






大二的时候就想搞一下推荐算法了,但是那时候不想倒腾,加上没啥参考资料,小破站上也没有啥教程,全是打广告推销卖作品的,大三又在考研,所以就没时间搞,现在自己的毕设里要加,木有办法,自己丰衣足食,通过查资料,理解别人的代码,自己也算简单实现了一下,还有更复杂的协同过滤算法,现在自己还没有理解,后面有时间再理解消化一下😂。话不多说,开干!
简单介绍
很明显,基于用户的协同过滤推荐算法是基于用户的行为去进行推荐,我这里是基于用户评分这个行为去过滤推荐的,我这里的例子是,贴吧里面有很多帖子,用户可以对帖子进行评分,我系统里需要实现给用户推荐帖子。首先肯定就得用一张表存储用户对帖子的评分情况,即stick_score:
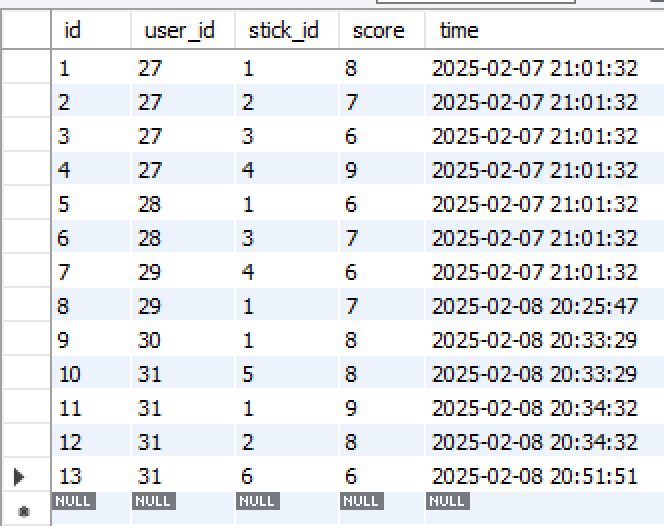
整个流程就是,首先根据stick_score表中的数据找出与目标用户最相似的三个用户,把他们的id存下来,然后根据他们的id再回到stick_score中找出目标用户没评分但是相似用户评过分的帖子id,然后根据推荐次数推荐给目标用户(当然这里是默认有这种情况,没有的话可以按照自己需求去推荐,下面会讲述)。
No.1 推荐模块的封装
我们可以将系统过滤推荐算法核心实现代码进行一个封装,放在工具类里进行实现,比如,在我这,需要封装一个帖子推荐模块,那就在common的工具类里封装一个StickRecommend类,如下所示:
接下来我们看一下这个核心代码的实现:
1.加载用户评分数据(loadRatingsFromDB)
这部分的作用就是预处理数据库stick_score里面的数据,将各部分数据映射成Map<Integer, Map<Integer, Double>> 数据结构,方便后续进行数据处理。
// 加载用户评分数据的方法
// 该方法从数据库中加载用户对各个帖子(stick)的评分数据
// 返回一个Map,其中key是用户ID,value是一个Map,存储该用户对各个帖子的评分
public static Map<Integer, Map<Integer, Double>> loadRatingsFromDB(Connection conn) throws SQLException {
Map<Integer, Map<Integer, Double>> userRatings = new HashMap<>();
// 使用Statement执行SQL查询,从数据库表 "stick_score" 获取用户评分数据
try (Statement stmt = conn.createStatement();
ResultSet rs = stmt.executeQuery("SELECT user_id, stick_id, score FROM stick_score")) {
// 遍历查询结果集,将数据按照用户ID和帖子ID组织成Map
while (rs.next()) {
int userId = rs.getInt("user_id"); // 获取用户ID
int stickId = rs.getInt("stick_id"); // 获取帖子ID
double rating = rs.getDouble("score"); // 获取评分
// 将评分数据存储到Map中,Map的结构是:用户ID -> (帖子ID -> 评分)
userRatings.computeIfAbsent(userId, k -> new HashMap<>()).put(stickId, rating);
}
}
return userRatings; // 返回存储评分数据的Map
}2.计算余弦相似度(cosineSimilarity)
这部分就是基于两个用户对相同帖子的评分计算他们的相似度。使用余弦相似度公式,衡量两个用户评分模式之间的相似程度,越接近1说明越相似。大致的过程就是如下:
1.计算两个用户对共同帖子的评分的点积(dotProduct)。
2.计算每个用户的评分的平方和的平方根(normA 和 normB)。
3.返回点积与两个评分向量模长的商,即得到用户之间的余弦相似度。
说明:余弦相似度的范围是 [−1,1][−1,1],其中 1 表示完全相似,0 表示没有相似度,-1 表示完全不相似。
// 计算余弦相似度
// 该方法用于计算两个用户之间的相似度,基于他们对相同帖子的评分进行计算
// 余弦相似度的值越大,说明两个用户的兴趣越相似
public static double cosineSimilarity(Map<Integer, Double> ratings1, Map<Integer, Double> ratings2) {
// 获取两个用户的评分的共同帖子ID
Set<Integer> commonBooks = new HashSet<>(ratings1.keySet());
commonBooks.retainAll(ratings2.keySet()); // 求交集,找到共同评分的帖子
// 如果两个用户没有共同评分的帖子,相似度为0
if (commonBooks.isEmpty()) return 0;
double dotProduct = 0.0; // 点积
double normA = 0.0; // 向量A的模
double normB = 0.0; // 向量B的模
// 计算点积和各自向量的模
for (int stickId : commonBooks) {
double rating1 = ratings1.get(stickId); // 用户1对该帖子的评分
double rating2 = ratings2.get(stickId); // 用户2对该帖子的评分
dotProduct += rating1 * rating2; // 计算点积
normA += Math.pow(rating1, 2); // 计算用户1评分的平方和
normB += Math.pow(rating2, 2); // 计算用户2评分的平方和
}
// 计算并返回余弦相似度
return dotProduct / (Math.sqrt(normA) * Math.sqrt(normB));
}这里补充一下:
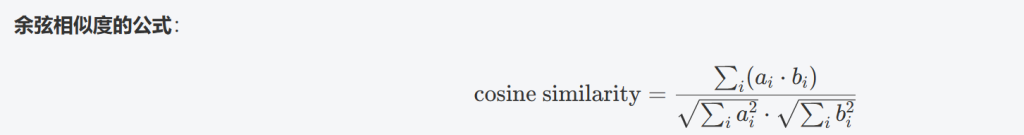
其中:
- aiai 和 bibi 是用户对帖子的评分。
- 分子是两个用户对共同帖子的评分的点积(即评分值相乘再求和)。
- 分母是两个用户评分的模长,即评分平方和的平方根。
3.找到最相似的三个用户(findTopThreeSimilarUsers)
这里显然很关键,只有找到了和目标用户相似的用户,才可以进行相关推荐,推荐推荐,和你相类似的人做这个,就可以猜测你也可能做这个,我就推给你,其实我感觉抖音有时就是这种情况,你的好友点赞了啥,诶他就推给你了。这里大致的流程就是遍历所有用户,计算每个用户与目标用户的相似度,找到与目标用户最相似的三个用户。使用优先队列(最大堆)存储和排序相似度,确保只保留最相似的三位用户。
// 找到与目标用户最相似的三个用户
// 该方法通过计算余弦相似度来找到与目标用户最相似的三个用户
public static List<Integer> findTopThreeSimilarUsers(int targetUserId, Map<Integer, Map<Integer, Double>> userRatings) {
// 使用优先队列(最大堆)存储用户相似度和用户ID
PriorityQueue<Map.Entry<Integer, Double>> pq = new PriorityQueue<>(
(e1, e2) -> Double.compare(e1.getValue(), e2.getValue()) // 按相似度升序排序
);
// 遍历所有用户,计算与目标用户的相似度
for (Map.Entry<Integer, Map<Integer, Double>> entry : userRatings.entrySet()) {
int userId = entry.getKey(); // 用户ID
if (userId == targetUserId) continue; // 跳过目标用户本身
// 计算余弦相似度
double similarity = cosineSimilarity(userRatings.get(targetUserId), entry.getValue());
// 将用户和相似度存入优先队列
Map.Entry<Integer, Double> user = new AbstractMap.SimpleEntry<>(userId, similarity);
pq.offer(user);
// 如果队列中的用户数超过3个,移除最不相似的用户
if (pq.size() > 3) {
pq.poll();
}
}
// 从优先队列中提取出最相似的三个用户
List<Integer> topUsers = new ArrayList<>();
while (!pq.isEmpty()) {
topUsers.add(pq.poll().getKey()); // 提取用户ID
}
return topUsers; // 返回最相似的三个用户的ID
}4.基于相似用户推荐帖子(recommendStickOnSimilarUsers)
万事具备了,可以推荐了。这里就是根据与目标用户最相似的几个用户的评分,推荐目标用户可能感兴趣的帖子。如果相似用户评分过的帖子目标用户未评分,则推荐该帖子。根据推荐次数排序,返回最受欢迎的帖子。当然里面推荐多少,都可以自己微调。
// 基于相似用户推荐帖子
// 该方法基于与目标用户最相似的用户来推荐帖子
public static List<Map.Entry<Integer, Integer>> recommendStickOnSimilarUsers(Map<Integer, Map<Integer, Double>> userRatings,
List<Integer> similarUsers, int targetUserId) {
Map<Integer, Integer> stickVotes = new HashMap<>(); // 存储每个帖子的推荐次数
// 遍历所有相似用户,统计他们推荐过的帖子
for (int userId : similarUsers) {
Map<Integer, Double> userBooks = userRatings.getOrDefault(userId, Collections.emptyMap());
for (Map.Entry<Integer, Double> bookRating : userBooks.entrySet()) {
// 如果目标用户没有评价过该帖子,则计入推荐次数
if (!userRatings.get(targetUserId).containsKey(bookRating.getKey())) {
stickVotes.merge(bookRating.getKey(), 1, Integer::sum); // 增加该帖子的推荐次数
}
}
}
// 将推荐次数进行排序,从高到低
List<Map.Entry<Integer, Integer>> sortedsticks = new ArrayList<>(stickVotes.entrySet());
sortedsticks.sort(Map.Entry.<Integer, Integer>comparingByValue().reversed());
// 只返回前5个推荐的帖子
List<Map.Entry<Integer, Integer>> recommendStick = new ArrayList<>();
System.out.println("为用户 " + targetUserId + " 推荐的帖子:");
for (int i = 0; i < Math.min(5, sortedsticks.size()); i++) {
recommendStick.add(sortedsticks.get(i)); // 获取前5个帖子
System.out.println("帖子ID: " + sortedsticks.get(i).getKey() + ", 被推荐次数: " + sortedsticks.get(i).getValue());
}
return recommendStick; // 返回推荐的帖子列表
}5.完整实现代码
到这里可以说工作完成大半了,接下来就是写接口调用咱们封装的模块了。我这里给出完整的StickRecommend的代码:
package com.nchu.common.recommend;
import java.sql.*;
import java.util.*;
public class StickRecommend {
// 数据库连接信息
public static final String DB_URL = "jdbc:mysql://localhost:3306/warmheart";
public static final String USER = "数据库用户名";
public static final String PASS = "自己的密码";
// 加载用户评分数据的方法
// 该方法从数据库中加载用户对各个帖子(stick)的评分数据
// 返回一个Map,其中key是用户ID,value是一个Map,存储该用户对各个帖子的评分
public static Map<Integer, Map<Integer, Double>> loadRatingsFromDB(Connection conn) throws SQLException {
Map<Integer, Map<Integer, Double>> userRatings = new HashMap<>();
// 使用Statement执行SQL查询,从数据库表 "stick_score" 获取用户评分数据
try (Statement stmt = conn.createStatement();
ResultSet rs = stmt.executeQuery("SELECT user_id, stick_id, score FROM stick_score")) {
// 遍历查询结果集,将数据按照用户ID和帖子ID组织成Map
while (rs.next()) {
int userId = rs.getInt("user_id"); // 获取用户ID
int stickId = rs.getInt("stick_id"); // 获取帖子ID
double rating = rs.getDouble("score"); // 获取评分
// 将评分数据存储到Map中,Map的结构是:用户ID -> (帖子ID -> 评分)
userRatings.computeIfAbsent(userId, k -> new HashMap<>()).put(stickId, rating);
}
}
return userRatings; // 返回存储评分数据的Map
}
// 计算余弦相似度
// 该方法用于计算两个用户之间的相似度,基于他们对相同帖子的评分进行计算
// 余弦相似度的值越大,说明两个用户的兴趣越相似
public static double cosineSimilarity(Map<Integer, Double> ratings1, Map<Integer, Double> ratings2) {
// 获取两个用户的评分的共同帖子ID
Set<Integer> commonBooks = new HashSet<>(ratings1.keySet());
commonBooks.retainAll(ratings2.keySet()); // 求交集,找到共同评分的帖子
// 如果两个用户没有共同评分的帖子,相似度为0
if (commonBooks.isEmpty()) return 0;
double dotProduct = 0.0; // 点积
double normA = 0.0; // 向量A的模
double normB = 0.0; // 向量B的模
// 计算点积和各自向量的模
for (int stickId : commonBooks) {
double rating1 = ratings1.get(stickId); // 用户1对该帖子的评分
double rating2 = ratings2.get(stickId); // 用户2对该帖子的评分
dotProduct += rating1 * rating2; // 计算点积
normA += Math.pow(rating1, 2); // 计算用户1评分的平方和
normB += Math.pow(rating2, 2); // 计算用户2评分的平方和
}
// 计算并返回余弦相似度
return dotProduct / (Math.sqrt(normA) * Math.sqrt(normB));
}
// 找到与目标用户最相似的三个用户
// 该方法通过计算余弦相似度来找到与目标用户最相似的三个用户
public static List<Integer> findTopThreeSimilarUsers(int targetUserId, Map<Integer, Map<Integer, Double>> userRatings) {
// 使用优先队列(最大堆)存储用户相似度和用户ID
PriorityQueue<Map.Entry<Integer, Double>> pq = new PriorityQueue<>(
(e1, e2) -> Double.compare(e1.getValue(), e2.getValue()) // 按相似度升序排序
);
// 遍历所有用户,计算与目标用户的相似度
for (Map.Entry<Integer, Map<Integer, Double>> entry : userRatings.entrySet()) {
int userId = entry.getKey(); // 用户ID
if (userId == targetUserId) continue; // 跳过目标用户本身
// 计算余弦相似度
double similarity = cosineSimilarity(userRatings.get(targetUserId), entry.getValue());
// 将用户和相似度存入优先队列
Map.Entry<Integer, Double> user = new AbstractMap.SimpleEntry<>(userId, similarity);
pq.offer(user);
// 如果队列中的用户数超过3个,移除最不相似的用户
if (pq.size() > 3) {
pq.poll();
}
}
// 从优先队列中提取出最相似的三个用户
List<Integer> topUsers = new ArrayList<>();
while (!pq.isEmpty()) {
topUsers.add(pq.poll().getKey()); // 提取用户ID
}
return topUsers; // 返回最相似的三个用户的ID
}
// 基于相似用户推荐帖子
// 该方法基于与目标用户最相似的用户来推荐帖子
public static List<Map.Entry<Integer, Integer>> recommendStickOnSimilarUsers(Map<Integer, Map<Integer, Double>> userRatings,
List<Integer> similarUsers, int targetUserId) {
Map<Integer, Integer> stickVotes = new HashMap<>(); // 存储每个帖子的推荐次数
// 遍历所有相似用户,统计他们推荐过的帖子
for (int userId : similarUsers) {
Map<Integer, Double> userBooks = userRatings.getOrDefault(userId, Collections.emptyMap());
for (Map.Entry<Integer, Double> bookRating : userBooks.entrySet()) {
// 如果目标用户没有评价过该帖子,则计入推荐次数
if (!userRatings.get(targetUserId).containsKey(bookRating.getKey())) {
stickVotes.merge(bookRating.getKey(), 1, Integer::sum); // 增加该帖子的推荐次数
}
}
}
// 将推荐次数进行排序,从高到低
List<Map.Entry<Integer, Integer>> sortedsticks = new ArrayList<>(stickVotes.entrySet());
sortedsticks.sort(Map.Entry.<Integer, Integer>comparingByValue().reversed());
// 只返回前5个推荐的帖子
List<Map.Entry<Integer, Integer>> recommendStick = new ArrayList<>();
System.out.println("为用户 " + targetUserId + " 推荐的帖子:");
for (int i = 0; i < Math.min(5, sortedsticks.size()); i++) {
recommendStick.add(sortedsticks.get(i)); // 获取前5个帖子
System.out.println("帖子ID: " + sortedsticks.get(i).getKey() + ", 被推荐次数: " + sortedsticks.get(i).getValue());
}
return recommendStick; // 返回推荐的帖子列表
}
}
No.2 推荐接口的实现
我的项目是基于SpringBoot和mybatis-plus框架,大家可以按照自己的需求去写。接下来依次看一下各个层的代码实现。
1.controller层
这里代码简单,不多说啥。
@GetMapping("/recommend")
public R getRecommend(@RequestParam Integer userId){
List<Sticks> list = sticksService.recommendSticks(userId);
return R.ok().data("stickList",list);
}
2.service层
我的推荐策略就是用户没有评分历史时,直接推荐五个点赞量最高的帖子;而在有评分历史的情况下,则利用协同过滤算法根据相似用户的偏好来推荐,但是如果相似用户评分过的帖子在目标用户这里也都评价了呢,那没办法再直接给他推荐五个点赞量最高达到帖子了😂,这里可以依据自己的情况而定。
public interface ISticksService extends IService<Sticks> {
//分页查询
PageResult<Sticks> findByPage(Integer page,Integer pageSize);
//获取最热
PageResult<Sticks> getHot(Integer page,Integer pageSize);
//获取最新
PageResult<Sticks> getNew(Integer page,Integer pageSize);
//推荐贴子
List<Sticks> recommendSticks(Integer userId);
}
public interface IStickScoreService extends IService<StickScore> {
List<Sticks> recommend(Integer userId);
}
---------------------------------------------------------------------------------------------
这里是 StickScoreService实现类的部分代码:
@Service
public class StickScoreServiceImpl extends ServiceImpl<StickScoreMapper, StickScore> implements IStickScoreService {
@Autowired
@Lazy // 懒加载注解,表示在第一次需要该 Bean 时才会加载
private ISticksService sticksService;
@Override
public List<Sticks> recommend(Integer userId) {
List<Sticks> stickList = new ArrayList<>(); // 用来存储最终推荐的帖子列表
try (
// 获取数据库连接
Connection conn = DriverManager.getConnection(StickRecommend.DB_URL, StickRecommend.USER, StickRecommend.PASS)
) {
// 从数据库加载用户评分数据
Map<Integer, Map<Integer, Double>> userRatings = StickRecommend.loadRatingsFromDB(conn);
// 找到与目标用户最相似的三个用户
List<Integer> similarUsers = StickRecommend.findTopThreeSimilarUsers(userId, userRatings);
System.out.println("与用户 " + userId + " 最相似的三个用户为:" + similarUsers);
// 根据与相似用户的评分,推荐目标用户可能感兴趣的帖子
List<Map.Entry<Integer, Integer>> list = StickRecommend.recommendStickOnSimilarUsers(userRatings, similarUsers, userId);
// 遍历推荐的帖子列表
for (Map.Entry<Integer, Integer> map : list) {
// map.getKey() 获取帖子 ID
LambdaQueryWrapper<Sticks> queryWrapper = new LambdaQueryWrapper<>();
queryWrapper.eq(Sticks::getId, map.getKey()); // 根据帖子 ID 构建查询条件
Sticks sticks = sticksService.getOne(queryWrapper); // 从数据库查询帖子信息
stickList.add(sticks); // 将查询到的帖子添加到推荐列表中
}
} catch (SQLException e) {
e.printStackTrace();
}
return stickList;
}
}
---------------------------------------------------------------------------------------------
这是SticksService实现类的部分代码
@Autowired
@Lazy
private IStickScoreService stickScoreService;
@Override
public List<Sticks> recommendSticks(Integer userId) {
LambdaQueryWrapper<StickScore> queryWrapper = new LambdaQueryWrapper<>();
queryWrapper.eq(StickScore::getUserId,userId);
List<StickScore> stickScoreList = stickScoreService.list(queryWrapper);
LambdaQueryWrapper<Sticks> wrapper = new LambdaQueryWrapper<>();
wrapper.orderBy(true,false,Sticks::getLikes);
wrapper.last("LIMIT 5");
//如果用户从未评价过,则推荐帖子点赞量最高的5个帖子,反之评价过则按协同过滤算法进行推荐
if(stickScoreList.isEmpty()) {
List<Sticks> sticks = this.list(wrapper);
return sticks;
}else {
List<Sticks> list = stickScoreService.recommend(userId);
if(list.isEmpty()){
//如果所有帖子都评价过,则推荐5个点赞量最高的帖子
List<Sticks> sticks = this.list(wrapper);
return sticks;
}else {
return list;
}
}
}No3.运行结果
到这里基本就结束了,大致的流程就是这样了,看一下结果,我用apifox测的。

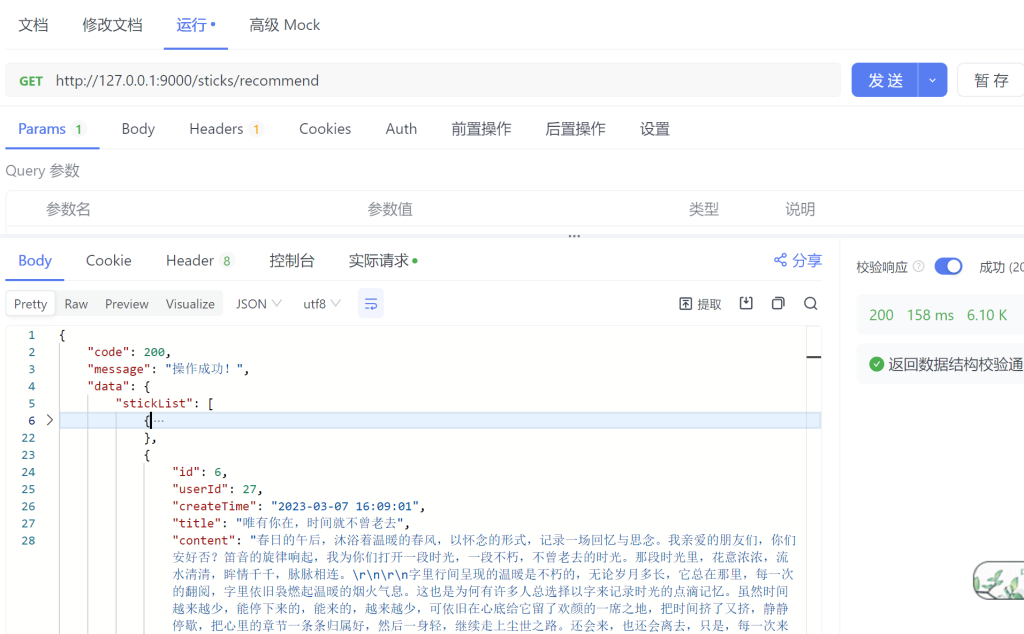
可以看到是可以进行相关推荐的,基础功能算是达到了。
对了这里再补充一下我这里遇到的一个问题:
2025-02-08 15:34:07.935 WARN 9792 --- [ main] ConfigServletWebServerApplicationContext : Exception encountered during context initialization - cancelling refresh attempt: org.springframework.beans.factory.UnsatisfiedDependencyException: Error creating bean with name 'sticksController': Unsatisfied dependency expressed through field 'sticksService'; nested exception is org.springframework.beans.factory.UnsatisfiedDependencyException: Error creating bean with name 'sticksServiceImpl': Unsatisfied dependency expressed through field 'stickScoreService'; nested exception is org.springframework.beans.factory.UnsatisfiedDependencyException: Error creating bean with name 'stickScoreServiceImpl': Unsatisfied dependency expressed through field 'sticksService'; nested exception is org.springframework.beans.factory.BeanCurrentlyInCreationException: Error creating bean with name 'sticksServiceImpl': Requested bean is currently in creation: Is there an unresolvable circular reference?
2025-02-08 15:34:07.938 INFO 9792 --- [ main] o.apache.catalina.core.StandardService : Stopping service [Tomcat]
2025-02-08 15:34:07.949 INFO 9792 --- [ main] ConditionEvaluationReportLoggingListener :
Error starting ApplicationContext. To display the conditions report re-run your application with 'debug' enabled.
2025-02-08 15:34:07.968 ERROR 9792 --- [ main] o.s.b.d.LoggingFailureAnalysisReporter :
APPLICATION FAILED TO START
Description:
The dependencies of some of the beans in the application context form a cycle:
sticksController (field private com.yaojie.service.ISticksService com.yaojie.controller.SticksController.sticksService)
┌─────┐
| sticksServiceImpl (field private com.yaojie.service.IStickScoreService com.yaojie.service.impl.SticksServiceImpl.stickScoreService)
↑ ↓
| stickScoreServiceImpl (field private com.yaojie.service.ISticksService com.yaojie.service.impl.StickScoreServiceImpl.sticksService)
└─────┘
Action:
Relying upon circular references is discouraged and they are prohibited by default. Update your application to remove the dependency cycle between beans. As a last resort, it may be possible to break the cycle automatically by setting spring.main.allow-circular-references to true.
进程已结束,退出代码1这个错误是由于 Spring Bean 的循环依赖(circular dependency)导致的。
SticksController 需要 SticksService。
SticksServiceImpl 需要 StickScoreService。
StickScoreServiceImpl 需要 SticksService。
我这里是使用 Spring 的 @Lazy 注解。通过将其中一个依赖注入设置为懒加载(延迟加载),可以打破循环依赖。
@Service
public class SticksServiceImpl implements ISticksService {
@Autowired
@Lazy
private IStickScoreService stickScoreService;
}No4.总结
这里的协同过滤推荐逻辑实现还是不算很复杂的,我看到的一个音乐协同过滤推荐,里面复杂的多了,之后有时间再研究研究,这次也是学到了一些东西的。😁
我也是带着学习的目的去尝试写的,所以代码肯定有很多没写好的地方,博客也是随心写的,也许会有很多错,大家手下留情,一起交流一起学习!一起进步!
欢迎来我个人博客知足的blog一起交流

















 2043
2043

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









