






积累知识,分享智慧,让成长之路不再孤单
Zookeeper:
是一个分布式应用程序协调服务;可以用来维护配置信息,实现分布式同步等;
是一种类似于文件系统树的数据结构来存储数据,每个节点称为 ZNode,每个 node 可以存储数据,并
可以设置监听事件,来监听节点的数据变化;提供了 watch 机制,由客户端对其监听;
ZNode可以分为四种类型:持久化节点、持久化顺序节点、临时节点和临时顺序节点。
● 特点
○ 顺序一致性:从同一客户端发起的请求会顺序应用到 zookeeper 中
○ 原子性:所有事务请求的处理结果在整个集群中所有机器上的应用情况是一致的,要么都应用,要么都没应用。
○ 持久性:可以持久化
○ 实时性:每个客户端的系统视图都是最新的
zookeeper 应用场景
● 数据的发布 / 订阅:通过 Watcher 机制进行监听节点变化,动态更新
● 负载均衡:通过 zookeeper 的临时节点实现,存储 serve 的地址表
● 分布式配置管理
● 服务注册和发现
● 分布式锁:节点的唯一性
● 集群管理
● 命名服务:可以根据 zookeeper 的顺序节点生成全局唯一 ID
zookeeper 保存的数据是在内存中的,其功能也是基于其能保存数据
zookeeper 的基本概念
数据模型
Data model
采用层次化的多叉树形结构,每个节点上都可以存储数据,每个节点还可以有 N 个子节点,最上层是根节点 / 代表,每个数据节点称为 znode,是 zookeeper 中数据的最小单元,每个 znode 都有一个唯一的路径标识。
zookeeper 主要是用来协调服务的,而不是存储业务数据的,每个节点的数据大小上限是 1M
数据节点
znode
分类:
● 持久节点
● 临时节点:生命周期随客户端会话关联,且只能作为叶子节点,不能创建子节点
● 持久顺序节点
● 临时顺序节点
组成部分:
● stat:状态信息,包含事务 ID、节点创建时间,子节点个数
● data:节点存储的具体内容
version:
由 stat 记录,记录 znode 的三个相关的版本:
● dataVersion:当前 znode 版本
● cversion:当前 znode 子节点的版本
● aclVersion:当前 znode 的 ACL 版本
权限控制
ACL
ZooKeeper 采用 ACL(AccessControlLists)策略来进行权限控制,类似于 UNIX 文件系统的权限控制。
权限包括:
● CREATE:能创建子节点
● READ:可读
● WRITE:可写
● DELETE:能删除子节点
● ADMIN:能设置 ACL
身份认证:
● world:默认,所有用户都可无条件访问
● auth:不使用任何 id,代表已认证的用户
● digest:用户名密码
● ip:对指定 ip 限制
事件监听器
Watcher
会话
session
Session 可以看作是 ZooKeeper 服务器与客户端的之间的一个 TCP 长连接,通过这个连接,客户端能够通过心跳检测与服务器保持有效的会话,也能够向 ZooKeeper 服务器发送请求并接受响应,同时还能够通过该连接接收来自服务器的 Watcher 事件通知。
每个 session 都有一个唯一的 sessionID
Zookeeper 集群
集群间通过 ZAB 协议保证数据的一致性,主要有 主从模式
集群中的角色:
Leader:负责所有写请求,并同步给其他 follower 节点
Follower:参与选举 leader
Observer:观察 leader 节点数据变化
ZooKeeper 集群中的所有机器通过一个 Leader 选举过程 来选定一台称为 “Leader” 的机器,Leader 既可以为客户端提供写服务又能提供读服务。除了 Leader 外,Follower 和 Observer 都只能提供读服务。Follower 和 Observer 唯一的区别在于 Observer 机器不参与 Leader 的选举过程,也不参与写操作的“过半写成功”策略,因此 Observer 机器可以在不影响写性能的情况下提升集群的读性能。
选举过程:
zookeeper 集群节点数一般为奇数
zookeeper 集群中存活节点数大于宕机数才能使用 3 台只允许宕机一台,4 台也是
脑裂
只有一个 leader 节点,但是可能分成两组,每组各选了一个 leader
解决:过半机制,少于等于一般不能产生 leader
ZAB 协议
Zookeeper 负载均衡的实现:
主要是通过集群中的多个节点来实现的。当客户端发送请求时,ZooKeeper会根据某种策略(例如轮询或随机)
将请求分配给不同的节点,从而实现负载均衡
与Nginx的负载均衡相比,ZooKeeper的负载均衡是基于应用程序级别的,而Nginx的负载均衡是基于网络级别的
ZooKeeper通过分布式事务和事务队列来保证原子性。
实现 分布式锁
CP
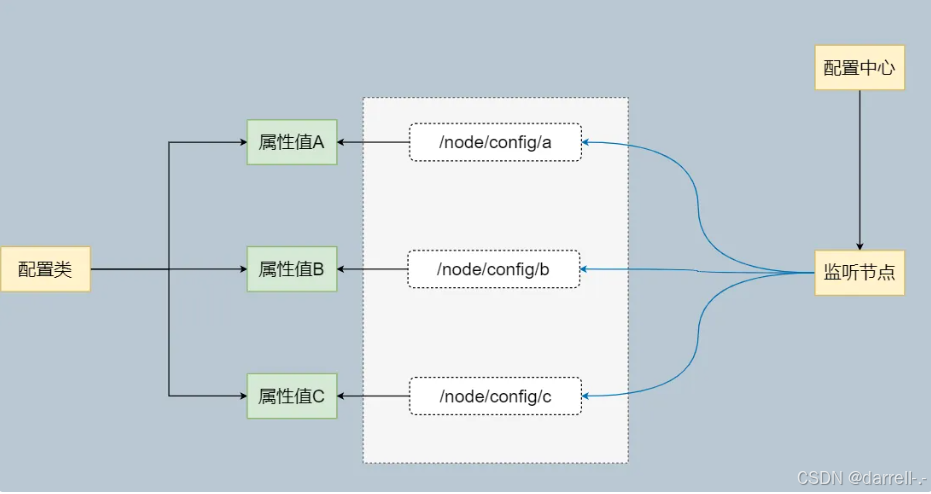
基于 Zookeeper 实现配置中心
配置中心,它的核心功能在于不需要上线系统的情况下,改变系统中对象或者属性的值。是属性的值,也就是你在通过类获取某个属性,判断;功能开关、渠道地址、人群名单、息费费率、切量占比等等,这些可能随时动态调整的值,都是通过配置中心实现的。
使得各个服务可以动态变更配置,使用 Zookeeper 的节点监听和节点值的变化来动态设置 Java 类中属性的变化。
ZooNavigator 可视化工具
docker run \
-d \ # 在后台运行容器
-p 19000:19000 \ # 将主机的19000端口映射到容器的19000端口
-e HTTP_PORT=19000 \ # 设置容器的环境变量HTTP_PORT为19000
--name zoonavigator \ # 将容器命名为zoonavigator
--restart unless-stopped \ # 在容器退出时自动重启容器,除非手动停止
elkozmon/zoonavigator:latest # 使用elkozmon/zoonavigator:latest镜像运行容器

















 2009
2009

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









