







打包压缩(归档)与搜索
tar 命令用于对文件进行打包压缩或解压,在Linux系统中,常见的文件格式比较多,其中主要使用的是.tar或.tar.gz或.tar.bz2格式,下面是常用的参数。
| 参数 | 作用 |
| -c | 创建压缩文件 |
| -x | 解开压缩文件 |
| -t | 查看压缩包内有哪些文件 |
| -z | 用Gzip压缩或解压 |
| -j | 用bzip2压缩或解压 |
| -f | 指定 目标文件名 |
| -p | 保留原始的权限与属性 |
| -C | 指定解压到的目录 |
| -v | 显示压缩和解压缩过程 |
.tar 格式-仅仅只是一个打包工具,并不负责压缩。只消耗非常少的CPU以及时间。
例1:.tar 格式:将test.txt文件使用Gzip压缩成名字为,test.txt.tar的文件,并显示过程。
[root@mylinux01 Desktop]# tar -cvf test.tar test.txt 压缩
[root@mylinux01 Desktop]# tar -xvf test.tar 解压缩
例2:.tar在桌面创建test目录,再将刚刚创建的test.txt.tar文件解压到该目录。
[root@mylinux01 Desktop]# mkdir test
[root@mylinux01 Desktop]# tar -xvf test.txt.tar -C /root/Desktop/test
test.txt
例3:在桌面创建test目录,再将刚刚创建的test.txt.tar文件解压到该目录。
tar.gz格式
这种格式是使用得最多的压缩格式。它在压缩时不会占用太多CPU的,而且可以得到一个非常理想的压缩率。
压缩方式: tar -zcvf archive_name.tar.gz filename
解压缩方式: tar -zxvf archive_name.tar.gz
tar -zxvf archive_name.tar.gz -C /root/bbc 指定路径
tar.bz2格式
这种压缩格式是我们提到的所有方式中压缩率最好的。当然,这也就意味着,它比前面的方式要占用更多的CPU与时间。
压缩方式: tar -jcvf archive_name.tar.bz2 filename
解压缩方式: tar -jxvf archive_name.tar.bz2
tar -jxvf archive_name.tar.bz2 -C /root/bbc 指定路径
zip 是个使用广泛的压缩程序,压缩后的文件后缀名为 .zip
Unzip解压缩( -d<目录> 指定文件解压缩后所要存储的目录)
-q 不显示指令执行过程。
-r 递归处理,将指定目录下的所有文件和子目录一并处理
压缩文件
#zip yy.zip yy.txt #rm -rf yy.txt
#unzip yy.zip
将 /home/html/目录所有文件 压缩。 压缩名html.zip
#zip -r html.zip /home/html 压缩
#unzip html.zip 解压
#unzip -d /root/ppv/ html.zip 解压到指定目录
文件处理及相关命令
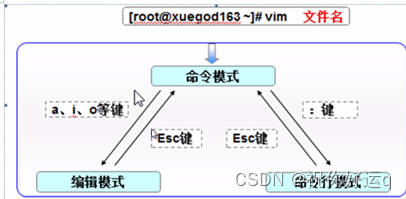
vim 文本编辑器
默认安装在当前所有的Linux操作系统上,得到广大厂商与用户的认可,vim编辑器中设置了三种模式—命令模式、末行模式和编辑模式,每种模式分别又支持多种不同的命令快捷键,这大大提高了工作效率。
命令模式:控制光标移动,可对文本进行复制、粘贴、删除和查找等工作。
输入模式:正常的文本录入。
末行模式:保存或退出文档,以及设置编辑环境。
常用命令:
| 命令 | 作用 |
| dd | 删除(剪切)光标所在整行 |
| 5dd | 删除(剪切)从光标处开始的5行 |
| yy | 复制光标所在整行 |
| 5yy | 复制从光标处开始的5行 |
| n | 显示搜索命令定位到的下一个字符串 |
| N | 显示搜索命令定位到的上一个字符串 |
| u | 撤销上一步的操作 |
| p | 将之前删除(dd)或复制(yy)过的数据粘贴到光标后面 |
| $ | 移动到这行的末尾 |
| G | 光标移动到文档末尾 |
| gg | 光标移动到文档首行 |
| U撤销 | 最近一次操作(可按多次,撤销多次操作)- 后悔撤销----(crtl + r ) |
末行模式中常用的命令:
| 命令 | 作用 |
| :w | 保存 |
| :q | 退出 |
| :q! | 强制退出(放弃对文档的修改内容) |
| :wq! | 强制保存退出 |
| :set nu | 显示行号 |
| :set nonu | 不显示行号 |
| :命令 | 执行该命令 |
| :整数 | 跳转到该行 |
常用替换及搜索命令:
| 命令 | 作用 |
| :s/one/two | 将当前光标所在行的第一个one替换成two |
| :s/one/two/g | 将当前光标所在行的所有one替换成two |
| :%s/one/two/g | 将全文中的所有one替换成two |
| ?字符串 | 在文本中从下至上搜索该字符串 |
| /字符串 | 在文本中从上至下搜索该字符串 |
练习:
cat 命令适合查看内容较少的纯文本文件, -n参数可以显示行号。
more 命令适合查看内容较多的纯文本文件,使用cat命令阅读长篇的文本内容,信息就会在屏幕上快速翻滚。more命令会在最下面使用百分比的形式来显示已经阅读了多少内容,可以使用空格键向下翻页或使用回车键跳行。
#ifconfig | more
head 命令用于查看纯文本文档的前N行,搭配参数-n使用,不使用参数则默认10行。
例:查看一个文件的前3行。

tail 命令用于查看纯文本文档的后N行或持续刷新内容,跟前一个命令一样,一般搭配-n参数使用,参数-f可以持续刷新一个文件的内容,不使用参数则默认10行。
例:查看一个文件的后3行。

tr 命令用于替换文本文件中的字符。
例:使用cat和tr命令,再搭配管道符,将test.txt中的1替换成3再输出。

wc 命令用于统计指定文本的行数、字数、字节数,常用的3个参数如下:
| 参数 | 作用 |
| -l | 只显示行数 |
| -w | 只显示单词数 |
| -c | 只显示字节数 |
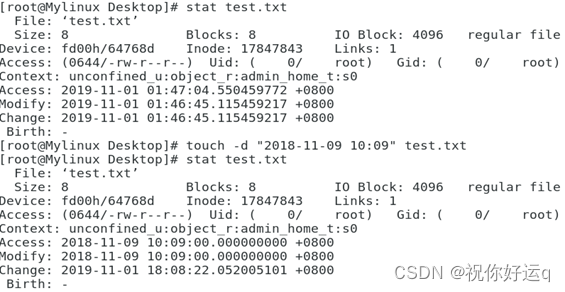
stat 命令用于查看文件的具体存储信息和时间等信息,会显示出文件的三种时间状态(已 加粗):Access、Modify、Change。
例:查询文件的三种时间状态,然后使用touch -d命令修改后再次查询。
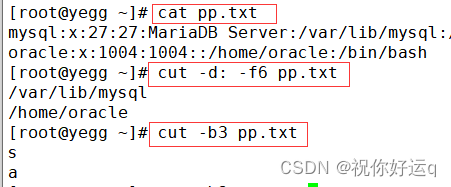
cut 命令用于按“列”提取文本字符,使用
-f参数来设置需要看的列数,还需要使用(与-d一起用)-d参数来设置间隔符号。
-b以字节为单位分割-c 以字符分割
例:文件/etc/passwd在保存用户数据信息时,用户信息的每一项值之间采用冒号来间隔,只提取用户用户名信息,即提取以冒号(:)为间隔符号的第一列内容:
# cut -d' ' -f3 a.txt 以空格为分割符号 #cut -d: -f1,7 /etc/passwd 看第一列和第七列

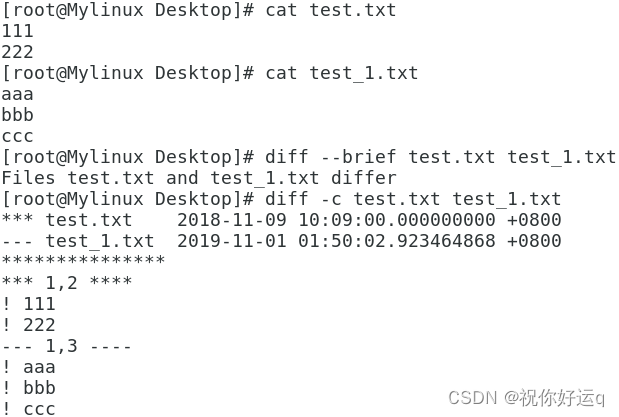
diff 命令用于比较多个文本文件的差异,可以使用--brief参数来确认两个文件是否不同,也
可以使用-c参数来详细比较出多个文件的差异之处。
例:分别使用两个参数比较test.txt和test_01.txt两个文件的差异。
grep 命令用于在文本中执行关键词搜索,并显示匹配的结果。grep命令是用途最广泛的文本 搜索匹配工具,参数很多,根据行匹配过滤。常用的参数如下:
| 参数 | 作用 |
| -b | 将可执行文件(binary)当作文本文件(text)来搜索 |
| -c | 仅显示找到的行数 |
| -i | 忽略大小写 |
| -n | 显示行号 |
| -v | 反向选择—仅列出没有“关键词”的行 |
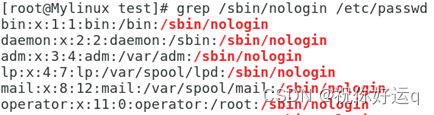
例1:使用grep命令搜索/etc/passwd中包含/sbin/nologin的行。
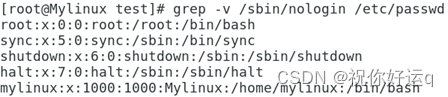
例2:使用grep命令,结合-v参数搜索/etc/passwd中不包含/sbin/nologin的行。
Sed 流编辑
sed 是一种新型的,非交互式的编辑器。它能执行与编辑器 vi 和 ex 相同的编辑任务。sed 编辑器没有提供交互式使用方式,使用者只能在命令行输入编辑命令、指定文件名,然后在屏幕上查看输出。 sed 编辑器没有破坏性,它不会修改文件,除非使用 shell 重定向来保存输出结果。默认情况下,所有的输出行都被打印到屏幕上。
参数说明
- -e<script>或--expression=<script> 以选项中指定的script来处理输入的文本文件。
- -f<script文件>或--file=<script文件> 以选项中指定的script文件来处理输入的文本文件。
- -n 默认情况下,sed 会在所有的脚本指定执行完毕后,会自动输出处理后的内容,而该选项会屏蔽启动输出,需使用 print 命令来完成输出。
- -r:使用扩展正则表达式
- -i 此选项--直接修改源文件,要慎用
动作说明
- a :新增/追加, 向匹配行 下 插入内容
- c :取代/更改, 更改匹配行的所有内容
- d :删除,因为是删除,所以 d 后面通常不接任何数据;
- i :插入, 向匹配行 前 插入内容
- p :打印print,亦即将某个选择的数据印出。通常 p 会与参数 sed -n 一起运行~
- s :替换,替换掉匹配内容
- !:表示取反
例子1,: Sed -e '4anewline' test.txt #在第四行后新增一行 newline
Sed -e '/123/a444' a.txt 匹配到123那行,追加一行,内容444
sed '$aUUUUUU' pp.txt 最后一行最加uuuuuu
sed '4cyyyyyyyyyyy' 1.txt 第四行替换成yyyyy
sed -e '/3333/caaaaa' 1.txt 匹配3333的行 替换 成 aaaaa
例子2: 打印(输出)----筛选出含 oracle的行
![]()
例子3: # sed '3d' pp.txt 删除第三行后,其余都显示
例子4:# sed '3,$d' pp.txt 删除第三行到最后一行, 显示前两行
例子5:# sed '/ccc/d' pp.txt 删除含ccc的行,其余显示
例子6:#sed -e '$i88' pp.txt 最后一行前插入88
例子7:#sed 's/11/999/g' pp.txt 将文中所有11 替换为999 g表示全部
sed 's/22/77/' pp.txt 将pp.txt中每行第一个22替换成77.
sed -n '2~2p' 1.txt #从第二行开始,每隔两行打印一行,波浪号后面的2表示步长
sed -n '$p' 1.txt #打印文件的最后一行
sed -n '1,3p' 1.txt #打印1到3行
#sed -n '1p' pp.txt 打印第一行
sed -n '3,/you/p' 1.txt #只打印第三行到匹配you的行
sed -n '/you/p' 1.txt #逐行读取文件,打印匹配you的行
sed -n '/too/,$p' 1.txt #打印从匹配too的行到最后一行的内容
sed -n '/bob/,/too/p' 1.txt #打印从匹配内容bob到匹配内容too的行
awk 工具
awk是一个强大的文本分析工具,相对于grep的查找,sed的编辑,awk在其对数据分析并生成报告时,显得尤为强大。简单来说awk就是把文件逐行的读入,以空格为默认分隔符将每行切片,切开的部分再进行各种分析处理。
-F参数:指定分隔符,可指定一个或多个。
示例1:请从该文件中过滤出'Poe'字符串与33794712,最后输出的结果为:Poe 33794712
[root@yegg]# cat test.txt ====》I am Poe,my qq:is=33794712
[root@yegg]# awk -F '[,:= ]' '{print $2,$7}' test.txt ==》Poe 33794712
示例2,最后创建的用户名
# cat /etc/passwd | sed -n '$p' | awk -F ':' '{print $1}' ==>ykk
# cat /etc/passwd | awk -F ':' '{print $1,$3,$7}'
示例3,匹配IP地址
# ifconfig eth0 | sed -n '2p' | awk '{print $2}' ==>192.168.10.208


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









