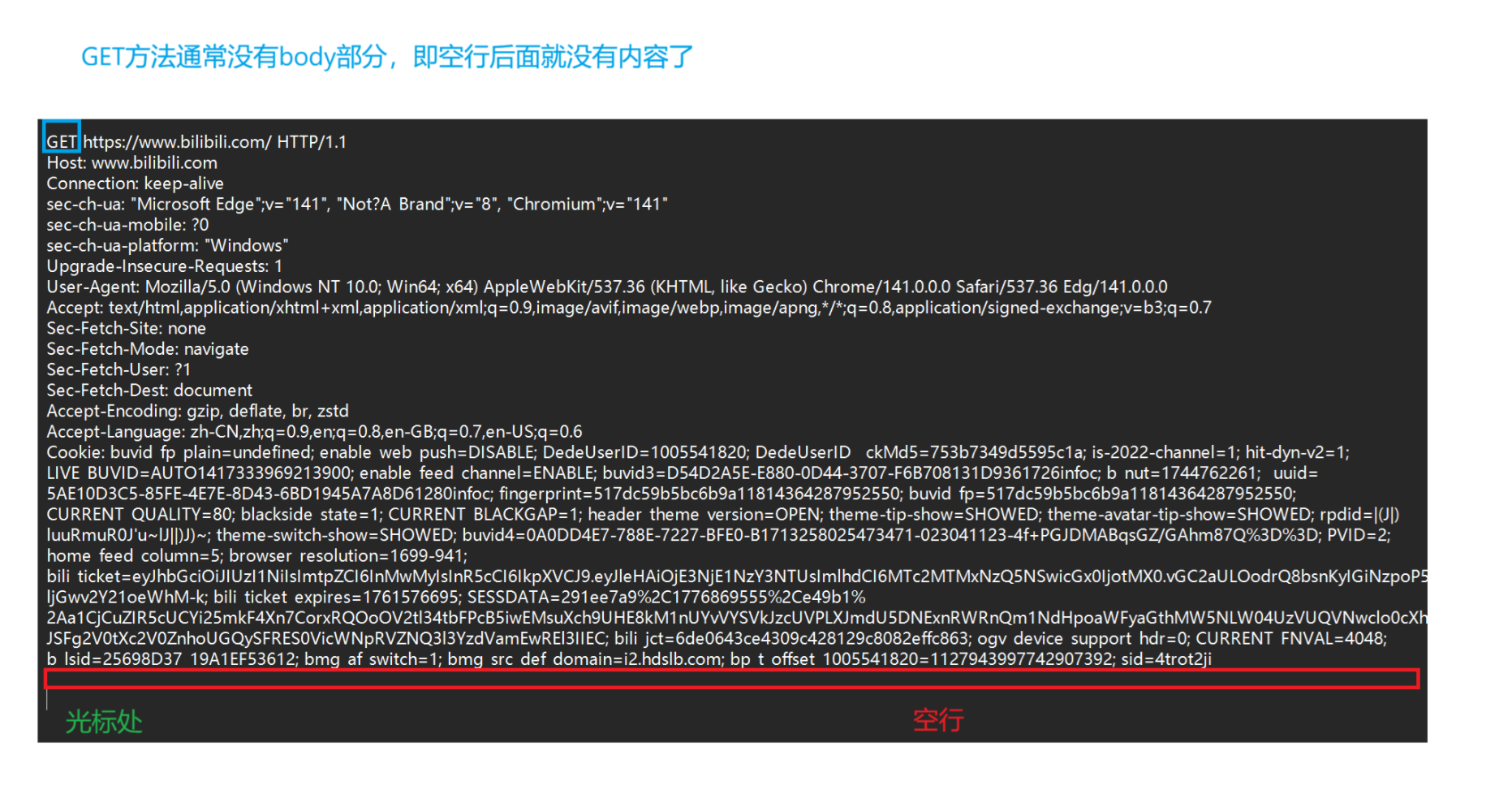
-
但是准确的来说,get方法可以有body。只是通常没有,这里再补充一下body的内容也是程序员自定义的
-
GET方法获取网络上的资源的时候,可以通过query string 和带层次的文件路径来补充说明需求(例如需要哪里的资源
-
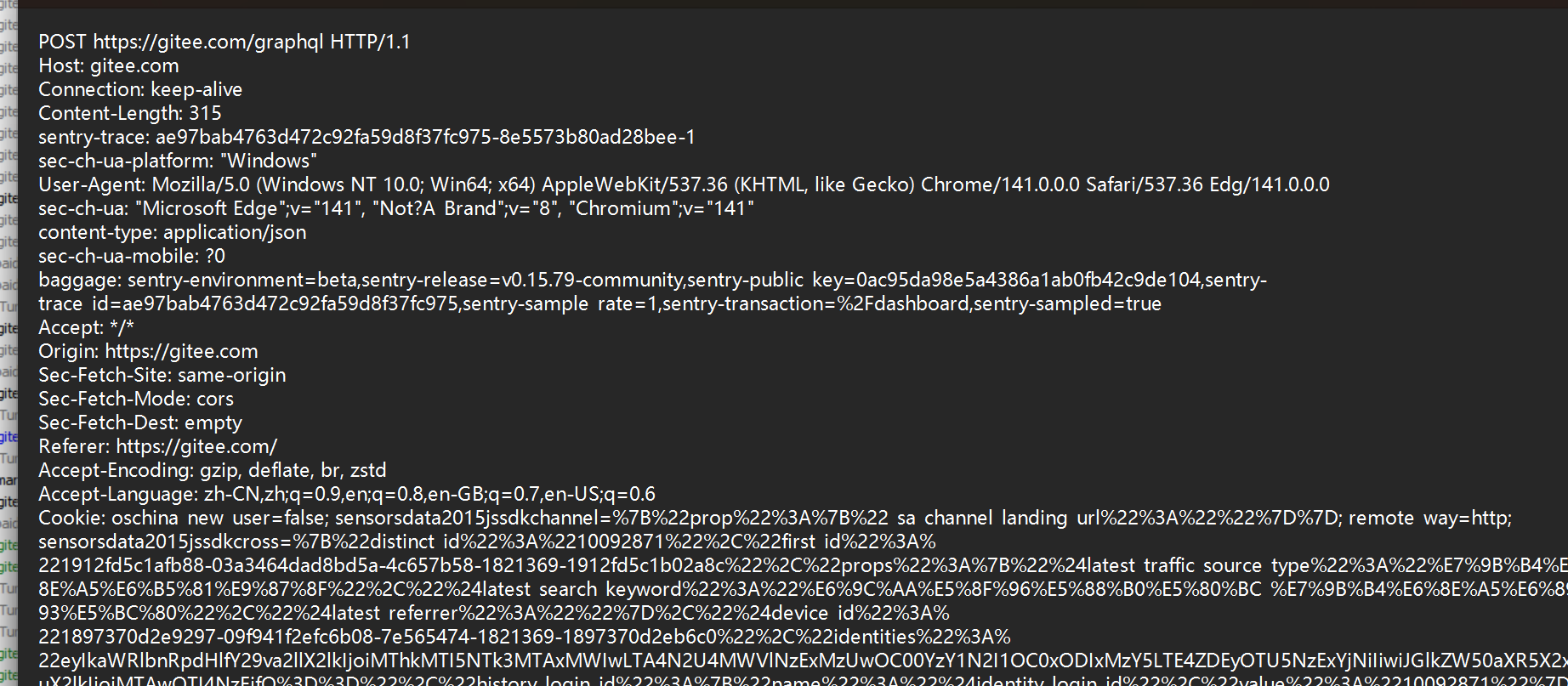
除了GET方法是经常出现以外,还有一个POST方法也是经常出现。他的语义是向网络中传输资源。
-
通常有两个应用的场景:一个是登录的场景,需要向服务器传输账号和密码进行验证。一个是传输文件的场景。
-
POST方法通常用于传递资源给服务器,他的query stirng一般情况没有内容的,如果对传递给服务器资源的时候有什么补充的内容是通过body来传输的。
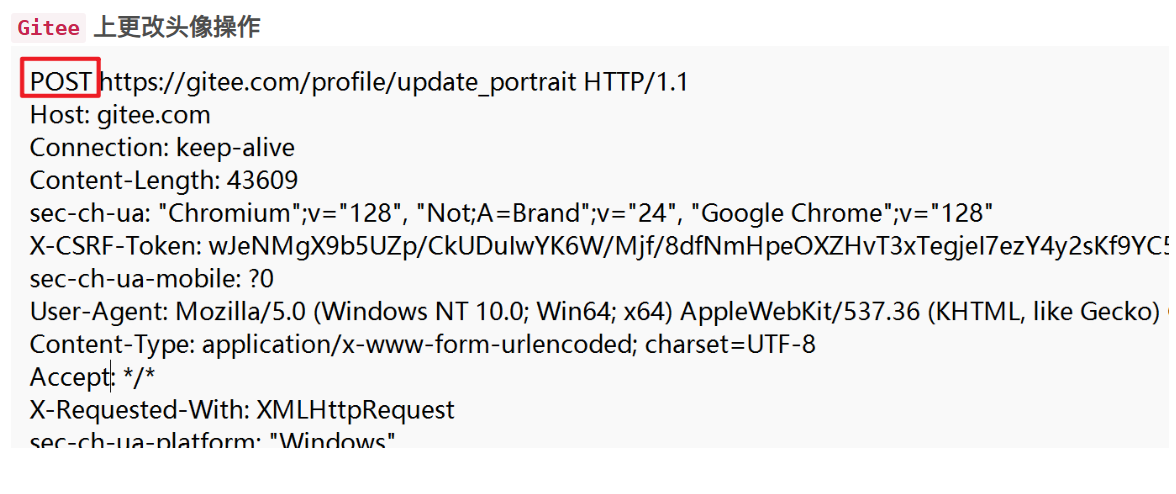
-
body 部分就是图片的内容,图片本身是二进制的,此处是对二进制的图片数据进行了 base64 编码(很长很长的数据)。后来HTTP的body也支持二进制传输了,但是这个做法被保留了下来

GET和POST的区别(高频面试题)
-
我们一定要回答:POST和GET本质上没有区别,GET能做到的POST能做, POST能做到的,GET也能做。
-
但是在使用习惯上POST和GET还是有区别的。
-
GET语义是获取资源,常用于获取服务器的资源。POST语义是传递资源,常用于传输资源给服务器
-
GET通常用query string来传递数据给服务器, POST通常用body来传递数据给服务器。当然GET也可以用body, POST也可以用query string
-
GET请求一般是幂等,POST请求没有幂等要求。解释这个之前我们要知道什么是幂等:每次输入的内容一定,输出的结果也一定,称为幂等;每次输入的内容一定,输出的结果不一定,就不是幂等。
通俗举例:就像我们奶牛吃草一样,每次挤出来的都是牛奶是吧。如果每次挤出来的是另外的东西(这里不好详细说,你懂得)。那么我们就说这个不是幂等的操作。所以在这里我们GET请求一般是幂等就意味着我们每次请求的结果都是一样的,但是现在我们实际上不一定是这样的,比如我们b站上每次刷新网页(就是GET服务器资源)的结果都是不一样的,他是基于大数据推荐返回结果给我们。
那么我们结果幂等有什么作用呢?如果每次结果都是幂等(一样的),这意味着我们可以把这个幂等结果缓存起来,如果很多用户需要这个结果我们就不需要去给每一个客户都重新算一遍了,这就节省了我们的CPU资源。就好比我们第一次算1+1, 想了半天才算出来,过后几天每天算一次1+1都是2,过后潜意识听到1+1就知道是2不用再让脑子思考了。
- GET是不安全的,POST是安全的。这种说法是完全错误的!很多人认为GET是不安全的是因为我们在传输数据给服务器是用URL中的query string, 浏览器地址栏可以直接看到query string中的内容,里面可能包含了用户账号和密码。认为POST是安全的是因为我们POST传输数据给服务器是用body,body是HTTP数据包里面地址栏并不能直接看见。这样的认知是错误的,这并不代表安全和不安全
- 那么到底是怎么区分安全和不安全的呢?所谓数据安全都是通过加密来实现的,关于加密的详细介绍我们在HTTPS协议中详细讲解。如果不加密就算我们的用户账号和密码在body中,那么我们黑客通过抓包工具吧HTTP数据包抓到了一看body里面的内容也会知道用户账号和密码。
- GET传输的数据长度比较小,而body传输的数据长度比较大,这种说法也不算完全正确或错误。这是因为前期IE我们微软使用的IE浏览器是对GET传输的数据长度限制较小,现在IE浏览器已经被微软的edge(本质上是Google的Chrome套壳)替代了,现在的浏览器能支持的传输数据长度和body几乎没有区别
- GET只能传输文本数据不能传输二进制数据,POST既能传输文本数据也能传输二进制数据。这种说法也不够正确GET的query string的确不能传输二进制数据,但是可以通过URL encode或者base64编码把他转换成文本数据啊。所以准确来说GET也可以传输二进制数据
请求报头
Host
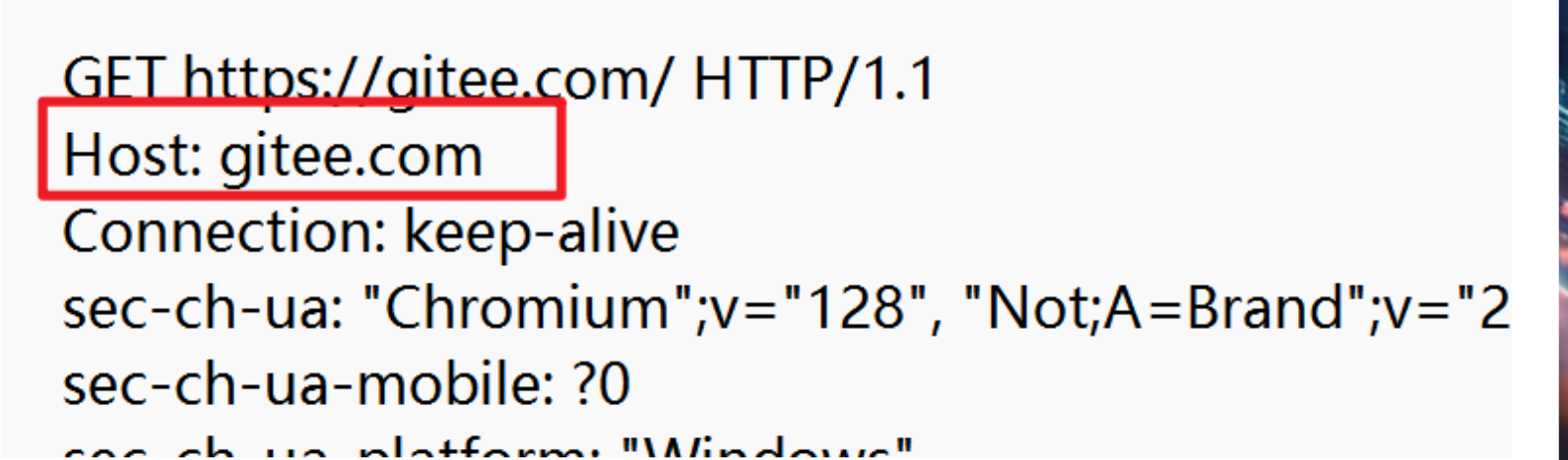
- Host这里就是地址和端口的意思。对于端口:这里通常是填写服务器的端口,用于标识我们HTTP请求的是服务器的那个端口。如果没有填写端口,那么默认会使用协议的默认端口号,这里HTTP端口号是80
- 这里的 Host 和 URL 中的 IP 地址、端口什么的,绝大部分情况下是一样的,少数情况下可能不同
- 当前我们经过某个代理进行转发。过程中,URL 中的 IP 指向的是代理服务器的 IP;Host 中的 IP 指向的是最终目标的地址
Content-Length和Content-Type
这两个字段都是和body密切相关的
- Content-Length这里就是描述了我们body的长度是多少,防止服务器读取body的时候出现TCP同样的粘包问题,如果没有这个字段描述,那么服务器就不知body到底读多少才算完。
- 如果说没有body部分,那么因为我们body前面有空行分割请求报头和body,那么应用程序读到空行后没有数据了,就默认没有body结束了。
- 但是如果有body部分,我们读到空行后面还有数据,因为HTTP底层也是基于TCP的,那么如果是基于TCP的就是字节流传输数据,哪到哪才算一个完整的数据包呢。Content-Length描述了我们body长度到底有多长,读完后整个包就完成了,就不会出现读多了导致粘包问题。
- 而我们Content-Type描述了我们body的数据格式什么,浏览器有了这个字段就知道如何使用什么格式来理解我们body里面的内容了
常见的数据格式有
在请求中:

在响应中:


- 服务器响应的Content Type的通常描述了数据的字符集,如果发现服务器返回的响应是乱码。那么很可能就是Content-Type中的字符集没写或者是写错了。
User-Agent

- 简单来说User-Agent描述了浏览器版本信息和操作系统的版本信息
- 那么为什么要HTTP请求中的User-Agent为什么要描述操作系统和浏览器信息呢?其根本原因就是服务器根据需要根据他们描述的信息给不同的操作系统和浏览器返回不同的响应信息。
- 这么做的原因就是我们互联网早期的时候浏览器的版本有很多,有的浏览器支持显示文本内容,有的浏览器支持显示超文本内容(音视频等等),服务器根据HTTP请求中的User-agent描述返回不同的浏览器响应。
- 还有一个原因就是为了区分PC和手机端的网页显示方式,我们知道PC端的网页显示大小和手机端的网页显示大小比例是不一样的,那么我们服务器就需要根据User-agent的描述信息来区分PC和手机端。
- 不过这种做法有一个很大的缺陷就是程序员要根据不同的UA写不同的代码,现在不用这种方式了而是用前端的一种新技术叫做响应式编程,动态获取手机或者PC屏幕大小来进行不同的页面排版显示。
Referer
- Referer就是描述当前页面是从那个页面跳转过来的。
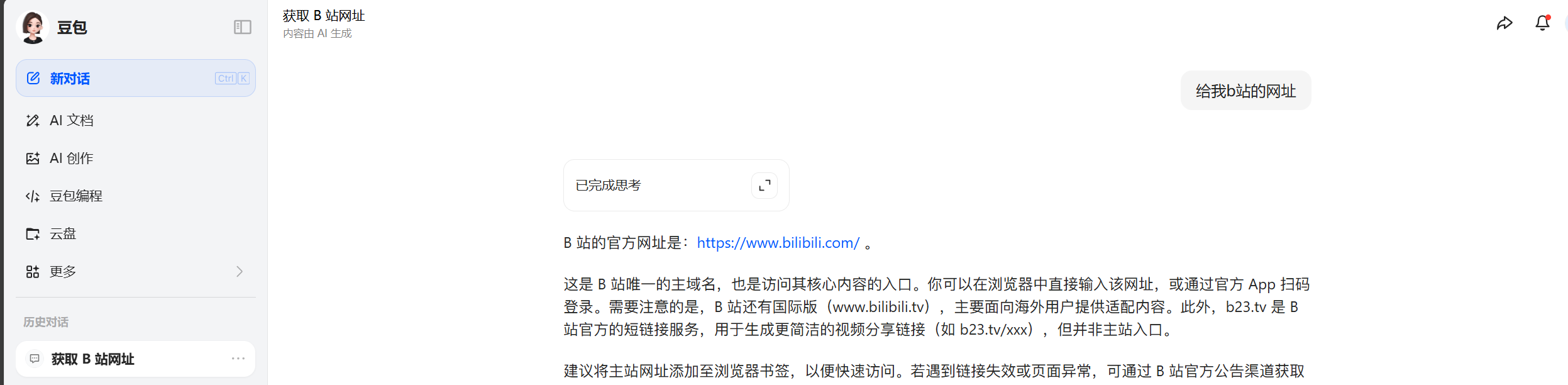
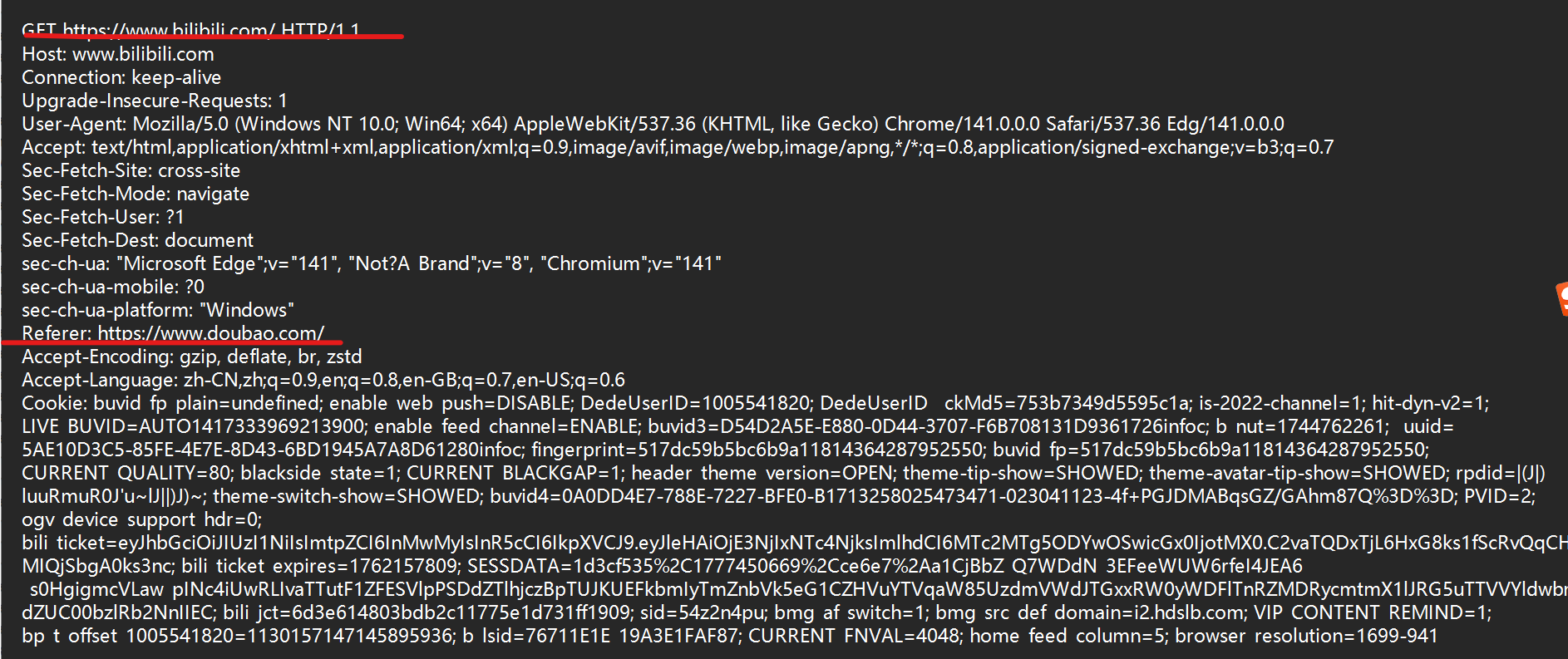
- 比如说我们在豆包网页版让豆包给我们b站的网址,通过豆包给的链接访问b站
-
可以看到通过抓包得到请求,发现Referer的确是豆包的网址
-
这里要注意直接在地址栏访问和收藏夹访问是没有Referer的,他们不是通过页面跳转访问的。
-
那么这个Referer到底用来干什么呢?他的作用就是当前页面是通过那个页面跳转过来的,那么我们广告主的老板就可以通过查看那个网页的跳转到他们广告页面Referer次数多,就该给对应的公司付钱。当然这里不得不说早期这个Referer还会被某些公司恶意修改,那么这就有了我们后面的HTTPS协议来解决。
Cookie

- 这个就是程序员自定义的键值对(只有程序员自己看得懂),每个键值对之间用;分割,键和值之间用=分割,主要作用就是用于浏览器给网页提供的本地存储数据(一般网页数据不能存在本地,有安全隐患),方便下次服务器需要的时候不需要通过网络资源加载直接从硬盘上加载(网络IO比硬盘IO速度还慢)。这个时候避免了多次请求,都需要走网络IO。

- 服务器通过响应中的Set来寄存在本地

- 那么Cookie的应用场景有那些呢?
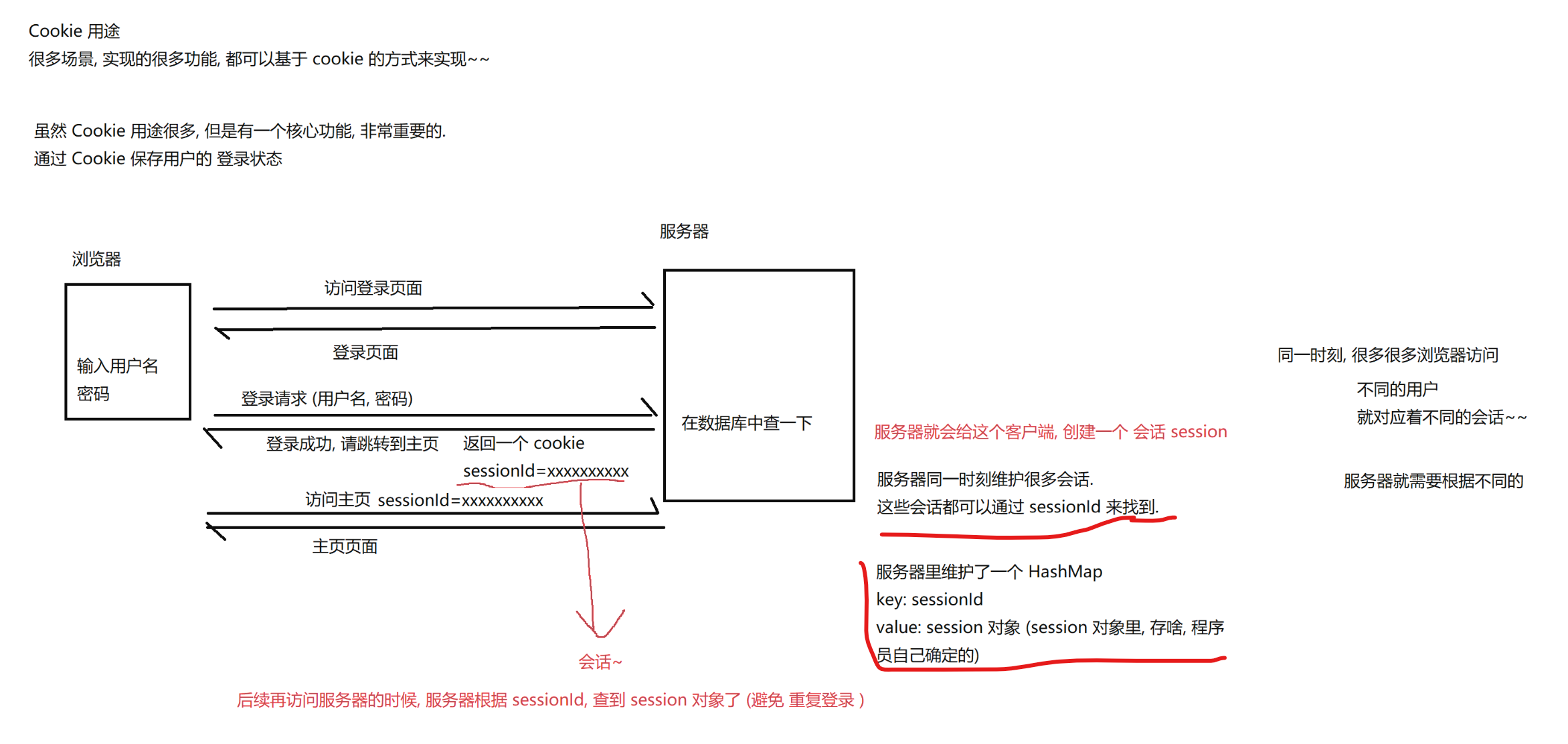
- 比如我们登录了Gitee网页,第二次进行登录的时候,由于我们服务器对登录进行了用sesson维护会话,通过cookie中返回seesionid,那么再次登录的时候就可以通过这个seesionid找到对应的session对象,那么久避免了重复登录认证,比如我们Gitee就是这么干的。
这就好比去医院看病,通常会让我们办理就诊卡,这个就诊卡里面就会有我们的各种信息:姓名,性别,年龄等。医生见到我们第一件事就是要就诊卡,通过就诊卡查看我们的信息,来根据信息做出对应的解决方案。这就是我们把信息存储到了就诊卡立减, 再比如我们检查完后去拿药,药房人员也可以通过就诊卡来看我们生的什么病来判断给我们开什么药。
- 当然我们真正的数据不是存储在就诊卡中,就诊卡只是我们的sessionid可以找到对应的session对象。
- 每次刷就诊卡都是一个请求,服务器就可以根据这个就诊卡中的ID找到对应的session对象

响应的格式
响应行
- 响应行就是体现服务器的反馈

- 第一部分是HTTP协议版本,第二部分是状态码,第三个部分是状态短语是(专用于程序员看)
状态码
其中状态码就是给我们计算机看的,看这个响应是否正确。
2xx开头
- 一般都是服务器处理成功,返回正确响应

3xx开头
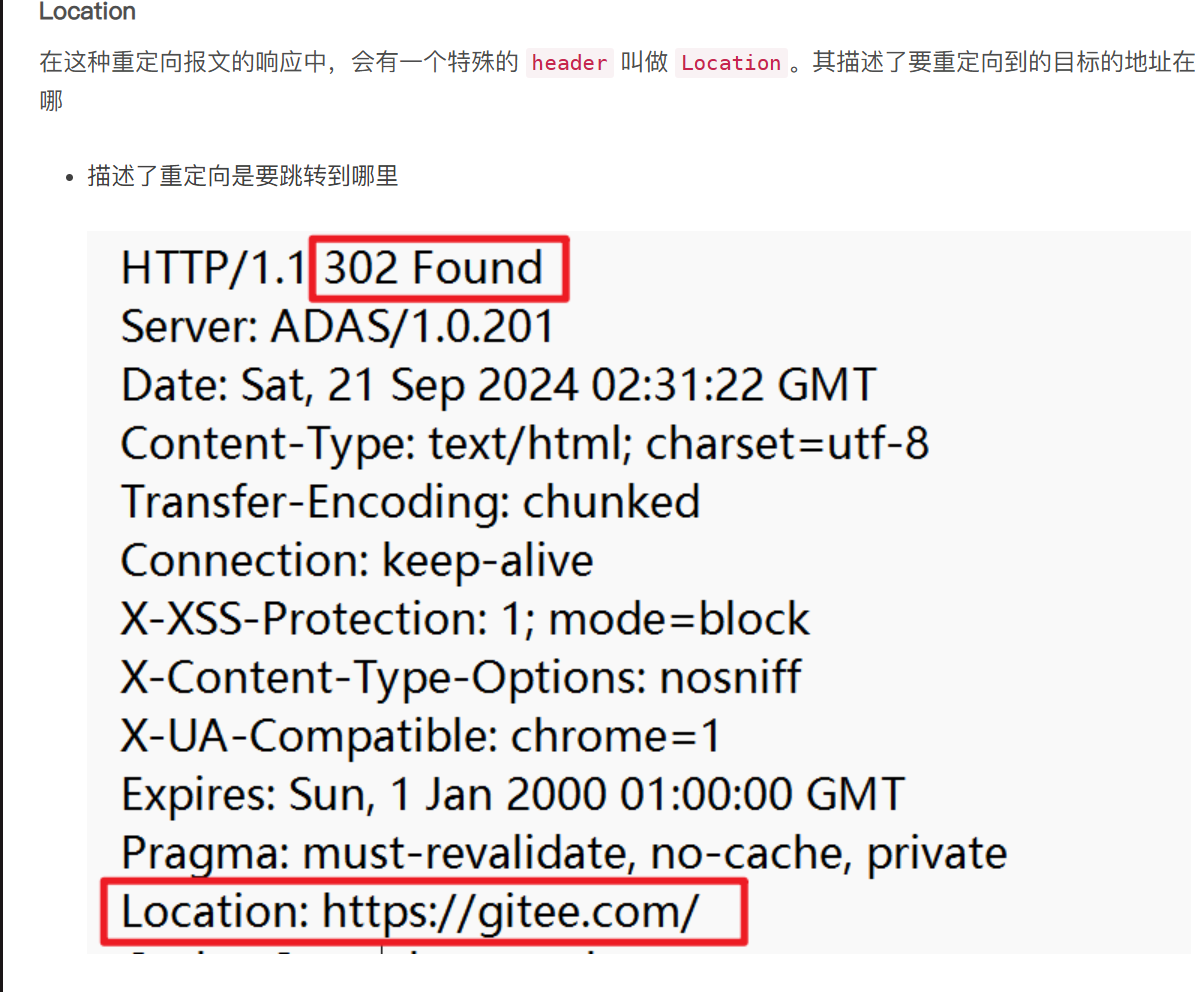
- 一般是对客户端访问的URL重定向
- 301是永久重定向,他会把重定向的新URL缓存在浏览器中,下一次访问旧的URL会再次重定向到新的URL
- 302是临时重定向,不会缓存在浏览器中,只是这次访问旧的URL会重定向到新的URL中。
4xx开头
- 这个开头的通常是客户端出现错误,比如404就是客户端填写的URL不存在
- 403就是访问的资源是私有的,客户端没有权限访问。
- 405就是客户端填写的请求方法服务器不支持



5xx开头
- 这个一般是服务器出现错误了
- 比如500就是服务器崩溃了。
- 504服务器那边的网关有问题

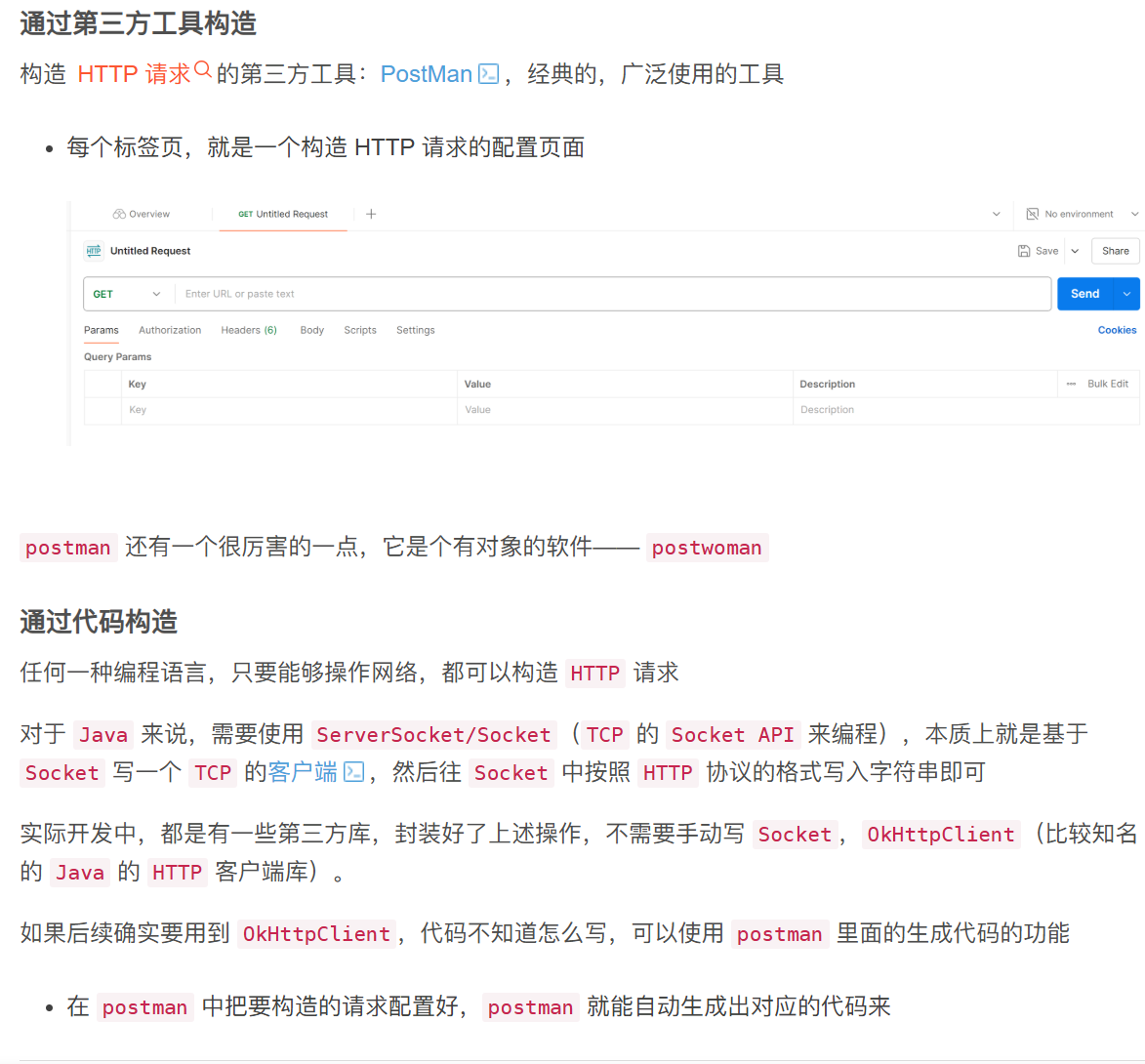
如何构造HTTP请求

















 1148
1148

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









