







 本文详细介绍了快速排序算法的工作原理,包括选择基准元素、分区操作和递归排序的过程,以及其平均O(nlogn)的时间复杂度。提供了C++代码示例,并与其他排序算法进行了对比。
本文详细介绍了快速排序算法的工作原理,包括选择基准元素、分区操作和递归排序的过程,以及其平均O(nlogn)的时间复杂度。提供了C++代码示例,并与其他排序算法进行了对比。
引言
排序算法c++实现系列第6弹——快速排序
文章末尾还有本菜已实现的其他排序算法文章的链接。不过,排序算法这个系列还没更完,争取本周末搞完!之后还会有堆排序、桶排序等的代码实现,感兴趣的佳人可以点个赞&收藏,如果我有幸获得佳人们一个关注,感激涕零,呜呜呜呜呜呜呜呜...
算法介绍
快速排序(Quick Sort)是一种常见且高效的排序算法,它和归并排序算法一样,都是基于分治法(Divide and Conquer)的思想。快速排序的核心思想是选择一个基准元素,将数组分成两部分,使得左边的元素都小于等于基准元素,右边的元素都大于等于基准元素,然后再对左右两部分分别进行递归排序,最终实现整个数组的排序。
算法步骤
下面是快速排序的主要步骤:
-
选择基准元素:从待排序数组中选择一个基准元素。通常选择第一个元素、最后一个元素或者中间元素作为基准元素。在本文中我们选择第一个元素为基准元素。
-
分区操作:将数组重新排列,将小于基准元素的所有元素移到基准元素的左边,将大于基准元素的所有元素移到基准元素的右边,基准元素本身则放置在最终的位置上。这个操作称为分区(Partition)操作。
比如说 有子数组a[p:r],下标从p到r。以a[p]为基准元素将a[p:r]划分成3段a[p:q-1],a[q]和a[q+1:r],使a[p,q-1]中任意一个元素小于等于a[q],而a[q+1:r]中任何一个元素大于等于a[q],下标q在划分过程中确定;
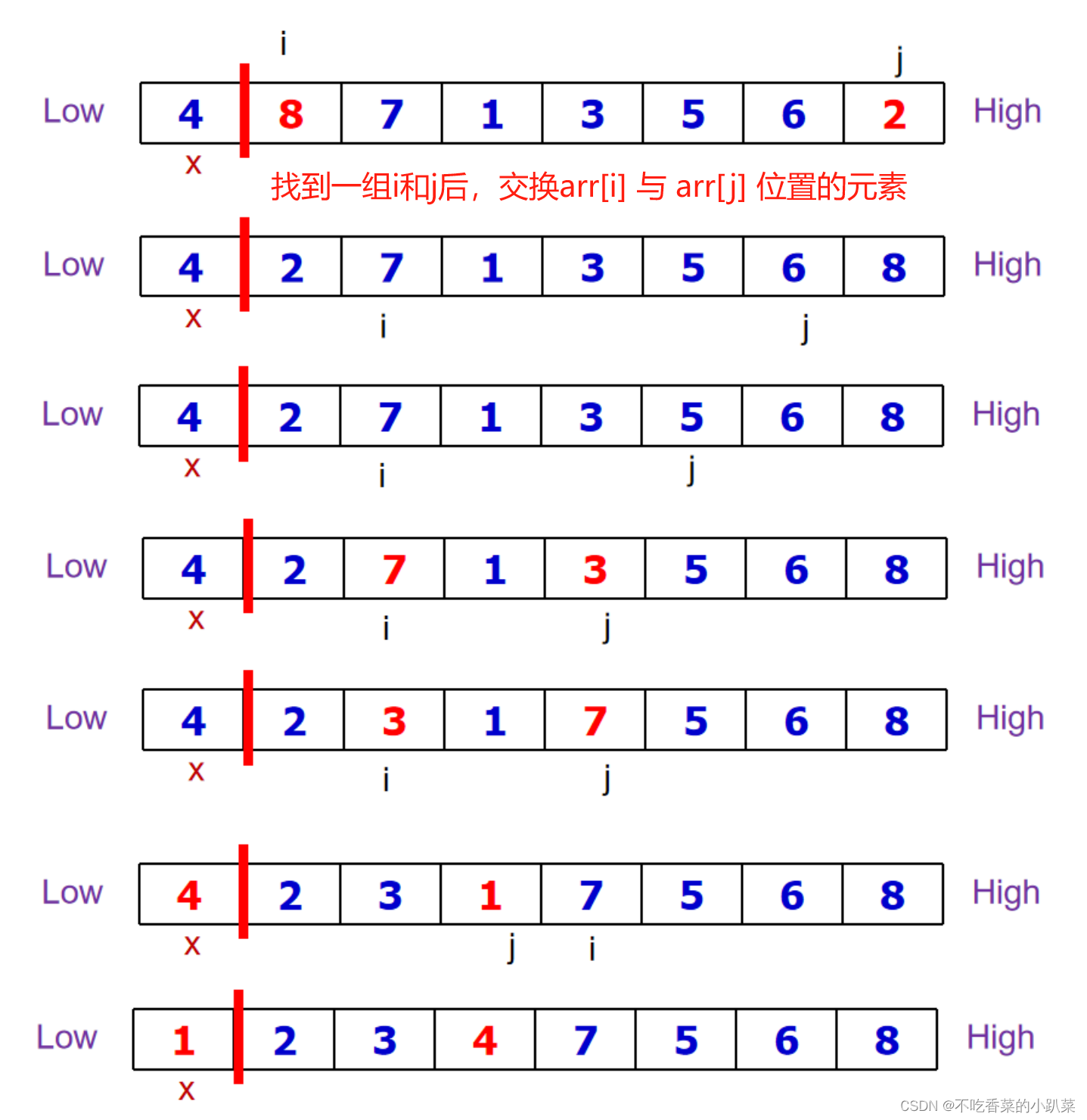
分区操作的具体过程可以看代码和下方的图片。这里简单描述,令 i 指向序列最左侧数据(不算基准元素),j 指向最右侧数据。
-
i 自前往后(或者说自左往右)寻找大于基准元素的值,找到后停止查找;
-
j 自后往前(自右往左)寻找小于基准元素的值,找到后停止
-
将 arr[i] 与 arr[j] 交换。
-
交换完毕后,重复步骤1、2、3,直到分区操作完成
-
-
递归排序:对分区后的左右两个子数组进行递归排序。对左子数组和右子数组分别重复步骤1和步骤2,直到子数组的大小为1或者0,此时子数组已经有序。接上边的例子,即通过递归调用快速排序算法分别对a[p:q-1]和a[q+1:r]进行排序;
具体举例展示:假设有数组a[] = {4,8,7,1,3,5,6,2} ,以第一个元素a[0]为基准元素,可以得到:a[q]=4; a[p: q-1]=[1,2,3]; a[q+1:r]=[7,5,6,8],下图是具体过程展示(建议拿该图用作代码的辅助理解)
时间复杂度
快速排序的平均时间复杂度为 O(nlogn),最坏情况下的时间复杂度为O(n^2),最好情况下的时间复杂度为O(nlogn)。
最坏的情况出现在序列已按递增或递减顺序排列,即数组已经有序。(条件:每次选序列中第一个元素为基准元素)
最好的情况出现在每次选择的基准元素都能将数组分为两个 n/2 区域再进行递归。
同时快速排序是一种原地排序算法,不需要额外的辅助空间。
代码实现
#include<bits/stdc++.h>
using namespace std;
template<typename T>
int partition(T arr[], int l, int r) {
int i = l, j = r + 1;
T key = arr[l];
// 记忆,边界问题一定要小心
while (true)
{//i<r 没有=,原因:假如有=,则i=r可进入循环,待下一轮,++i为r+1,可能出现数组越界
while (arr[++i] < key && i < r) {}
// 两个while循环中与key比较都不加=,原因见代码下方
while (arr[--j] > key) {}
if (i >= j) break; // 等号 必须有,如果a[j]起初刚好是小于key的,而a[i]一路找过来没找到大于key的,最后停在a[j]处;
swap(arr[i], arr[j]);
}
arr[l] = arr[j];
arr[j] = key;
return j;
}
template<typename T>
void quick_sort(T arr[], int l, int r) {
// 思路是先按大小交换,获得pilot的下标,从而好将问题分解为两部分
if (l < r) {
int k = partition(arr, l, r);
quick_sort(arr, l, k - 1);
quick_sort(arr, k + 1, r);
}
}
int main() {
int arr[] = {61, 17, 29, 22, 34, 60, 72, 21, 50, 1, 62};
int len = (int) sizeof(arr) / sizeof(*arr);
quick_sort(arr, 0, len - 1);
for (int i = 0; i < len; i++) {
cout << arr[i] << " ";
}
cout << endl;
float arrf[] = {17.5, 19.1, 0.6, 1.9, 10.5, 12.4, 3.8, 19.7, 1.5, 25.4, 28.6, 4.4, 23.7, 5.4};
int lenf = sizeof(arrf) / sizeof(*arrf);
quick_sort(arrf, 0, lenf - 1);
for (int i = 0; i < lenf; i++) {
cout << arrf[i] << " ";
}
return 0;
}
while循环等号解释
在快速排序的分区操作中,加等号可能导致出现问题的原因是在找到小于等于基准值的元素时,如果加了等号,则可能会导致相等的元素被交换,从而影响排序的稳定性。快速排序是一种不稳定的排序算法,意味着相等元素的相对位置在排序后可能会改变,加上等号可能会导致相等元素的顺序被打乱。
举个例子,假设原始数组为[2, 3, 2, 1],如果在分区操作中加上等号,即将arr[i] <= key改为arr[i] < key,那么在分区操作后,可能会得到[2, 1, 2, 3]这样的结果,相等的元素2的相对位置发生了改变。而如果不加等号,则可能会得到[1, 2, 2, 3]这样的结果,保持了相等元素的相对位置不变。
因此,为了保证快速排序的稳定性,一般会选择不加等号的方式来实现分区操作。
运行结果展示:

其他排序算法实现
十大经典排序算法复杂度、应用场景总结 | 插入排序、希尔排序、选择排序、冒泡排序、归并排序、快速排序、堆排序、基数排序、桶排序、计数排序-优快云博客
经典排序算法之基数排序详解|c++代码实现|简单易懂-优快云博客
经典排序算法之桶排序详解|c++代码实现|简单易懂-优快云博客
经典排序算法之堆排序详解|c++代码实现|什么是堆排序|如何代码实现堆排序-优快云博客
经典排序算法之归并排序|递归和迭代法代码均提供|c++代码实现|什么是归并排序|如何代码实现-优快云博客
经典排序算法之希尔排序|c++代码实现||什么是希尔排序|如何代码实现-优快云博客



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











