







目录
OCR——快速使用 PaddleOCR
- 【项目官网】:PaddlePaddle/PaddleOCR (github.com)
- 【PaddleOCR 简介】:PaddleOCR/doc/doc_ch/ppocr_introduction.md at release/2.7 · PaddlePaddle/PaddleOCR (github.com)
- 【项目文档教程】:PaddleOCR/doc/doc_ch/quickstart.md at release/2.7 · PaddlePaddle/PaddleOCR (github.com)
- 【飞浆文档】:使用指南-使用文档-PaddlePaddle深度学习平台
安装 PaddleOCR
命令

- 机器是 CUDA9 或 CUDA10:
python -m pip install paddlepaddle-gpu -i https://mirror.baidu.com/pypi/simple
- 机器是 CPU:
python -m pip install paddlepaddle -i https://mirror.baidu.com/pypi/simple
注:【卸载 PaddleOCR】
- GPU 版本的 PaddlePaddle:
python -m pip uninstall paddlepaddle-gpu
- CPU 版本的 PaddlePaddle:
python -m pip uninstall paddlepaddle
验证安装是否成功
import paddle
paddle.utils.run_check()
print(paddle.__version__)

安装 paddleocr
命令
pip install paddleocr
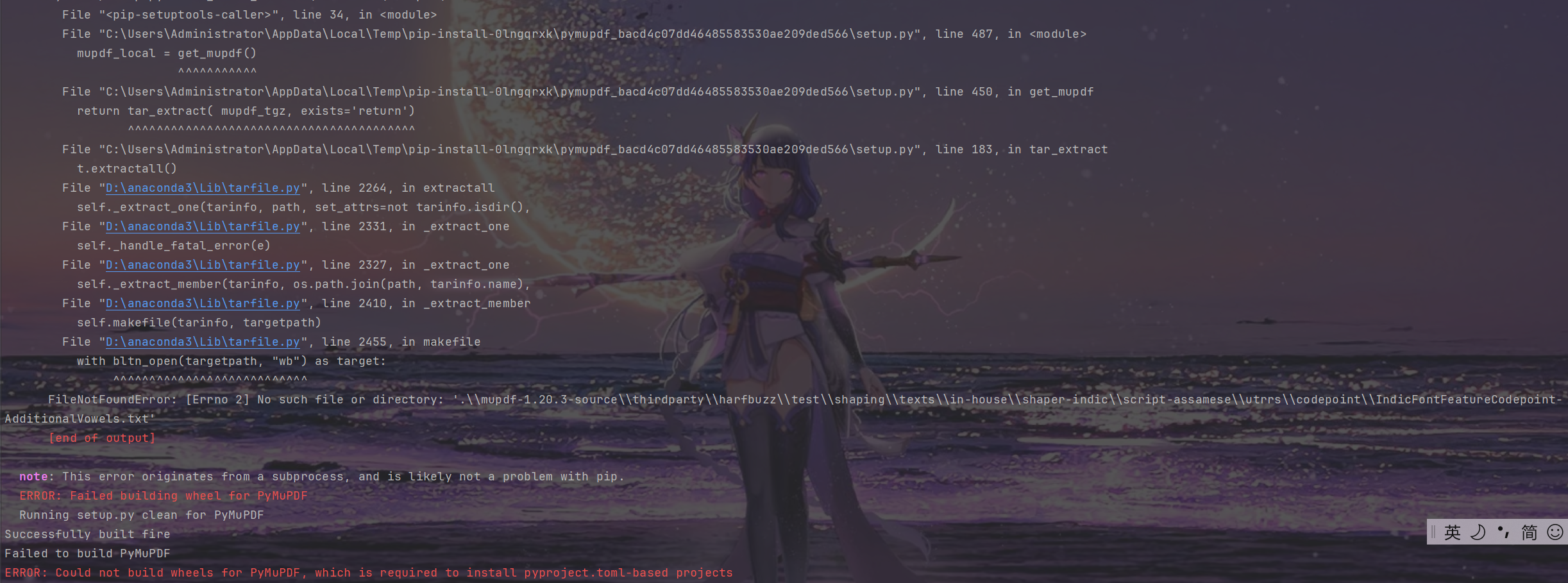
以上报错不要慌,使用以下方式即可解决:
安装 paddleocr 的时候 指定 PyMuPDF 版本
pip install “paddleocr>=2.0.1” --upgrade PyMuPDF==1.21.1
测试示例
- 测试数据集:
- 链接:https://pan.baidu.com/s/1aQYctBF4C3D9o3-bD9ePDg?pwd=qlsc
提取码:qlsc
- 链接:https://pan.baidu.com/s/1aQYctBF4C3D9o3-bD9ePDg?pwd=qlsc
- 测试代码(检测+方向分类器+识别全流程):【项目文档教程】中的代码有坑,有一行是多余的
from paddleocr import PaddleOCR, draw_ocr
# Paddleocr 目前支持中英文、英文、法语、德语、韩语、日语,可以通过修改 lang 参数进行切换
# 参数依次为`ch`, `en`, `french`, `german`, `korean`, `japan`。
ocr = PaddleOCR(use_angle_cls=True, lang="ch") # need to run only once to download and load model into memory
img_path = 'ppocr_img/ch/ch.jpg'
result = ocr.ocr(img_path, cls=True)
for idx in range(len(result)):
res = result[idx]
for line in res:
print(line)
# 显示结果
from PIL import Image
# result = result[0] # 这行代码是多余的
image = Image.open(img_path).convert('RGB')
boxes = [line[0] for line in result]
txts = [line[1][0] for line in result]
scores = [line[1][1] for line in result]
im_show = draw_ocr(image, boxes, txts, scores, font_path='ppocr_img/fonts/simfang.ttf')
im_show = Image.fromarray(im_show)
im_show.save('result.jpg')
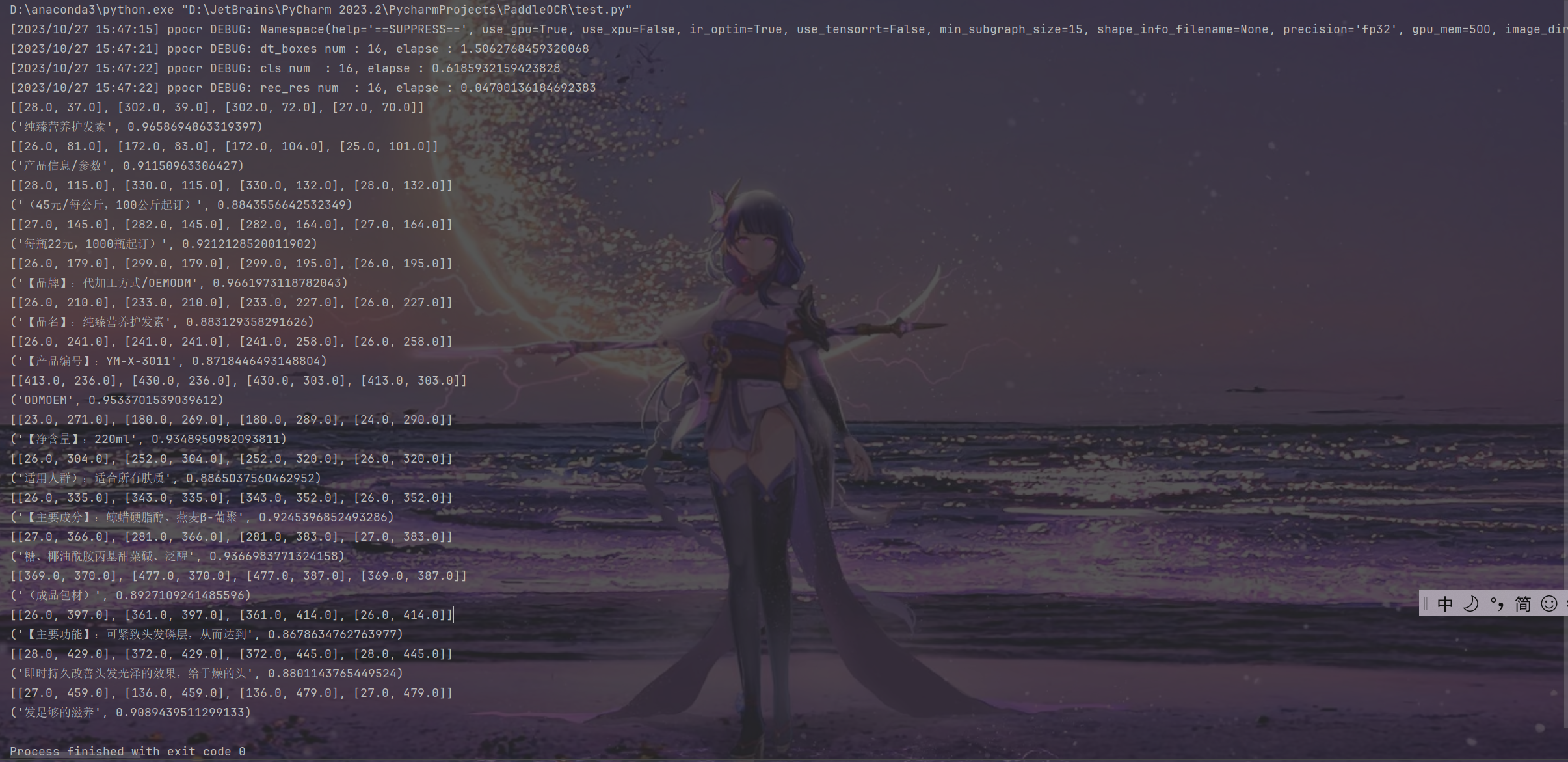

- 上述代码只支持单个图片的检测,以下代码是对文件夹进行检测:
import os
from paddleocr import PaddleOCR, draw_ocr
from PIL import Image
# Paddleocr 目前支持中英文、英文、法语、德语、韩语、日语,可以通过修改 lang 参数进行切换
# 参数依次为`ch`, `en`, `french`, `german`, `korean`, `japan`。
ocr = PaddleOCR(use_angle_cls=True,
lang="ch",
image_dir='ppocr_img/ch')
# 定义存储结果的父文件夹
parent_result_dir = 'results'
if not os.path.exists(parent_result_dir):
os.makedirs(parent_result_dir)
# 获取已存在的文件夹名称,找到下一个可用的数字
existing_results = [dir for dir in os.listdir(parent_result_dir) if dir.startswith("predict")]
if existing_results:
existing_results = sorted(existing_results, key=lambda x: int(x.replace("predict", "")))
next_result_dir = f"predict{int(existing_results[-1].replace('predict', '')) + 1}"
else:
next_result_dir = "predict1"
# 创建结果文件夹
results_dir = os.path.join(parent_result_dir, next_result_dir)
os.makedirs(results_dir)
# 处理 image_dir 中的所有图片
image_dir = 'ppocr_img/ch'
for image_file in os.listdir(image_dir):
if image_file.endswith('.jpg') or image_file.endswith('.png'):
img_path = os.path.join(image_dir, image_file)
result = ocr.ocr(img_path, cls=True)
image = Image.open(img_path).convert('RGB')
boxes = [line[0] for line in result]
txts = [line[1][0] for line in result]
scores = [line[1][1] for line in result]
im_show = draw_ocr(image, boxes, txts, scores, font_path='ppocr_img/fonts/simfang.ttf')
# 生成结果文件的路径
result_image_path = os.path.join(results_dir, image_file)
im_show = Image.fromarray(im_show)
im_show.save(result_image_path)
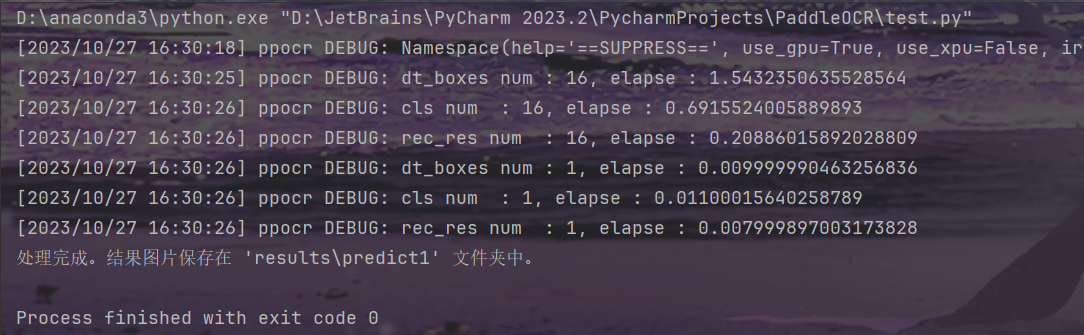
print(f"处理完成。结果图片保存在 '{results_dir}' 文件夹中。")

















 672
672

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









