






代码来源
https://github.com/visual-attention-network/segnext
模块作用
卷积注意力在编码上下文信息方面比自注意力更高效、更有效
模块结构
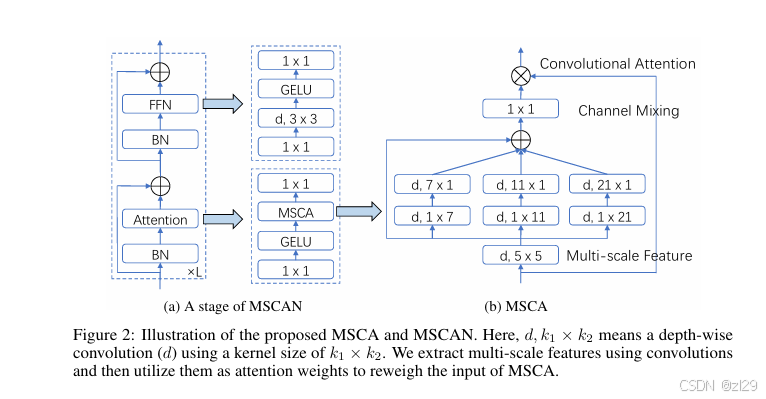
SegNeXt由编码器(MSCAN)和解码器两部分组成。
编码器(MSCAN)
编码器采用金字塔结构,包含四个阶段,每个阶段使用多尺度卷积注意力(MSCA)模块替代自注意力机制。MSCA通过深度卷积和多分支深度条带卷积(内核大小为7、11、21)捕获多尺度上下文信息,并使用1×1卷积进行通道混合。公式为:
- 注意力图:
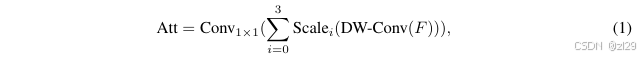
- 输出:
 其中,F是输入特征,DW-Conv表示深度卷积,Scale_i (i∈{0,1,2,3}) 是分支,Scale0是身份连接。
其中,F是输入特征,DW-Conv表示深度卷积,Scale_i (i∈{0,1,2,3}) 是分支,Scale0是身份连接。
解码器
解码器聚合编码器最后三个阶段的特征,使用轻量级Hamburger(Ham)模块提取全局上下文,避免使用第一阶段的特征以减少计算开销。Ham模块在性能-计算效率方面表现出色,与其他注意力机制(如CC、EMA、NL)相比,在ADE20K数据集上取得了最佳平衡(见表5)。
MSCA
组件与操作
- 输入特征:设输入特征为F。
- 多尺度分支:模块包括三个分支,分别使用内核大小为7、11、21的条带卷积捕获不同尺度的特征。
- 每个分支使用一对深度1×K和K×1卷积来模拟大核卷积,高效降低计算成本。
- 分支求和:将这些分支的输出与身份连接(原始特征FFF)求和。
- 生成注意力图:对求和结果应用1×1卷积,生成注意力图Att。
- 输出特征:将注意力图Att与原始特征FFF逐元素相乘,得到输出特征Out。
原理
- 多尺度特征聚合:通过不同内核大小的卷积,模块有效捕获不同感受野的特征,适合处理分割任务中大小不一的对象。
- 高效计算:使用条带卷积减少计算复杂度,与标准大核卷积相比,计算成本更低。
- 卷积注意力:利用卷积操作生成注意力,提供比Transformer自注意力更高效的上下文编码方式。
代码
class MSCAN(BaseModule):
def __init__(self,
in_chans=3,
embed_dims=[64, 128, 256, 512],
mlp_ratios=[4, 4, 4, 4],
drop_rate=0.,
drop_path_rate=0.,
depths=[3, 4, 6, 3],
num_stages=4,
norm_cfg=dict(type='SyncBN', requires_grad=True),
pretrained=None,
init_cfg=None):
super(MSCAN, self).__init__(init_cfg=init_cfg)
assert not (init_cfg and pretrained), \
'init_cfg and pretrained cannot be set at the same time'
if isinstance(pretrained, str):
warnings.warn('DeprecationWarning: pretrained is deprecated, '
'please use "init_cfg" instead')
self.init_cfg = dict(type='Pretrained', checkpoint=pretrained)
elif pretrained is not None:
raise TypeError('pretrained must be a str or None')
self.depths = depths
self.num_stages = num_stages
dpr = [x.item() for x in torch.linspace(0, drop_path_rate,
sum(depths))] # stochastic depth decay rule
cur = 0
for i in range(num_stages):
if i == 0:
patch_embed = StemConv(3, embed_dims[0], norm_cfg=norm_cfg)
else:
patch_embed = OverlapPatchEmbed(patch_size=7 if i == 0 else 3,
stride=4 if i == 0 else 2,
in_chans=in_chans if i == 0 else embed_dims[i - 1],
embed_dim=embed_dims[i],
norm_cfg=norm_cfg)
block = nn.ModuleList([Block(dim=embed_dims[i], mlp_ratio=mlp_ratios[i],
drop=drop_rate, drop_path=dpr[cur + j],
norm_cfg=norm_cfg)
for j in range(depths[i])])
norm = nn.LayerNorm(embed_dims[i])
cur += depths[i]
setattr(self, f"patch_embed{i + 1}", patch_embed)
setattr(self, f"block{i + 1}", block)
setattr(self, f"norm{i + 1}", norm)
def init_weights(self):
print('init cfg', self.init_cfg)
if self.init_cfg is None:
for m in self.modules():
if isinstance(m, nn.Linear):
trunc_normal_init(m, std=.02, bias=0.)
elif isinstance(m, nn.LayerNorm):
constant_init(m, val=1.0, bias=0.)
elif isinstance(m, nn.Conv2d):
fan_out = m.kernel_size[0] * m.kernel_size[
1] * m.out_channels
fan_out //= m.groups
normal_init(
m, mean=0, std=math.sqrt(2.0 / fan_out), bias=0)
else:
super(MSCAN, self).init_weights()
def forward(self, x):
B = x.shape[0]
outs = []
for i in range(self.num_stages):
patch_embed = getattr(self, f"patch_embed{i + 1}")
block = getattr(self, f"block{i + 1}")
norm = getattr(self, f"norm{i + 1}")
x, H, W = patch_embed(x)
for blk in block:
x = blk(x, H, W)
x = norm(x)
x = x.reshape(B, H, W, -1).permute(0, 3, 1, 2).contiguous()
outs.append(x)
return outs总结
在本文中,我们分析了以往成功的分割模型,并总结了它们所具备的优秀特性。基于这些发现,我们提出了一种定制卷积注意力模块(MSCA) 和一个CNN 结构的分割网络(SegNeXt)。实验结果表明,SegNeXt 在性能上远超当前最先进的基于 Transformer 的方法。
近年来,Transformer 结构的模型 在各种分割任务排行榜上占据主导地位。然而,本研究表明,当 CNN 经过合理设计后,仍然能够比 Transformer 方法表现更好。

















 1998
1998

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









