







目录
简单引入
在使用到集合之前,都是使用数组来存储元素,但是数组有以下缺点:
- 长度在初始化的时候就要指定,而且一定指定,必须更改;
- 保存的必须为同一类型的元素;
- 增删元素不方便,灵活性不够。
因此引入集合,集合可以动态保存任意多个对象,而且提供了多个操作对象的方法,灵活度很高。
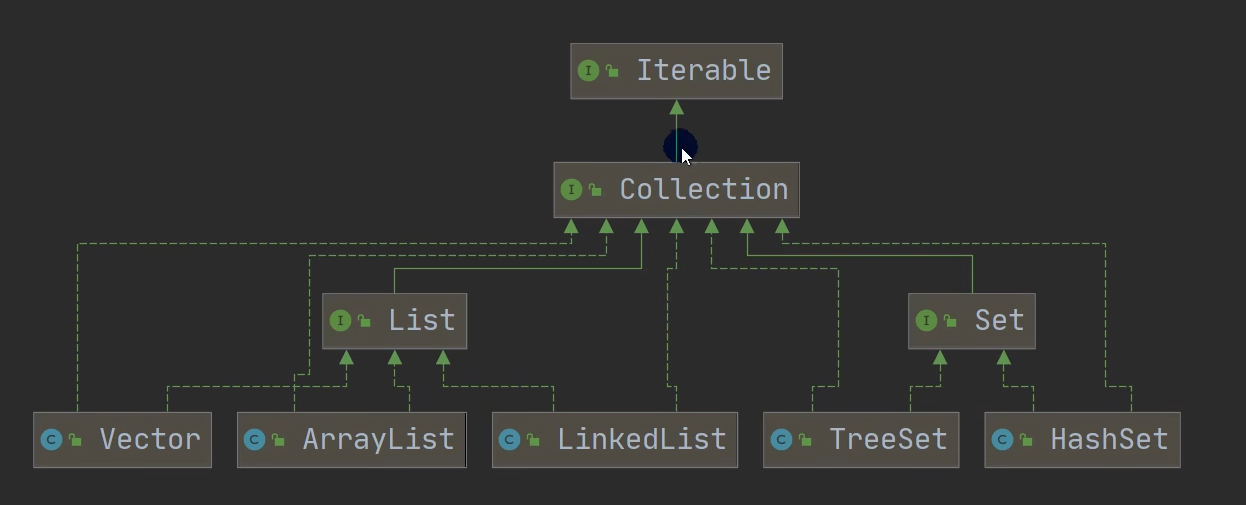
集合主要分两种,单列集合和双列集合。
Collection接口有两个重要的子接口,List和Set,这两个接口的实现子类都是单列集合。
Map接口的实现子类都是双列集合,存放的都是key-value数据。
Collection方法
常见的Collection方法,比较基础,在注释中已经详细介绍:
// 创建ArrayList实例(向上转型为Collection接口)
Collection<Object> collection = new ArrayList<>();
// 1. add: 添加单个元素(支持自动装箱)
collection.add("Jack"); // 添加String类型
collection.add(10); // 自动装箱为Integer
collection.add(true); // 自动装箱为Boolean
System.out.println("添加元素后: " + collection); // [Jack, 10, true]
// 2. remove: 删除指定元素(按对象内容删除)
boolean removed = collection.remove(Integer.valueOf(10)); // 必须使用包装类对象
System.out.println("删除10: " + removed + " | 当前集合: " + collection); // true | [Jack, true]
// 3. contains: 检查元素是否存在
System.out.println("包含Jack? " + collection.contains("Jack")); // true
System.out.println("包含10? " + collection.contains(10)); // false
// 4. size: 获取元素个数
System.out.println("集合大小: " + collection.size()); // 2
// 5. isEmpty: 判断集合是否为空
System.out.println("集合为空? " + collection.isEmpty()); // false
// 6. addAll: 添加多个元素(合并集合,实现了Collection接口的类的对象都可以传进去)
Collection<Object> otherCollection = new ArrayList<>();
otherCollection.add("Alice");
otherCollection.add(3.14); // 自动装箱为Double
collection.addAll(otherCollection);
System.out.println("合并后集合: " + collection); // [Jack, true, Alice, 3.14]
// 7. containsAll: 检查是否包含所有元素
System.out.println("包含所有元素? " + collection.containsAll(otherCollection)); // true
// 8. removeAll: 删除指定集合包含的所有元素
collection.removeAll(otherCollection);
System.out.println("删除部分元素后: " + collection); // [Jack, true]
// 9. clear: 清空集合
collection.clear();
System.out.println("清空后集合: " + collection); // []
System.out.println("清空后大小: " + collection.size()); // 0
System.out.println("集合为空? " + collection.isEmpty()); // true迭代器遍历
只要是实现了Collection接口的类,在遍历的时候就可以有两种方式:使用Iterator(迭代器)和增强for遍历 。
Iterator遍历
Collection接口的父接口是Iterable,其部分源码如下:
public interface Iterable<T> {
/**
* 返回类型为 T 的元素的迭代器。
*
* @return 一个迭代器。
*/
Iterator<T> iterator();
}
可以看到,通过Iterator方法返回Iterator对象,即迭代器对象,用于元素的遍历(本身并不存放数据)。
在Iterator的源码中,有一个hasNext方法:
public interface Iterator<E> {
/**
* 如果迭代中还有更多元素,则返回 true。
* (即如果 {@link #next} 方法将返回一个元素,而不是抛出异常,则返回 true。)
*
* @return 如果迭代中还有更多元素,则返回 true
*/
boolean hasNext();
/**
* 返回迭代中的下一个元素。
*
* @return 迭代中的下一个元素
* @throws NoSuchElementException 如果迭代没有更多元素
*/
E next();
}
因此,在调用next()方法之前必须要调用hasNex()进行检测。若不调用,且下一条记录无效,直接调用next()会抛出NoSuchElementException异常。
这样,也就介绍完了第一种遍历方法,示例如下:
// 1. 创建集合并添加元素
ArrayList<String> animeList = new ArrayList<>();
animeList.add("进击的巨人");
animeList.add("鬼灭之刃");
animeList.add("咒术回战");
animeList.add("钢之炼金术师");
// 2. 获取迭代器对象(相当于获得一个"智能指针")
Iterator<String> iterator = animeList.iterator();
System.out.println("====== 开始遍历集合 ======");
// 3. 使用hasNext()判断是否存在下一个元素
while(iterator.hasNext()) { // 类似:"是否还有下一页?"
// 4. 使用next()完成两个操作:
// a. 指针下移(翻到下一页)
// b. 返回当前元素(阅读当前页内容)
String currentAnime = iterator.next();
System.out.println("正在观看:" + currentAnime);
}
System.out.println("====== 遍历结束 ======");注意此时,迭代器的指针已经到了最后,不能再遍历,如果需要再次遍历,需要重新初始化:
iterator = animeList.iterator();这时候就可以继续使用这个迭代器了。
增强for遍历
使用方法很简单,同样适用于数组和集合的遍历。
public class CollectionFor {
public static void main(String[] args) {
// 1. 创建集合并添加元素(使用泛型指定元素类型为String)
Collection<String> animeCollection = new ArrayList<>();
animeCollection.add("《进击的巨人》");
animeCollection.add("《鬼灭之刃》");
animeCollection.add("《咒术回战》");
animeCollection.add("《钢之炼金术师》");
// 2. 使用增强for循环遍历集合(底层自动转换为迭代器)
System.out.println("====== 遍历集合 ======");
for (String anime : animeCollection) { // 元素类型必须与集合泛型一致
// 在循环体内可以直接访问元素
System.out.println("推荐动漫:" + anime);
// 注意:此处如果调用 animeCollection.remove(anime) 会抛出
// ConcurrentModificationException(并发修改异常)
}
// 3. 遍历数组演示(同样适用)
System.out.println("\n====== 遍历数组 ======");
int[] ratings = {9, 10, 8, 9};
for (int score : ratings) { // 自动将数组元素赋值给score变量
System.out.println("评分:" + score + "分");
}
}
}
/* 执行结果:
====== 遍历集合 ======
推荐动漫:《进击的巨人》
推荐动漫:《鬼灭之刃》
推荐动漫:《咒术回战》
推荐动漫:《钢之炼金术师》
*/增强for的底层仍然是迭代器,可以理解成简化版的迭代器。
Collection(List接口)
List接口以及使用
- List接口的基本特点:
- List集合类中元素有序(即添加顺序和取出顺序一致),且可重复;
- List集合类中的每个元素都有其对应的顺序索引,即支持索引;
- List容器中的每个元素都对应一个整数型的序号记载其在容器中的位置,可以根据序号存取容器中的元素。
- 常用的实现类:ArrayList、LinkedList、Vector。
特性演示如下:
import java.util.ArrayList;
import java.util.List;
/**
* 演示List接口的核心特性
*/
public class ListDemo {
public static void main(String[] args) {
// 1. 创建List实例(使用最常用的ArrayList实现类)
List<String> nameList = new ArrayList<>();
// 2. 演示有序且可重复的特性
nameList.add("tom"); // 索引0
nameList.add("jack"); // 索引1
nameList.add("mary"); // 索引2
nameList.add("mary"); // 索引3(重复元素)
nameList.add("smith2"); // 索引4
nameList.add("kristina");// 索引5
System.out.println("初始列表: " + nameList);
// 输出: [tom, jack, mary, mary, smith2, kristina]
// 3. 索引访问操作(索引从0开始)
// 3.1 获取指定位置元素
System.out.println("\n索引访问演示:");
System.out.println("索引2的元素: " + nameList.get(2)); // mary
System.out.println("索引3的元素: " + nameList.get(3)); // mary(重复元素)
// 3.2 修改指定位置元素
nameList.set(4, "smith"); // 修改索引4的值
System.out.println("\n修改后列表: " + nameList);
// 输出: [tom, jack, mary, mary, smith, kristina]
// 3.3 插入元素到指定位置
nameList.add(1, "新插入的Bob"); // 在索引1插入,原元素后移
System.out.println("\n插入元素后列表: " + nameList);
// 输出: [tom, 新插入的Bob, jack, mary, mary, smith, kristina]
// 4. 索引删除操作
String removed = nameList.remove(0); // 删除索引0的元素(tom)
System.out.println("\n删除元素: " + removed);
System.out.println("当前列表: " + nameList);
// 输出: [新插入的Bob, jack, mary, mary, smith, kristina]
// 5. 遍历演示(结合索引)
System.out.println("\n带索引遍历:");
for (int i = 0; i < nameList.size(); i++) {
System.out.println("索引" + i + ": " + nameList.get(i));
}
// 6. 常见实现类说明
System.out.println("\n实现类说明:");
List<String> linkedList = new LinkedList<>(); // 链表实现
List<String> vector = new Vector<>(); // 线程安全实现
// 7. 异常演示(注释掉实际运行会崩溃的代码)
// System.out.println(nameList.get(10)); // 抛出IndexOutOfBoundsException
}
}以下是List接口实现类的常见方法:
import java.util.ArrayList;
import java.util.Arrays;
import java.util.List;
public class ListMethodsDemo {
public static void main(String[] args) {
// 1. 创建ArrayList实例(List接口的实现类)
List<String> list = new ArrayList<>();
// 2. 初始化列表(演示普通add方法)
list.add("Apple"); // 索引0
list.add("Banana"); // 索引1
list.add("Cherry"); // 索引2
System.out.println("初始化列表: " + list);
// 3. add(int index, E element) - 在指定位置插入元素
list.add(1, "Blueberry"); // 在索引1插入,原元素后移
System.out.println("\n插入Blueberry后: " + list); // [Apple, Blueberry, Banana, Cherry]
// 4. addAll(int index, Collection) - 批量插入元素
List<String> newFruits = Arrays.asList("Durian", "Elderberry");
list.addAll(3, newFruits); // 在索引3插入两个元素
System.out.println("批量添加后: " + list); // [Apple, Blueberry, Banana, Durian, Elderberry, Cherry]
// 5. get(int index) - 获取指定位置元素
String thirdElement = list.get(2);
System.out.println("\n索引2的元素: " + thirdElement); // Banana
// 6. indexOf(Object) - 获取元素首次出现的索引
int firstIndex = list.indexOf("Banana");
System.out.println("Banana首次出现位置: " + firstIndex); // 2
// 7. lastIndexOf(Object) - 获取元素最后出现的索引
list.add("Banana"); // 添加重复元素
int lastIndex = list.lastIndexOf("Banana");
System.out.println("Banana最后出现位置: " + lastIndex); // 6
// 8. remove(int index) - 删除并返回指定位置元素
String removed = list.remove(0); // 删除第一个元素
System.out.println("\n被删除的元素: " + removed); // Apple
System.out.println("删除后列表: " + list); // [Blueberry, Banana, Durian, Elderberry, Cherry, Banana]
// 9. set(int index, E element) - 替换指定位置元素
String replaced = list.set(3, "Fig"); // 替换索引3的元素
System.out.println("\n被替换的元素: " + replaced); // Elderberry
System.out.println("替换后列表: " + list); // [Blueberry, Banana, Durian, Fig, Cherry, Banana]
// 10. subList(int from, int to) - 获取子列表(视图)
List<String> subList = list.subList(1, 4); // 包含索引1,不包含索引4
System.out.println("\n子列表: " + subList); // [Banana, Durian, Fig]
// 子列表的修改会影响原始列表
subList.set(2, "Grape"); // 修改子列表最后一个元素
System.out.println("修改子列表后的原始列表: " + list); // [Blueberry, Banana, Durian, Grape, Cherry, Banana]
}
}ArrayList
基本特性
基本特性:
- 可以放所有的元素、包括空元素;
- 由数组来实现数据的存储;
- 基本等同于Vector,除了ArrayList是线程不安全的,在多线程的场景下不建议使用。
import java.util.ArrayList;
import java.util.Collections;
import java.util.List;
public class ArrayListDemo {
public static void main(String[] args) {
// 1. 创建ArrayList(基于数组的动态扩容实现)
List<String> list = new ArrayList<>(3); // 初始容量为3的数组
// 2. 添加元素演示(允许包含null)
list.add("Apple"); // 数组[0]
list.add(null); // 演示null值存储(图片特性1)
list.add("Banana"); // 数组[2]
System.out.println("初始列表: " + list); // [Apple, null, Banana]
// 3. 自动扩容演示(超过初始容量时会创建新数组)
list.add("Cherry"); // 触发扩容(新数组容量=旧容量*1.5)
System.out.println("\n扩容后列表: " + list); // [Apple, null, Banana, Cherry]
}
}部分源码如下:
public boolean add(E e) {
modCount++;
add(e, elementData, size);
return true;
}没有synchronized的修饰,所以是线程不安全的。
扩容机制(含底层源码)
- ArrayList中维护了一个Object类型的数据elementData。
- 当创建ArrayList对象时,如果使用的是无参构造器,则初始elementData容量为0,第1次添加,则扩容elementData为10,如需要再次扩容,则扩容elementData为1.5倍。
- 如果使用的是指定大小的构造器,则初始elementData容量为指定大小,如果需要扩容,则直接扩容elementData为1.5倍。
——transient关键字表示该属性不会被序列化。
接下来进入源码分析:
对于无参构造及其扩容机制
ArrayList list = new ArrayList();步入无参构造的方法:
/**
* 构造一个初始容量为10的空列表(延迟初始化机制)
*/
public ArrayList() {
this.elementData = DEFAULTCAPACITY_EMPTY_ELEMENTDATA;
}再次步入,发现这就是一个空数组:
/**
* 用于默认大小空实例的共享空数组实例(区别于EMPTY_ELEMENTDATA)
* 通过该标记可识别无参构造创建的ArrayList,在首次添加元素时按默认容量10扩容
*/
private static final Object[] DEFAULTCAPACITY_EMPTY_ELEMENTDATA = {};然后是add方法的调用,会把基本数据类型进行装箱,所以用到了Integer的ValueOf方法
步入:
/**
* 返回表示指定int值的Integer实例。
* 在不需要新Integer实例的情况下,应优先使用此方法而非构造函数{@link #Integer(int)},
* 因为该方法通过缓存频繁请求的值,可能显著提高空间和时间性能。
*
* 该方法总是缓存-128到127(包含)范围内的值,
* 并可能缓存此范围外的其他值。
*
* @param i 一个int值
* @return 表示i的Integer实例
* @since 1.5
*/
@IntrinsicCandidate
public static Integer valueOf(int i) {
// 检查值是否在缓存范围内
if (i >= IntegerCache.low && i <= IntegerCache.high)
// 返回缓存的Integer实例
return IntegerCache.cache[i + (-IntegerCache.low)];
// 不在缓存范围内则创建新实例
return new Integer(i);
}步入add方法:
protected transient int modCount = 0;
/**
* 将指定元素追加到列表末尾。
*
* @param e 要追加到列表的元素
* @return {@code true}(遵循 {@link Collection#add} 的规范)
*/
public boolean add(E e) {
modCount++; // 结构性修改计数+1(用于迭代器的快速失败机制)
add(e, elementData, size); // 实际添加逻辑(内部方法处理扩容和插入)
return true; // ArrayList的add操作始终成功
} modCount用于记录结构性修改次数(用于 fail-fast 机制,在并发修改时抛出 ConcurrentModificationException)。
再步入这里的add方法:
/**
* 内部实现的元素添加方法,处理实际的数据存储和扩容逻辑
*
* @param e 待添加的元素
* @param elementData 当前存储数据的数组
* @param s 当前列表大小(即下一个要插入的位置索引)
*/
private void add(E e, Object[] elementData, int s) {
// 检查数组是否已满
if (s == elementData.length)
// 触发扩容并获取新数组
elementData = grow();
// 将元素放入数组末尾
elementData[s] = e;
// 更新列表大小
size = s + 1;
}逻辑已经在注释中标注出,接下来步入grow()方法:
private Object[] grow() {
return grow(size + 1);
}再次步入grow方法:
/**
* 增加容量以确保至少能容纳指定的最小元素数量
*
* @param minCapacity 期望的最小容量
* @throws OutOfMemoryError 如果最小容量为负数
*/
private Object[] grow(int minCapacity) {
int oldCapacity = elementData.length;
// 当已有容量>0,或当前数组不是默认空数组时触发标准扩容逻辑
if (oldCapacity > 0 || elementData != DEFAULTCAPACITY_EMPTY_ELEMENTDATA) {
// 计算新容量:旧容量的1.5倍(通过右移1位实现),同时满足最小扩容需求
int newCapacity = ArraysSupport.newLength(oldCapacity,
minCapacity - oldCapacity, // 最小增量
oldCapacity >> 1 // 推荐增量(原容量50%)
);
// 创建新数组并拷贝数据[1,4](@ref)
return elementData = Arrays.copyOf(elementData, newCapacity);
} else {
// 首次扩容逻辑:取默认容量10与minCapacity的较大值[6,8](@ref)
return elementElementData = new Object[Math.max(DEFAULT_CAPACITY, minCapacity)];
}
}对于有参构造及其扩容机制
ArrayList list = new ArrayList(8);步入这里的ArrayList方法:
/**
* 构造一个具有指定初始容量的空列表
*
* @param initialCapacity 列表的初始容量
* @throws IllegalArgumentException 如果指定初始容量为负数
*/
public ArrayList(int initialCapacity) {
if (initialCapacity > 0) {
// 创建指定容量的新数组[1,3](@ref)
this.elementData = new Object[initialCapacity];
} else if (initialCapacity == 0) {
// 使用空数组标记(非延迟初始化)[3,5](@ref)
this.elementData = EMPTY_ELEMENTDATA;
} else {
// 抛出非法参数异常[1,3](@ref)
throw new IllegalArgumentException("Illegal Capacity: " + initialCapacity);
}
}这是一个跟之前不一样的构造器,可以初始化一个指定大小的空列表,具体逻辑在注释中已经写出,之后的扩容步骤和上面无参构造时候一样,都是按照当前尺寸的1.5倍进行扩容。
由此印证了上面对其扩容机制的总结。
Vector
基本特性
public class Vector<E>
extends AbstractList<E>
implements List<E>, RandomAccess, Cloneable, java.io.Serializable底层同样是对象数组。
protected Object[] elementData;操作方法基本都带有synchronized修饰符,是线程同步的吗,即线程安全,但执行效率不高。
在开发中,需要线程安全时,考虑使用Vector。
扩容机制
和ArrayList扩容机制基本一样,区别在于每次的扩容倍数是2倍而不是1.5倍。
源码和之前的ArrayList逻辑差不多:
比如无参构造:
public Vector() {
this(10);
}有参构造:
public Vector(int initialCapacity) {
this(initialCapacity, 0);
}add方法:
public synchronized boolean add(E e) {
modCount++;
add(e, elementData, elementCount);
return true;
} 步入这里的add方法:
/**
* 内部实现的辅助添加方法,从公共方法 add(E) 中拆分出来,
* 目的是控制公共方法的字节码大小不超过35(-XX:MaxInlineSize 的默认值),
* 以便在 C1 编译器优化的循环中调用 add(E) 时保持高效性。
*
* @param e 待添加的元素
* @param elementData 当前存储数据的数组
* @param s 当前列表大小(即下一个要插入的位置索引)
*/
private void add(E e, Object[] elementData, int s) {
// 检查数组是否已满
if (s == elementData.length)
// 触发扩容并获取新数组
elementData = grow();
// 将元素放入数组末尾
elementData[s] = e;
// 更新列表实际元素计数
elementCount = s + 1;
}步入这里的grow方法:
/**
* 触发扩容操作,返回扩容后的新数组
*
* @return 扩容后的新数组
*/
private Object[] grow() {
// 调用带参数的扩容方法,传入所需最小容量(当前元素数量+1)
return grow(elementCount + 1);
}步入这里的grow方法:
/**
* 扩容核心方法,确保容量至少满足指定的最小容量要求
*
* @param minCapacity 扩容后至少需要达到的最小容量
* @return 扩容后的新数组
* @throws OutOfMemoryError 如果无法分配所需容量的内存(如 minCapacity 为负数或超过 JVM 限制)
*/
private Object[] grow(int minCapacity) {
int oldCapacity = elementData.length; // 当前数组容量
// 计算新容量:基于旧容量、最小增量(minCapacity - oldCapacity)和首选增量(capacityIncrement 或 oldCapacity)
int newCapacity = ArraysSupport.newLength(
oldCapacity,
minCapacity - oldCapacity, // 必须满足的最小增量
(capacityIncrement > 0) ? capacityIncrement : oldCapacity // 首选增量
);
// 创建新数组并拷贝原数据
return elementData = Arrays.copyOf(elementData, newCapacity);
}这里也就展示完了Vector的扩容方法,和之前ArrayList较为相似。
LinkedList
基本特性
- LinkedList底层实现了双向链表和双端队列的特点;
- 可以添加任意元素,元素可以重复,包括null;
- 线程不安全,没有实现同步。
特性一示例:
// 初始化LinkedList并添加元素
LinkedList<String> linkedList = new LinkedList<>();
linkedList.add("A"); // 默认尾部插入
linkedList.addFirst("B"); // 头部插入
linkedList.addLast("C"); // 尾部插入
// 双端队列操作
linkedList.offerFirst("D"); // 等效于 addFirst
linkedList.offerLast("E"); // 等效于 addLast
System.out.println("链表结构:" + linkedList);
// 输出:[D, B, A, C, E]
// 逆向遍历(体现双向链表特性)
Iterator<String> it = linkedList.descendingIterator();
System.out.print("逆向遍历:");
while(it.hasNext()) {
System.out.print(it.next() + " "); // 输出:E C A B D
}特性二示例:
LinkedList<Object> list = new LinkedList<>();
list.add(null); // 添加null
list.add("Java");
list.add("Java"); // 重复元素
list.add(2023); // 不同类型元素
System.out.println("包含元素:" + list);
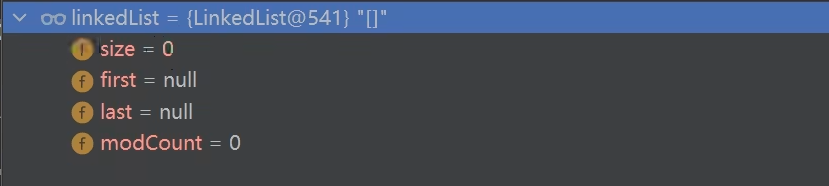
// 输出:[null, Java, Java, 2023]LinkedList底层维护了一个双向链表,通过两个属性first和last分别指向链表的首节点和尾节点。
每个链表节点由Node对象表示,内部包含三个关键属性:
prev:指向前一个节点的引用next:指向后一个节点的引用item:存储当前节点的实际数据
由于数据存储和操作完全基于链表指针(而非数组),在元素的添加和删除场景中具有较高效率。
public class Main {
public static void main(String[] args) {
MyLinkedList<String> list = new MyLinkedList<>();
// 添加元素
list.addFirst("B"); // 链表:B
list.addFirst("A"); // 链表:A -> B
list.addLast("C"); // 链表:A -> B -> C
// 遍历
list.traverseForward(); // 输出:A -> B -> C -> null
list.traverseBackward(); // 输出:C -> B -> A -> null
// 删除操作
list.removeFirst(); // 删除A,链表:B -> C
list.removeLast(); // 删除C,链表:B
list.traverseForward(); // 输出:B -> null
}
}添加机制
对于使用无参初始化的LinkedList:
增
对于add方法,源码为:
public boolean add(E e) {
linkLast(e);
return true;
}很明显是在执行尾插操作,再次步入,可以看到尾插操作的具体逻辑:
void linkLast(E e) {
final Node<E> l = last; // 1. 获取当前尾节点
final Node<E> newNode = new Node<>(l, e, null); // 2. 创建新节点
last = newNode; // 3. 更新尾节点为新节点
if (l == null) { // 4.1 原链表为空
first = newNode; // 首尾均指向新节点
} else { // 4.2 原链表非空
l.next = newNode; // 原尾节点的 next 指向新节点
}
size++; // 5. 链表长度 +1
modCount++; // 6. 并发修改计数 +1
}删
接下来是删除remove方法有参时的源码:
public E remove(int index) {
checkElementIndex(index); // 1. 校验索引合法性
return unlink(node(index)); // 2. 通过索引定位节点并解除链接
}步入checkElementIndex方法:
/**
* 校验指定索引是否在有效元素范围内(0 ≤ index < size)。
* 若索引非法,抛出包含具体越界信息的 IndexOutOfBoundsException。
*
* @param index 待校验的索引值
* @throws IndexOutOfBoundsException 当索引越界时抛出(参考网页1、网页3、网页9)
*/
private void checkElementIndex(int index) {
// 调用 isElementIndex 判断索引是否合法(网页5、网页7)
if (!isElementIndex(index)) {
// 生成包含索引值和链表当前长度的错误信息(网页2、网页8)
throw new IndexOutOfBoundsException(outOfBoundsMsg(index));
}
}
/**
* 判断索引是否属于有效元素范围(0 ≤ index < size)。
* 用于元素访问类操作(如 get、remove)。
*
* @param index 待校验的索引值
* @return true 表示索引合法,false 表示越界(网页9、网页10)
*/
private boolean isElementIndex(int index) {
return index >= 0 && index < size; // 校验索引下限和上限(网页1、网页5)
}
/**
* 生成索引越界异常信息模板,格式:"Index: {index}, Size: {size}"。
*
* @param index 引发异常的非法索引值
* @return 包含索引和链表长度的错误描述字符串(网页7、网页8)
*/
private String outOfBoundsMsg(int index) {
return "Index: " + index + ", Size: " + size;
}主要对数据进行删除操作的还是unlink方法:
E unlink(Node<E> x) {
final E element = x.item;
final Node<E> next = x.next;
final Node<E> prev = x.prev;
// 处理前驱节点
if (prev == null) {
first = next; // 删除头节点,更新头指针
} else {
prev.next = next; // 前驱节点指向后继节点
x.prev = null; // 清理被删节点的前驱引用
}
// 处理后继节点
if (next == null) {
last = prev; // 删除尾节点,更新尾指针
} else {
next.prev = prev; // 后继节点指向前驱节点
x.next = null; // 清理被删节点的后继引用
}
x.item = null; // 释放数据引用
size--; // 链表长度减1
modCount++; // 并发修改计数更新
return element;
}对于remove方法的无参使用,就是默认删除表头:
/**
* 移除并返回此列表的头部元素(第一个元素)。
* 若链表为空,则抛出 NoSuchElementException 异常。
*
* @return 链表的头部元素
* @throws NoSuchElementException 如果链表为空
* @since 1.5 (从 Java 1.5 版本开始提供)
*/
public E remove() {
return removeFirst(); // 直接调用 removeFirst() 方法实现头部删除操作[1,6](@ref)
}步入removeFirst方法:
/**
* 移除并返回链表的第一个元素(头节点)。
* 若链表为空,抛出 NoSuchElementException 异常。
*
* @return 链表的第一个元素
* @throws NoSuchElementException 当链表为空时抛出(触发条件见网页3[3](@ref))
*/
public E removeFirst() {
final Node<E> f = first; // 1. 获取当前头节点引用(网页2[2](@ref))
if (f == null)
throw new NoSuchElementException(); // 2. 空链表抛出异常(网页3[3](@ref))
return unlinkFirst(f); // 3. 调用核心解链逻辑(网页6[6](@ref))
}再次步入:
private E unlinkFirst(Node<E> f) {
final E element = f.item; // 保存被删元素值
final Node<E> next = f.next; // 获取头节点的下一个节点
f.item = null; // 清理数据引用(帮助GC回收)
f.next = null; // 断开原头节点与链表的链接(网页5[5](@ref))
first = next; // 更新头节点指针(网页2[2](@ref))
if (next == null)
last = null; // 链表仅有一个节点时,尾指针置空
else
next.prev = null; // 新头节点的前驱置空(网页6[6](@ref))
size--; // 链表长度减1(网页7[7](@ref))
modCount++; // 并发修改计数更新(网页6[6](@ref))
return element; // 返回被删除元素
}可以看到这个方法用于删除链表头部元素。
改
接下来是修改数据set方法的源码:
/**
* 将链表中指定位置的元素替换为新元素,并返回被替换的旧元素。
* 若索引越界,抛出 IndexOutOfBoundsException 异常。
*
* @param index 要替换元素的索引(需满足 0 ≤ index < size)
* @param element 要存储到指定位置的新元素
* @return 被替换的旧元素
* @throws IndexOutOfBoundsException 当索引越界时抛出(参考网页3、网页5)
*/
public E set(int index, E element) {
checkElementIndex(index); // 1. 校验索引合法性(网页5、网页7)
Node<E> x = node(index); // 2. 通过二分法遍历定位目标节点(网页6、网页9)
E oldVal = x.item; // 3. 保存旧元素值
x.item = element; // 4. 更新节点存储的新元素(网页3、网页7)
return oldVal; // 5. 返回被替换的旧元素(网页3、网页7)
}逻辑较为简单。
查
查询数据get的方法:
/**
* 获取链表中指定索引位置的元素。
* 若索引越界(index < 0 或 index ≥ size),抛出 IndexOutOfBoundsException 异常。
*
* @param index 要获取元素的索引(需满足 0 ≤ index < size)
* @return 对应索引位置的元素值
* @throws IndexOutOfBoundsException 当索引越界时抛出(参考网页2、网页5、网页7)
*/
public E get(int index) {
checkElementIndex(index); // 1. 校验索引合法性(网页5、网页7)
return node(index).item; // 2. 定位节点并返回其存储的数据(网页2、网页6、网页7)
}再次步入node方法:
/**
* 根据指定索引定位链表中的节点,采用二分法优化遍历效率。
*
* @param index 目标节点索引(需满足 0 ≤ index < size)
* @return 指定索引位置的节点对象
*/
Node<E> node(int index) {
// 断言:索引已通过合法性校验(参考网页3、网页5的checkElementIndex逻辑)
// 判断索引是否在链表前半段(size >> 1等价于size/2,位运算优化性能)
if (index < (size >> 1)) { // [3,6](@ref)
Node<E> x = first; // 从头节点开始遍历
for (int i = 0; i < index; i++)// 循环index次,逐级访问后继节点
x = x.next; // [1,8](@ref)
return x;
} else { // 索引位于链表后半段
Node<E> x = last; // 从尾节点开始遍历
for (int i = size - 1; i > index; i--) // 循环(size-1 - index)次
x = x.prev; // 逐级访问前驱节点[4,5](@ref)
return x;
}
}可以看到这个方法的核心逻辑就是二分查找。
Collection(Set接口)
Set接口以及使用
Set接口主要具有的两大特性是元素无序性和不可重复,代码演示如下:
import java.util.HashSet;
import java.util.Set;
public class SetDemo {
public static void main(String[] args) {
// 特性1:无序性演示
Set<String> languages = new HashSet<>();
languages.add("Java");
languages.add("Python");
languages.add("C++");
languages.add("JavaScript");
System.out.println("添加顺序:Java → Python → C++ → JavaScript");
System.out.println("实际存储顺序:" + languages);
// 可能输出:[Java, C++, JavaScript, Python](顺序随机)
// 特性2:元素唯一性演示
languages.add("Java"); // 重复元素
languages.add(null); // 第一个null
languages.add(null); // 重复null
System.out.println("添加重复元素后:" + languages);
// 始终输出:[Java, C++, JavaScript, Python, null](去重后)
}
}和List接口一样,Set接口也是Collection的子接口,常用方法和Collection接口一样。
遍历方式也和Collection接口一样,但是不能使用索引的方式来获取。
注意:取出元素的顺序虽然不一定和存入的顺序一致,但是是固定的(具体在后面源码中分析)。
HashSet
基本特性
HashSet实际上是HashMap,从源码中可以看出:
/**
* 创建一个新的空集合,其底层基于初始容量为16、
* 负载因子为0.75的HashMap实现。
*
*/
public HashSet() {
map = new HashMap<>(); // 通过HashMap实现Set接口特性
}它可以存放空值,但是只能存放一个null。
在执行add方法时,会返回一个布尔值,源码如下:
/**
* @param e 要添加到集合中的元素
* @return 如果集合因调用而改变(即元素是新添加的)则返回 {@code true},
* 如果集合已包含该元素则返回 {@code false}
*/
public boolean add(E e) {
return map.put(e, PRESENT)==null; // 利用HashMap键的唯一性实现去重
}扩容机制
HashMap底层通过哈希表(数组+链表/红黑树)存储数据,添加元素时会先计算键的哈希值并转换为数组索引;若该索引位置为空则直接插入,若已存在元素(哈希冲突),则遍历链表逐一用equals()比较键值——相同则覆盖,不同则追加到链表尾部;当链表长度超过TREEIFY_THRESHOLD(默认8)且数组容量达到MIN_TREEIFY_CAPACITY(默认64)时,链表会转化为红黑树以提高查询效率。整个过程融合了哈希函数、拉链法和树化策略,兼顾哈希表的高效性与冲突处理的健壮性。
LinkedHashSet
基本特性
public class LinkedHashSet<E>
extends HashSet<E>
implements Set<E>, Cloneable, java.io.SerializableLinkedHashSet继承了HashSet。
它的底层是一个LinkedHashMap,底层维护的是一个数组 + 双向链表。
无参构造的源码:
public LinkedHashSet() {
super(16, .75f, true);
}再次步入:
/**
* 构造一个新的、空的链式哈希集合。(此包内私有构造器仅由LinkedHashSet使用)
* 底层HashMap实例是一个具有指定初始容量和加载因子的LinkedHashMap。
*
* @param initialCapacity 哈希映射的初始容量
* @param loadFactor 哈希映射的加载因子
* @param dummy 忽略此参数(用于区分该构造器与其他int/float参数的构造器)
* @throws IllegalArgumentException 如果初始容量小于零,或加载因子非正数
*/
HashSet(int initialCapacity, float loadFactor, boolean dummy) {
map = new LinkedHashMap<>(initialCapacity, loadFactor); // 使用LinkedHashMap实现链式存储[2,6](@ref)
}LinkedHashSet根据元素的HashCode值来决定元素的存储位置,同时使用链表维护元素的次序,使得元素看起来是以插入顺序保存的。
底层机制
| 特性 | HashSet | LinkedHashSet |
|---|---|---|
| 底层结构 | 哈希表 | 哈希表 + 双向链表 |
| 遍历顺序 | 无序 | 严格按插入顺序 |
| 内存占用 | 较低 | 较高(每个节点多存两个指针) |
| 适用场景 | 只需快速去重 | 需去重且保留插入/访问顺序的场景 |
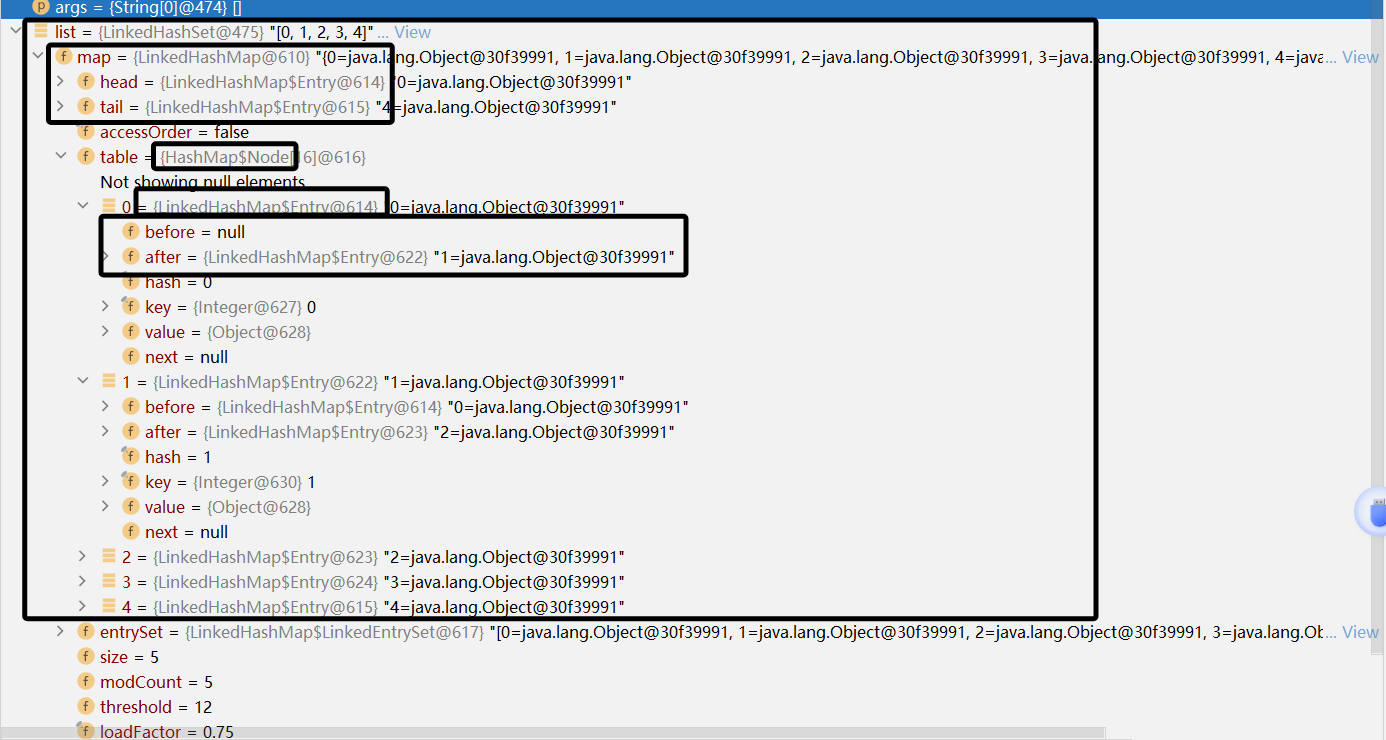
第一次添加元素时,直接将数组 table 扩容到 16 ,存放的结点类型是LinkedHashMap$Entry,但是table 的类型为HashMap$Node。
为什么会有这种现象,在LinkedHasgMap的源码中可以看到他们之间的继承关系:
/**
* LinkedHashMap 的专用节点类,继承自 HashMap.Node。
* 在 HashMap 哈希表结构的基础上,通过维护双向链表实现元素的有序性。
* (对应 LinkedHashSet 的底层实现,用于记录插入顺序或访问顺序)[3,6,7](@ref)
*/
static class Entry<K,V> extends HashMap.Node<K,V> {
// 双向链表的前驱和后继指针,用于按插入顺序或访问顺序链接节点
Entry<K,V> before, after;
/**
* 构造一个新的链表节点。
*
* @param hash 键的哈希值(通过 key.hashCode() 计算并扰动处理)[3](@ref)
* @param key 节点的键(对应 LinkedHashSet 中的元素值)
* @param value 节点的值(固定为 LinkedHashSet 中的虚拟占位对象 PRESENT)[5,7](@ref)
* @param next 哈希表中同一桶内的下一个节点(解决哈希冲突的链表指针)[3](@ref)
*/
Entry(int hash, K key, V value, Node<K,V> next) {
super(hash, key, value, next); // 调用父类 HashMap.Node 的构造方法
}
}关于他们之间的对比:
| 特性 | HashMap.Node | LinkedHashMap.Entry |
|---|---|---|
| 数据结构 | 单向链表(哈希冲突链) | 双向链表(顺序维护) + 哈希表 |
| 遍历顺序 | 无序 | 按插入或访问顺序 |
| 内存占用 | 较低(仅 next 指针) | 较高(before + after 指针) |
注意,从源码中可以看到:Node是HashMap的静态内部类,为什么要这么写呢?原因如下:
- 避免内存泄漏:若
Node设计为非静态内部类,则每个Node实例会隐式持有外部HashMap对象的引用(通过Outer.this)。当HashMap对象不再被使用时,若其内部的Node仍被其他结构(如迭代器)引用,会导致HashMap实例无法被垃圾回收(GC),产生内存泄漏。静态内部类不依赖外部类实例,仅能访问外部类的静态成员。这使得Node对象与HashMap实例解耦,即使HashMap被销毁,Node仍可独立存在或被回收,避免了内存泄漏风险。 - 独立存储结构:
Node作为哈希表的基础存储单元,其功能(存储键值对、处理哈希冲突)与HashMap的业务逻辑(扩容、树化)相对独立。通过静态内部类设计,Node可专注于数据存储,提升代码模块化程度。 - 支持序列化:静态
Node无需携带外部类引用,序列化时仅存储必要数据(键、值、哈希、链表指针),既节省空间又保证反序列化时的正确性。 - 节省内存:每个
Node实例节省了隐式外部类引用的存储空间(通常为4-8字节),在存储海量数据时显著减少内存消耗。
add方法依然走的父类的HashSet的源码流程(HashSet-->HasgMap)。
整个的添加过程,都会有指针追踪前驱元素和后继元素,确保遍历时候与插入顺序的一致性。
下图可以看到各个部分的结构:
TreeSet
基本特点以及相关源码
TreeSet底层是TreeMap。
无参构造的 TreeSet 是有序的,但排序规则由元素类自身的 Comparable 实现决定。若未显式定义比较器且元素类未实现自然排序,则会因无法比较而报错。
当希望TreeSet中的字符串元素按照自定义的顺序进行排序的时候,可以传入一个比较器(匿名内部类),并指定排序规则。
示例,按照字母的反向进行输出:
import java.util.*;
public class StudyCollection {
public static void main(String[] args) {
TreeSet treeSet = new TreeSet(new Comparator() {
@Override
public int compare(Object o1, Object o2) {
//调用String的compareTo方法进行大小值比较
return ((String)o2).compareTo((String)o1);
}
});
treeSet.add("A");
treeSet.add("B");
treeSet.add("C");
treeSet.add("D");
treeSet.add("E");
treeSet.add("F");
System.out.println(treeSet);
}
}
输出结果为:
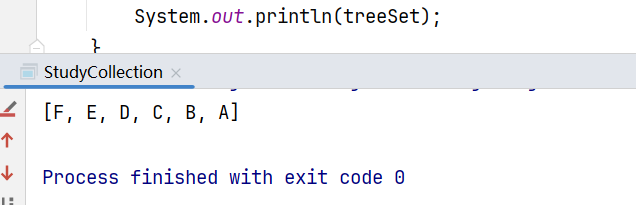
其中的compareTo方法:
/**
* 按字典顺序比较当前字符串与目标字符串
*
* @param anotherString 要比较的目标字符串
* @return 正数(当前字符串大)、负数(当前字符串小)或0(相等)
*/
public int compareTo(String anotherString) {
// 获取当前字符串的字节数组(根据编码存储字符数据)
byte v1[] = value;
// 获取目标字符串的字节数组
byte v2[] = anotherString.value;
// 获取当前字符串的编码格式(LATIN1或UTF16)
byte coder = coder();
// 如果两字符串编码格式相同
if (coder == anotherString.coder()) {
// LATIN1编码(单字节字符集)的比较
return coder == LATIN1 ? StringLatin1.compareTo(v1, v2)
// UTF16编码(双字节字符集)的比较
: StringUTF16.compareTo(v1, v2);
}
// 编码格式不同时的跨编码比较
return coder == LATIN1 ?
// 将当前LATIN1编码转换为UTF16后比较
StringLatin1.compareToUTF16(v1, v2)
// 将目标LATIN1编码转换为UTF16后比较
: StringUTF16.compareToLatin1(v1, v2);
}当参数中创建了一个比较器对象时,会有:
public TreeSet(Comparator<? super E> comparator) {
this(new TreeMap<>(comparator));
}
public TreeMap(Comparator<? super K> comparator) {
this.comparator = comparator;
}所以实际上是把自定义的比较器对象传递给底层的TreeMape的比较器。
具体debug时,可以看到核心逻辑在于:
private V put(K key, V value, boolean replaceOld) {
Entry<K,V> t = root; // 获取红黑树的根节点
if (t == null) { // 当前树为空时(首次插入)
addEntryToEmptyMap(key, value); // 调用方法初始化根节点
return null; // 无旧值可返回
}
int cmp; // 存储键比较结果
Entry<K,V> parent; // 记录当前遍历节点的父节点
Comparator<? super K> cpr = comparator; // 获取自定义比较器
if (cpr != null) { // 存在自定义比较器时的处理逻辑
do {
parent = t; // 记录父节点位置
cmp = cpr.compare(key, t.key); // 使用比较器比较键值
if (cmp < 0) // 新键小于当前节点键,向左子树遍历
t = t.left;
else if (cmp > 0) // 新键大于当前节点键,向右子树遍历
t = t.right;
else { // 找到相同键时的处理
V oldValue = t.value; // 获取旧值
if (replaceOld || oldValue == null) { // 根据参数决定是否覆盖
t.value = value; // 更新节点值
}
return oldValue; // 返回旧值(可能为null)
}
} while (t != null); // 循环直到找到叶子节点位置
}
// …………………………
}cmp = cpr.compare(key, t.key); // 使用比较器比较键值
这行代码是正式调用比较器参数的地方。
同样,从代码中,可以看到符合相同条件的元素,视为key相同,不进行元素的替换!
示例:自定义成别的比较方法,比如按照字符串长度进行排序:
此处同时有“CCC”和“DDD”,这时候会把这两个元素视为一样的!
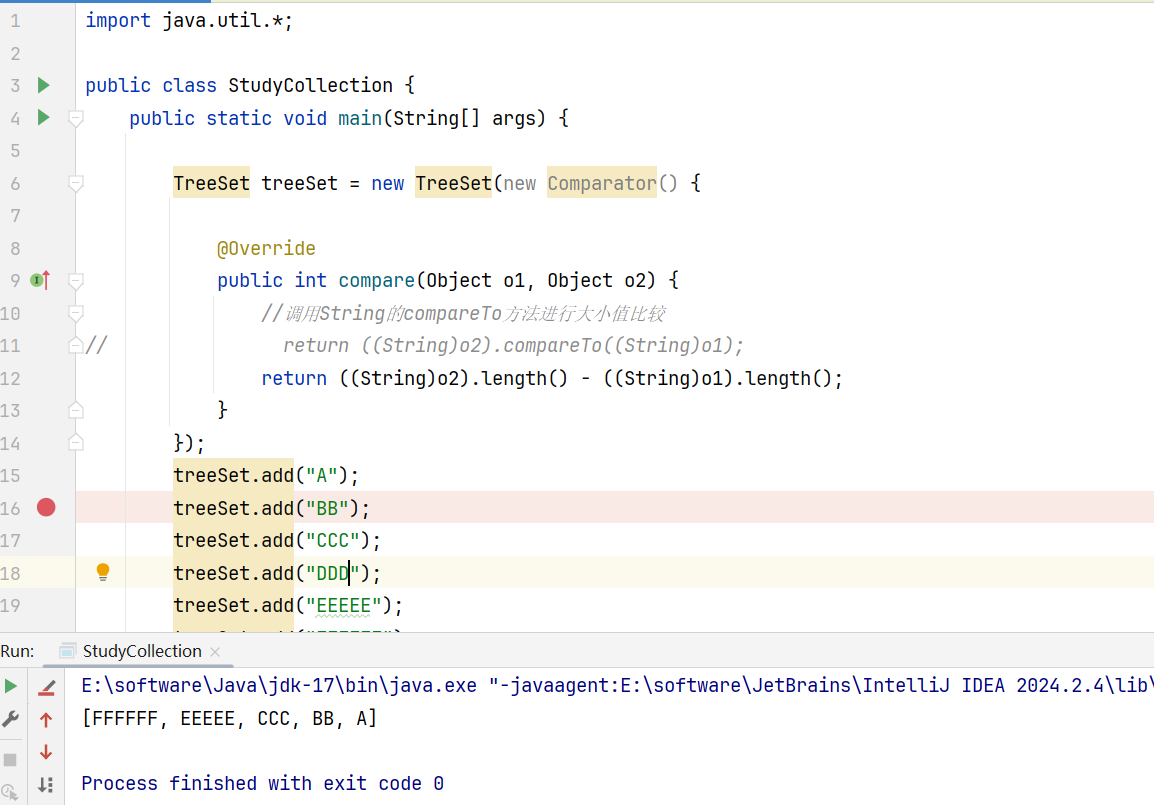
可以看到“DDD”没有被添加进去!
强调
一般思维会想,TreeSet底层是TreeMap,Map遇到重复值不是会替代原来的吗?
上面例子中,TreeSet 拒绝添加重复元素而非替换,源于其 底层设计与 Set 接口的语义约束:
TreeSet 内部通过 TreeMap 实现,其元素作为 TreeMap 的 Key 存在,而 Value 则是一个固定占位符 PRESENT(如 private static final Object PRESENT = new Object())。当添加元素时,实际执行的是 TreeMap.put(key, PRESENT)。若 Key 已存在(即比较器返回 0),TreeMap 会更新 Value,但 PRESENT 始终不变,因此 TreeSet 对外表现为“拒绝添加”而非替换。
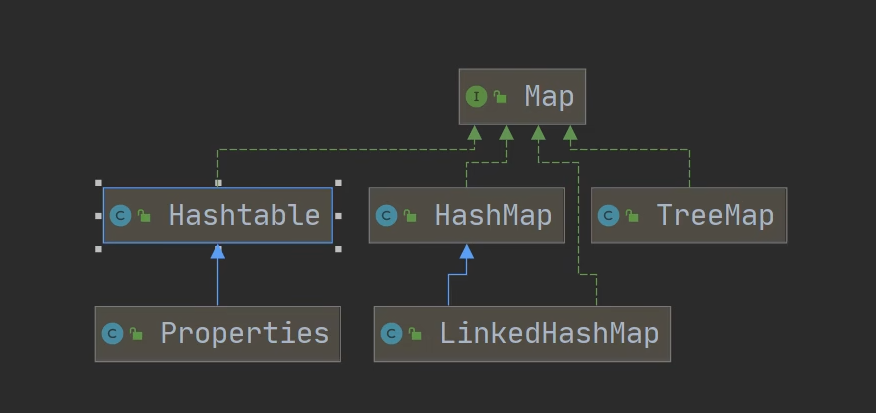
Map接口
Map接口以及使用
Map接口用于保存具有映射关系的数据:Key-Value。
Key不允许重复,原因和HashSet一样,但是Value可以重复。
键(Key)唯一性的底层原理
核心机制:通过 哈希码(hashCode) 和 对象相等性(equals) 双重验证保证唯一性
具体流程:
- 哈希定位:调用
key.hashCode()计算哈希值,确定数组索引位置。 - 冲突处理:若该位置已有元素,遍历链表/红黑树,通过
key.equals()逐一比较:
- 相等:覆盖旧值(HashMap)或视为重复元素(HashSet);
- 不相等:添加新节点到链表或树中。
Map<String, Integer> map = new HashMap<>();
// 添加键值对(Key唯一性)
map.put("apple", 10); // 新键
map.put("banana", 20); // 新键
map.put("apple", 20); // 重复键,覆盖旧值
System.out.println(map); // 输出: {banana=20, apple=30}Key和Value的值可以为null,最多一个Key为null。
使用get方案可以获取相对应的Value。
Map中的Key和Value可以是任何引用类型的数据,会封装到HashMap$Node对象中。
一对k-v是放在一个Node中的,因为Node实现了Entry接口,所以也可以说一堆k-v就是一个Entry。
可以从put方法中可以看出:
public V put(K key, V value) {
// 调用 putVal 方法实现具体逻辑,其中:
// - hash(key):通过扰动函数计算键的哈希值(高位与低位异或,减少冲突概率)[3](@ref)
// - onlyIfAbsent=false:允许覆盖旧值
// - evict=true:允许扩容(LinkedHashMap 可能用到)
return putVal(hash(key), key, value, false, true);
}
final V putVal(
int hash, // 键的扰动哈希值
K key, // 键对象
V value, // 值对象
boolean onlyIfAbsent, // 是否仅在旧值为空时覆盖
boolean evict // 是否触发扩容或回调(LinkedHashMap 使用)
) {
Node<K,V>[] tab; // 哈希表数组
Node<K,V> p; // 当前桶的头节点
int n, i; // n=数组长度,i=桶索引
// 1. 初始化哈希表(首次插入或扩容后)
if ((tab = table) == null || (n = tab.length) == 0) {
n = (tab = resize()).length; // 调用 resize() 初始化或扩容[7](@ref)
}
// 2. 计算桶索引:(n-1) & hash,等价于取模运算但更高效[1,3](@ref)
i = (n - 1) & hash;
p = tab[i];
// 3. 处理空桶:直接插入新节点
if (p == null) {
tab[i] = newNode(hash, key, value, null); // 创建普通链表节点
}
// 4. 处理非空桶(哈希冲突)
else {
Node<K,V> e; // 用于临时存储重复键的节点
K k;
// 4.1 检查头节点是否与当前键重复
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k)))) {
e = p; // 标记为重复键节点
}
// 4.2 若当前桶是红黑树节点,调用红黑树插入逻辑[6](@ref)
else if (p instanceof TreeNode) {
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
}
// 4.3 遍历链表处理冲突
else {
for (int binCount = 0; ; ++binCount) {
// 4.3.1 到达链表尾部,插入新节点
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
// 链表长度≥8时树化(需数组长度≥64)[6,7](@ref)
if (binCount >= TREEIFY_THRESHOLD - 1) { // TREEIFY_THRESHOLD=8
treeifyBin(tab, hash); // 树化方法
}
break;
}
// 4.3.2 检查当前节点是否与键重复
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k)))) {
break; // 找到重复键节点
}
p = e; // 继续遍历下一个节点
}
}
// 5. 处理重复键:覆盖旧值
if (e != null) {
V oldValue = e.value;
// 根据 onlyIfAbsent 决定是否覆盖(默认覆盖)[1,5](@ref)
if (!onlyIfAbsent || oldValue == null) {
e.value = value;
}
afterNodeAccess(e); // LinkedHashMap 的回调方法(维护访问顺序)
return oldValue; // 返回旧值
}
}
// 6. 更新结构修改计数器(用于迭代器的快速失败机制)
++modCount;
// 7. 检查是否需要扩容(元素数超过阈值)
if (++size > threshold) {
resize(); // 扩容并重新分布节点[7](@ref)
}
// 8. LinkedHashMap 的回调方法(可能用于删除最旧节点)
afterNodeInsertion(evict);
return null; // 插入新键时返回 null
}可以看到这里执行了newNode方法,步入该方法:
Node<K,V> newNode(int hash, K key, V value, Node<K,V> next) {
return new Node<>(hash, key, value, next);
}可以看到返回的类型是Node,追入这里的Node类:
static class Node<K,V> implements Map.Entry<K,V> {
final int hash;
final K key;
V value;
Node<K,V> next;
Node(int hash, K key, V value, Node<K,V> next) {
this.hash = hash;
this.key = key;
this.value = value;
this.next = next;
}
public final K getKey() { return key; }
public final V getValue() { return value; }
public final String toString() { return key + "=" + value; }
public final int hashCode() {
return Objects.hashCode(key) ^ Objects.hashCode(value);
}
public final V setValue(V newValue) {
V oldValue = value;
value = newValue;
return oldValue;
}
public final boolean equals(Object o) {
if (o == this)
return true;
return o instanceof Map.Entry<?, ?> e
&& Objects.equals(key, e.getKey())
&& Objects.equals(value, e.getValue());
}
}为了方便程序员的遍历,还会创建EntrySet集合,该集合存放的元素类型为Entry,而一个Entry对象中,存放的是一个k-v。
/**
* 缓存 entrySet() 方法返回的集合视图。
* 注:AbstractMap 中的字段已用于缓存 keySet() 和 values() 的集合视图,
* 此处单独维护 entrySet 以提高访问效率。
*/
transient Set<Map.Entry<K,V>> entrySet;可以使用entrySet方法得到其运行类型:
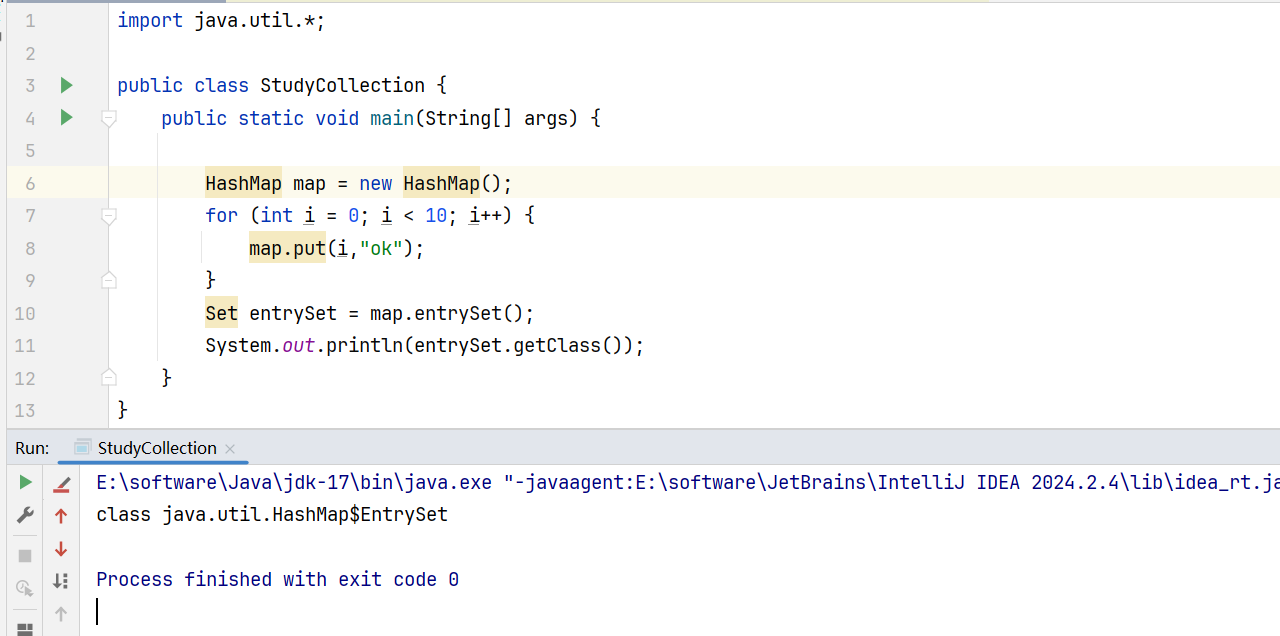
entrySet中,定义的类型是Map.Entry,但是实际上存放的还是HashMap$Node。
遍历上面entrySet中的元素,并获取运行类型,可以看到效果:
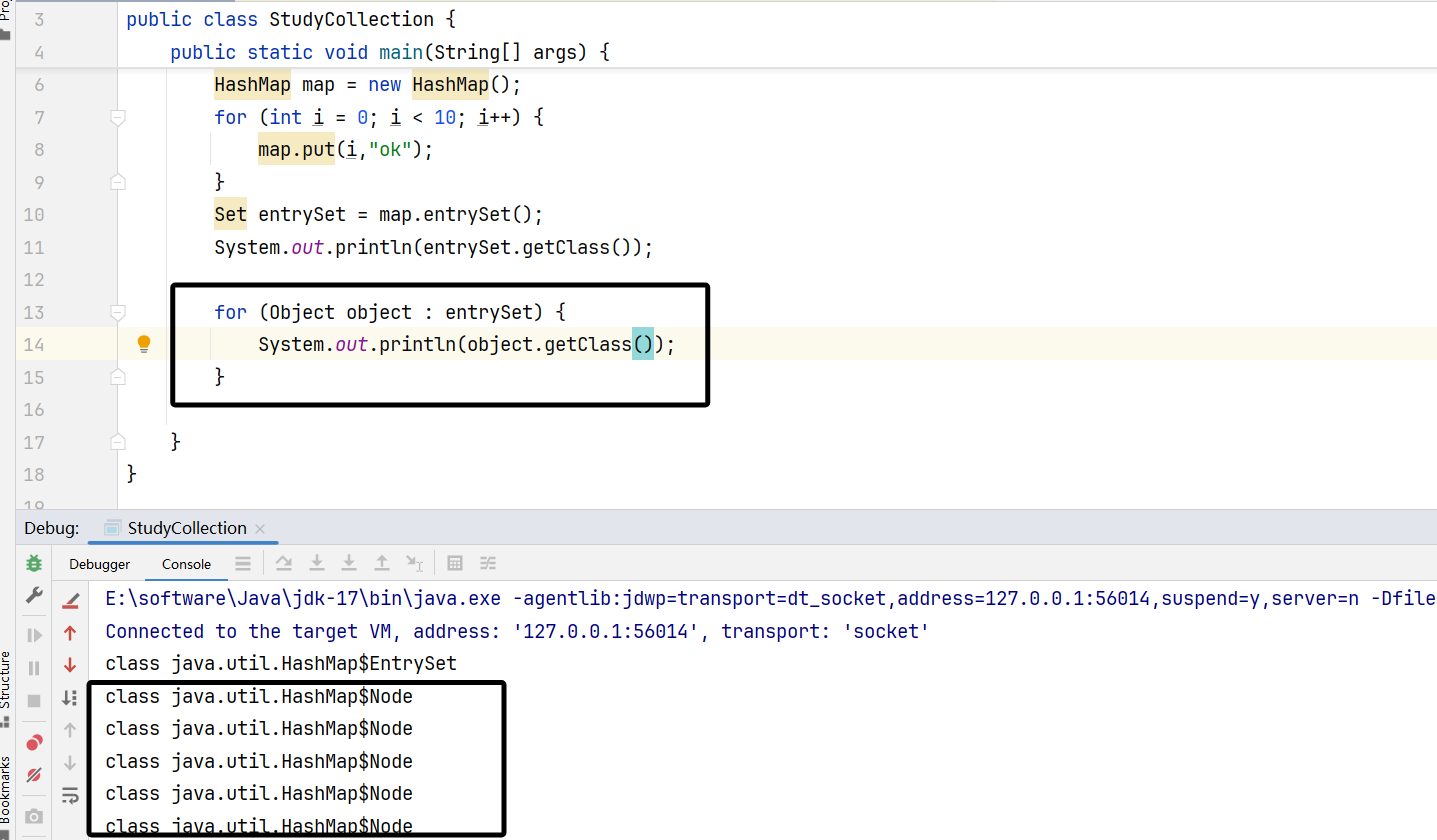
因为HashMap$Node实现了Map.Entry的接口。
这么设计的原因是:当把HashMap$Node对象存放到EntrySet中,会方便遍历。
在EntrySet方法中,封装了两个遍历的方法:
/**
* 表示映射中的键值对条目。
* 每个条目都包含一个键(Key)和对应的值(Value),
* 并提供访问和修改这些值的核心方法。
*/
interface Entry<K, V> {
/**
* 返回此条目对应的键。
*
* @return 条目的键
* @throws IllegalStateException
* 如果此条目已被从底层映射中删除,
* 具体实现类可能(但不强制要求)抛出此异常。
*/
K getKey();
/**
* 返回此条目对应的值。如果此条目已被从底层映射中删除
* (例如通过迭代器的 {@code remove} 操作),
* 则此方法的返回结果是未定义的。
*
* @return 条目的值
* @throws IllegalStateException
* 如果此条目已被从底层映射中删除,
* 具体实现类可能(但不强制要求)抛出此异常。
*/
V getValue();
}可以利用这两个方法进行遍历:
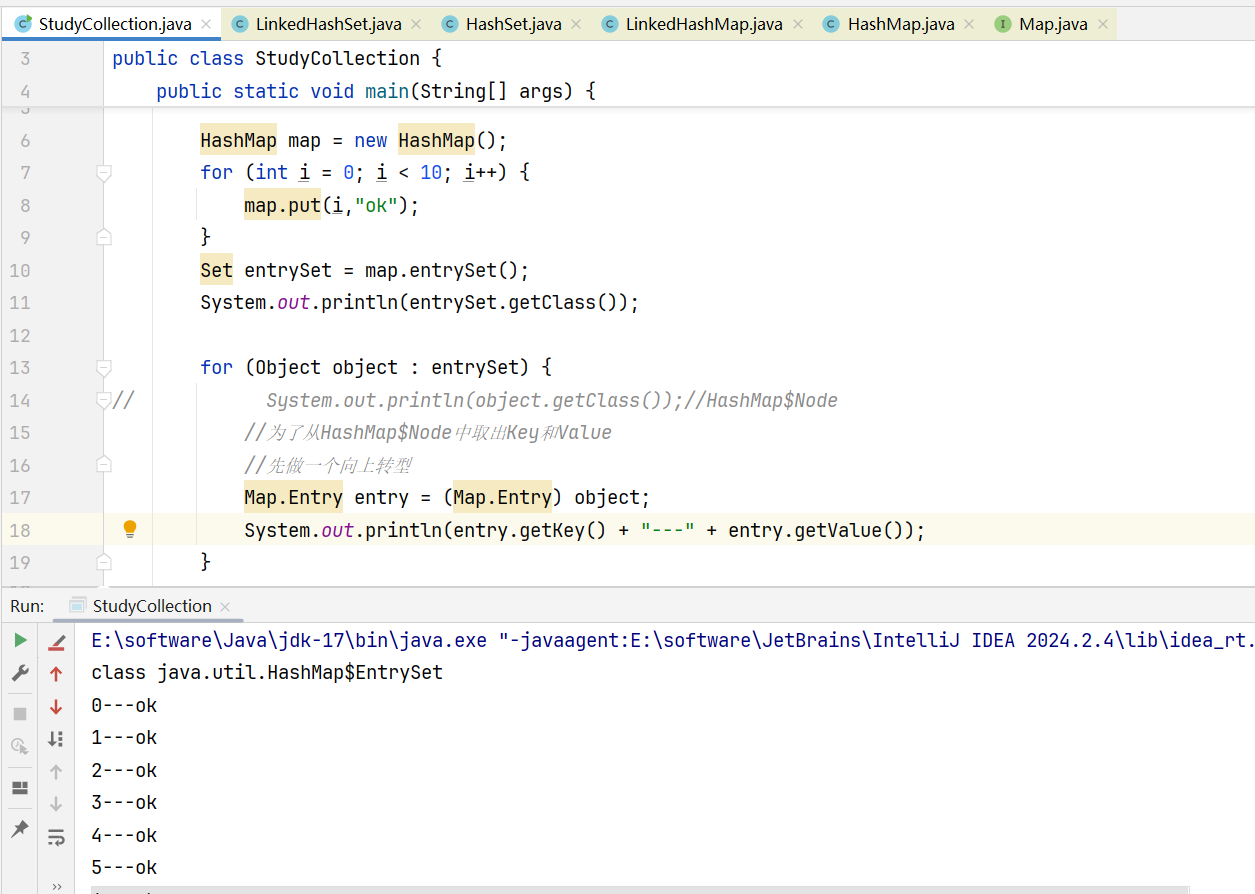
可以用keySet和values分别获取所有的Key和Value:
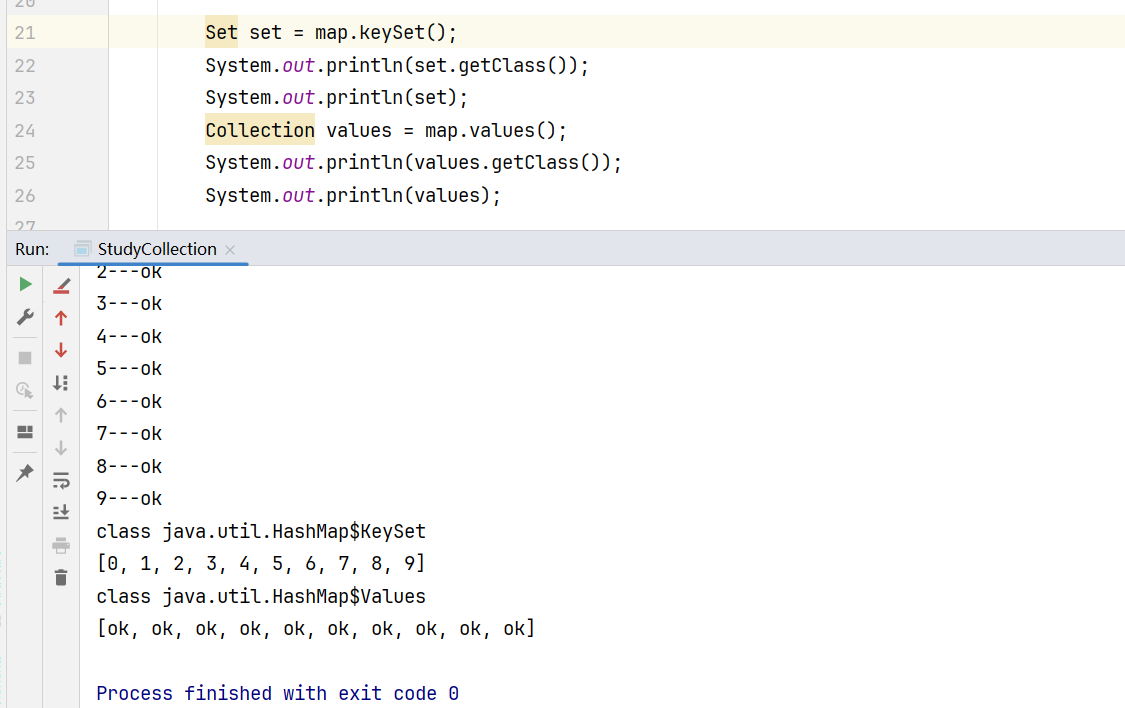
常见的Map接口方法及其使用:
import java.util.HashMap;
import java.util.Map;
public class MapMethodDemo {
public static void main(String[] args) {
// 初始化Map(以HashMap为例)
Map<String, Integer> map = new HashMap<>();
// 1. put: 添加键值对(重复键会覆盖旧值)
map.put("apple", 10); // 添加新键
map.put("banana", 20); // 添加新键
map.put("apple", 30); // 覆盖已有键的值
System.out.println("添加后Map内容: " + map);
// 输出: {banana=20, apple=30}
// 2. size: 获取元素个数
System.out.println("元素个数: " + map.size());
// 输出: 2
// 3. containsKey: 判断键是否存在
boolean hasApple = map.containsKey("apple");
boolean hasGrape = map.containsKey("grape");
System.out.println("存在apple? " + hasApple); // true
System.out.println("存在grape? " + hasGrape); // false
// 4. get: 根据键获取值
Integer appleValue = map.get("apple");
Integer grapeValue = map.get("grape");
System.out.println("apple的值: " + appleValue); // 30
System.out.println("grape的值: " + grapeValue); // null
// 5. remove: 根据键删除条目
Integer removedValue = map.remove("banana");
System.out.println("删除banana后的Map: " + map);
// 输出: {apple=30}
System.out.println("被删除的值: " + removedValue); // 20
// 6. isEmpty: 判断Map是否为空
System.out.println("Map是否为空? " + map.isEmpty()); // false
// 7. clear: 清空所有条目
map.clear();
System.out.println("清空后Map内容: " + map);
// 输出: {}
System.out.println("清空后是否为空? " + map.isEmpty()); // true
}
}Map接口的遍历方式
import java.util.*;
public class StudyCollection {
public static void main(String[] args) {
HashMap map = new HashMap();
for (int i = 0; i < 10; i++) {
map.put(i,"ok" + i);
}
System.out.println("-------第一种-------");
//1.先取出所有的key, 通过key去查对应的value
Set keySet = map.keySet();
//(1)增强for
for (Object key : keySet) {
System.out.println(key + "-" + map.get(key));
}
//(2)迭代器
System.out.println("-------第二种-------");
//2.通过EntrySet进行遍历
Set entrySet = map.entrySet();
//1.增强for
for (Object entry : entrySet) {
//把entry转换成Map.Entry
Map.Entry entry1 = (Map.Entry) entry;
System.out.println(entry1.getKey() + "-" + entry1.getValue());
}
//(2)迭代器
}
}HashMap
基本特点
与HashSet一样,不保证映射的顺序,因为底层是以hash表的形式来存储的。
HashMap没有实现同步,因此是线程不安全的。
底层机制与源码解读
扩容机制:
HashMap底层通过Node数组table存储数据,初始状态下数组为空。首次添加键值对时触发初始化,数组容量设为默认值16,并基于容量与负载因子(默认0.75)计算临界值threshold为12(16×0.75)。当元素数量超过临界值时触发扩容,新容量扩展为原容量的2倍(如16→32),临界值同步更新为新的容量×负载因子。
在Java 8中,哈希冲突处理进一步优化:当某条链表的长度超过TREEIFY_THRESHOLD(默认8)且数组容量达到MIN_TREEIFY_CAPACITY(默认64)时,链表将转换为红黑树,将查询时间复杂度从O(n)优化至O(log n)。这一机制在动态扩容与冲突解决之间实现性能平衡,兼顾存储效率与查询速度。
接下来通过源码进行解析:
import java.util.*;
public class StudyCollection {
public static void main(String[] args) {
HashMap map = new HashMap();
map.put("A", 1);
map.put("B", 2);
map.put("A", 3);
}
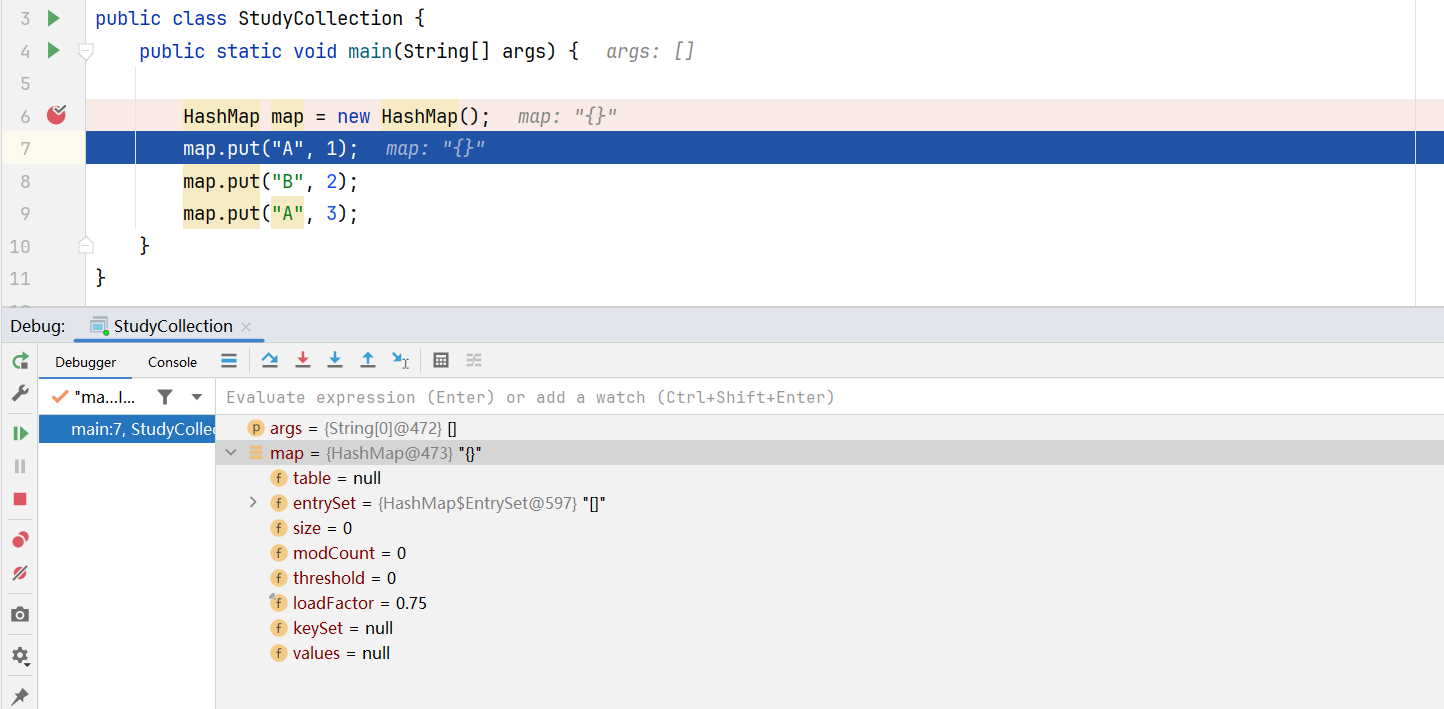
}对于无参构造HashMap(),会先初始化一个大小为0.75的加载因子(loadfactor)。
相当于执行了HashMap$Node table = null;
 接下来执行put方法:
接下来执行put方法:
/**
* 将指定值与此映射中的指定键关联。若映射中已存在该键的映射关系,则替换旧值。
*
* @param key 要关联的键(允许为 null)
* @param value 要关联的值(允许为 null)
* @return 返回与键关联的旧值,若键不存在则返回 null。
* 注意:返回 null 也可能表示键之前关联的值本身就是 null。
*/
public V put(K key, V value) {
// 调用实际存储逻辑的 putVal 方法:
// 1. hash(key):计算键的哈希值(高16位与低16位异或,优化哈希分布)
// 2. key/value:待插入的键值对
// 3. false:onlyIfAbsent 参数为 false,表示允许覆盖旧值
// 4. true:evict 参数为 true,表示允许扩容时淘汰旧数据
return putVal(hash(key), key, value, false, true);
}查看一下hash()方法,看看key的Hash值是怎么计算出来的:
/**
* 计算键(key)的哈希值,用于确定其在哈希表中的存储位置。
* 通过扰动函数优化哈希分布,减少哈希冲突概率。
*
* @param key 待计算哈希值的键(允许为 null)
* @return 优化后的哈希值(若 key 为 null 则返回 0)
*/
static final int hash(Object key) {
int h;
// 步骤 1:若 key 为 null,哈希值固定为 0(对应数组第 0 个位置)
// 步骤 2:若 key 非 null,计算其原始哈希值(h = key.hashCode())
// 步骤 3:将原始哈希值的高 16 位与低 16 位进行异或运算(h ^ (h >>> 16))
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}接下来看一下这里的putVal方法,是这里最核心的方法:
final V putVal(int hash, K key, V value, boolean onlyIfAbsent, boolean evict) {
// 声明局部变量:哈希表数组、当前桶的头节点、表长度、索引位置
Node<K,V>[] tab;
Node<K,V> p;
int n, i;
// 1. 初始化哈希表:若表未初始化或长度为0,调用resize()分配初始容量(默认16)[1,8](@ref)
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
// 2. 计算桶索引:通过 (n-1) & hash 确定位置(等效于取模运算,n为2的幂次)[4,6](@ref)
if ((p = tab[i = (n - 1) & hash]) == null)
// 若当前桶为空,直接插入新节点作为链表头节点
tab[i] = newNode(hash, key, value, null);
else {
// 3. 处理哈希冲突:当前桶已有数据(链表或红黑树)
Node<K,V> e;
K k;
// 3.1 检查头节点是否匹配:哈希值相同且键相等(==或equals())[2,8](@ref)
if (p.hash == hash && ((k = p.key) == key || (key != null && key.equals(k))))
e = p; // 标记为待更新节点
// 3.2 处理红黑树节点:若当前桶是树结构,调用树插入方法[4,6](@ref)
else if (p instanceof TreeNode)
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else {
// 3.3 遍历链表:尾插法插入新节点,或找到相同键的节点
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
// 到达链表尾部,插入新节点(JDK8优化为尾插法,避免死链)[1,8](@ref)
p.next = newNode(hash, key, value, null);
// 树化检查:链表长度≥8且数组容量≥64时转为红黑树[2,4](@ref)
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
// 找到相同键的节点,跳出循环
if (e.hash == hash && ((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e; // 继续遍历下一个节点
}
}
// 4. 覆盖旧值逻辑:若存在相同键的节点,按条件更新值并返回旧值[6,8](@ref)
if (e != null) {
V oldValue = e.value;
// onlyIfAbsent为false或旧值为null时强制覆盖
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e); // LinkedHashMap回调(维护访问顺序)
return oldValue;
}
}
// 5. 扩容检查与后续处理
++modCount; // 修改计数器(用于快速失败机制)[6](@ref)
if (++size > threshold) // 元素数量超过阈值(容量×负载因子0.75),触发扩容[1,8](@ref)
resize();
afterNodeInsertion(evict); // LinkedHashMap回调(维护插入顺序)
return null; // 插入新键时返回null
}逻辑已经在代码注释中详细写出,可以叙述如下:
以下是对 `HashMap.putVal` 方法逻辑的自然语言总结,结合代码实现与多篇技术解析:
1. 初始化与索引计算
- 首次插入检查:若哈希表未初始化(`table == null` 或长度为0),调用 `resize()` 分配默认容量 16,并计算扩容阈值(容量 × 负载因子 0.75)。
- 定位桶索引:通过 `(n-1) & hash` 计算键的存储位置(等价于取模运算,但效率更高)。
2. 处理空桶
- 直接插入:若目标桶为空(`tab[i] == null`),直接创建新节点作为链表头节点插入。
3. 哈希冲突处理
- 头节点匹配:检查桶的头节点是否与当前键相同(哈希值相等且键通过 `==` 或 `equals` 匹配)。若匹配,标记为待更新节点。
- 红黑树插入:若当前桶是红黑树结构(`TreeNode`),调用 `putTreeVal` 方法插入或更新节点。
- 链表遍历:
尾插法:遍历链表至尾部插入新节点(JDK8优化,避免并发扩容时形成环形链表)。
树化检查:若插入后链表长度 ≥8 且哈希表容量 ≥64,将链表转为红黑树(时间复杂度从 `O(n)` 优化为 `O(log n)`)。
4. 覆盖旧值逻辑
- 键已存在:若遍历过程中找到相同键的节点,根据 `onlyIfAbsent` 参数决定是否覆盖旧值(默认覆盖),并返回旧值。
- 钩子方法:调用 `afterNodeAccess()`(用于 `LinkedHashMap` 维护访问顺序)。
5. 扩容检查与触发
- 容量阈值:插入新节点后,若元素总数 size > threshold(当前容量 × 负载因子),触发 `resize()` 扩容。
- 扩容机制:
容量翻倍:新容量为旧容量的两倍(`newCap = oldCap << 1`),确保容量始终为 2的幂次。
数据迁移:重新计算所有节点的索引,链表拆分为高位链和低位链(优化迁移效率)。
此方法通过分层处理冲突、动态扩容和树化机制,确保 `HashMap` 在多数场景下保持高效性。
关于其中的树化操作,可以步入其中的treeifyBin方法:
/**
* 将指定哈希桶中的链表节点替换为红黑树节点。
* 若当前哈希表容量不足(小于MIN_TREEIFY_CAPACITY),则优先扩容而非树化。
*
* @param tab 哈希表数组
* @param hash 当前键的扰动哈希值
*/
final void treeifyBin(Node<K,V>[] tab, int hash) {
// 核心逻辑分两阶段:容量不足时扩容,否则转换为红黑树
int n, index;
Node<K,V> e;
// 1. 容量检查:若表为空或容量小于64(MIN_TREEIFY_CAPACITY),优先扩容[1,2,5](@ref)
if (tab == null || (n = tab.length) < MIN_TREEIFY_CAPACITY)
resize(); // 扩容而非树化
// 2. 树化逻辑:容量足够时,将链表转换为红黑树
else if ((e = tab[index = (n - 1) & hash]) != null) {
TreeNode<K,V> hd = null, tl = null; // 红黑树的头尾节点
do {
// 2.1 节点转换:将普通Node替换为TreeNode,构建双向链表[6](@ref)
TreeNode<K,V> p = replacementTreeNode(e, null);
if (tl == null)
hd = p; // 头节点初始化
else {
p.prev = tl; // 前驱指针
tl.next = p; // 后继指针(双向链表结构)
}
tl = p; // 更新尾节点
} while ((e = e.next) != null); // 遍历原链表所有节点
// 2.2 树化操作:将双向链表转换为红黑树[3,6](@ref)
if ((tab[index] = hd) != null)
hd.treeify(tab); // 调用TreeNode内部方法构建红黑树
}
}总结逻辑就是:
在链表长度超过 8 时触发树化逻辑,但优先检查哈希表容量是否达到 64,若未达到则通过扩容(`resize()`)重新分布数据以减少冲突,而非直接树化。若容量满足条件,则将链表节点转换为 `TreeNode` 并构建双向链表,随后通过 `treeify()` 方法将双向链表转换为红黑树,通过旋转和染色保证平衡性,将查询效率从链表的 O(n) 提升至红黑树的 O(log n)。树化阈值(8)与退化阈值(6)的错位设计避免了频繁结构转换,而线程不安全特性要求高并发场景需使用 `ConcurrentHashMap`。
HashTable
基本特点
HashTable也实现了Map接口,和HashMap是平级的关系。
public class Hashtable<K,V>
extends Dictionary<K,V>
implements Map<K,V>, Cloneable, java.io.Serializable它的键和值都不能为null,否则会抛出NullPointerExpception。
它的使用方法基本上和HashMap一样。
HashTable是线程安全的,HashMap是线程不安全的。
简单说一下HashTable的数组:
底层是数组,HashTable$Entry,初始化大小为11,加载因子为0.75,初始的threshold就是8。
扩容机制
对于添加元素,最核心的是底层中的addEntry方法:
private void addEntry(int hash, K key, V value, int index) {
Entry<?,?> tab[] = table; // 获取当前哈希表数组
// 1. 扩容检查与触发(当元素数量超过阈值时)
if (count >= threshold) { // [3,7](@ref)
rehash(); // 执行扩容操作(重新分配桶数组并迁移数据)
tab = table; // 更新为扩容后的新数组
hash = key.hashCode(); // 重新计算键的哈希值
index = (hash & 0x7FFFFFFF) % tab.length; // 重新计算索引(确保非负)
}
// 2. 创建新条目并插入链表头部
@SuppressWarnings("unchecked")
Entry<K,V> e = (Entry<K,V>) tab[index]; // 获取原桶位置的链表头节点
tab[index] = new Entry<>(hash, key, value, e); // [1,4](@ref)
// 新建Entry对象,并将原链表头作为新节点的next指针(头插法)
// 3. 更新状态计数器
count++; // 当前哈希表总元素数+1
modCount++; // 结构修改计数器+1(用于迭代器快速失败机制)[6](@ref)
}可以看到rehash是执行扩容操作的方法,步入:
/**
* 执行哈希表扩容操作(Hashtable的rehash实现)
* 核心流程:创建新容量数组 → 遍历旧表节点 → 重新计算索引 → 迁移至新表[1](@ref)
*/
protected void rehash() {
// 1. 保存旧表参数
int oldCapacity = table.length;
Entry<?,?>[] oldMap = table;
// 2. 计算新容量(旧容量*2+1,但不超过最大限制)
int newCapacity = (oldCapacity << 1) + 1; // 左移一位等效乘2
if (newCapacity - MAX_ARRAY_SIZE > 0) { // 溢出检查
if (oldCapacity == MAX_ARRAY_SIZE) return; // 已达上限不扩容
newCapacity = MAX_ARRAY_SIZE; // 强制设置为最大容量
}
// 3. 创建新哈希表数组
Entry<?,?>[] newMap = new Entry<?,?>[newCapacity];
// 4. 更新表状态参数
modCount++; // 结构修改计数器(用于迭代器快速失败机制[1,5](@ref))
threshold = (int)Math.min(newCapacity * loadFactor, MAX_ARRAY_SIZE + 1); // 新阈值=容量*负载因子
table = newMap; // 切换哈希表引用
// 5. 数据迁移(双重循环遍历旧表所有节点)
for (int i = oldCapacity; i-- > 0 ;) { // 倒序遍历旧数组
for (Entry<K,V> old = (Entry<K,V>)oldMap[i]; old != null ;) { // 遍历链表
Entry<K,V> e = old;
old = old.next; // 暂存后继节点
// 5.1 计算新索引(与HashMap不同,未优化高位运算[6](@ref))
int index = (e.hash & 0x7FFFFFFF) % newCapacity; // 确保哈希值为正数后取模
// 5.2 头插法插入新链表(线程不安全,需外部同步[1](@ref))
e.next = (Entry<K,V>)newMap[index]; // 新节点指向原链表头
newMap[index] = e; // 更新链表头为新节点
}
}
}总结来说:HashTable的底层扩容机制同样通过动态调整容量来平衡哈希冲突与空间效率。
当元素数量超过阈值(阈值 = 当前容量 × 负载因子,默认负载因子为0.75)时触发扩容,新容量计算为旧容量的两倍加一(int newCapacity = (oldCapacity << 1) + 1; // 左移一位等效乘2),但不超过预设的最大容量限制(如 `MAX_ARRAY_SIZE`)。扩容过程中,所有元素需通过全量重哈希重新计算索引(采用 `(hash & 0x7FFFFFFF) % newCapacity` 取模运算),并以头插法迁移到新数组的对应链表中,这一过程效率较低且可能在高并发场景下引发死链问题。与HashMap相比,HashTable未采用红黑树优化链表,且扩容后索引计算依赖取模而非位运算,导致性能劣势。此外,其线程安全通过方法级 `synchronized` 关键字实现,但扩容时需依赖外部同步机制,无法完全避免并发风险。
Properties
基本特点
Properties类继承自HashTable类并且实现了Map接口,使用特点和HashTable类似。
它还可以用于从xxx.properties文件中,加载数据到properties类对象,并进行读取和修改。
TreeMap
TreeMap实现了Map接口,和HashMap同级。
关于排序相关,和TreeSet相关用法一样。
集合选择
单列对象:Collection接口
允许重复:List接口
增删多:LinkedList
改查多:ArrayList
不允许重复:Set接口
无序:HashSet
有序:TreeSet
插入和取出顺序一致:LinkedHashSet
键值对数据:Map
键无序:HashMap
健排序:TreeMap
键插入和取出的顺序一致:LinkedHashMap
读取文件:Properties
Collections工具类
Collections 是 Java 集合框架中一个专用于操作集合的工具类,提供了一系列静态方法,支持对 List、Set、Map 等集合进行排序、查找、替换、同步控制等高效操。其核心功能包括:
- 常规操作:反转顺序(
reverse)、随机乱序(shuffle)、交换元素(swap); - 排序与查找:支持自然排序(
sort)、自定义排序(sort(Comparator))、二分查找(binarySearch),以及最大值/最小值查找(max/min); - 线程安全处理:通过
synchronizedList等方法将非线程安全集合转换为同步版本; - 不可变集合:生成只读集合(如
unmodifiableList)或单元素集合(如singletonList)。
import java.util.*;
public class CollectionsDemo {
public static void main(String[] args) {
// 初始化一个测试List集合
List<Integer> list = new ArrayList<>(Arrays.asList(5, 2, 8, 1, 3));
System.out.println("原始列表: " + list); // [5, 2, 8, 1, 3]
// 1. reverse() - 反转顺序
Collections.reverse(list);
System.out.println("反转后: " + list); // [3, 1, 8, 2, 5]
// 2. shuffle() - 随机乱序
Collections.shuffle(list);
System.out.println("随机乱序后: " + list); // 随机顺序,如 [2, 5, 3, 1, 8]
// 3. sort() - 自然排序(升序)
Collections.sort(list);
System.out.println("自然排序后: " + list); // [1, 2, 3, 5, 8]
// 4. sort() - 自定义排序(降序)
Collections.sort(list, new Comparator<Integer>() {
@Override
public int compare(Integer o1, Integer o2) {
return o2 - o1; // 降序规则
}
});
System.out.println("降序排序后: " + list); // [8, 5, 3, 2, 1]
// 5. swap() - 交换元素位置(索引0和1交换)
Collections.swap(list, 0, 1);
System.out.println("交换0和1位置后: " + list); // [5, 8, 3, 2, 1]
}
}import java.util.*;
public class CollectionsDemo {
public static void main(String[] args) {
// 初始化测试数据
List<Integer> list = new ArrayList<>(Arrays.asList(3, 5, 7, 5, 2, 5));
List<Integer> destList = new ArrayList<>(Arrays.asList(0, 0, 0, 0, 0, 0));
// 1. 最大值与最小值(自然顺序)
Integer maxNatural = Collections.max(list);
Integer minNatural = Collections.min(list);
System.out.println("自然顺序最大值: " + maxNatural); // 7
System.out.println("自然顺序最小值: " + minNatural); // 2
// 2. 最大值与最小值(自定义Comparator降序)
Comparator<Integer> reverseComparator = (a, b) -> b - a;
Integer maxCustom = Collections.max(list, reverseComparator); // 实际找最小值
Integer minCustom = Collections.min(list, reverseComparator); // 实际找最大值
System.out.println("降序规则下的\"最大值\": " + maxCustom); // 2
System.out.println("降序规则下的\"最小值\": " + minCustom); // 7
// 3. 元素出现频率
int frequency = Collections.frequency(list, 5);
System.out.println("元素5出现次数: " + frequency); // 3
// 4. 列表复制(覆盖目标列表)
Collections.copy(destList, list);
System.out.println("复制后的目标列表: " + destList); // [3, 5, 7, 5, 2, 5]
// 5. 替换所有元素
boolean isReplaced = Collections.replaceAll(list, 5, 10);
System.out.println("替换后的列表: " + list); // [3, 10, 7, 10, 2, 10]
System.out.println("是否进行了替换? " + isReplaced); // true
}
}


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









