







大家好,这是本人的第五篇笔记,记于2022.10.26,目的是分享最近的爬虫感悟,如果有什么错误或者有什么表达不清楚的地方,请斧正,谢谢。
最近的学习太忙了,社团,部门,党建各种事情铺天盖地的,所以我很久没有更新了,那么今天给大家开一个大活——爬小说。当然了,我们是尊重作者版权的,我们不会去做侵犯作者权力的事情,对吧!
目录
0.确定内容
在开始之前我们先确定自己要爬的内容和所在网址(网址也就是大佬们常说的url)我比较喜欢搞笑的,所以我们就去爬《**饶命》,网址是“大王饶命最新章节_大王饶命无弹窗全文阅读_顶点小说 (ddyueshu.com)”
1.确定爬取策略
1.1开始的第一件事情是确定自己的爬取策略,由于我现在是一个小菜鸟(如果有大佬会更加高深的东西,请不要嘲讽我这个小菜鸡,谢谢),所以现在只会两种策略,一是先将其目录的爬下来,然后爬取文本信息,二是先爬取文本信息,然后再通过此界面的跳转键(下一章)跳转。他们的效率区别如下:
| 策略一 | 策略二 | |
| 运行速度(相同的网络情况下) | 较快 | 较慢 |
| 简易程度 | 比较简单 | 非常简单,异常简单 |
如果有的小伙伴的网络很快,而且不想花时间去搞第一个,可以自己试试第一个。我就不在这里给大家介绍第一种了,另外由于策略一的内容是按照目录爬的,所以在部分网站将目录打乱之后,你所爬下来的内容也会出现内容顺序不正确的情况
1.2让我们看看它的目录,嗯,可以很轻松的发现他把所有的目录放在了一个界面,那我们就可以直接使用策略二了
2..在策略下开始写备注
(一定要写备注,不然一两个月之后你就不知道自己是怎么想的了,到时候如果需要重新使用这段代码,你就只能重新写了,老浪费时间了)
3.准备对应的库
本次使用的库有time(用来休眠,防止出现因为高频请求而被封掉IP),requests(得到返回数据),bs4里面的BeautifulSoup(定位对应内容),其中requests,bs4的库需要下载,如果有不知道怎么下的可以去看看我的其他内容,具体的链接点我主页有(如果没有就是还没有写好,emmmmmmm,如果写好了我就会把这句话划掉),具体情况如下:
import time
import requests
from bs4 import BeautifulSoup
它不出现报错就是好的
4.根据策略执行第一部分
我们先爬取目录的网址:
4.1保存url
设定一个字符串数据url_list_url来保存我们已经确定的目录页的网址的,如图
import time
import requests
from bs4 import BeautifulSoup
url_list_url = "https://www.ddyueshu.com/6_6394/"4.2设定自己的header
(网络里面的User-Agent)(这个可能会违规大家如果想看,去看看我首页的,就不放这里了,防止本篇内容没了)
4.3进入浏览器的开发者模式
点击F12,进入浏览器的开发者模式,进入元素部分,如图
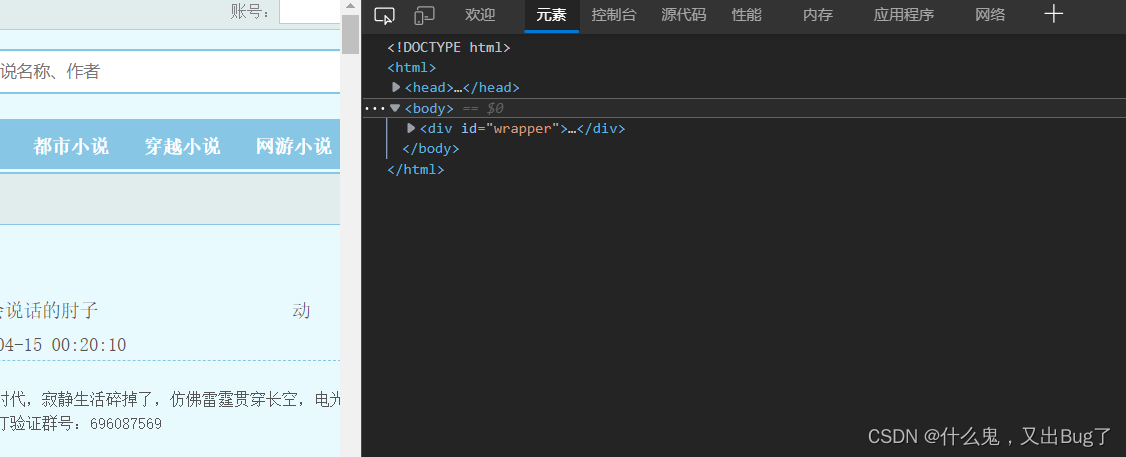
4.4找到对应的节点
点击右上角的查询符号,然后点击章节名称之后找到对应的节点
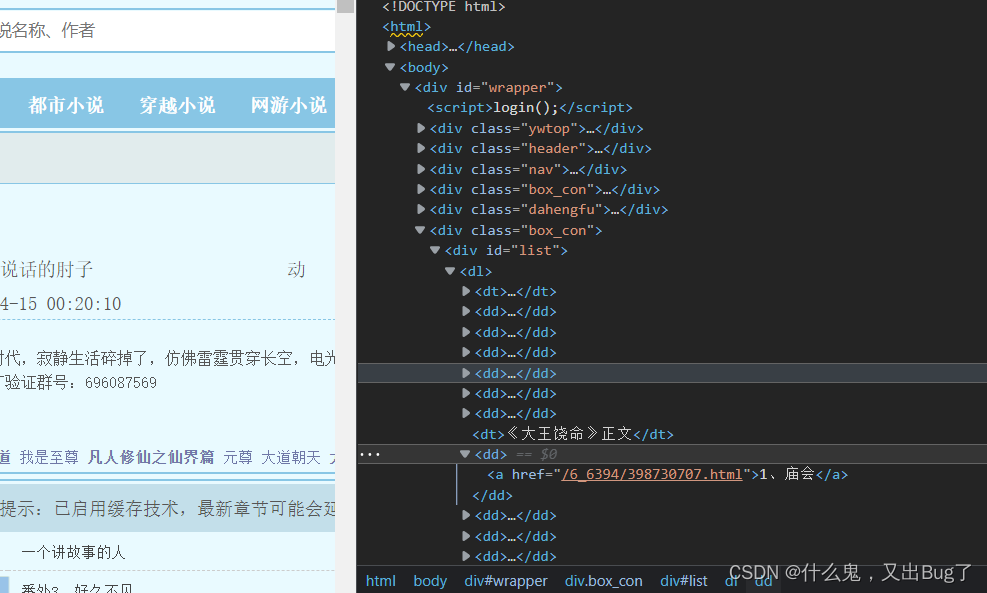
4.5确定编码格式
然后确定本网站的编码格式,一般来说都是在head里面的charset内
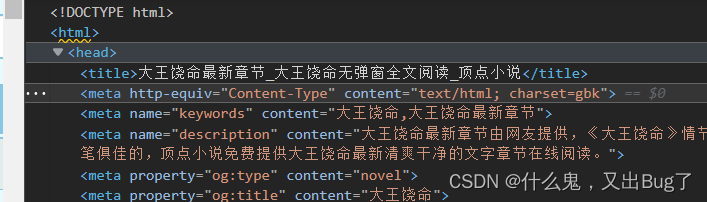
4.6得到网页源代码
(可以输出看看),(这个大佬们一般叫做请求头)
import time
import requests
from bs4 import BeautifulSoup
url_list_url = "https://www.ddyueshu.com/6_6394/"
header={
"User-Agent": "#####"}
# 获得网页源代码
response = requests.get(url=url, headers=header).content.decode("gbk")
print(response)
输出之后如果可以得到这样的结果就说明基本正确了
我们仔细观察就会发现其内容和元素内的内容基本一致了
4.7定位到要爬取的内容
从这里开始我们就可以使用BeautifulSoup。
为了使用他我们要先转化文件格式,其中"html.parser"是转化方式(当然,在这里面有许多的转化方法,但是此方法是容错效率最高的)
代码如下
import time
import requests
from bs4 import BeautifulSoup
url_list_url = "https://www.ddyueshu.com/6_6394/"
header = {
"User-Agent": "####"}
# 获得文件
response = requests.get(url=url_list_url, headers=header).content.decode("gbk")
print(response)
soup = BeautifulSoup(response, "html.parser")
# 类型切换
url_list_point = soup.find('div', id="list").find_all("a")
print(url_list_point)
print(type(url_list_point))观察输出,我们可以知道以下几点:
一.输出的类型是列表
二.有一部分(0到5)是我们不需要的
所以我们可以使用列表的切片方法来获取我们所需要的章节名
4.8获取节点中的属性
我使用的方法是get("(对应的属性名)"),具体代码如下:
import time
import requests
from bs4 import BeautifulSoup
url_list_url = "https://www.ddyueshu.com/6_6394/"
header = {
"User-Agent": "####"}
# 获得文件
response = requests.get(url=url_list_url, headers=header).content.decode("gbk")
print(response)
soup = BeautifulSoup(response, "html.parser")
# 类型切换
url_list_point = soup.find('div', id="list").find_all("a")
url_list_point=url_list_point[6:]
# 放列表
url_list=[]
for each in url_list_point:
url_list.append(each.get("href"))
print(url_list)输出以后可以看到对应的数据,如图:
![]()
4.9确定url列表
很明显我们得到的是对应url的后面一部分,所以为了不出现混淆,我们可以现在将同样的前半部分拼接上去,代码如下:
import time
import requests
from bs4 import BeautifulSoup
url_list_url = "https://www.ddyueshu.com/6_6394/"
header = {
"User-Agent": "####"}
# 获得文件
response = requests.get(url=url_list_url, headers=header).content.decode("gbk")
print(response)
soup = BeautifulSoup(response, "html.parser")
# 类型切换
url_list_point = soup.find('div', id="list").find_all("a")
url_list_point=url_list_point[6:]
# 放列表
url_list=[]
for each in url_list_point:
url_list.append('https://www.ddyueshu.com/'+each.get("href"))
print(url_list)可以看出现在的url_list就是我们的url列表
5.将对应方法设为函数
设为函数可以让我们更好的看代码,层次更加明显,还可以提高代码的利用率(当我们需要写其他类似代码的时候)
6.执行策略的第二步
6.1进入开发者模式,完成基本信息的确定
在进入对应的网页后,点击F12进入开发者模式,明确编码方式,并快速定位到节点,,如图:
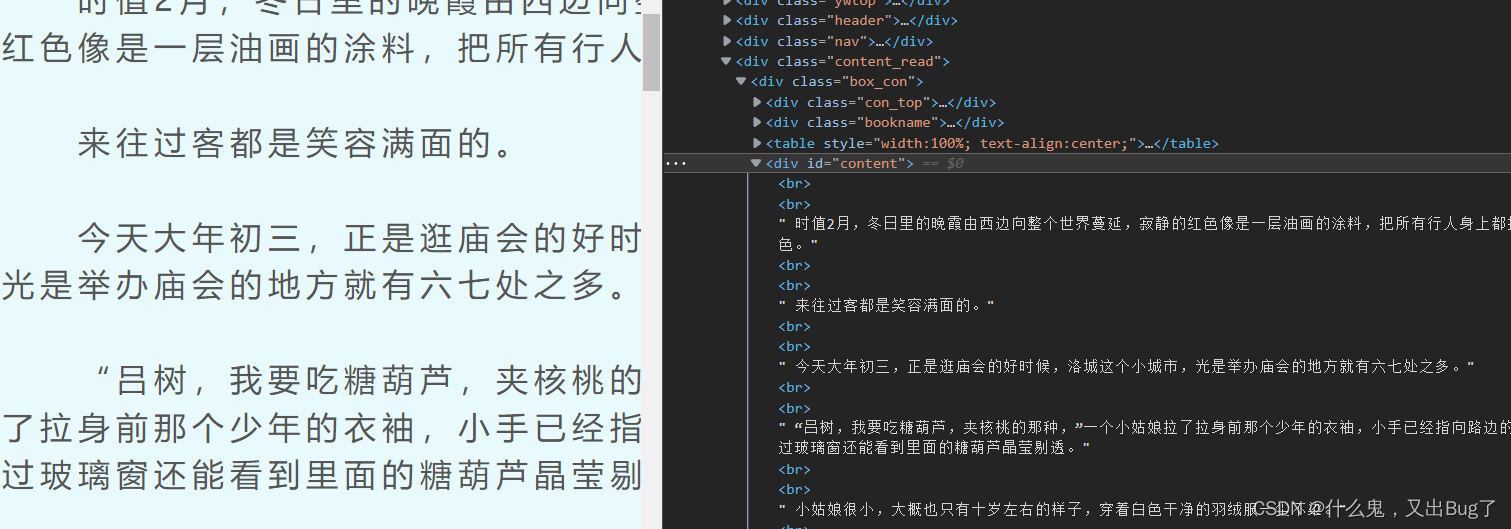
6.2完成代码
根据对应的信息完成代码(真的不是敷衍,而是上面基本上已经讲过了,不想水,虽然现在还没有收到过点赞,但是和朋友吹牛的时候还是可以说我的文章干货满满,至少有东西可以吹),具体代码如下:
import requests
from bs4 import BeautifulSoup
from alive_progress import alive_bar
url_list_url = "https://www.ddyueshu.com/6_6394/"
header = {
"User-Agent": "#####"}
def get_url_list(url_list_url):
# 获得文件
response = requests.get(url=url_list_url, headers=header).content.decode("gbk")
soup = BeautifulSoup(response, "html.parser")
# 类型切换
url_list_point = soup.find('div', id="list").find_all("a")
url_list_point=url_list_point[6:]
url_list=[]
for each in url_list_point:
url_list.append("https://www.ddyueshu.com"+each.get("href"))
return url_list
def get_txt(url):
response = requests.get(url=url, headers=header).content.decode("gbk")
soup = BeautifulSoup(response, "html.parser")
# 类型切换
txt = str(soup.find('div', id="content"))
txt=txt.replace('<div id="content"><br/><br/>','')
txt=txt.replace('<br/><br/>','\n')
txt=txt.replace('<script>chaptererror();</script><br/>请记住本书首发域名:ddyueshu.com。顶点小说手机版阅读网址:m.ddyueshu.com</div>','')
return txt
url_list=get_url_list(url_list_url)
txt=''
for each in url_list:
txt=txt+get_txt(each)
print(txt)好了,本次的博客就这样了,谢谢屏幕前面的你能看到这里。
记于2022.10.26,与诸君共勉。


















 915
915

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











