







一、目标
理解 RDD 的算子分类, 以及其特性
理解常见算子的使用
二、分类
RDD 中的算子从功能上分为两大类
Transformation(转换) 它会在一个已经存在的 RDD 上创建一个新的 RDD, 将旧的 RDD 的数据转换为另外一种形式后放入新的 RDD
Action(动作) 执行各个分区的计算任务, 将的到的结果返回到 Driver 中
RDD 中可以存放各种类型的数据, 那么对于不同类型的数据, RDD 又可以分为三类
针对基础类型(例如 String)处理的普通算子
针对
Key-Value数据处理的byKey算子针对数字类型数据处理的计算算子
三、特点
Spark 中所有的 Transformations 是 Lazy(惰性) 的, 它们不会立即执行获得结果. 相反, 它们只会记录在数据集上要应用的操作. 只有当需要返回结果给 Driver 时, 才会执行这些操作, 通过 DAGScheduler 和 TaskScheduler 分发到集群中运行, 这个特性叫做 惰性求值
默认情况下, 每一个 Action 运行的时候, 其所关联的所有 Transformation RDD 都会重新计算, 但是也可以使用
presist方法将 RDD 持久化到磁盘或者内存中. 这个时候为了下次可以更快的访问, 会把数据保存到集群上.
四、常见的Transformations 算子
| Transformation function |
解释 |
|---|---|
|
|
作用
签名
参数
注意点
|
|
|
作用
调用
参数
注意点
|
|
|
作用
|
|
|
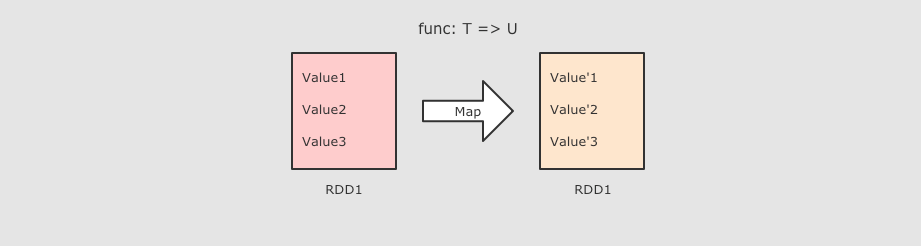
RDD[T] ⇒ RDD[U] 和 map 类似, 但是针对整个分区的数据转换 |
|
|
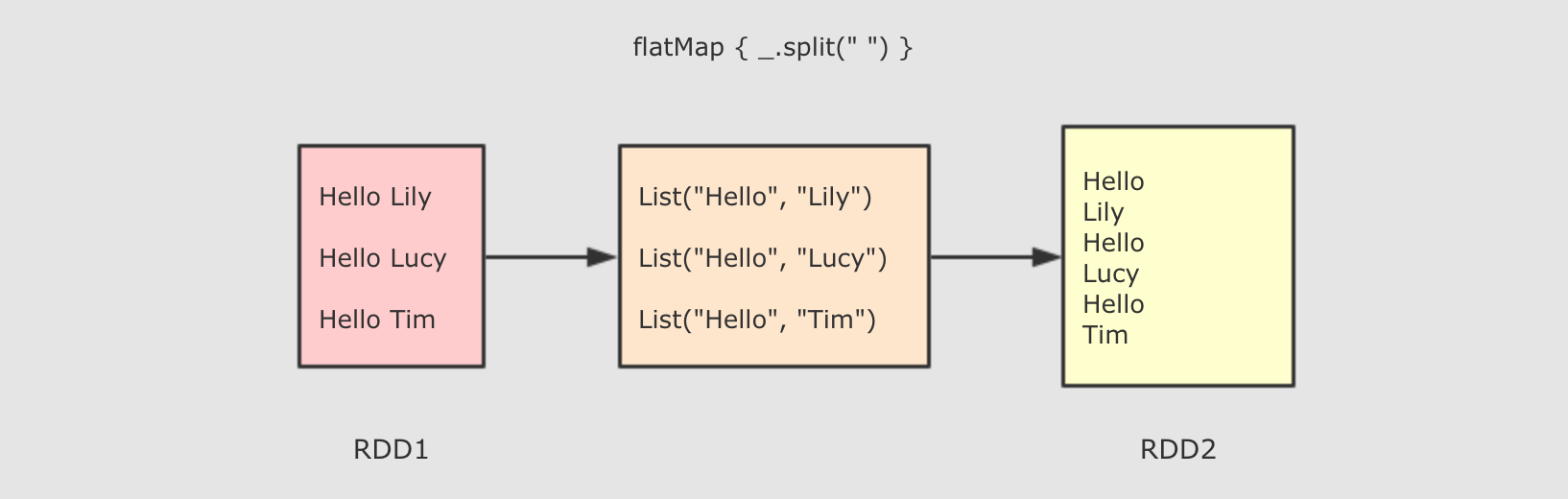
和 mapPartitions 类似, 只是在函数中增加了分区的 Index |
|
|
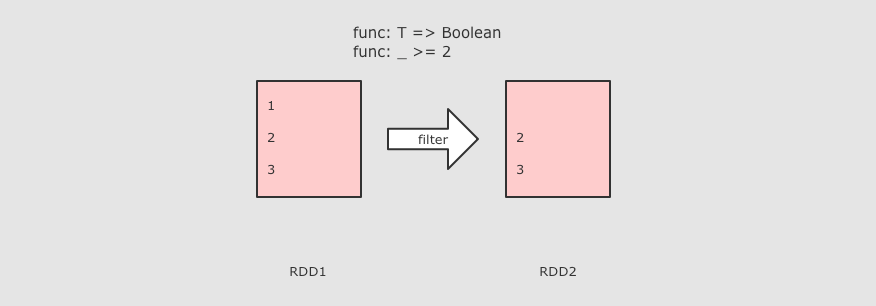
作用
|




 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 536
536

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









