






一文带你了解Zookeeper
因为本人的公司使用到了Zookeeper,所以花了点时间来了解一下Zookeeper。
Zookeeper的诞生
以下内容摘抄自ZooKeeper入门,这一篇给你讲的明明白白
Zookeeper 最早起源于雅虎研究院的一个研究小组。在当时,研究人员发现,在雅虎内部很多大型系统基本都需要依赖一个类似的系统来进行分布式协调,但是这些系统往往都存在分布式单点问题。所以,雅虎的开发人员就试图开发一个通用的无单点问题的分布式协调框架,以便让开发人员将精力集中在处理业务逻辑上,Zookeeper 就这样诞生了。后来捐赠给了 Apache ,现已成为 Apache 顶级项目。
关于“ZooKeeper”这个项目的名字,其实也有一段趣闻。在立项初期,考虑到之前内部很多项目都是使用动物的名字来命名的(例如著名的Pig项目),雅虎的工程师希望给这个项目也取一个动物的名字。时任研究院的首席科学家 RaghuRamakrishnan 开玩笑地说:“再这样下去,我们这儿就变成动物园了!”此话一出,大家纷纷表示就叫动物园管理员吧一一一因为各个以动物命名的分布式组件放在一起,雅虎的整个分布式系统看上去就像一个大型的动物园了,而 Zookeeper 正好要用来进行分布式环境的协调一一于是,Zookeeper 的名字也就由此诞生了。

Zookeeper是什么
ZooKeeper 官网是这么介绍的:“Apache ZooKeeper 致力于开发和维护一个支持高度可靠的分布式协调的开源服务器”
Zookeeper是一个分布式协调服务,用于管理和协调分布式应用程序。它提供了一组简单的原语来实现分布式锁、配置管理、命名服务、集群管理等功能。Zookeeper通过其一致性协议(如ZAB协议)确保数据的一致性和可靠性,常用于Hadoop、Kafka等大数据和分布式系统中。
ZooKeeper有五大核心特性:
- 顺序一致性:来自客户端的更新请求将按照它们被接收的顺序应用。
- 原子性:更新操作要么完全应用,要么完全不应用,不存在中间状态。
- 单一系统映像:任何客户端看到的系统状态都是一致的。
- 可靠性:一旦更新被应用,它将被永久地应用,即使发生系统故障。
- 实时性:系统的状态变更可以被实时地通知到客户端。
Zookeeper应用场景
-
分布式锁:确保分布式系统中的多个进程或线程在访问共享资源时不会发生冲突。
-
服务注册与发现:服务提供者在ZooKeeper上注册自己的服务,服务消费者通过ZooKeeper发现可用的服务实例。
-
配置管理:集中管理配置信息,当配置信息发生变化时,能够实时更新到所有相关的服务节点。
- 命名服务:可以通过 ZooKeeper 的顺序节点生成全局唯一 ID。
- 数据发布/订阅:通过 Watcher 机制 可以很方便地实现数据发布/订阅。当你将数据发布到 ZooKeeper 被监听的节点上,其他机器可通过监听 ZooKeeper 上节点的变化来实现配置的动态更新。
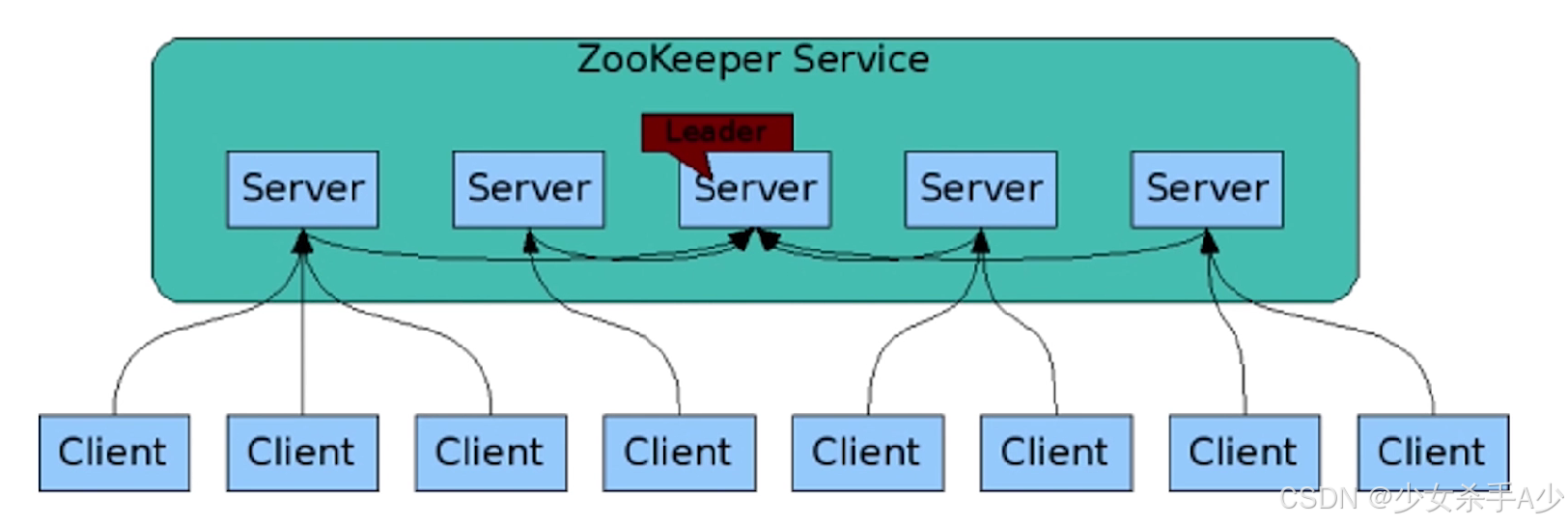
Zookeeper工作原理
- 数据模型:Zookeeper的数据模型类似于文件系统,数据以树状结构存储,每个节点称为znode。znode可以存储数据和子节点。
- 一致性协议:Zookeeper使用ZAB协议(Zookeeper Atomic Broadcast)来保证数据的一致性。ZAB协议是一种支持崩溃恢复的原子广播协议,确保在分布式环境中数据的一致性。
- Leader选举:在Zookeeper集群中,有一个Leader节点和多个Follower节点。Leader节点负责处理写请求,并将数据同步到Follower节点。Follower节点处理读请求,并从Leader节点同步数据。
- 会话管理:客户端通过会话与Zookeeper服务器交互。会话是有状态的,Zookeeper通过心跳机制检测客户端的连接状态。如果客户端长时间未发送心跳,Zookeeper会认为客户端已断开连接,并清理相关的会话信息。
- 通知机制:Zookeeper支持事件监听机制,客户端可以对znode设置监听器,当znode的数据或子节点发生变化时,Zookeeper会通知客户端。
- 数据持久化:Zookeeper将数据存储在内存中,并定期将数据快照和事务日志持久化到磁盘,以保证数据的可靠性和持久性。
Zookeeper使用
zookeeper基本数据类型
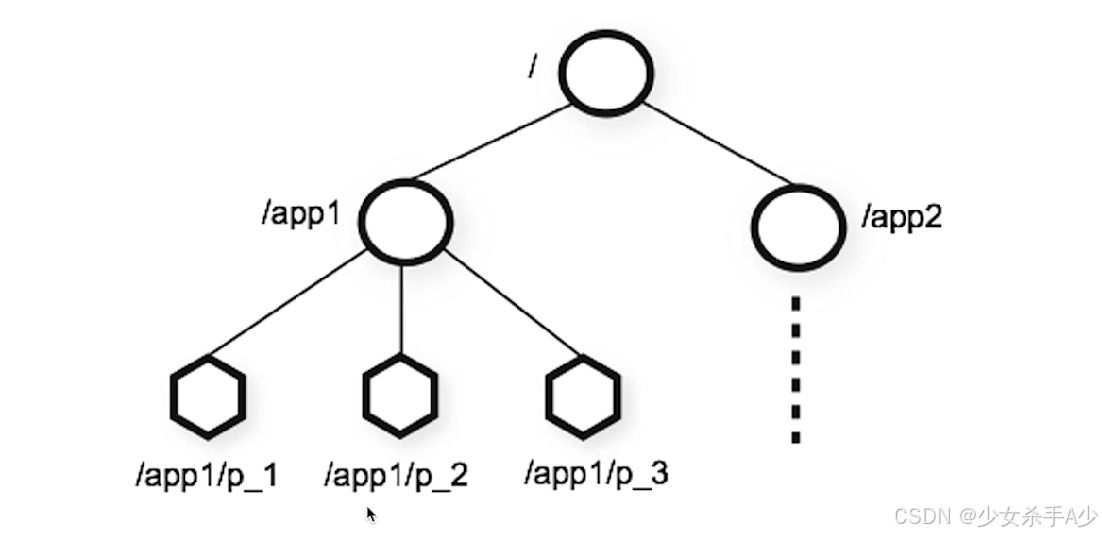
ZooKeeper 数据模型采用层次化的多叉树形结构,每个节点上都可以存储数据,这些数据可以是数字、字符串或者是二进制序列。并且。每个节点还可以拥有 N 个子节点,最上层是根节点以“/”来代表。每个数据节点在 ZooKeeper 中被称为 znode,它是 ZooKeeper 中数据的最小单元。并且,每个 znode 都有一个唯一的路径标识。
我们知道每个数据节点在 ZooKeeper 中被称为 znode,它是 ZooKeeper 中数据的最小单元。你要存放的数据就放在上面,是你使用 ZooKeeper 过程中经常需要接触到的一个概念。
我们通常是将 znode 分为 4 大类:
- 持久(PERSISTENT)节点:一旦创建就一直存在即使 ZooKeeper 集群宕机,直到将其删除。
- 临时(EPHEMERAL)节点:临时节点的生命周期是与 客户端会话(session) 绑定的,会话消失则节点消失。并且,临时节点只能做叶子节点 ,不能创建子节点。
- 持久顺序(PERSISTENT_SEQUENTIAL)节点:除了具有持久(PERSISTENT)节点的特性之外, 子节点的名称还具有顺序性。比如
/node1/app0000000001、/node1/app0000000002 - 临时顺序(EPHEMERAL_SEQUENTIAL)节点:除了具备临时(EPHEMERAL)节点的特性之外,子节点的名称还具有顺序性
znode中的数据
每个 znode 由 2 部分组成:
- stat:状态信息
- data:节点存放的数据的具体内容
[zk: 127.0.0.1:2181(CONNECTED) 6] get /dubbo
# 该数据节点关联的数据内容为空
null
# 下面是该数据节点的一些状态信息,其实就是 Stat 对象的格式化输出
cZxid = 0x2
ctime = Tue Nov 27 11:05:34 CST 2018
mZxid = 0x2
mtime = Tue Nov 27 11:05:34 CST 2018
pZxid = 0x3
cversion = 1
dataVersion = 0
aclVersion = 0
ephemeralOwner = 0x0
dataLength = 0
numChildren = 1| znode 状态信息 | 解释 |
| cZxid | create ZXID,即该数据节点被创建时的事务id |
| ctime | create time,即该节点的创建时间 |
| mZxid | modified ZXID,即该节点最终一次更新时的事务 id |
| mtime | modified time,即该节点最后一次的更新时间 |
| pZxid | 该节点的子节点列表最后一次修改时的事务 id,只有子节点列表变更才会更新 pZxid,子节点内容变更不会更新 |
| cversion | 子节点版本号,当前节点的子节点每次变化时值增加 1 |
| dataVersion | 数据节点内容版本号,节点创建时为 0,每更新一次节点内容(不管内容有无变化)该版本号的值增加 1 |
| aclVersion | 节点的 ACL 版本号,表示该节点 ACL 信息变更次数 |
| ephemeralOwner | 创建该临时节点的会话的 sessionId;如果当前节点为持久节点,则 ephemeralOwner=0 |
| dataLength | 数据节点内容长度 |
| numChildren | 当前节点的子节点个数 |
Zookeeper基本使用
# 创建znode
create /path/to/znode "data"
# 获取znode数据
get /path/to/znode
# 设置znode数据
set /path/to/znode "new data"
# 删除znode
delete /path/to/znode
# 列出znode子节点
ls /path/to/znode
# 查看znode状态
stat /path/to/znode
# 创建持久节点
create /path/to/persistent_znode "data"
# 创建临时节点
create -e /path/to/ephemeral_znode "data"
# 创建有序节点
create -s /path/to/sequential_znode "data"
# 创建临时有序节点
create -e -s /path/to/ephemeral_sequential_znode "data"
# 检查znode是否存在
exists /path/to/znode
# 设置ACL(访问控制列表)
setAcl /path/to/znode world:anyone:crdwa
# 获取ACL
getAcl /path/to/znode
# 同步znode
sync /path/to/znode
# 递归删除znode及其子节点
deleteall /path/to/znode

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









