







一.添加请求头信息
head = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/131.0.0.0 Safari/537.36 Edg/131.0.0.0" }如以上代码所示,如果没有伪装User-Agent,可能会不能获取该网页源码,所以head里的为伪装信息,那么我们该如何获取一条伪装信息呢(如果你已经学会爬虫了,那你已经可以变成一个小茶壶了,可以直接跳过这个理解)
1.打开你的目标网页,查看该网页的网络活动(以Microsoft Edge为例,其他浏览器也基本一致)
目标url:https://movie.douban.com/top250

2.点击右侧访问成功的进去找它的User-Agent。复制进你的head里即可完成伪装
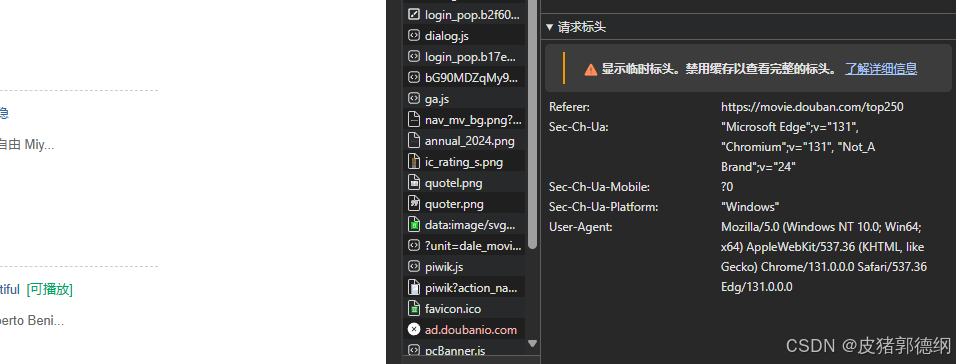
3.发送请求 获取响应
response = requests.get(url,headers=head)4.实例化etree对象(有的同学这个可能会不理解,为什么我们要实例化呢)
tree = etree.HTML(html)上篇文章里爬豆瓣Top250电影排行用到了xpath语法,lxml模块
因为利用etree.HTML,将html字符串(bytes类型或str类型)转化为Element对象,Element对象具有xpath的方法,返回结果的列表(让我们想获取的信息存在一张列表里面)
-
etree.HTML: 这里提到的
etree通常是指lxml库中的一个模块,它用于高效地处理XML和HTML文档。etree.HTML是一个函数,用于将HTML内容解析为一个可以被程序进一步操作的树形结构。这个函数非常灵活,可以接受bytes类型或str类型的HTML字符串作为输入。bytes类型是Python中用于表示二进制数据的数据类型,而str类型是用于表示文本数据的数据类型。 -
转化为Element对象: 当
etree.HTML函数处理完输入的HTML字符串后,它会返回一个Element对象。这个对象代表了HTML文档的根元素,通过它你可以访问和操作整个HTML文档的结构和内容。Element对象是lxml库中的一个核心概念,它提供了丰富的接口来遍历和操作XML或HTML文档。 -
Element对象具有xpath的方法:
Element对象提供了xpath方法,这是一种基于XPath表达式查询文档内容的方式。XPath(XML Path Language)是一种在XML文档中查找信息的语言,同样适用于HTML文档。通过xpath方法,你可以指定一个XPath表达式来查找文档中的特定元素、属性或文本内容。 -
返回结果的列表:
xpath方法执行后,会返回一个列表。这个列表包含了所有匹配指定XPath表达式的元素。每个元素本身也是一个Element对象,你可以进一步操作这些对象来获取更详细的信息。这种方式使得从复杂的HTML文档中提取所需信息变得相对简单和直接。 -
让我们想获取的信息存在一张列表里面: 这句话意味着通过
xpath方法返回的结果列表,你可以很容易地将所有你需要的信息集中起来。这在进行网页数据抓取或分析时非常有用,因为你可以一次性获取到所有感兴趣的数据点,然后再对它们进行处理或分析。
Xpath
XPath(XML Path Language)即XML路径语言,它是一种用来确定XML文档中某部分位置的语言。XPath基于XML的树状结构,提供在数据结构树中找寻节点的能力。起初XPath的提出的初衷是将其作为一个通用的、介于XPointer与XSL间的语法模型,但XPath很快地被开发者采用来当作小型查询语言。以下是关于XPath的详细介绍:
一、XPath的用途
XPath的选择功能非常强大,它可以通过简单的路径选择语法,选取文档中的任意节点或节点集。XPath同样支持HTML元素的解析,学会XPath可以轻松抓取网页数据,提高数据获取效率。XPath常被用于以下场景:
- 数据抓取:XPath爬虫可以用于抓取网页上的特定信息,如商品信息、新闻资讯、用户评论等。通过使用XPath表达式,可以精确地定位到所需元素,从而高效地抓取数据。
- 网页解析:在处理HTML或XML文档时,XPath提供了一种强大的方式来解析和提取文档中的信息。这对于需要从网页中提取数据的爬虫项目来说尤为重要。
- 自动化测试:XPath在自动化测试中也有广泛应用,特别是在Selenium自动化测试中,XPath被用来选择Web元素,这对于测试网站的功能和性能非常有用。
二、XPath的语法
XPath使用路径表达式在XML文档中选取节点。节点是通过沿着路径或者step来选取的。路径表达式是从一个XML节点(当前的上下文节点)到另一个节点、或一组节点的书面步骤顺序。这些步骤以“/”字符分开,每一步有三个构成成分:轴描述(用最直接的方式接近目标节点)、节点测试(用于筛选节点位置和名称)、节点描述(用于筛选节点的属性和子节点特征)。
以下是XPath语法的一些关键点:
-
选取节点:选取节点是最基础的操作之一。节点所在的路径既可以从根节点开始,也可以从任意位置开始。
- 节点名称:选取此节点的所有子节点。
- /:从根节点开始选取直接子节点,相当于绝对路径。
- //:从当前节点开始选取后代节点,相当于相对路径。
- .:选取当前节点。
- ..:选取当前节点的父节点。
- @:选取属性节点。
-
谓语:谓语是为路径表达式附加的条件,主要用于筛选当前被处理的节点集,选取出满足某个特定条件的节点,或者包含了指定属性或值的节点。谓语会嵌入方括号中,位于要补充说明的节点后面。带谓语的路径表达式的语法格式为“节点[谓语]”。在上述格式中,方括号中的谓语可以是整数、属性、函数,也可以是整数、属性、函数与运算符组合的表达式。
- 如果谓语是整数(从1开始),则这个数值将作为位置,用于从节点集中选取与该位置对应的节点。
- 如果是属性,则会从节点集中选取包含该属性的节点。
- 如果是函数,则会将该函数的返回值作为条件,从节点集中选取满足条件的节点。
-
通配符:XPath提供了选取未知节点的通配符和函数。
- *:匹配任何元素节点。
- @*:匹配任何属性节点。
- node():匹配任何类型的节点。
-
运算符:XPath表达式中可以使用多种运算符,如“|”(或)、“+”(加)、“-”(减)、“*”(乘)、“div”(除)、“mod”(取余)等,以及逻辑运算符如“and”(与)、“or”(或)等。
-
选取多个路径:在XPath中,可以使用“|”运算符连接多个路径表达式,根据多个路径选取对应的节点。
-
标准函数:XPath含有超过100个内建的函数,这些函数用于字符串值、数值、日期和时间比较、节点和QName处理、序列处理、逻辑值等等。常用的XPath函数包括:
- position():返回当前被处理的节点的位置。
- last():返回当前节点集中的最后一个节点。
- count():返回节点的总数目。
- max()、min():返回指定参数中的最大值或最小值。
- name():返回当前节点的名称。
- current-date():返回当前的日期(带有时区)。
- current-time():返回当前的时间(带有时区)。
- contains(string1,string2):若string1包含string2,则返回True,否则返回False。
三、XPath的用法示例
以下是一些XPath用法的示例:
-
精确定位:
//*[contains(@class,'c-summaryc-row ')]:选择@class值中包含“c-summary c-row”的节点。//div[contains(.//text(),'价格')]:选择text()中包含“价格”的div节点。//*[@class='result'][position()=1]:选择@class='result'的第一个节点。//*[@class='result'][last()]:选择@class='result'的最后一个节点。
-
过滤信息:
substring-before(str1,str2):用于返回字符串str1中位于第一个str2之前的部分。substring-after(str1,str2):返回字符串str1中位于第一个str2之后的部分。normalize-space():用来将一个字符串的头部和尾部的空白字符删除,如果字符串中间含有多个连续的空白字符,将用一个空格来代替。translate(string,str1,str2):假如string中的字符在str1中有出现,那么替换为str1对应str2的同一位置的字符,假如str2这个位置取不到字符则删除string的该字符。
-
拼接信息:
concat()函数用于串连多个字符串,例如concat('http://baidu.com',.//*[@class='c-more_link']/@href)。
XPath是一种功能强大且灵活的语言,能够精确定位和操作XML或HTML文档中的节点。通过学习和掌握XPath的语法和用法,开发者可以高效地解析和处理XML或HTML文档中的数据。
<div class="info">
<div class="hd">
<a href="https://movie.douban.com/subject/1292052/" class="">
<span class="title">肖申克的救赎</span>
<span class="title"> / The Shawshank Redemption</span>
<span class="other"> / 月黑高飞(港) / 刺激1995(台)</span>
</a>
<span class="playable">[可播放]</span>
</div>以上为豆瓣top250中的随便一部电影,那我们该如何使用Xpath语法精准获取我们想要的信息呢
首先在网页html中<div class="info">,信息都存在这个里面,我们只需要用几行的代码来实现,你可以理解为“info”是一个洋葱 里面加装着“hd”,“a”,“span”这些洋葱心,我们需要剥开处理获得洋葱心
1.第一层“info”,我们可以对照网页的html来找到<div class="info">标签
divs = tree.xpath('//div[@class="info"]')这样就找到了<div class="info">框里的信息,但是还没有获得我们想要的信息
2.第二层<div class="hd">标签,是不是在info里,因为数据比较多,我们用for循环在里面一直不断地获取,而且我们习惯于用字典来存
for div in divs:
dic = {}
title = div.xpath('./div[@class="hd"]/a/span[@class="title"]/text()')
# 电影中文标题
title_cn = ''.join(title).split('\xa0/\xa0')[0]
dic['电影中文名'] = title_cn
# 电影英文标题
title_en = div.xpath('./div[@class="hd"]/a/span[2]/text()')[0].strip('\xa0/\xa0')
dic['电影英文名'] = title_en 我们可以看到外文名有一些\xa0/\xa0这样的符号,\xa0 是一个 Unicode 字符,表示非断行空格。我们利用索引取值之后可以用字符串中的strip函数将它给去除。
#导入模块
import requests
from lxml import etree
import csv
# 请求头信息
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36'
}
moive_list = []
for page in range(1, 11):
# 目标url
url = f'https://movie.douban.com/top250?start={(page - 1) * 25}&filter='
# 发送请求, 获取响应
res = requests.get(url, headers=headers)
# 打印响应信息
# print(res.text)
# 网页源码
html = res.text
# 实例化etree对象
tree = etree.HTML(html)
divs = tree.xpath('//div[@class="info"]')
# print(divs)
for div in divs:
dic = {}
title = div.xpath('./div[@class="hd"]/a/span[@class="title"]/text()')
# 电影中文标题
title_cn = ''.join(title).split('\xa0/\xa0')[0]
dic['电影中文名'] = title_cn
# 电影英文标题
title_en = div.xpath('./div[@class="hd"]/a/span[2]/text()')[0].strip('\xa0/\xa0')
dic['电影英文名'] = title_en
# 电影详情页链接
links = div.xpath('./div[@class="hd"]/a/@href')[0]
dic['电影详情页链接'] = links
brek具体其他的一些有关xpath的使用详情可以查看以下网址:
- W3School官方文档:XPath 教程

















 58万+
58万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









