






目录
机器学习:利用经验改善自身的性能,将经验转化为数据
随着该领域的发展,目前主要研究智能数据分析的理论和方法,并已成为智能数据分析技术的源泉之一
1 基本术语
1) 模型
模型这一词语将会贯穿整个教程的始末,它是机器学习中的核心概念。你可以把它看做一个“魔法盒”,你向它许愿(输入数据),它就会帮你实现愿望(输出预测结果)。整个机器学习的过程都将围绕模型展开,训练出一个最优质的“魔法盒”,它可以尽量精准的实现你许的“愿望”,这就是机器学习的目标。
2) 数据集
数据集,从字面意思很容易理解,它表示一个承载数据的集合,如果说“模型”是“魔法盒”的话,那么数据集就是负责给它充能的“能量电池”,简单地说,如果缺少了数据集,那么模型就没有存在的意义了。数据集可划分为“训练集”和“测试集”,它们分别在机器学习的“训练阶段”和“预测输出阶段”起着重要的作用。
3) 样本&特征
样本指的是数据集中的数据,一条数据被称为“一个样本”,通常情况下,样本会包含多个特征值用来描述数据,比如现在有一组描述人形态的数据“180 70 25”如果单看数据你会非常茫然,但是用“特征”描述后就会变得容易理解
4) 向量
任何一门算法都会涉及到许多数学上的术语或者公式。在本教程写作的过程中也会涉及到很多数学公式,以及专业的术语,在这里我们先对常用的基本术语做一下简单讲解。
第一个常用术语就是“向量”,向量是机器学习的关键术语。向量在线性代数中有着严格的定义。向量也称欧几里得向量、几何向量、矢量,指具有大小和方向的量。您可以形象地把它的理解为带箭头的线段。箭头所指:代表向量的方向;线段长度:代表向量的大小。与向量对应的量叫做数量(物理学中称标量),数量只有大小,没有方向。
在机器学习中,模型算法的运算均基于线性代数运算法则,比如行列式、矩阵运算、线性方程等等。其实对于这些运算法则学习起来并不难,它们都有着一定运算规则,只需套用即可,因此你也不必彷徨,可参考向量运算法则。向量的计算可采用 NmuPy 来实现,如下所示:
import numpy as np
#构建向量数组
a=np.array([-1,2])
b=np.array([3,-1])
#加法
a_b=a+b
#数乘
a2=a*2
b3=b*(-3)
#减法
b_a=a-b
print(a_b,a2,b3,b_a)
5)监督学习 (Supervised Learning)
解释:在监督学习中,模型从带有标签的数据集中学习,这些标签是数据的正确答案或分类。模型通过比较其预测与真实标签来学习如何做出更好的预测。
6)无监督学习 (Unsupervised Learning)
解释:无监督学习涉及在没有标签的数据上训练模型,模型的任务是发现数据中的内在结构或模式,例如聚类或降维。
2 假设空间
科学推理的两大基本手段:归纳(induction)与演绎(deduction)
前者是从特殊到一般的“泛化”(generalization)过程,即从具体的事实归结出一般性规律;
后者则是从一般到特殊的“特化”(specialization)过程,即从基础原理推演出具体状况.
归纳学习有狭义与广义之分,广义的归纳学习大体相当于从样例中学习,而狭义的归纳学习则要求从训练数据中学得概念(concept),因此亦称为“概念学习”或“概念形成”.
概念学习中最基本的是布尔概念学习,即对“是”“不是”这样的可表示为0/1布尔值的目标概念的学习.
我们可以把学习过程看作一个在所有假设(hypothesis)组成的空间中进行搜索的过程,搜索目标是找到与训练集“匹配”(fit)的假设,即能够将训练集中的瓜判断正确的假设.假设的表示一旦确定,假设空间及其规模大小就确定了.
可以有许多策略对这个假设空间进行搜索,例如自顶向下、从一般到特殊,或是自底向上、从特殊到一般,搜索过程中可以不断删除与正例不一致的假设、和(或)与反例一致的假设.最终将会获得与训练集一致(即对所有训练样本能够进行正确判断)的假设,这就是我们学得的结果.
需注意的是,现实问题中我们常面临很大的假设空间,但学习过程是基于有限样本训练集进行的,因此,可能有多个假设与训练集一致,即存在着一个与训练集一致的“假设集合”,我们称之为“版本空间”(version space)
3 归纳偏好
任何一个有效的机器学习算法必有其归纳偏好,否则它将被假设空间中看似在训练集上“等效”的假设所迷惑,而无法产生确定的学习结果.可以想象,如果没有偏好,我们的西瓜学习算法产生的模型每次在进行预测时随机抽选训练集上的等效假设,那么对这个新瓜“(色泽=青绿;根蒂=蜷缩;敲声=沉闷)”,学得模型时而告诉我们它是好的、时而告诉我们它是不好的,这样的学习结果显然没有意义.
下图中有算法A和算法B,哪么哪个算法更好呢?
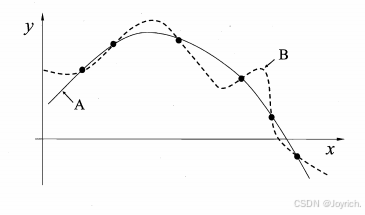
这时候就可以用到奥卡姆剃刀,选择一个更简单(平滑)的曲线,也就是A曲线。
奥卡姆剃刀”(Occam's razor):一种常用的、自然科学研究中最基本的原则,即“若有多个假设与观察一致,则选最简单的那个”.如果采用这个原则,并且假设我们认为“更平滑”意味着“更简单”
但在很多时候,什么算法是更简单,这个是很难界定的。
事实上,归纳偏好对应了学习算法本身所做出的关于“什么样的模型更好”的假设.在具体的现实问题中,这个假设是否成立,即算法的归纳偏好是否与问题本身匹配,大多数时候直接决定了算法能否取得好的性能.
NFL定理:一个算法若在某些问题上比另一个算法
好,必存在另一些问题
比
好

在图(a)中A优于B,但在图(B)中B优于A。
NFL定理的重要前提:
- 所有“问题”出现的机会相同、或所有问题同等重要
- 实际情形并非如此;我们通常只关注自己正在试图解决的问题
- 脱离具体问题,空泛地谈论“什么学习算法更好”毫无意义!


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









