







第6章-组合数据类型
1、组合数据类型的基本概念
计算机不仅能对单个变量表示的数据进行处理,通常情况,计算机更需要对一组数据进行批量处理。这种能够表示多个数据的类型称为组合数据类型。Python语言中最常用的组合数据类型有3大类,分别是集合类型、序列类型和映射类型。
集合类型是一个元素集合,元素之间无序,相同元素在集合中唯一存在。
序列类型是一个元素向量,元素之间存在先后关系,通过序号访问,元素之间不排他(元素之间不排他时,是指在序列类型中,一个元素可以同时属于多个序列。)。序列类型的典型代表是字符串类型和列表类型
映射类型是“键-值”数据项的组合.每个元素是一个键值对,表示为((key,value)。映射类型的典型代表是字典类型。
集合类型是一个具体的数据类型名称,而序列类型和映射类型是一类数据类型的总称。
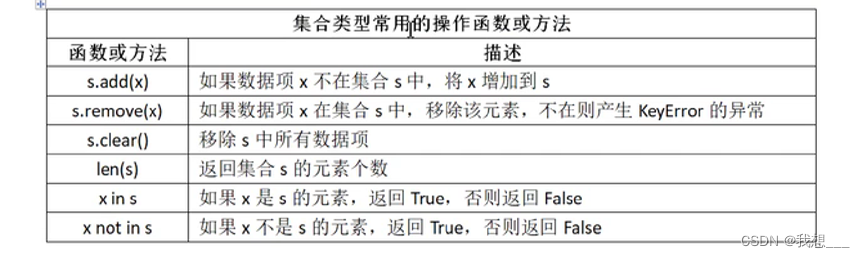
- (1)、集合类型概述
Python语言中的集合类型与数学中的集合概念一致,即包含0个或多个数据项的无序组合。集合是元序组合,用大括号表示,它没有索引和位置的概念,集合中的元素可以动态增加或删除。
集合中的元素不可重复,元素类型只能是不可变数据类型.例如整数、浮点数、字符串、元组等.相比较而言,列表、字典和集合类型本身都是可变数据类型,不能作为集合中的元素出现。
注意事项:由于集合元素是无序的,集合的输出顺序与定义顺序可以不一致。
由于集合元素独一无二,使用集合类型能够过滤掉重复元素。
由于集合元素是无序的,所以集合元素间没有顺序,不能比较,不能排序。创建集合直接使用报。
a = {'Python',844,844,10.5}
print(a)
#运行结果
# {'Python', 10.5, 844}
尽管集合中的元素是不可重复的,但是集合元素在输入时是不受限制的。元素在输入集合后会自动去重。

s={1,2,3}
t={3,4,5}
s-t
{1, 2}
s&t
{3}
s^t
{1, 2, 4, 5}
s|t
{1, 2, 3, 4, 5}
上述操作符表达了集合类型的4种基本操作,交集(&)、并集(|),差集(-),补集(^),操作逻辑与数学定义相同。
set(x)函数将其他的组合数据类型变成集合类型,返回结果是一个无重复且排序任意的集合。set()函数也可以生成空集合变量。
其中,set()表示空集合。
集合类型主要用于元素去重,适合于任何组合数据类型。
- 使用 set() 函数:
empty_set = set() - 使用空的集合字面量 set([]):
empty_set = set([]) - 使用 set 字面量 set():
empty_set = set() - (2)、序列类型概述
序列类型是一维元素向量,元素之间存在先后关系,通过序号访问。序列的基本思想和表示方法均来源于数掌概念。在数学中,经常给每个序列起一个名字,例如,n个数的序列s,可以表示为:s=s0,s1,s3=2,…,sn-1
当需要访问序列中某个特定值时,只需要通过下标标出即可。例如,需要找到序号为2的元素,即可通过s[2]获得。注意,序列的下标从0开始编号。
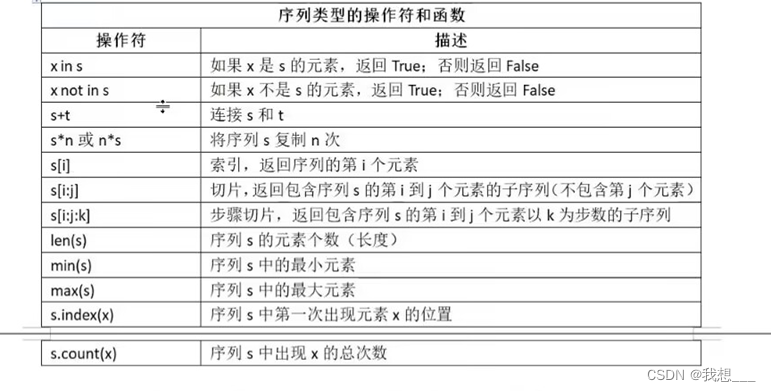
由于元素之间存在顺序关系,所以序列中可以存在数值相同但位置不同的元素。Python语言中有很多数据类型都是序列类型,其中比较重要的是字符串类型、列表类型和元组类型。
字符串类型可以看成是单一字符串的有序集合,属于序列类型。列表则是一个可以使用多种类型元素的序列类型。
序列类型各个具体类型使用相同的索引体系,与字符串类型一样,即正向递增序号和反向递减序号。
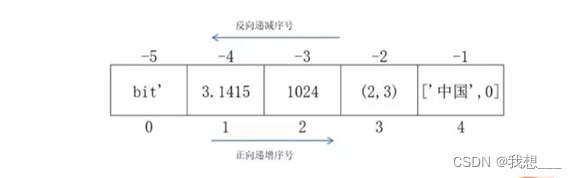
需要注意,序列类型的正向递增序号从0开始。通常说第1个元素,指的是序号为0的元素。
元组类型是序列类型的重要组成之一。元组类型在 Python语言中表示为tuple,一般以小括号和逗号进行组织。
a =(1,3,2)
print(type(a))
#运行结果
- List item
# <class 'tuple'>
元组类型严格遵循序列类型的操作定义,可以使用序列类型的操作符和函数。
元组类型一旦定义就不能修改,在编程中不够灵活,同时,元组类型的所有操作都可以由列表类型实现。因此,一般编程中,如果需要自定义变量,通常以列表类型替代元组类型使用。如果确认编程中不需要修改数据,可以使用元组类型。
元组类型主要在 Python语法相关的场景使用,例如,当函数返回多个值时,多个返回值以元组类型返回,实际上返回一个数据类型。
def text(x):
return x,x+1,x+2
print(type(text(1)))
#运行结果
# <class 'tuple'>
- (3)、映射类型概述
映射类型是“键-值”数据项的组合,每个元素是一个键值对,即元素是( key,value),
元素之间是无序的。键值对(key,value)是一种二元关系,源于属性和值的映射关系。
映射类型是序列类型的一种扩展。在序列类型中,采用从0开始的正向递增序号进行具体元素值的索引。而映射类型则由用户来定义序号,即键,用其去索引具体的值。
键(key)表示一个属性,也可以理解为一个类别或项目,值(valu)是属性的内容,键值对刻画了一个属性和它的值。键值对将映身关系结构化,用于存储和表达。
2、列表类型
- (1)、列表的定义
列表类型是包含0个或多个元素的有序序列,属于序列类型。列表可以进行元素的增加删除、替换、查找等操作。列表没有长度限制,无素类型可以不同,不需要预定长度。
列表类型用中括号[]表示,也可以通过 list(x)函数将集合或字符串类型转换成列表类型list()函数可生成空列表。
_list=[888,888,"Python",[1,2,3]]
_list1=list("Python复习")
_list2=list({1,2,3})
print(_list)
print(_list1)
print(_list2)
#运行结果
# [888, 888, 'Python', [1, 2, 3]]
#['P', 'y', 't', 'h', 'o', 'n', '复', '习']
#[1, 2, 3]
由于列表属于序列类型,所以列表类型支持序列类型对应的操作。
- (2)、列表的索引
索引是列表的基本操作,用于获得列表中的元素。该操作沿用序列类型的索引方式,即正向递增序号和反向递减序号,使用中括号作为索引操作符,索引序号不能超过列表的元素范围,否则会产生 IndexErrorr的错误。
可以使用循环对列表类型的元素进行遍历操作。
语法格式:

_list=[888,888,"Python",[1,2,3]]
for i in _list:
print(i,end=' ')
#运行结果
#888 888 Python [1, 2, 3]
- (3)、列表的切片
切片是列表的基本操作,用于获得列表的一个片段,即获得零个或多个元素。切片后的结果也是列表类型。切片有两种使用方式:
列表或列表变量[N:M]
列表或列表变量[N:M:K]
注意事项: Python语言在[]中表示区间需要使用冒号(:)如切片;表示枚举使用逗号(,),如列表。
切片获取列表类型从N到M(不包括M)的元素组成新的列表,其中,N和M为列表类型的索引序号,可以混合使用正向递增序号和递减序号,一般要求N小于M。当N大于等于M时,返回空列表。当K不存在时,切片获取列表类型从N到M(不包含M)以K为步长所对应元素组成的列表。
_list=[888,888,"Python",[1,2,3]]
a=_list[1:4]
b=_list[-3:-1]
c=_list[::-1]
print(a,b,c)
#运行结果:
#[888, 'Python', [1, 2, 3]] [888, 'Python'] [[1, 2, 3], 'Python', 888, 888]
3、列表类型的操作
- (1)、列表的操作函数
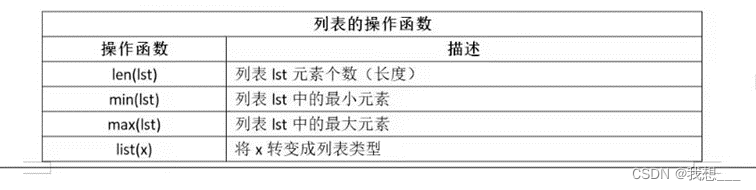
_list=[888,88,89,1,2,3,90]
a=len(_list)
b=min(_list)
c=max(_list)
d=list("Python计算机二级")
print(a,b,c,d,sep='\n')
#运行结果
#7
1
888
['P', 'y', 't', 'h', 'o', 'n', '计', '算', '机', '二', '级']
min(lst)与max(lst)分别返回一个列表的最小或最大元素,使用这两个函数的前提是列表出中各元素类型可以进行比较。如果列表元素间不能比较,使用这两个函数将会报错。
(2)、列表的操作方法
列表类型存在一些操作方法。
语法格式:
列表对象.方法名(参数列表)
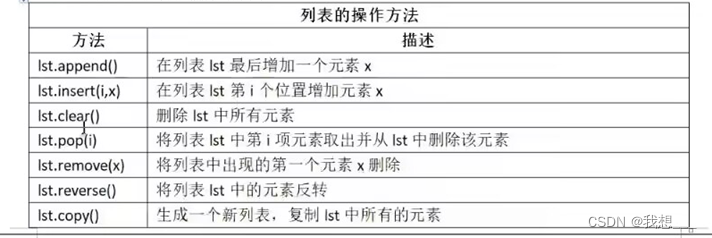
列表的方法主要针对列表对象,实现列表的元素的增、删、改等功能。
_list=[888,1,88,89,1,2,3,90]
_list.append("Python")
_list.insert(2,"计算机二级")
_list.pop(1)
_list.remove(1)
print(_list)
#运行结果
#[888, '计算机二级', 88, 89, 2, 3, 90, 'Python']
除了上述的删除方法,还可以使用Python保留字del对列表元素或片段进行删除。
语法格式:
del列表对象[索引序号]
del 列表对象[索引起始:索引结束]
del列表对象[索引起始:索引结束:步长]
_list=[888,1,88,89,1,2,3,90]
del _list[0]
print(_list)
#运行结果
#[1, 88, 89, 1, 2, 3, 90]
一个列表 _list使用.copy()方法复制后赋值给变量_list2,将 _Iist元素清空不影响新生成的变量 _Iist2。如果不使用.copy()方法,通过直接赋值方式不能产生新列表,仅能够为列表增加一个别名。
_list=[888,1,88,89,1,2,3,90]
g=_list
_list.clear()
print(g)
#运行结果
#[]
对于基本的数据类型,如整数或字符串,可以通过等号实现元素赋值。但对于列表类型,使用等号无法实现真正的赋值。其中,lst2=lst 语句并不是拷贝lst中元素给变量 lst2,而是关联了一个引用,即 lst2与 lst所指向的是同一套内容。
使用索引配合等号(=)可以对列表元素进行修改。
_list=[888,1,88,89,1,2,3,90]
_list[0]=999
print(_list)
#运行结果
#[999, 1, 88, 89, 1, 2, 3, 90]
使用切片配合等号(=)可以对列表片段进行修改,修改内容可以不等长。当使用一个列表改变另一个列表值时,Python不要求两个列表长度一样,但遵循“多增少减”的原则。
列表是一个十分灵活的数据结构,它具有处理任意长度、混合类型的能力,并提供了丰富的基础操作符和方法。当程序需要使用组合数据类型管理批量数据时,请尽量使用列表类型。
4、字典类型
- (1)、字典的定义
“键值对”是组织数据的一种重要方式,广泛应用在当代大型信息系统中,如 Web系统。键值对的基本思想是将“值”信息关联一个“键”信息,进而通过键信息找对应的值信息,这个过程叫映射。Python语言中通过字典类型实现映射。
Python语言中的字典使用大括号{}建立,每个元素是一个键值对。
语法格式:
{键1:值1,键2:值2,键3:值3,…键N:值N}
其中,键和值通过冒号连接,不同键值对通过逗号隔开。从 Python 设计角度考虑,由于大括号{}可以表示集合,所以,字典类型也具有和集合类似的性质,即键值对之间没有顺序具不能重复。可以简单地把字典看成元素是键值对的集合。注意,尽管都使用大括号,但集合与字典是不同的类型。
需要注意的是:字典各个元素并没有顺序之分。
提示:字典和集合
字典类型和集合类型形式上都采用大括号表示,但如果直接使用大括号,则生成字典类型,而不是集合类型。
type({})
<class 'dict'>
- (2)、字典的索引
索引是按照一定顺序检索内容的体系。列表类型采用元素顺序的位置进行索引。由于字典元素“键值对”中键是值的索引,因此,可以直接利用键值对关系索引元素。
字典中键值对的索引语法:
变量名=字典对象[键]
d = {201:'小红',202:"小明",203:"小夏"}
name = d[201]
print(name)
#运行结果
#小红
利用索引和赋值配合,可以对字典中每个元素进行修改。
d = {201:'小红',202:"小明",203:"小夏"}
d[201]="小楚"
print(d)
#运行结果
#{201: '小楚', 202: '小明', 203: '小夏'}
使用大括号{}可以创建字典,可以创建一个空字典。通过索引和赋值配合,可以向字典中增加元素。
d = {}
d[201]="小楚"
print(d)
#运行结果
#{201: '小楚'}
字典是存储可变数据量键值对的数据结构,键和值可以是任意数据类型,通过键索引值,并可以通过键修改值。
5、字典的操作函数

min(d)和 max(d)分别返回字典d中最小值或最大索引值,使用这两个函数的前提是字典中各索引元素可以进行比较。
d = {201:'小红',202:"小明",203:"小夏"}
a=len(d)
b=min(d)
c=max(d)
print(a,b,c,sep='\n')
#运行结果
# 3
201
203
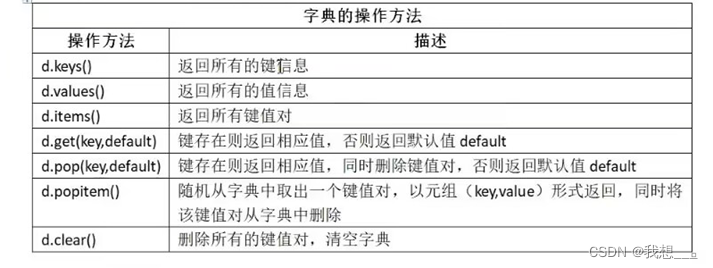
语法格式:
字典对象名.方法名(方法参数)
d = {201:'小红',202:"小明",203:"小夏"}
a=d.keys()
b=d.values()
c=d.items()
f=d.get(409,"无此值")
e=d.pop(304,"无此值")
g=d.popitem()
print(a,b,c,f,e,g,sep='\n')
#运行结果
"""
dict_keys([201, 202])
dict_values(['小红', '小明'])
dict_items([(201, '小红'), (202, '小明')])
无此值
无此值
(203, '小夏')
"""
提示:字典的值
字典类型没办法直通过值进行索引,这是键值对定义的约束。
d.keys()返回字典中所有的键信息,返回结果是 Python的一种内部数据类型dict_keys,专用于表示字典的键。如果希望更好地使用返回结果,可以将其转换为列表类型。
= {201:'小红',202:"小明",203:"小夏"}
a=d.keys()
b=list(a)
print(a)
print(b)
#运行结果
# dict_keys([201, 202, 203])
[201, 202, 203]
此外,如果希望删除字典中某一个元素,可以使用Python的保留字del。
字典类型也支持保留字in,用来判断一个键是否在字典中。如果在,则返回True,否则返回 False。
d = {201:'小红',202:"小明",203:"小夏"}
del d[201]
print(d)
#运行结果
# {202: '小明', 203: '小夏'}
与其他组合类型一样,字典可以遍历循环对其元素进行遍历。
语法结构:

由于键值对中的键相当于索引,所以,for 循环返回的变量名是字典的索引值。如果要获取键对应的值,可以在语句块中通过get()方法获得。
6、选择题
(1)、以下程序的输出结果是()
names=[“小明”,”小红”,”小白”,”小新”]
if ‘小明朋友’ in names:
print(“存在“)
else:
print(“不存在”)
A、存在
B、不存在
C、程序错误
D、不确定
(2)、以下创建字典方式错误的是()
A、d={1:[1,2],3:[3,4]}
B、d={[1,2]:1,[3,4]:3}
C、d={(1,2):1,(3,4):3}
D、d={1:”小红”2:”小明”}
(3)、以下说法中错误的是()
A、浮点数0.0等于 False,条件判断为假
B、空字典对象不等于False,条件判断为真
C、值为0的任何数字类型元素相当于False,条件判断为假
D、空字符串对象相当于 False,条件判断为假
(4)以下程序的输出结果是()
nums=[1,2,3,4]
nums.append([5,6,7,8])
print(len(nums))
A、4
B、5
C、8
D、以上都不对
(5)以下选项中不能创建一个字典的是()
A、d={[1,2,3]:‘Python’}
B、d={}
C、d={(1,2,3):‘Python’}
D、d={3:5}
(6)、以下程序的输出结果是()
d={‘1’:1,’2’:2,’3’:3,’4’:4}
d2=d
d[‘2’]=5
print(d[‘2’]+d2[‘2’])
A、2
B、5
C、7
D、10
(7)以下数据类型属于不可变化类型的是( )
A、列表
B、复数
C、字典
D、元组
(8)将一个字典的内容添加到另外一个字典中的方法是()
A、update()
B、keys()
C、item()
D、元组
(9)列表类型中pop的功能是( )
A、删除列表中第一个元素
B、返回并删除列表中第一个元素
C、删除列表中最后一个元素
D、返回并删除列表中最后一个元素
(10)a和b是两个列表,将它们的内容合并为列表c的方法是()
A、c=a.update(b)
B、a.update(b)
C、c=[a,b]
D、c=a+b
1B
2B
3B
4B
5A
6D
7D
8A
9D
10D
7、编程题
- (1)英文字符频率统计。编写一个程序,对给定字符串中出现的a~z字母频率进行分析,忽略大小写,采用降序方式输出。
def analyze_character_frequency(string):
# 初始化字母频率字典
frequency = {}
# 将字符串中的字母转换为小写
string = string.lower()
# 遍历字符串中的每个字符
for char in string:
# 仅考虑字母字符
if char.isalpha(): #检查一个字符是否为字母
# 更新字母频率
frequency[char] = frequency.get(char, 0) + 1
#frequency.items() 将字典 frequency 转换为一个包含键值对的元组列表。
#例如,{'a': 5, 'b': 2, 'c': 3} 被转换为 [('a', 5), ('b', 2), ('c', 3)]。
# 按照频率降序排列字母
sorted_frequency = sorted(frequency.items(), key=lambda x: x[1], reverse=True)
# 输出结果
for char, freq in sorted_frequency:
print(char, freq)
# 测试
analyze_character_frequency("Hello World!")
- (2)、中文字符频率统计。编写这与一个程序,对给定字符串中出现的全部字符(含中文字符)频率进行分析,采用降序方式输出。
def character_frequency_analysis(string):
frequency = {}
for char in string:
if char in frequency:
frequency[char] += 1
else:
frequency[char] = 1
sorted_frequency = sorted(frequency.items(), key=lambda x: x[1], reverse=True)
return sorted_frequency
input_string = "编写一个程序,对给定字符串中出现的全部字符(含中文字符)频率进行分析。"
result = character_frequency_analysis(input_string)
for item in result:
print(item[0], ':', item[1])
- (3)、随机密码生成。编写程序在26个字母大小写和9个数字组成的列表中随机生成10个8位密码。
import random
def generate_random_password(length):
characters = 'abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ0123456789'
password = ''
for _ in range(length):
password += random.choice(characters)
return password
passwords = []
for _ in range(10):
password = generate_random_password(8)
passwords.append(password)
for password in passwords:
print(password)
- (4)、重复元素判定。编写一个函数,接收列表作为参数,如果一个元素在列表中出现了不止一次,则返回True,但不要改变原列表的值。同时编写调用这个函数和输出测试结果的程序。
def check_duplicate_elements(lst):
if len(lst) != len(set(lst)):
return True
else:
return False
# 测试函数
lst = [1, 2, 3, 4, 5]
print(check_duplicate_elements(lst)) # False
lst = [1, 2, 3, 3, 4, 5]
print(check_duplicate_elements(lst)) # True
lst = ['a', 'b', 'c', 'a']
print(check_duplicate_elements(lst)) # True
- (5)、重复元素判定续。利用集合的无重复性改编上一个程序,获得一个更快更简洁的版本。
def check_duplicate_elements(lst):
return len(lst) != len(set(lst))
# 测试函数
lst = [1, 2, 3, 4, 5]
print(check_duplicate_elements(lst)) # False
lst = [1, 2, 3, 3, 4, 5]
print(check_duplicate_elements(lst)) # True
lst = ['a', 'b', 'c', 'a']
print(check_duplicate_elements(lst)) # True


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









