







文章目录
Transformer概述
Transformer是基于自注意机制(self-attention)的神经网络模型。其经常用于来处理时序数据。我们知道还有另外的常用的两类深度神经网络模型循环神经网络(RNN)和卷积神经网络(CNN)。那么对于Transformer而言,其相较于另外两种的优势在哪呢?
- 其使用自注意机制,可同时并行处理时序数据,计算他们之间的相关性
- 并且其输入时引入了位置编码来保留的序列的相关信息
- 因为其可并行处理,所以训练速度可以很快
其结构如下图所示,其特性正是由其结构所决定的,所以接下来带你逐步分析逐层结构。
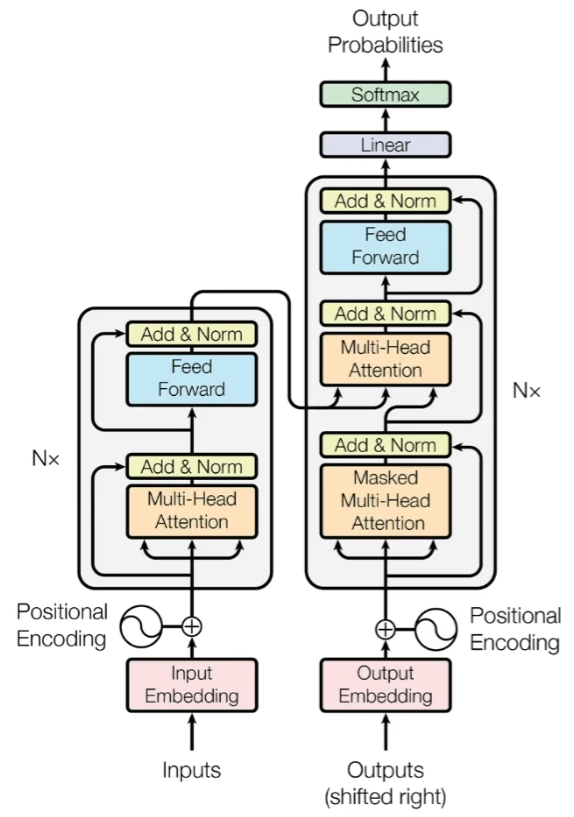
分模块解析Transformer
模型的输入输出
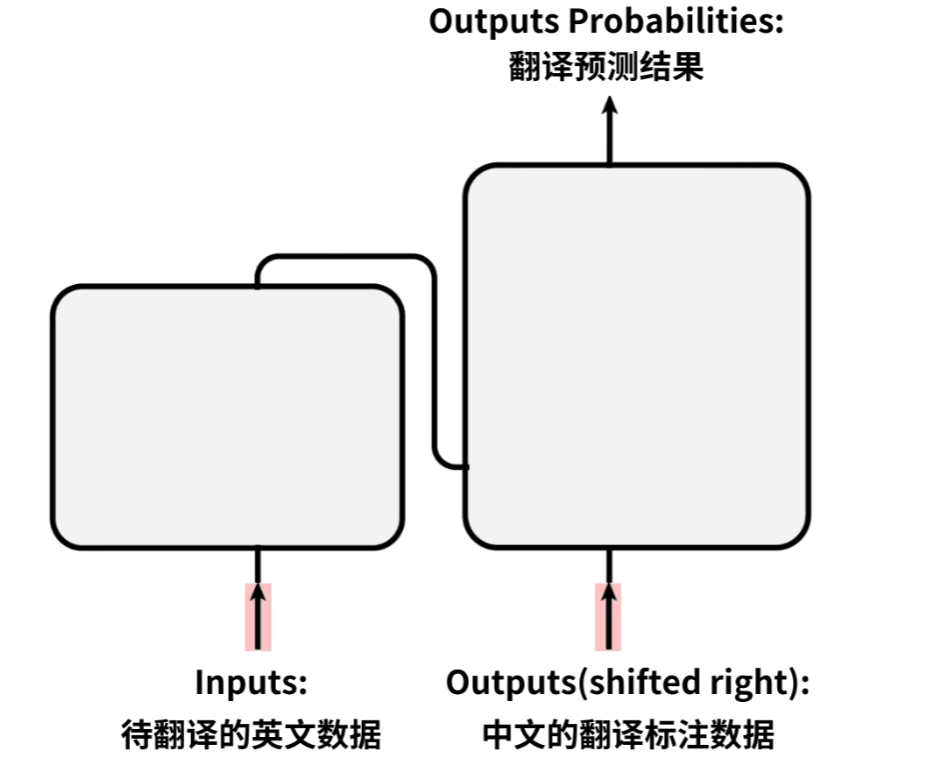
首先来看输入输出部分,从结构图也很容易看出来,输入有两个,输出一个。那我们以机器翻译为例,左部分输入(Inputs)为需要待翻译的英文数据,右边输入(Outputs(shifted right))为中文的翻译标注数据,那么最终的输出(Outputs Probabilities)即为翻译预测的结果。
其输入首先会经过模型的词向量层进行处理,简单来说就是单词的序列会被转换为单词向量的序列。但是如果仅仅就是这样的序列输入到模型中,会出现一个很大的问题,因为模型是并行处理的,对于这样的输入数据,模型是无法知道其位置如何的,比如我们输入的是Are you ok?但是模型可能会以为是You are ok?或者是Ok? Are you那么对于这样的情况应该怎么处理呢?所以Transformer引入了位置编制加入其位置信息。

位置编码(Positional Encoding)
我们现在知道了其引入位置编码的目的就是为了将其位置信息附加到原始的信息上面,其实现是通过正弦函数和余弦函数的计算来实现的。
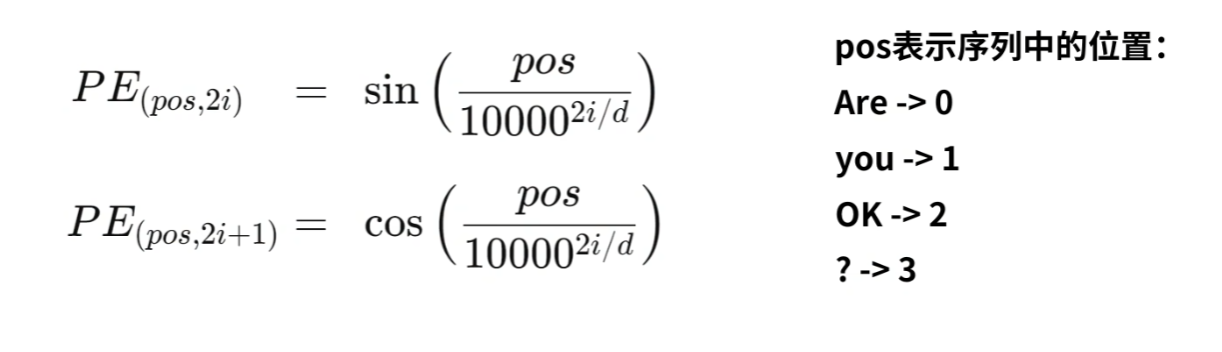
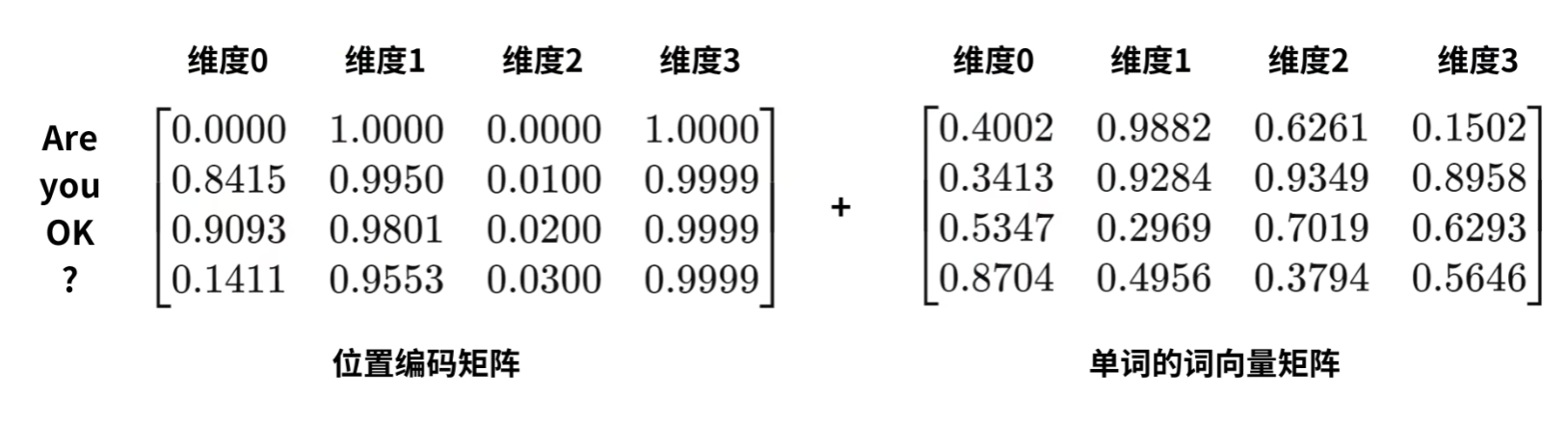
具体就是pos代表着在序列中的位置,2i和2i+1怎么理解呢,我们就可以将其看为偶数维度和奇数维度,即对于Are而言PE(0,0),PE(0,2)使用正弦计算其位置信息,PE(0,1),PE(0,3)则使用余弦计算其位置信息。其中d代表了总的维度。故其最终的输入信息为加入了位置信息的编码,如下所示:
编码器解码器结构(Encoder-Decoder)
经过位置编码后的数据则会被输入到Encoder-Decoder结构中,其中N代表了有多个Encoder和Decoder,论文中的N为6.其总共有三个计算过程。
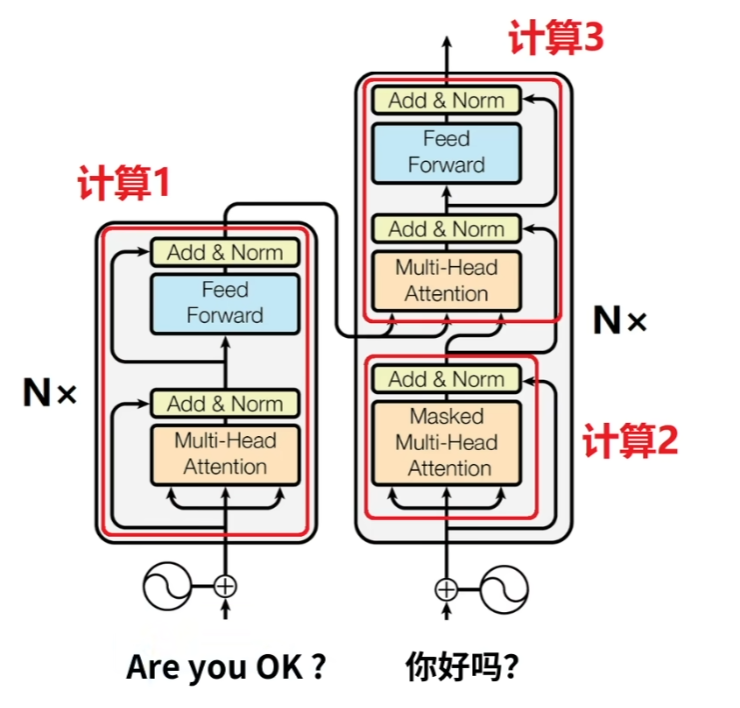
- 计算过程1
待翻译的英文数据经过编码输入后会首先进入其编码器(Encoder),经过多头自注意力机制(Muti-Head Attention),在经过残差连接和归一化层。这里注意下,这里使用的是层归一化(LN),那么为什么不使用批归一化(BN)?因为BN是通过将一个批次的同一维度进行归一化,用其均值方差,代表整个数据的均值方差,那么对于处理不同长度的时序数据就会出现问题,可能有些序列特别长,那么部分维度的数据可能就会特别少,这就会导致其数据太少,噪音过大,不能够正确的代表整个数据的均值方差。然后在经过前馈网络和残差归一化得到最后的编码输出。
- 计算过程2
其实与计算过程1相类似,只不过这里使用的是掩码多头注意力机制(Masked Multi-Head Attention),其与多头自注意力机制(Muti-Head Attention)区别就在于加入了掩码,掩盖了后续的信息。这么做的原因就在于,我们真实预测的时候,是无法知道后续的信息的,我们只能根据我们已有的信息和已经推断出来的信息去推测下一个可能的预测。
- 计算过程3
经过计算1和计算2得出的编码信息会一同进入第三个计算过程进行解码,得到最后的预测结果输出。
多头注意力机制(Muti-Head-Attention)
前文说了很多遍的多头自注意力机制(Muti-Head Attention)了,那么其到底是如何运行的呢?其具体的结构如下图
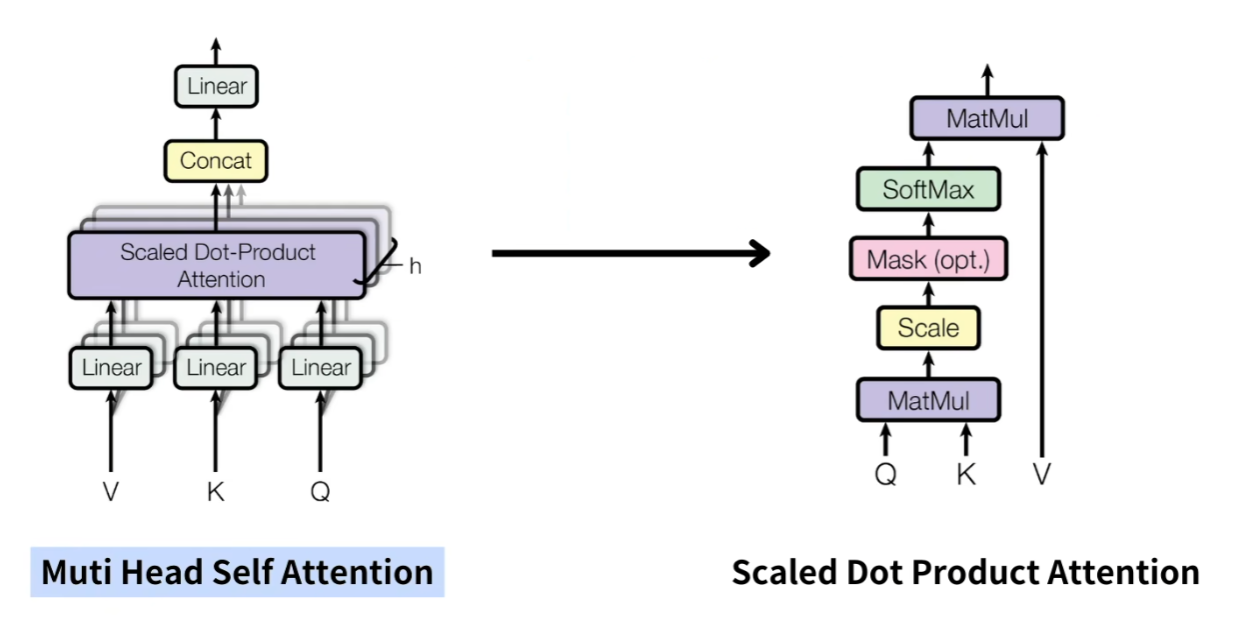
其就是通过Q、K、V三个线性层对输入数据进行特征变换,在通过注意力机制对其进行融合,多头的意思即有多个自注意机制层。最后将所有自注意机制层的结果进行合并,通过线性层得到最终的输出。(这里我并未详细说明什么是注意力机制,大家其就可以简单的理解其为一个线性处理即可)
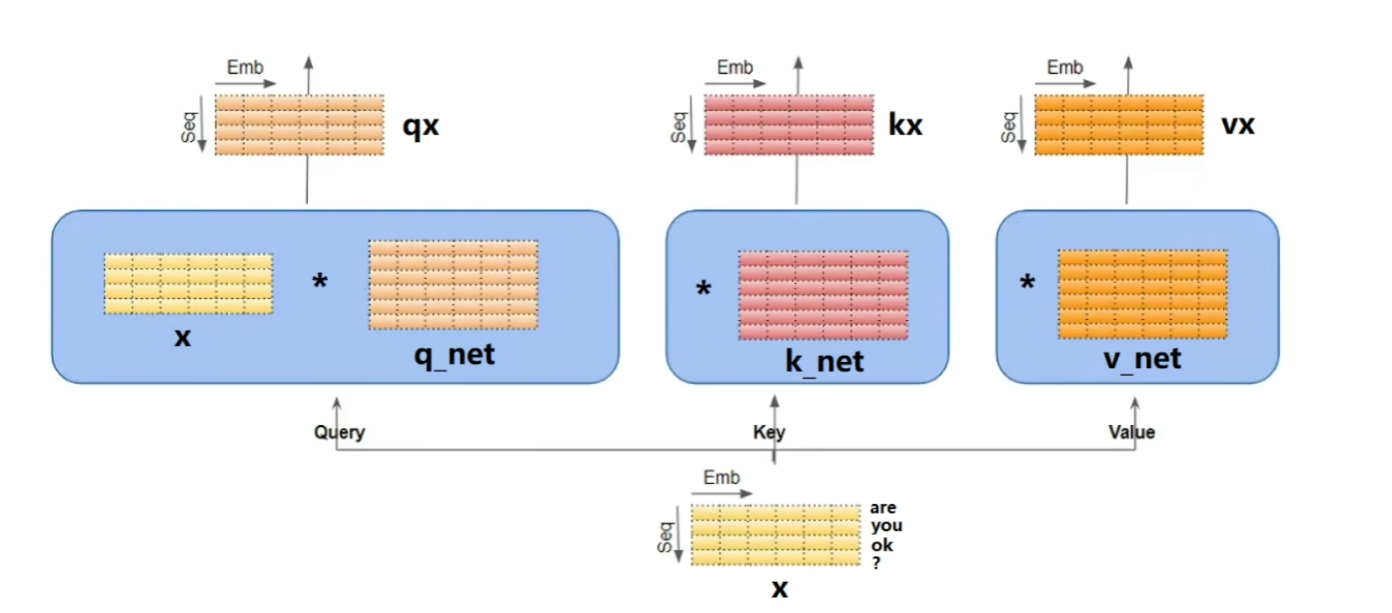
具体的计算过程如下,经过编码后的输入x会与Q、K、V三个线性层进行处理得到Qx,Kx,Vx三个不同的编码信息,然后我们通过注意力机制进行融合。
其公式为。简单理解就是对于Q、K、V三组信息,进行选择与融合,从而得到最终的注意力机制结果。
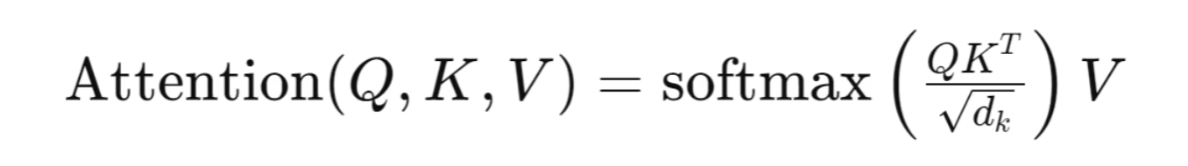
看到这里相信你已经对于Transformer的结构已经有了很深入的了解了,但是这仅仅就是理论的基础,后续将会给大家更新如何搭建自己的transformer去处理相关的问题。
参考资料:

















 32
32

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









