







文章目录
文章目录
程序环境和预处理
一、程序的编译环境和执行环境
- 在
ANSI C(美国国家标准学会制定的C语言标准) 的任何一种实现中,存在两个不同的环境:-
- 翻译环境,在这个环境中源代码被转换为可执行的机器指令
-
- 执行环境,用于实际执行代码
-
Ⅰ、程序的编译和链接
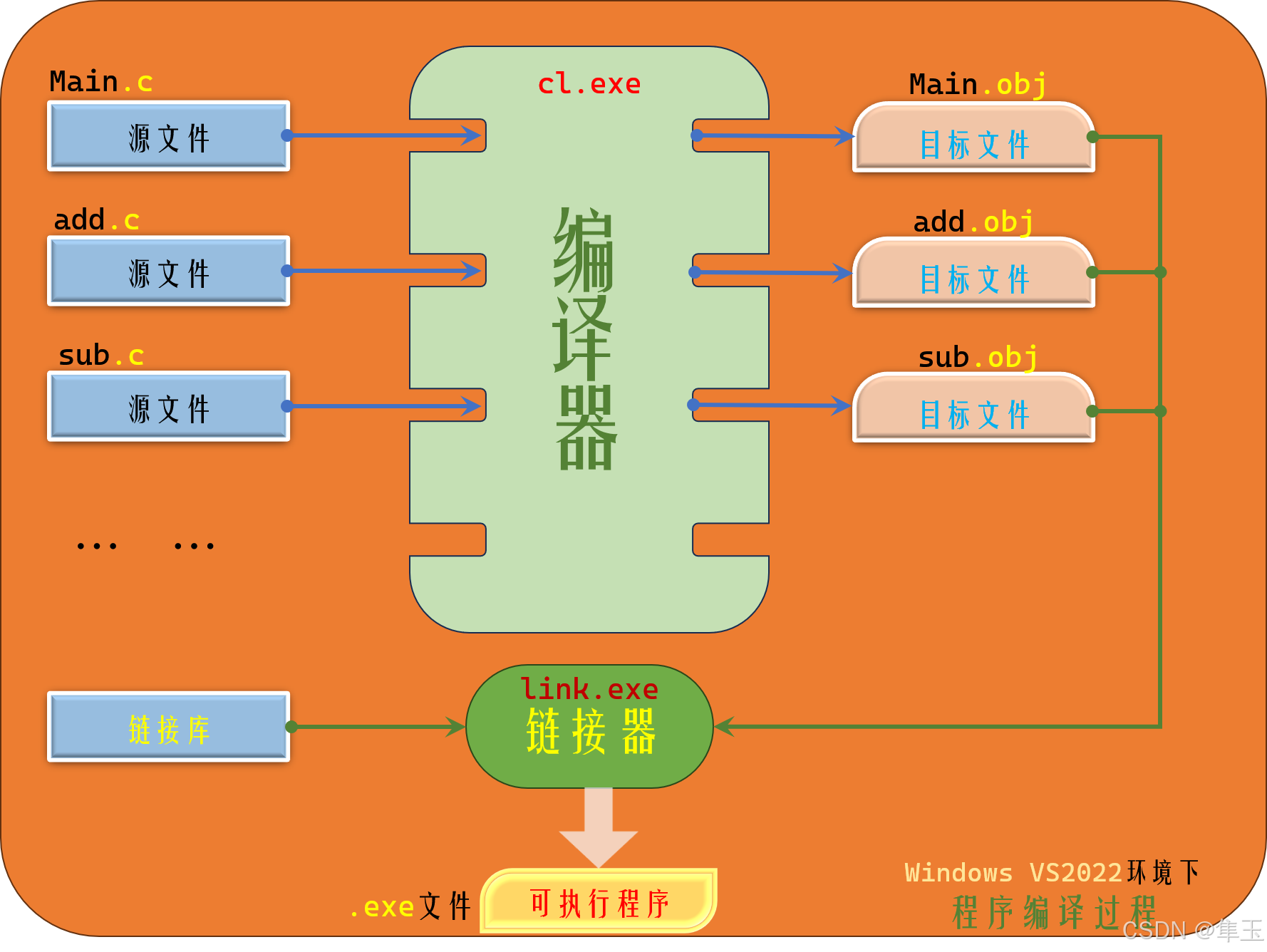
.c源文件经编译器编译后会产生.obj目标文件,.obj文件再经链接器处理得到.exe可执行程序
- 组成一个程序的每个源文件通过编译过程分别转换成目标代码
- 每个目标文件由链接器
(linker)捆绑在一起,形成一个单一而完整的可执行程序- 链接器同时也会引入标准C函数库中任何被该程序所用到的函数,而且它可以搜索程序员个人的程序库,将其需要的函数也链接到程序中
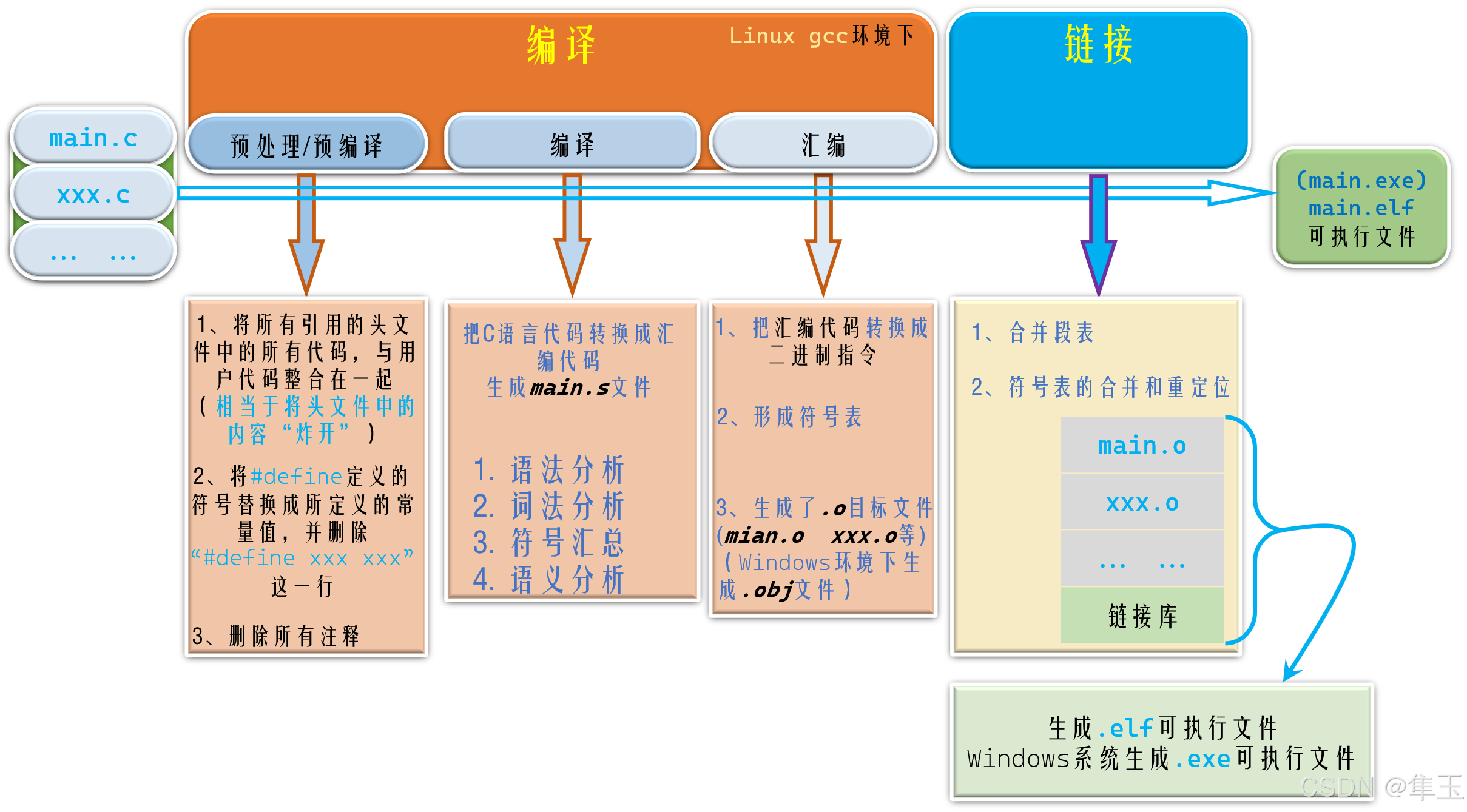
- 可执行文件生成的大致过程:
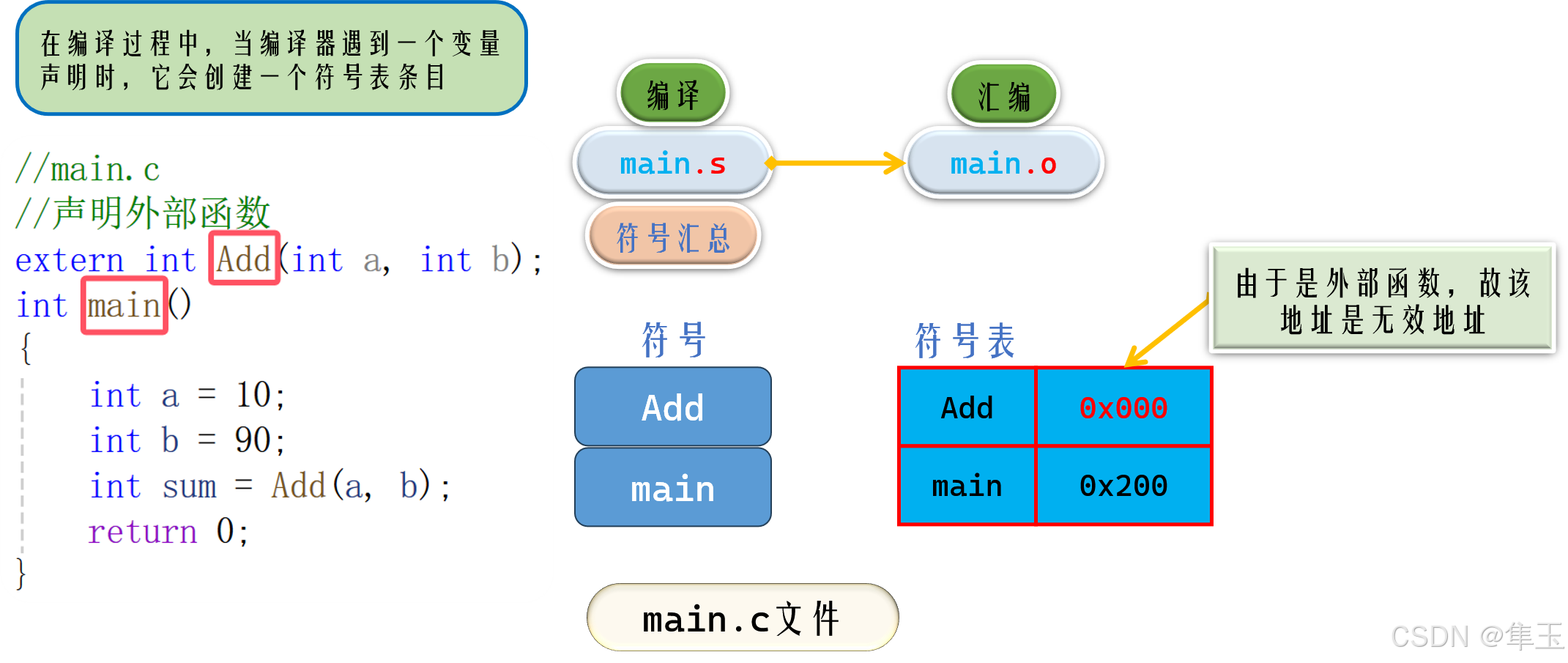
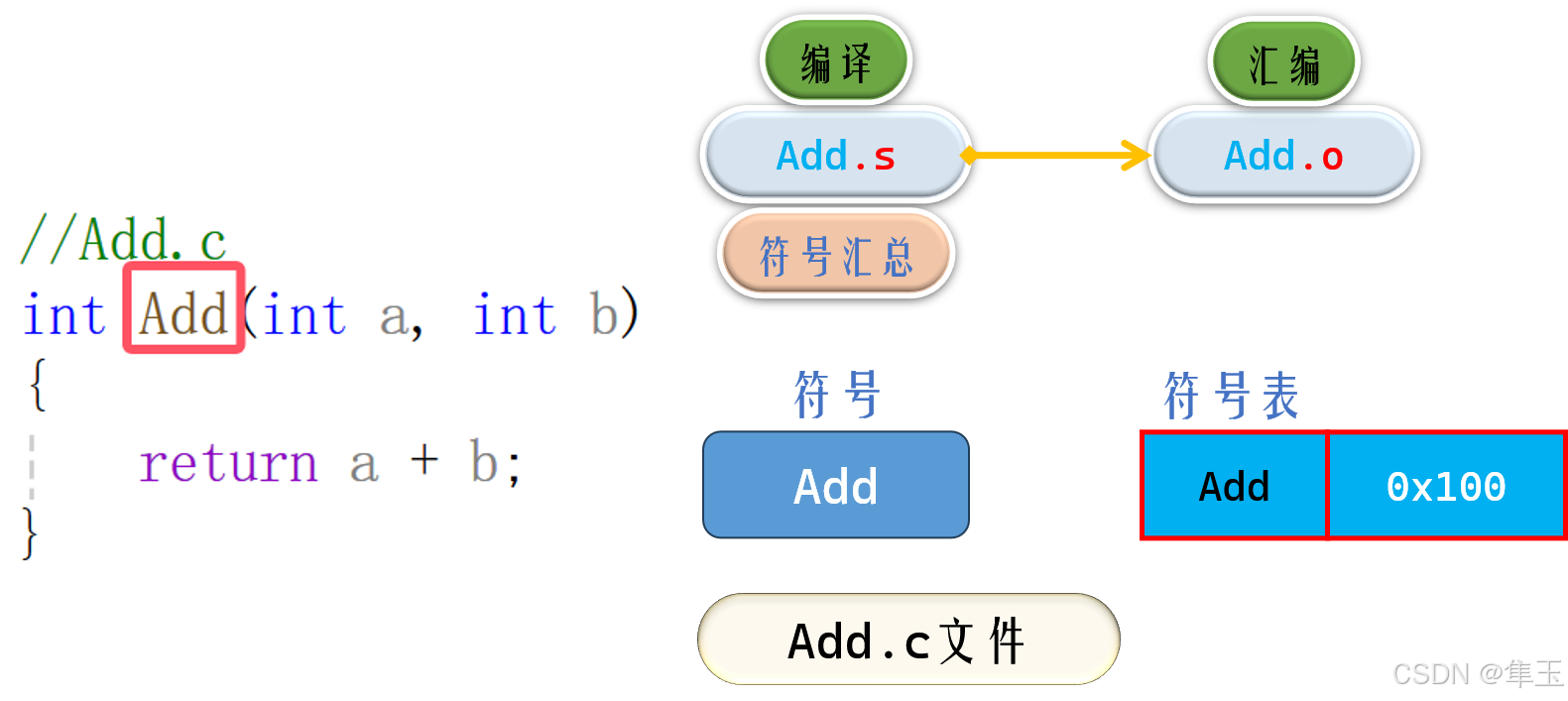
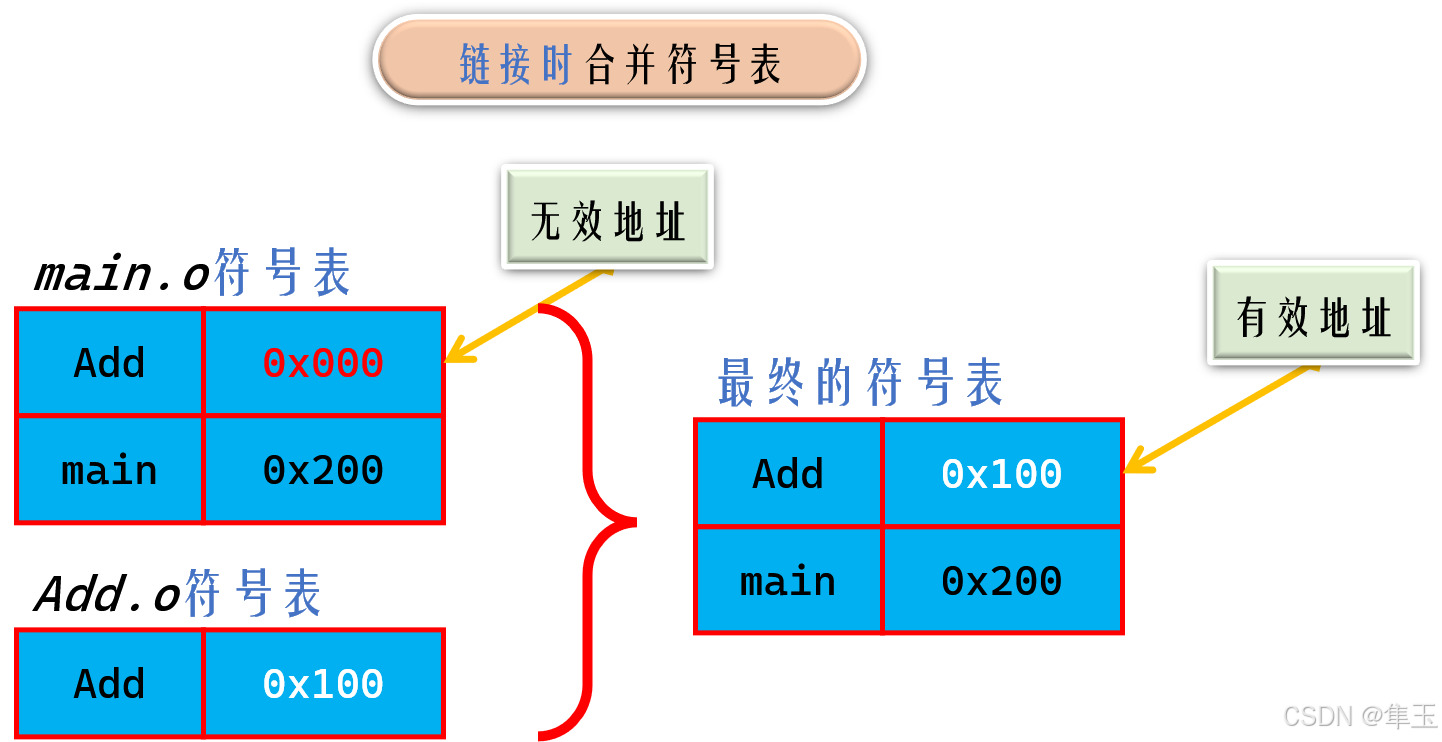
- 符号汇总以及符号表的生成:
Ⅱ、运行环境
程序执行的过程:
- 程序必须载入内存中。在有操作系统的环境中,一般这个由操作系统完成。在独立的环境中,程序的载入必须由手工安排,也可能是通过可执行代码置入只读内存来完成
- 程序的执行便开始。接着便调用
main函数 - 开始执行程序代码。这个时候程序将使用一个运行时堆栈(stack),存储函数的局部变量和返回地址。程序同时也可以使用静态(static)内存,存储于静态内存中的变量在程序的整个执行过程一直保留它们的值
- 终止程序。正常终止
main函数;也有可能是意外终止
二、预处理
Ⅰ 预定义符号
预定义符号
(Predefined Symbols)或预定义标识符是编译器自动定义的一组特殊的标识符,它们在编译时就已经确定了值这些符号通常用于提供关于编译环境、编译时间、编译器版本等信息
几个常见的预定义符号:
__FILE__:一个字符串字面量,进行编译的源文件__LINE__:一个整数值,表示当前代码行的行号__DATE__:一个字符串字面量,包含编译日期,格式为"MMM DD YYYY",其中MMM是月份的缩写__TIME__:一个字符串字面量,包含编译时间,格式为"HH:MM:SS"__func__:一个字符串字面量,包含当前函数的名称。在C99标准中引入__STDC__:一个整数值,如果编译器符合ANSI C标准,其值为1,否则未定义
使用示例:
int main()
{
for (int i = 0; i < 10; i++)
{
printf("file:%s line:%d date:%s time%s %d\n",
__FILE__, __LINE__, __DATE__, __TIME__, i);
}
return 0;
}
-
file : D : \C_Code_1\Demo_9\demo.c line : 389 date : Dec 15 2024 time13 : 00 : 06 0 file : D : \C_Code_1\Demo_9\demo.c line : 389 date : Dec 15 2024 time13 : 00 : 06 1 file : D : \C_Code_1\Demo_9\demo.c line : 389 date : Dec 15 2024 time13 : 00 : 06 2 file : D : \C_Code_1\Demo_9\demo.c line : 389 date : Dec 15 2024 time13 : 00 : 06 3 file : D : \C_Code_1\Demo_9\demo.c line : 389 date : Dec 15 2024 time13 : 00 : 06 4 file : D : \C_Code_1\Demo_9\demo.c line : 389 date : Dec 15 2024 time13 : 00 : 06 5 file : D : \C_Code_1\Demo_9\demo.c line : 389 date : Dec 15 2024 time13 : 00 : 06 6 file : D : \C_Code_1\Demo_9\demo.c line : 389 date : Dec 15 2024 time13 : 00 : 06 7 file : D : \C_Code_1\Demo_9\demo.c line : 389 date : Dec 15 2024 time13 : 00 : 06 8 file : D : \C_Code_1\Demo_9\demo.c line : 389 date : Dec 15 2024 time13 : 00 : 06 9 -
注意事项:
- 预定义符号的值在编译时就已经确定,它们不是在运行时计算的
- 使用预定义符号可以提高代码的可移植性和灵活性,因为它们允许程序在不同的编译环境下自适应
- 预定义符号通常用于日志记录、调试信息、条件编译等场景
Ⅱ #define定义符号
#define指令用于创建符号常量,也称为宏(Macros)。是一种简单的文本替换工具,它允许在代码中定义一个标识符,并在编译时将其替换为另一个值或表达式
基本用法:
#define STU students
STU:宏的名称,通常使用大写字母表示,以区分变量和宏students:宏被替换的文本,可以是常量、表达式或其他代码
使用示例:
#define PI 3.14 //定义常量
#define STU stdents //为students这个关键字创建一个更简短的名字
#define PRINT_HW printf("hello world\n") //定义标识符,不要加 ;
Ⅲ #define定义宏
条件宏定义 可以在编译时根据条件定义宏:
#ifdef DEBUG #define DEBUG_PRINT(x) printf("Debug: " #x " = %d\n", x) #else #define DEBUG_PRINT(x) //空宏,不产生任何代码 #endif
- 这样,只有在定义了
DEBUG的情况下,DEBUG_PRINT宏才会输出调试信息
带参数的宏 #define SQUARE(x) ((x) * (x))
- 这个宏
SQUARE接受一个参数x,并将其平方。使用时,SQUARE(2)将被替换为(2 * 2)- 为了避免优先级,导致计算结果错误
应在合适的地方加上()
带多个参数的宏 宏可以模拟函数的行为,但它们在预处理阶段进行文本替换,而不是在运行时调用函数:
#define MAX(a, b) ((a) > (b) ? (a) : (b))
- 这允许通过
MAX(3, 5)来获取两个数中的最大值
取消宏定义 使用
#undef可以取消之前定义的宏:#undef SAFE_ADD
带有副作用的宏参数 宏在替换时可能会引入副作用,特别是当宏的参数是表达式时:
#define INC(x) (x += 1)
- 使用
INC(x++)可能会导致问题,因为x++会被计算两次,使用x+1即可避免
Ⅳ # 和 ##
宏的字符串化
#操作符可以将宏的参数转换为字符串:#define STRINGIFY(x) #x
例如使用
STRINGIFY(PI)会得到"PI"#define PRINT(X) printf("The value of " #X " is %d\n",X); int main() { int A = 5; int B = 10; //printf("The value of A is %d\n", A); //printf("The value of B is %d\n", B); PRINT(A); PRINT(B); return 0; }
The value of A is 5 The value of B is 10该例使用宏,将参数A和B转换为字符串打印出来
宏的标记粘贴
##操作符可以将两个标记连接在一起,即使它们是宏参数:#define CONCAT(a, b) a ## b
例如使用
CONCAT(MAX, _TEST)会得到MAX_TEST#define SOC(X,Y) X##Y int main() { int No_1 = 98; int No_6 = 88; printf("%d\n", SOC(No_, 1)); printf("%d\n", SOC(No_, 6)); return 0; }
98 88允许宏定义从分离的文本片段创建标识符
Ⅴ #define 的替换规则
在程序中扩展 #define 定义符号和宏时,需要涉及几个步骤:
- 在调用宏时,首先对参数进行检查,看看是否包含任何由
#define定义的符号。如果是,它们首先被替换 - 替换文本随后被插入到程序中原来文本的位置。对于宏,参数名被它们的值替换
- 最后,再次对结果文件进行扫描,看看它是否包含任何由
#define定义的符号。如果是,就重复上述处理过程
注意:
- 宏参数和
#define定义中可以出现其他#define定义的变量。但是对于宏,不能出现递归 - 当预处理器搜索
#define定义的符号的时候,字符串常量的内容并不被搜索
Ⅵ 使用函数和使用宏的优劣
函数的优劣 优点:
- 类型安全:函数在编译时进行类型检查,可以避免类型不匹配的错误
- 作用域限制:函数具有局部作用域,不会对全局作用域产生影响
- 易于调试:函数调用可以被调试器跟踪,便于调试和分析
- 节省资源:函数在调用时分配资源,返回后释放,而宏在每次使用时都会生成代码
- 支持递归:函数可以递归调用自身,宏则不能递归调用
缺点:
- 开销较大:函数调用涉及到一系列的操作,如保存寄存器、堆栈操作等,可能会有性能开销
- 限制较多:函数不能用于所有场合,如作为常量或需要内联执行的场合
宏的优劣 优点:
- 性能:宏在预处理阶段进行文本替换,没有函数调用的开销
- 灵活性:宏可以在任何地方使用,包括作为常量或在需要内联执行的场合
- 简洁性:宏可以简化复杂的表达式或创建简单的常量
缺点:
- 类型不安全:宏在预处理阶段进行文本替换,不进行类型检查,可能导致类型错误
- 作用域问题:宏替换可能会引入作用域问题,尤其是在宏定义中使用了外部变量时
- 难以调试:宏替换后的代码在调试时难以跟踪,因为它们在源代码中并不存在
- 代码膨胀:宏在每个使用点都会生成代码,可能导致代码膨胀和不必要的重复
- 潜在错误:宏替换可能导致意外的副作用,尤其是在宏参数是表达式时
| 特性 | 函数 | 宏 |
|---|---|---|
| 类型安全 | 是 | 否 |
| 作用域 | 有 | 无,宏替换可能影响全局作用域 |
| 调试支持 | 是 | 否 |
| 资源分配 | 函数调用时分配,返回后释放 | 每次使用都会生成代码,可能导致资源浪费 |
| 递归支持 | 支持 | 不支持宏递归 |
| 性能开销 | 有,函数调用涉及保存寄存器和堆栈操作 | 无,宏在预处理阶段进行文本替换 |
| 灵活性 | 受限制,不能用于常量或内联执行场合 | 高,可以在任何地方使用,包括常量定义 |
| 简洁性 | 代码可能较长,但清晰 | 可以简化复杂表达式,但易出错 |
| 代码膨胀 | 无 | 有,宏在每个使用点都会生成代码 |
| 潜在错误 | 低,编译器提供错误检查 | 高,宏替换可能导致意外副作用 |
| 预处理器支持 | 否 | 是,宏在预处理阶段处理 |
Ⅶ 命名约定
- 函数名:不全大写
- 宏:全大写
Ⅷ #undef 取消宏定义
#undef指令用于取消之前使用#define指令定义的宏
基本语法:
#undef MACRO_NAME
MACRO_NAME:要取消定义的宏的名称。示例:
假设有一个程序,其中定义了一个宏
DEBUG,用于控制调试信息的输出:#define DEBUG 1在程序的某个部分,若想要禁用调试信息的输出,这时可以使用
#undef来取消DEBUG的定义:#undef DEBUG
Ⅸ 命令行定义
- 通过命令行在编译时定义宏。这通常用于条件编译,允许开发者在编译期间根据需要启用或修改程序的特定部分
- 命令行定义宏的方法依赖于使用的编译器
使用 -D 选项可以在命令行中定义宏:
gcc -DDEBUG -o myprogram myprogram.c
- 这里,
-DDEBUG告诉编译器定义名为DEBUG的宏。这等同于在源代码中使用#define DEBUG
Ⅹ 条件编译
① #if 和 #endif
#if允许你根据表达式的值(通常是宏定义)来决定是否编译代码段#endif标记条件编译块的结束#if 1 printf("Hello\n");代码段 #endif
- 当
#if后的代码值为真,则参与编译
② #ifdef 和 #ifndef
#ifdef用于检查某个宏是否已经被定义#ifdef ADD=#if defined(ADD)#ifdef DEBUG printf("%d\n", x); #endif
- 如果
DEBUG已经被定义,则编译printf("%d\n", x);
#ifndef用于检查某个宏是否未被定义#ifndef ADD=#if !defined(ADD)#ifndef MAX_VALUE #define MAX_VALUE 100 #endif
- 如果
MAX_VALUE没有被定义,则编译#define MAX_VALUE 100
③ #else 和 #elif
#else用于在#ifdef或#ifndef条件不满足时执行#elif用于在多个#ifdef条件中提供额外的条件检查
defined(macro):如果宏macro已经被定义,表达式的结果为真(1);否则为假(0)#ifdef DEBUG printf("Debug mode\n"); #elif defined(RELEASE) printf("Release mode\n"); #else printf("Unknown mode\n"); #endif
- 如果
DEBUG已经被定义,则printf("Debug mode\n");参与编译
- 如果#elif后的内容为真,则printf("Release mode\n");参与编译
- 如果以上条件都不满足,则printf("Unknown mode\n");参与编译
④ #define 和 #undef
#define用于定义宏,可以在命令行中定义或在源代码中定义#undef用于取消宏的定义#define FEATURE_X #ifdef FEATURE_X // 代码段,当FEATURE_X被定义时编译 #else // 代码段,当FEATURE_X未定义时编译 #endif #undef FEATURE_X
注意事项
- 条件编译指令在预处理阶段处理,这意味着它们在编译器进行语法分析之前就已经决定了代码的包含或排除
- 条件编译可以嵌套使用,但应避免过度嵌套,以保持代码的清晰和可维护性
- 使用条件编译时,确保所有路径都经过考虑,避免遗漏重要的错误检查或功能实现
- 条件编译指令不应与正常的逻辑控制语句(如
if、else)混淆,它们在编译时处理,而不是在运行时
XI 文件包含
- 在写程序时,若是一个头文件被多次包含,则在程序预处理时会产生较多的冗余,进而占用系统资源;对此可以使用以下解决方案
防止头文件被多次包含::方案1:
#pragam once int Add(int a, int b);
- 加上
#pragam once后该文件中的内容只会被编译一次- 部分较老的编译器不支持
防止头文件被多次包含::方案2:
#ifndef __ADD_H__ #define __ADD_H__ int Add(int a, int b); #endif
- 这样也可以防止头文件(此处是
add.h)被多次包含
引用头文件时,使用<>和""的查找策略不同
<>查找策略:- 直接去库目录下查找
- 如果找不到,则会报错(编译错误)
""查找策略:- 先在源文件路径下查找
- 如果找不到,则去库目录下查找
XII 其它预处理指令
1.
#error
#error指令用于在编译时生成一个错误。这通常用于条件编译中,当某些条件不满足时,可以强制编译器报错并停止编译#ifdef UNSUPPORTED_PLATFORM #error "This platform is not supported." #endif2.
#pragma
#pragma是一个编译器指令,用于向编译器提供特定的指令或选项。它可以用来控制编译器的行为,如优化级别、代码段、编译器警告等
#pragma的具体行为取决于编译器,不同的编译器可能支持不同的#pragma指令#pragma once // 通常用于防止头文件被多次包含 #pragma warning(disable: 4996) // 禁用特定警告3.
#line
#line指令用于改变编译器报告错误和警告时显示的文件名和行号这在处理头文件或生成代码时特别有用,因为它可以提供更准确的调试信息
#define MY_HEADER_NAME "my_header.h" #line 42 MY_HEADER_NAME // 这会使得编译器在处理这个指令后的代码时,错误和警告信息显示为 "my_header.h" 文件的第 42 行。注意事项
#error指令通常用于确保代码在特定条件下不会编译,这对于防止在不支持的环境下编译代码非常有用。#pragma指令是编译器特定的,不是所有编译器都支持相同的#pragma指令。在使用时,需要查阅相应编译器的文档。#line指令可以用于调试目的,提供更清晰的错误报告,或者在生成代码时调整行号信息。
XIII offsetof 宏的实现
- 声明在
<stddef.h>头文件中 offsetof的作用: 用于计算结构体成员相对于结构体起始地址的偏移量
宏定义:
offsetof宏的原型如下:#define offsetof(type, member) ((size_t)((char *)&(((type *)0)->member) - (char *)0))参数解释:
type:结构体类型member:结构体中的成员名称使用示例:
#include <stddef.h> struct S { char c1; int i; char c2; }; int main() { struct S s = { 0 }; printf("%d\n", offsetof(struct S, c1));//0 printf("%d\n", offsetof(struct S, i ));//4 printf("%d\n", offsetof(struct S, c2));//8 return 0; }
offsetof宏的实现:
#define OFFSETOF(type,member) ((size_t)&(((type*)0)->member))
(type*)0:在0地址处(0x00000000)开始存放一个type类型的结构体&(((type*)0)->member):取出该结构体中成员member的地址


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









