






目录
1模式和模式类
第十二章 目标识别
在界定数字图像处理的覆盖范围时,包含了图像中各个区域的识别,这些区域称为目标或模式。
| 模式识别方法 | 使用的描绘子 |
| 决策理论方法 | 定量描绘子,如长度、面积、纹理 |
| 结构方法 | 定性描绘子,如关系描绘子 |
模式是描绘子的组合
由机器完成的模式识别是对不同的模式赋予不同类别的技术
实践中常用的三种模式组合是向量(用于定量描述)、串和树(用于结构描述)。
模式向量以列向量(即n×1阶矩阵)的形式表示,如:
表示模式向量x,其中每个分量xi表示第i个描绘子,n是与该模式有关的描绘子的总数。
描述的模式向量不同,不仅体现在不同的类之间,也体现在一个类的内部,类的可分程度很大程度上取决于所用的描绘子的选择,描述子对基于模式向量方法的目标识别的最终性能会有深刻的影响。
模式向量x中的各个分量的性质,取决于用于描述该物理模式本身的方法。
串描述适用于生成其结构是基于基元的较简单的连接,并且通常是和边界形状有关系的目标模式和其他实体模式
树常用于层次排序,树的根表示整幅图像,不断细分,直到达到我们在图像上解析不同区域的能力的极限为止。
2基于决策理论方法的识别
决策理论方法识别是以使用决策(或判别)函数为基础的。令x=表示一个n维模式向量。对于W个模式类
决策理论模式识别的基本问题是依据下属性来找到W个决策函数
如果模式x属于类
,则
将x带入所有决策函数后,如果(x)得到最大值,则称位置模式x属于第i个模式类。
从中分离出类
的决策边界,由满足
的x值给出,对于模式类
有
,而对于模式类
有
2.1匹配
基于匹配的识别技术通过一个原型模式向量来表示每个类。
最小距离分类器
定义:根据一种预先定义的度量,将一个未知模式赋予最接近的类。
最小距离分类器由每个类的均值向量来确定:
最小距离等同于计算函数:
![]()
对于一个最小的距离分类器,类和
之间的决策边界为:
决策面是连接和
的线段的垂直等分线
相关匹配
空间相关通过相关定理与函数的变换相联系:
![]()
归一化相关系数:
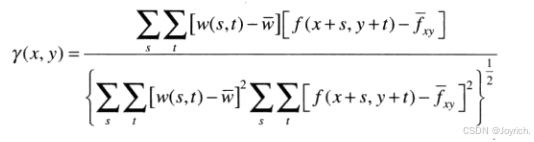
通常我们将w称为模板,将相关称为模板匹配。
通过移动该模板的中心(即增大x和y),以便w的中心访问f中的每个像素,可得到所有的相关系数y(x, y)。寻找y(x, y )中的最大值,从而找到最好匹配的位置。如果y(x, y)中有多个位置出现最大值,表明w和f之间有多个匹配。
2.2最佳统计分类器
在平均意义上有可能推导出一种最佳分类方法,用该方法会产生最低的错误分类的概率。
基础知识
令分类器导致的损失记为Lij。
则平均损失为:
通常称为"条件平均风险或损失"。
可以将该式简化为:
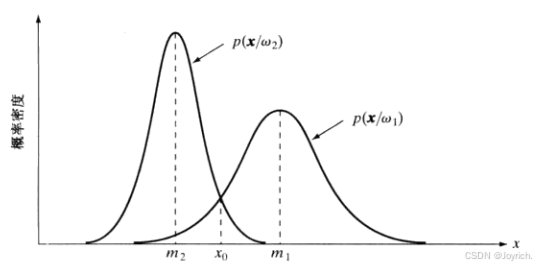
高斯模式的贝叶斯分类器
将总体平均损失降至最低的分类器称为贝叶斯分类器。
由每个类的均值向量和协方差矩阵决定
贝叶斯决策函数:
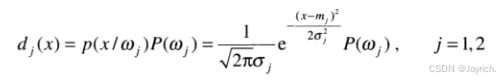
在n维情形下,第j个模式类的向量的高斯密度为:
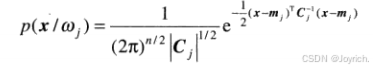
2.3神经网络
训练模式:用于估计参数(已知其所属的类)的模式
训练集:来自每个类的一组模式
学习或训练:使用训练集得到决策函数的过程
两个模式的感知机
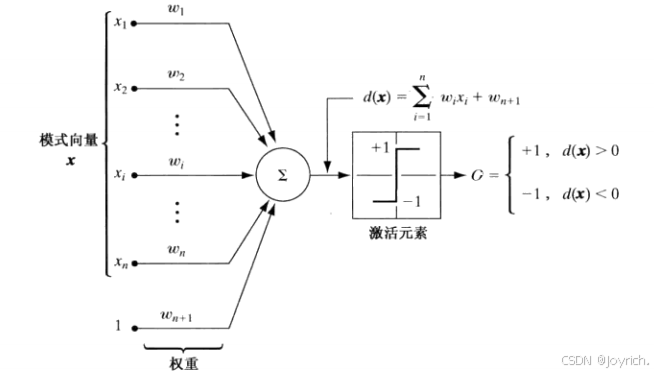
在这种最基本的形式中,感知机学习一个线性决策函数,该决策函数对分两个线性可分的训练集。显示了两个模式类的感知机模型。这个基本装置的响应基于其输入的加权和,即
这是一个与模式向量的分量有关的线性决策函数。称为权重的系数w,i = 1, 2,…, n,n+1在对输入求和前,对这些输人进行修正,并馈送到阈值单元中。在这一意义上,权重类似于人类神经系统中的神经突触。将求和连接的输出映射为该装置的最终输出的函数,有时称为激活函数。
当d(x)>0时,阈值单元使感知机的输出为+1,这表明模式r被识别为属于类o,。当d(x)<0时,情形正好相反。这种操作模式与之前的注释为两个类使用单个决策函数是一致的。当d(x)=0时,x位于分隔两个模式类的决策面上,这给出了一个不能确定的条件。由感知机实现的决策边界是通过d(x)等于零得到的:
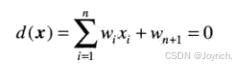
图2.3中阈值单元的输出取决于d(x)的符号。替代测试整个函数来确定它是正还是负,我们可以对w.,此时系统的输出是
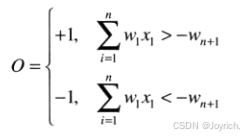
训练算法
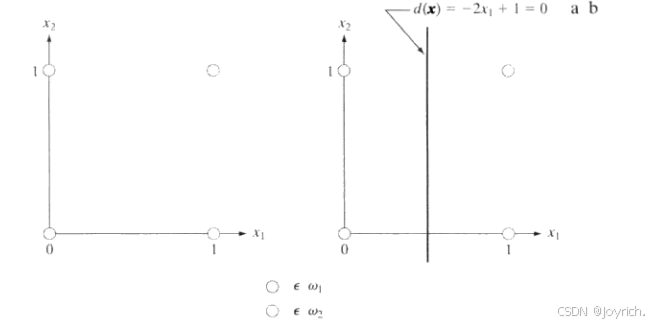
线性可分的类:用于求两个线性可分训练集的权重向量解的一种简单迭代算法如下。
该算法仅当正被考虑的模式在训练序列第k步被错误分类时,才改变w。假设修正增量c为正,现在它是一个常量。该算法有时称为固定增量校正准则。
当两个类的整个训练集循环通过机器而不出现任何错误时,该算法收敛。如果模式的两个训练集是线性可分的,那么固定增量校正准则会在有限步内收敛。称为感知机训练定理的该结果的证明,
不可分的类: 实际上,线性可分的模式类是个例外,通常情况并非如此。随着神经网络训练方面取得进展,解决不可分行为的许多方法已成为仅具有历史意义的课题。然而,一种早期的方法与该讨论直接相关,这就是原始的delta规则。称为感知机训练的Widrow-Hoff或最小均方(LMS)delta规则,该规则在任何训练步骤都使得在实际响应与期望响应间的误差最小。
考虑准则函数:
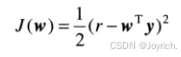
多层前馈神经网络
基本结构:它由多层结构上相同的计算节点(神经元)排列而成,从而一层中的每个神经元的输出送到下一层的每个神经元的输入。称为层 A 的第--层中的神经元的个数为N。通常,N。= n,它是输入模式向量的维度。称为0层的输出层中的神经元的数量表示为。
等于w,即神经网络经训练后用于识别模式类的数量。如下面的讨论所示,如果该网络的第i个输出为“高”,而其他输出为“低”,则网络将模式向量x识别为属于类
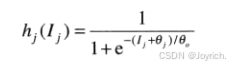
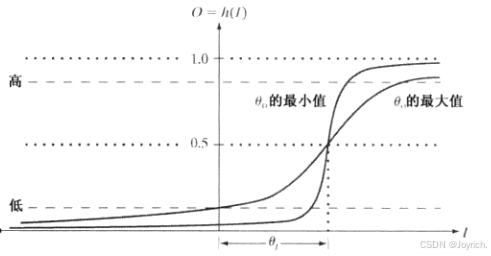
“S形”激活函数总为正,并且仅当激活元素的输入分别为负无穷或正无穷时,它才到达极限值0和1
3结构方法
在这一节,我们学习两种基本串表示的边界开关的识别方法,串是结构模式识别中最实用的方法
3.1匹配形状数
两个区域边界(形状)之间的相似度k定义为它们的形状数仍保持一致的最大阶。令a和b代表由4方向链码表示的团合边界的形状数。
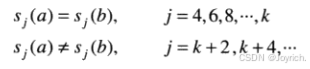
两个形状a和b之间的距离定义为他们相似度的倒数
该距离满足如下性质:
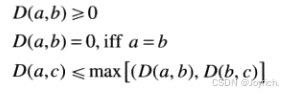
如果使用相似度,则k越大,形状就越相似
如果使用距离度量,则k越小,形状越相似
3.2串匹配
假设两个区域边界a和b已被编码成串,α表示两个串之间的匹配数,不匹配的符号数为
a和b之间的一种简单的相似性度量时比率R,
完美匹配时R无限大,而当a和b中没有任何符号匹配时,无任何符号匹配时R=0


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









