






训练完成后,会在runs文件夹下生成结果分析(前提是model.train()方法中的参数plots设为True,这样才会生成结果分析图标),如下实例是task为detect,mode为train的一次记录:
1.weight文件夹
里边存着训练时性能最好的一批权重,以及最后一个epoch后更新的权重
2.args.yaml
存着model.train(args)方法里的args,能查看自己训练时用的是什么参数,方便后续进行参数性能对比
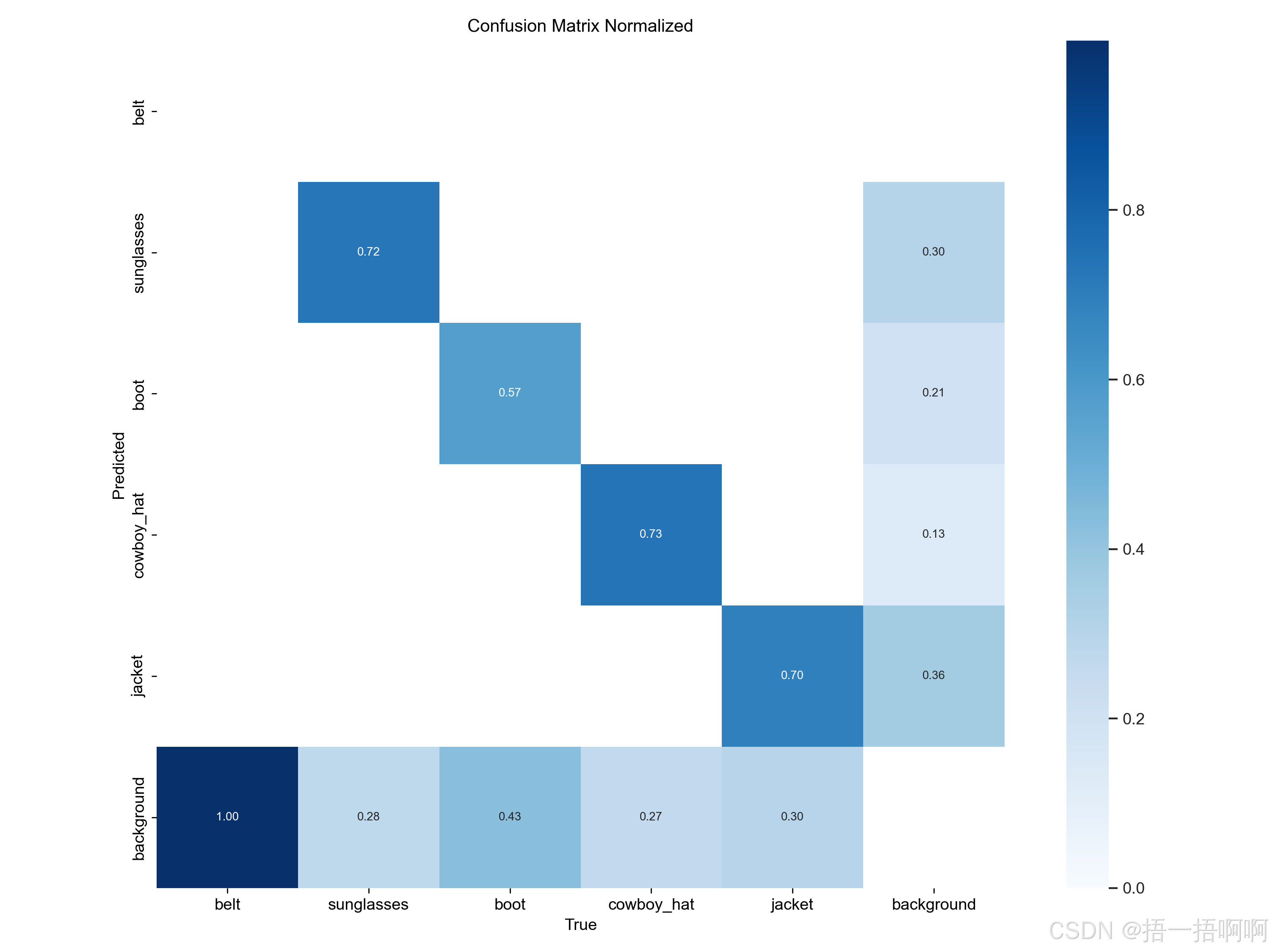
3.confusion_matrix.png
混淆矩阵,记录了真实值与预测值的结果
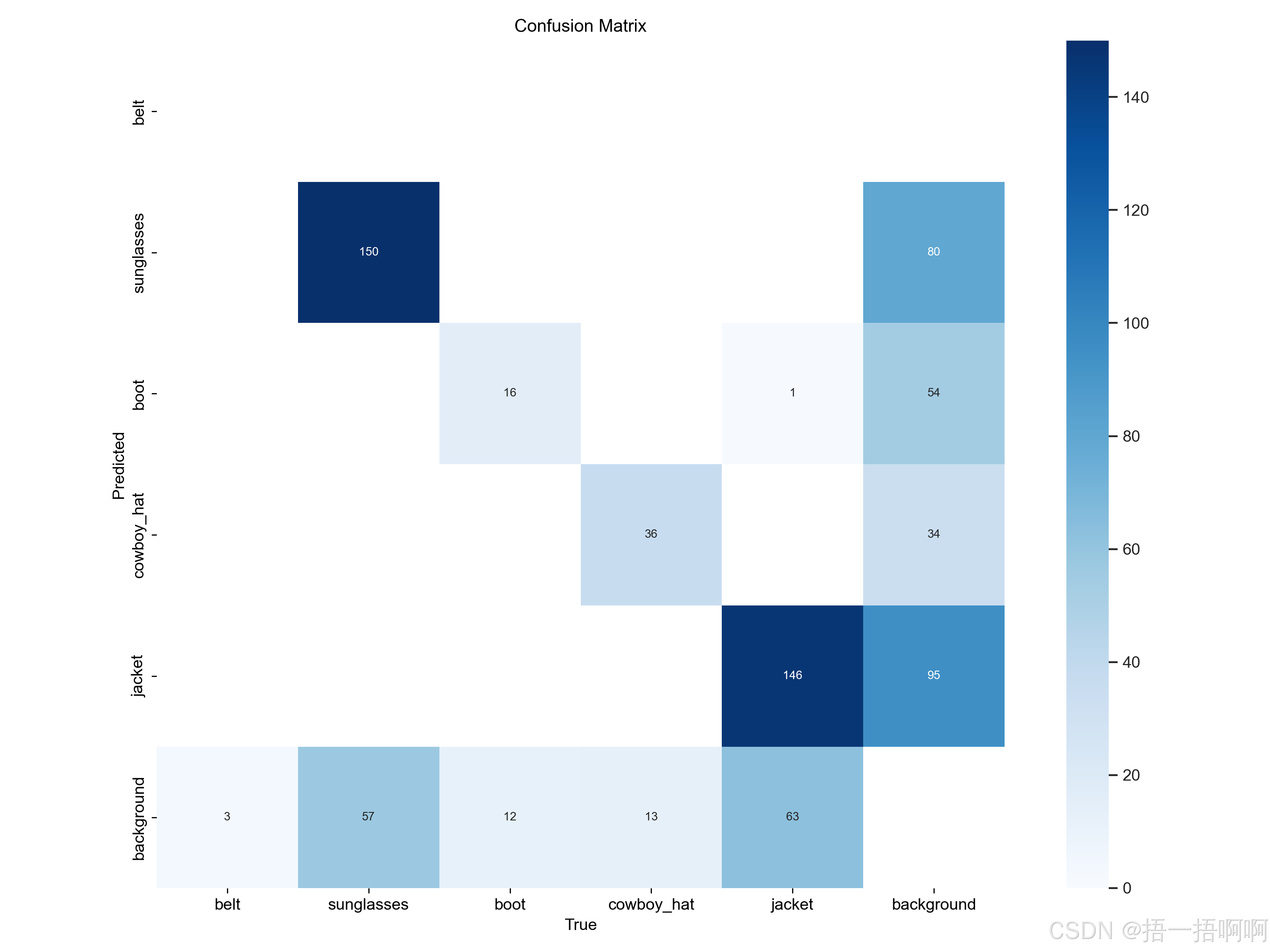
方块呈正对角线时,表示每个类都能被正确分类,此时性能最好,如下:
4.confusion_matrix_normalized.png
归一化后的混淆矩阵,就是把方块里的值换成0~1范围了,更能体现比例的关系
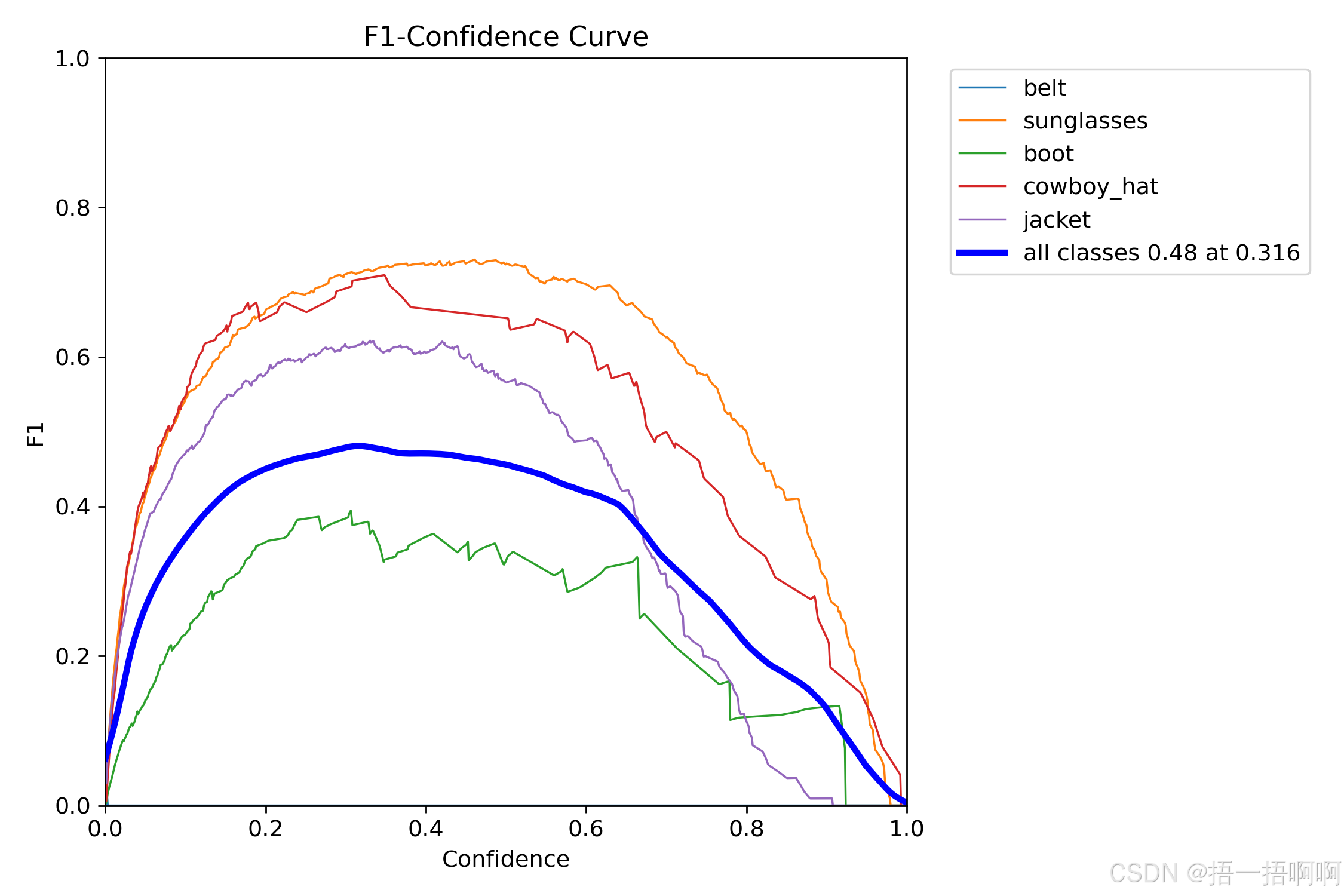
5.F1_curve.png
记录了不同置信度下F1分数的高低,F1取值范围从 0.0 到 1.0 。F1 分数是精确率(Precision)和召回率(Recall)的调和平均数,用于综合评估模型的性能,值越高表示模型性能越好。
精确率
P
r
e
c
i
s
i
o
n
=
T
P
T
P
+
F
P
Precision=\frac{TP}{TP+FP}
Precision=TP+FPTP
召回率
R
e
c
a
l
l
=
T
P
T
P
+
F
N
Recall=\frac{TP}{TP+FN}
Recall=TP+FNTP
F1就是精确率与召回率的调和平均
F
1
=
2
∗
P
r
e
c
i
s
o
n
∗
R
e
c
a
l
l
P
r
e
c
i
s
o
n
+
R
e
c
a
l
l
F1=2*\frac{Precison*Recall}{Precison+Recall}
F1=2∗Precison+RecallPrecison∗Recall即
F
1
=
2
∗
T
P
2
∗
T
P
+
F
P
+
F
N
F1=\frac{2*TP}{2*TP+FP+FN}
F1=2∗TP+FP+FN2∗TP
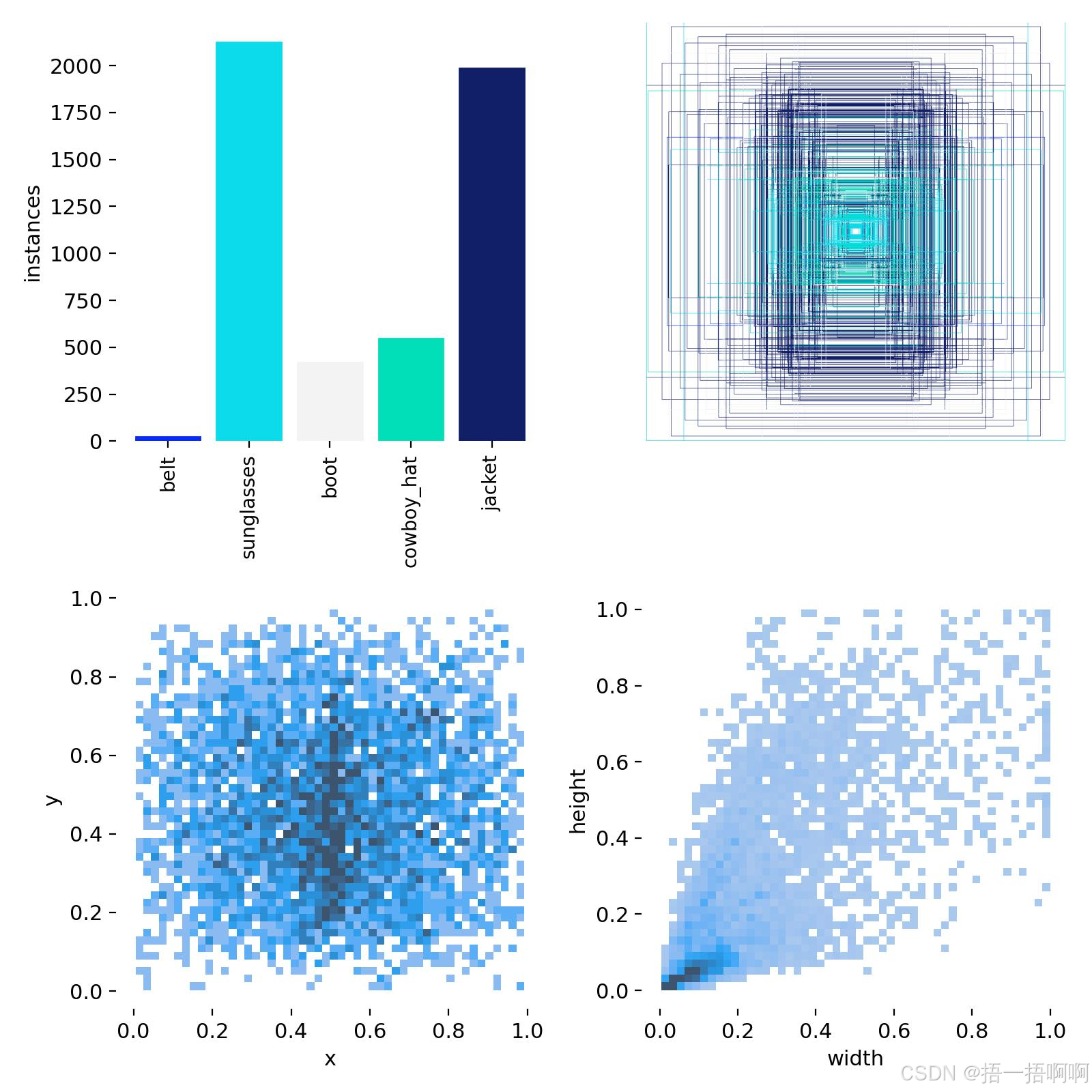
6.labels.jpg
对给出的样本真实值label进行分析:
左上角柱状图
- 内容:展示了不同类别目标的实例数量 。横坐标类别包括“belt”(腰带)、“sunglasses”(太阳镜)、“boot”(靴子)、“cowboy_hat”(牛仔帽)、“jacket”(夹克) 。纵坐标为“instances”(实例数)。可以看出,“sunglasses”和“jacket”实例数较多,“belt”实例数极少。
- 作用:帮助了解数据集中各类别目标出现的频次差异,可用于分析样本均衡性,判断是否存在类别不平衡问题,影响模型训练和检测性能。
右上角边界框图
- 内容:一堆相互重叠的边界框,不同颜色(主要是蓝色系)代表不同的边界框 。这些边界框可能是对某一类或多类目标的预测框或标注框。
- 作用:直观呈现目标检测中边界框的分布、重叠情况等。通过观察边界框的聚集程度、重叠比例等,可评估模型对目标位置预测的准确性、目标密集区域的检测效果等。 可以看出图片大物体多还是小物体多,以便找到侧重点 \textcolor{red}{可以看出图片大物体多还是小物体多,以便找到侧重点} 可以看出图片大物体多还是小物体多,以便找到侧重点。
左下角散点图
- 内容:以坐标点展示目标位置信息,横坐标为“x”,纵坐标为“y” 。每个点代表一个目标实例,点的颜色深浅可能表示该位置目标出现的密度或频率。
- 作用:用于分析目标在图像平面上的分布规律,比如是否集中在某些特定区域, 有助于了解目标在场景中的常见出现位置 \textcolor{red}{有助于了解目标在场景中的常见出现位置} 有助于了解目标在场景中的常见出现位置,辅助模型优化和数据增强策略制定。
右下角散点图
- 内容:展示目标边界框的宽高信息,横坐标为“width”(宽度),纵坐标为“height”(高度) 。点的分布反映不同目标边界框宽高的取值情况,颜色深浅可能代表宽高组合出现的频率。
- 作用:帮助了解数据集中目标尺寸的分布特征,指导模型在训练时对不同尺寸目标的处理策略,比如调整锚框尺寸设置等,提升对不同大小目标的检测性能。
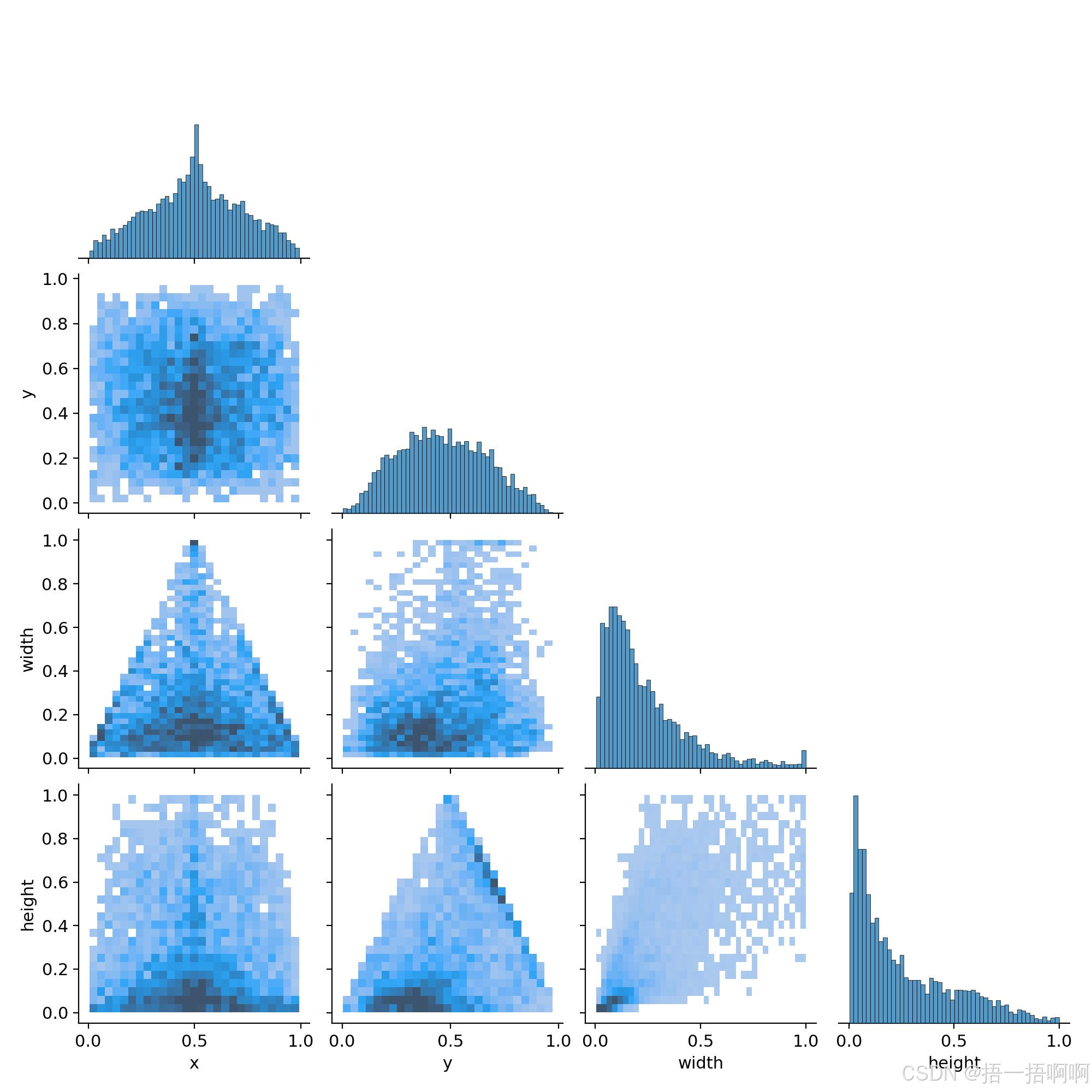
7.labels_correlogram.jpg
标签相关性图,(x,y)为框的中心点坐标吧。
以点图(x,height)为例,他说明了中心点横坐标x取不同值时,此时标注框的height大小关系。
条状图x、条状图y联合表面物体主要聚集在图片中间。
右下角条状图height表明height偏向于较小值,再结合width条状图得知,真实框的大小偏向于小框,所以样本中小物体比重占的多,那么我就可以侧重于识别小物体。
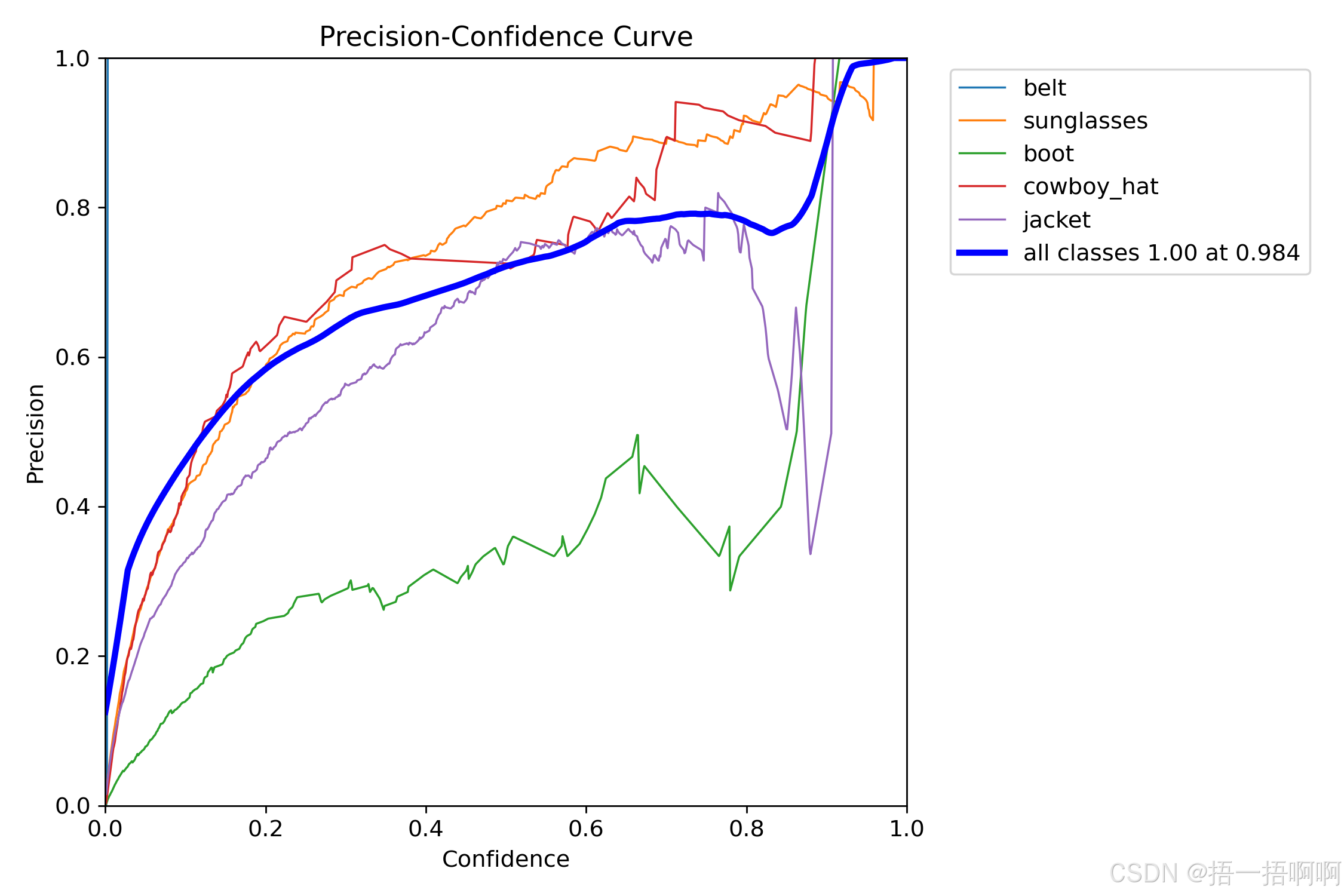
8.P_curve.png
显而易见,这是准确率与置信度关系的曲线
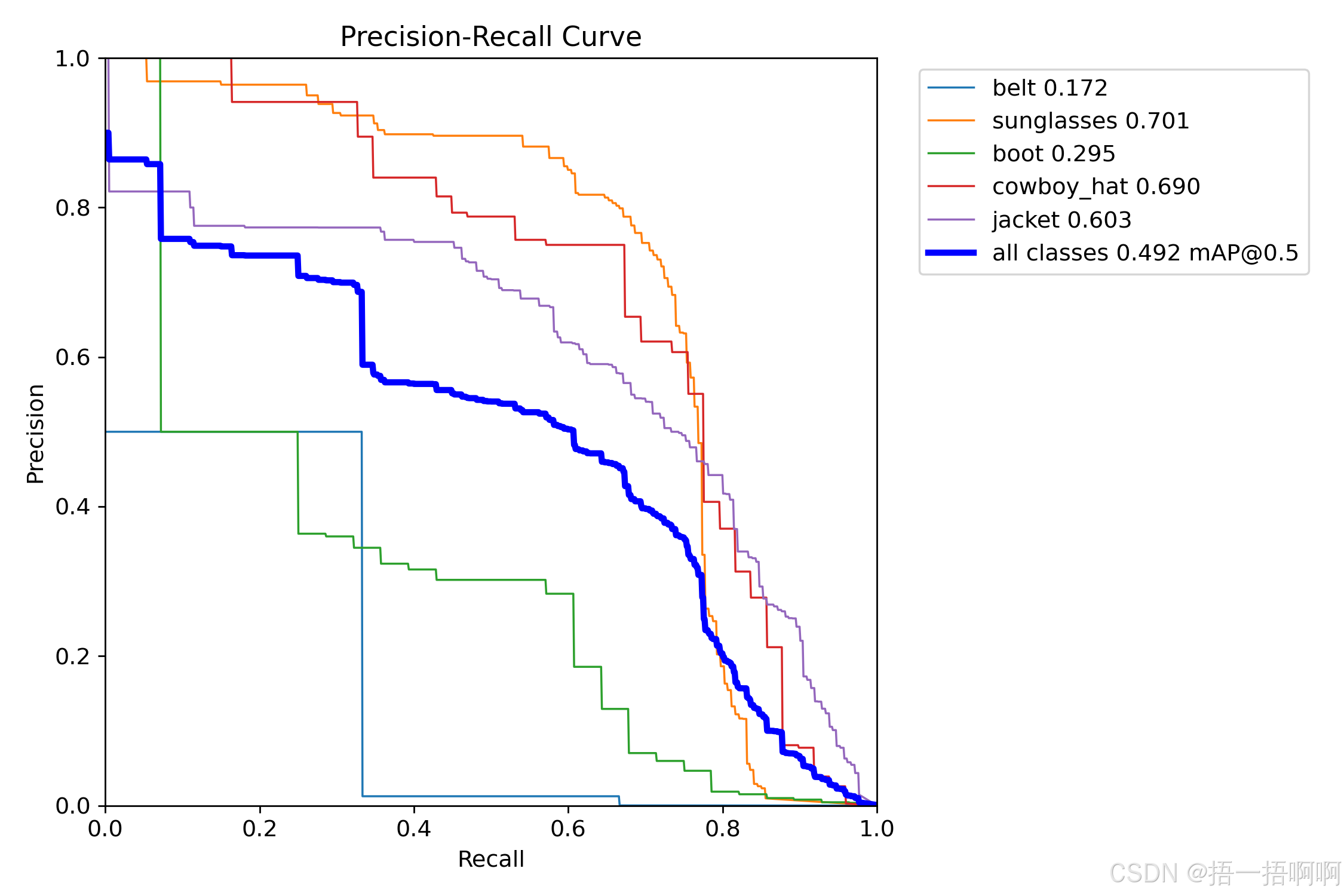
9.PR_curve.png
准确率与召回率关系的曲线图(两者会有制约,只能折中)
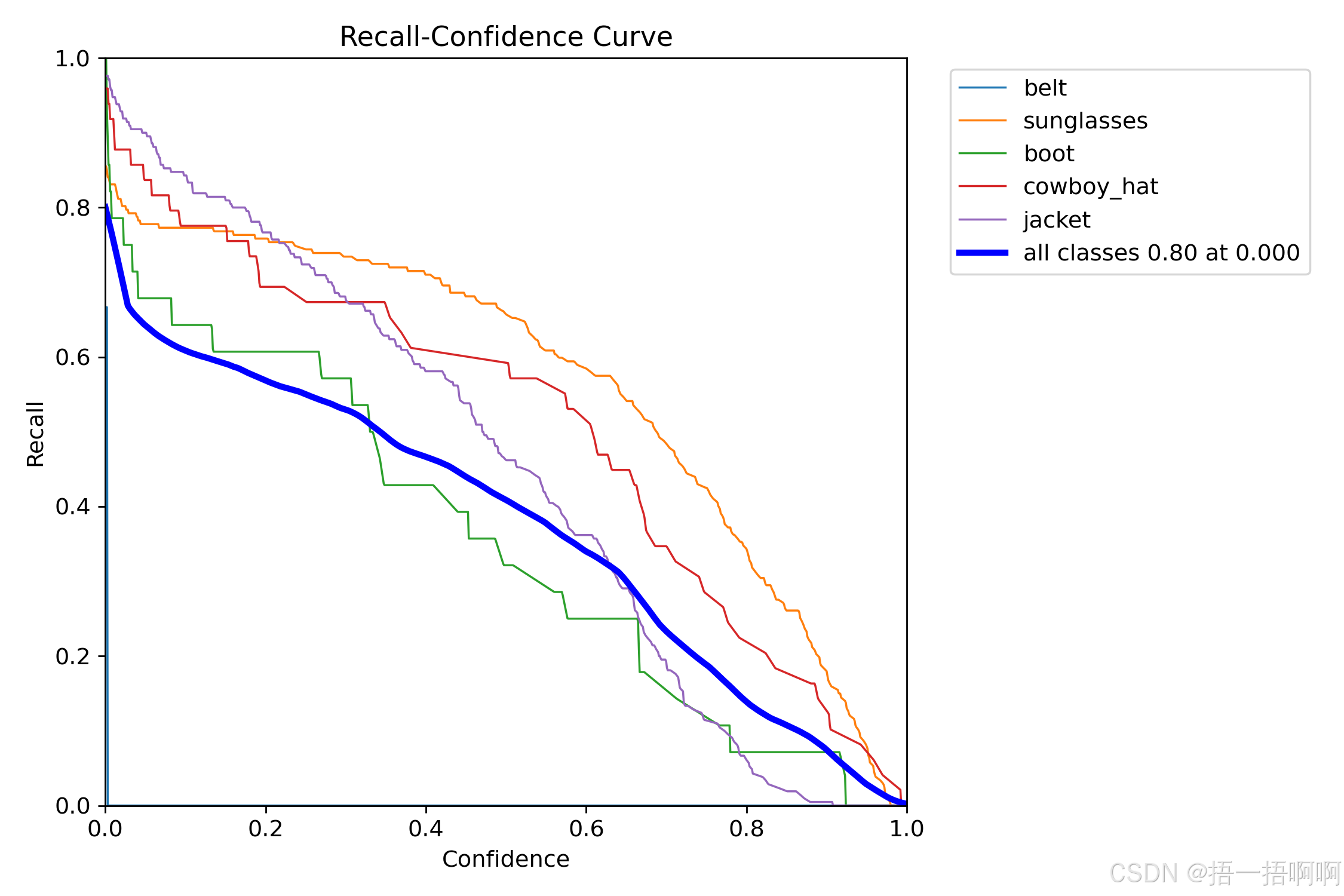
10.R_curve.png
召回率与置信度之间的关系曲线
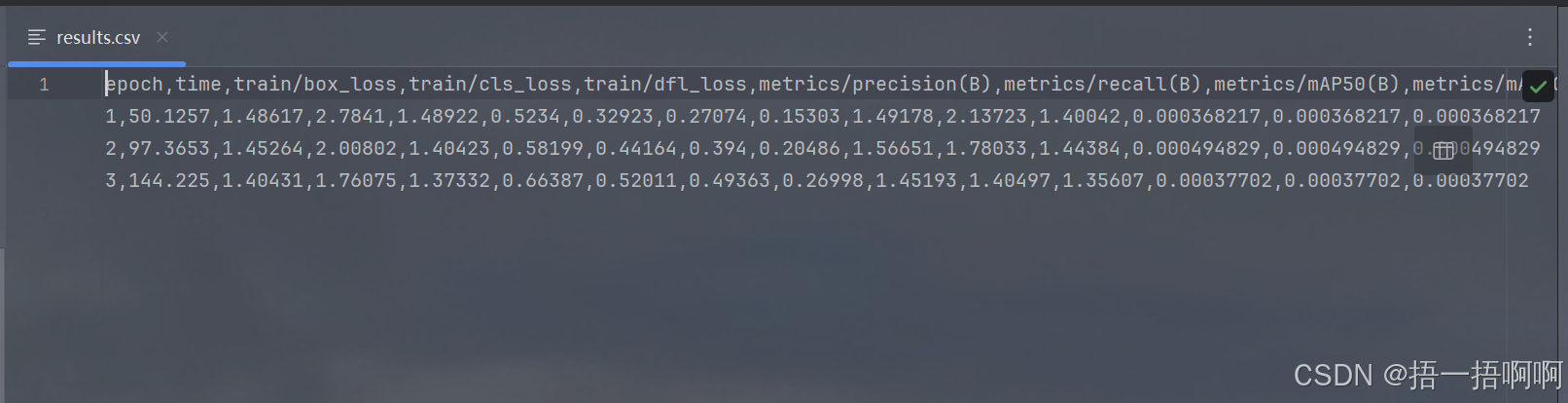
11.results.csv
存有各种对于模型的评估指标
epoch
time:经历完每个epoch时的时间
train/box_loss:训练时每个epoch的box_loss,衡量了预测框与真实框的吻合度
train/cls_loss:衡量了预测类与真实类的吻合度
train/dfl_loss:衡量了框的稳定程度,不然碰到模糊边界时,框容易大小乱动
metrics/precision(B):B 类别的精确率,指预测为 B 类的结果中真正属于 B 类的比例,衡量分类的准确性
metrics/recall(B)
metrics/mAP50(B):B 类别的平均精度均值(IoU 阈值为 0.5 时 ),综合评估模型对 B 类目标的检测性能,考量不同召回率下的精确率。

metrics/mAP50-95(B):B 类综合检测性能指标,考量多 IoU 阈值下检测效果。
val/box_loss
val/cls_loss
val/dfl_loss
lr/pg0:通常指的是骨干网络权重的学习率。
lr/pg1:一般与 YOLO 层权重的学习率相关。
lr/pg2:常表示其他额外参数(如偏置项)的学习率。
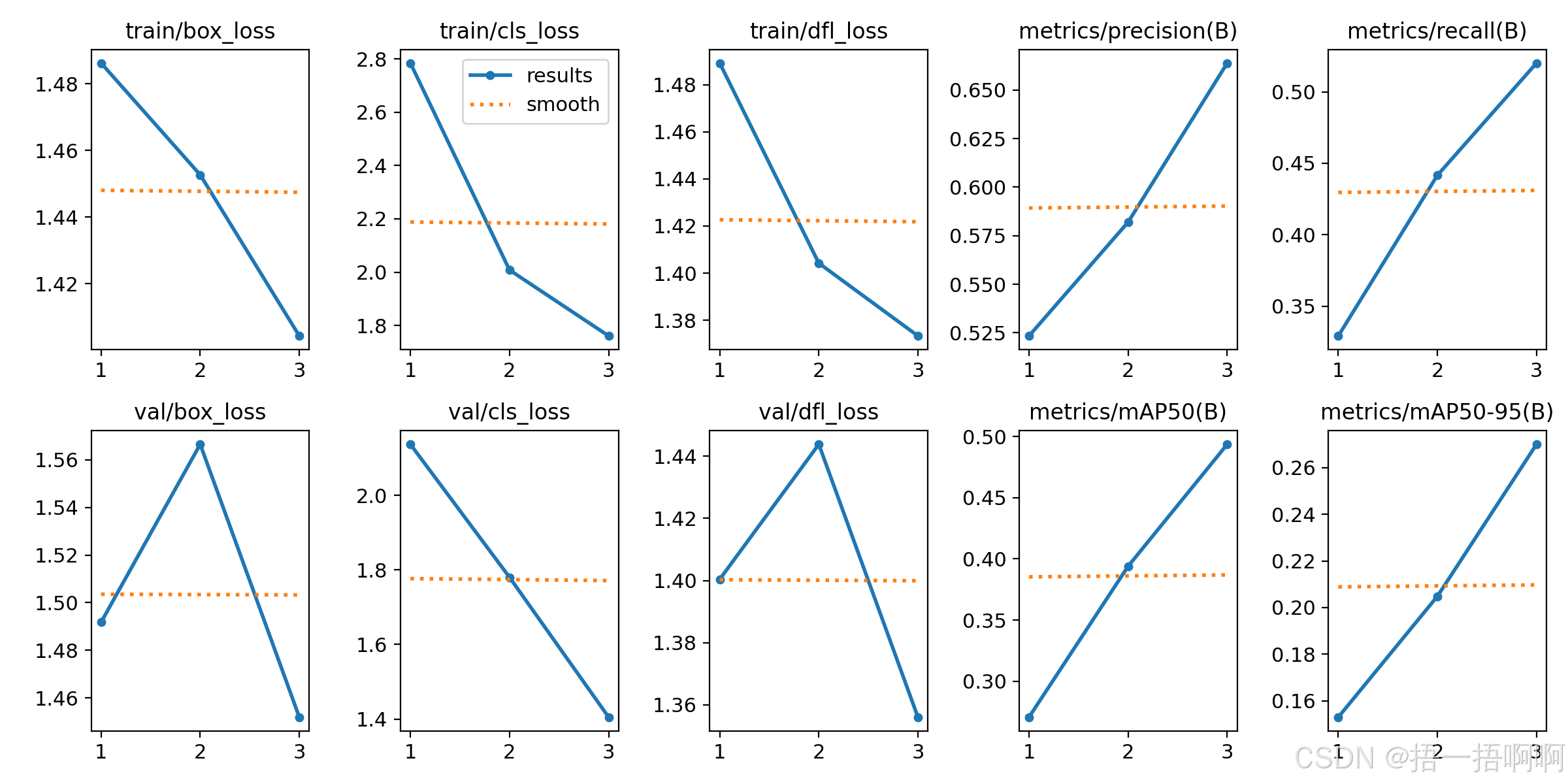
12.results.png
对上面的results.csv里边某些评估指标的绘图
13.train_batch(i).jpg
我的理解是训练时第i个epoch中第一个批量的检测结果,当我batch_size=16时,下边的图片刚好囊括了16个小图片

14.val_batch(i)_labels.jpg
我的理解是验证时第i个epoch中第一个批量的实际类别结果

15.val_batch(i)_pred.jpg
与上面的val_batch(i)_labels.jpg对应,这里的是预测结果


















 9万+
9万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









