






使用ER模式建立的数仓,优点是没有冗余的数据。缺点是:数仓是用于分析的,分析的数据量特别大,多个表需要join操作,运行的时候特别慢。
比如:统计哪一年,哪个国家的哪个品类卖的最好?
此时就需要join 12张表,数据量特别大的情况下就是灾难。
所以ER模式-- mysql等关系型数据库依然在用。
hive等用于分析的工具不用了,数据量大不便于分析
因为ER模型用不了,所以有大师提出了另一种模型-----维度建模法
下图为一个典型的维度模型,其中位于中心的SalesOrder为事实表,其中保存的是下单这个业务过程的所有记录。位于周围每张表都是维度表,包括Date(日期),Customer(顾客),Product(产品),Location(地区)等,这些维度表就组成了每个订单发生时所处的环境,即何人、何时、在何地下单了何种产品。从图中可以看出,模型相对清晰、简洁。
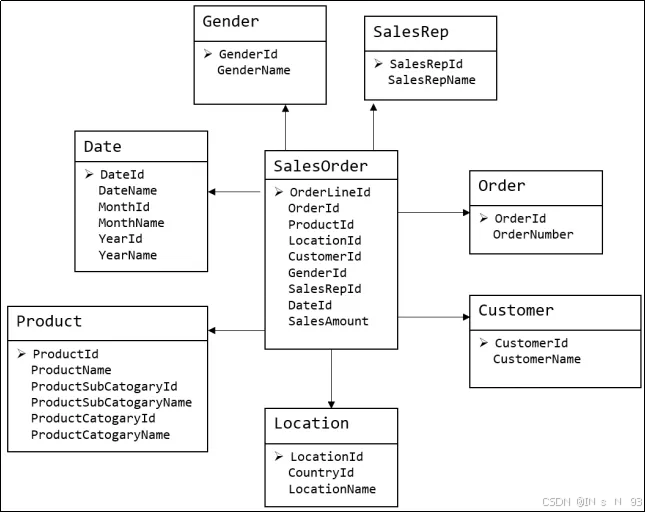
维度越多,用于统计的指标就越丰富。
维度建模以数据分析作为出发点,为数据分析服务,因此它关注的重点是用户如何更快的完成需求分析以及如何实现较好的进行大规模复杂查询的响应性能。
所以,目前来讲,维度建模法,是最流行的。各大公司都用的是维度建模法。
维度建模的过程:
第一步 选取业务处理:
业务处理过程是组织机构中进行的一般都由源系统提供支持的 [自然业务活动]。
要记住的重要一点是,这里谈到的业务处理过程并不是指业务部门或者职能。
第二步 定义粒度
粒度定义意味着对各事实表行实际代表的内容给出明确的说明。
粒度传递了同事实表度量值相联系的细节所达到的程度方面的信息。它给出了后面这个问题的答案:“如何描述事实表的单个行?”。
粒度定义是不容轻视的至关重要的步骤。 在定义粒度时应优先考虑为业务处理获取最有原子性的信息而开发维度模型。
原子型数据是所收集的最详细的信息,是高维度结构化的。
度量值越细微并具有原子性,就越能够确切地知道更多的事情。
原子型数据可为分析方面提供最大限度的灵活性,维度模型的细节性数据是稳如泰山的,并随时准备接受业务用户的特殊攻击。
第三步 选定维度
维度所引出的问题是,“业务人员将如何描述从业务处理过程得到的数据?”
应该用一组在每个度量上下文中取单一值而代表了所有可能情况的丰富描述,将事实表装扮起来。
常见维度的例子包括日期、产品、客户、账户和机构等。
第四步 确定事实(度量指标)
事实的确定可以通过回答“要对什么内容进行评测”这个问题来进行。
1、针对某个特定的行为动作,建立一个以行为活动最小单元为粒度的事实表。
2、针对某个实体对象在当前时间上的状况。我们通过对这个实体对象在不同阶段存储它的快照。
3、针对业务活动中的重要分析和跟踪对象,统计在整个企业不同业务活动中的发生情况。
维度表的设计:
相比较范式(关系型)建模、维度建模更粗暴。
星型模型、雪花模型、星座模型
规范化与反规范化:
规范化是指使用一系列范式设计数据库的过程,其目的是减少数据冗余,增强数据的一致性。通常情况下,规范化之后,一张表的字段会拆分到多张表。
(通过之前的几大范式设计出来的表就叫做规范化的表)
反规范化是指将多张表的数据冗余到一张表,其目的是减少join操作,提高查询性能。
在设计维度表时
如果对其进行规范化,得到的维度模型称为雪花模型,
如果对其进行反规范化,得到的模型称为星型模型。
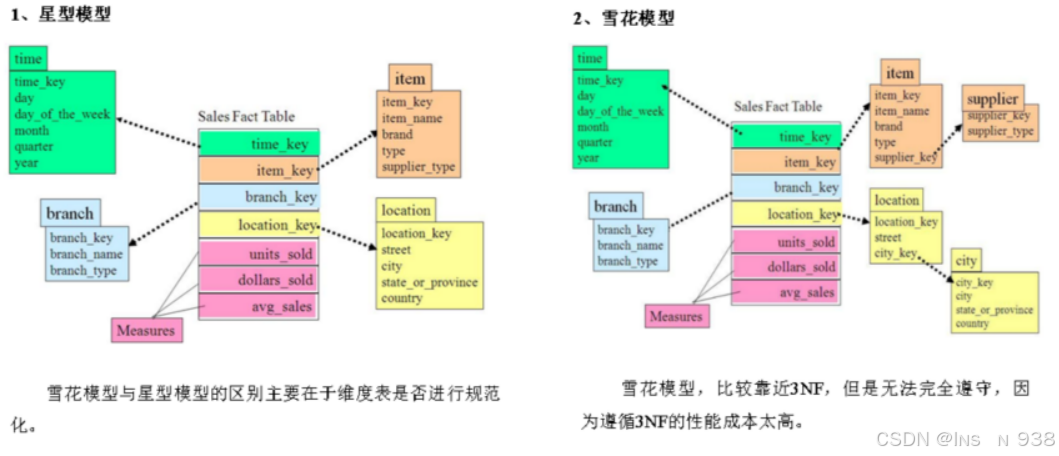
数据仓库系统的主要目的是用于数据分析和统计,所以是否方便用户进行统计分析决定了模型的优劣。采用雪花模型,用户在统计分析的过程中需要大量的关联操作,使用复杂度高,同时查询性能很差,而采用星型模型,则方便、易用且性能好。所以出于易用性和性能的考虑,维度表一般是很不规范化的。

维度建模:事实表
事实表作为数据仓库维度建模的核心,紧紧围绕着业务过程来设计。其包含与该业务过程有关的维度引用(维度表外键)以及该业务过程的度量(通常是可累加的数字类型字段)。
事实表特点
事实表通常比较“细长”,即列较少,但行较多,且行的增速快。
比如:订单表,数据每天都有人下订单(每时每刻),列最多也就十几个。
1、事务型事实表(用的最多)
事务事实表用来记录各个业务过程,它保存的是各个业务中的原子操作事件,即最细粒度的操作事件
事务型事实表可以用于分析与各个业务过程相关的各项统计指标,因为其中保存的是最细粒度的记录,提供了最大限度的灵活性,可以支持无法预期的各种细节层次的统计需求
比如一个表中存放的都是一个人每年的消费情况,他就无法统计 某一年某一月的消费情况。
设计流程:
设计事务事实表时一般可遵循以下四个步骤:
选择业务过程→声明粒度→确认维度→确认事实
1)选择业务过程
在业务系统中,挑选我们感兴趣(即将要统计的)的业务过程,业务过程(加入购物车)可以概括为一个个不可拆分的行为事件,例如电商交易中的下单,取消订单,付款,退单等,都是业务过程。通常情况下,一个业务过程对应一张事务型事实表
2)声明粒度
业务过程确定后,需要为每个业务过程声明粒度。即精确定义每张事务型事实表的每行数据表示什么,应该尽可能选择最细粒度,以此来应各种细节程度的需求
3)确定维度
确定维度具体是指,确定与每张事务型事实表相关的维度有哪些。
确定维度时应尽量多的选择与业务过程相关的环境信息。因为维度的丰富程度就决定了维度模型能够支持的指标丰富程度。
4)确定事实
此处的“事实”一词,指的是每个业务过程的度量值(通常是可累加的数字类型的值,例如:次数、个数、件数、金额等)。
经过上述四个步骤,事务型事实表就基本设计完成了。第一步选择业务过程可以确定有哪些事务型事实表,第二步可以确定每张事务型事实表的每行数据是什么,第三步可以确定每张事务型事实表的维度外键,第四步可以确定每张事务型事实表的度量值字段。
2、周期型快照事实表
周期快照事实表以具有规律性的、可预见的时间间隔来记录事实,主要用于分析一些存量型(例如商品库存,账户余额)或者状态型(空气温度,行驶速度)指标。
设计流程
1)确定粒度
周期型快照事实表的粒度可由采样周期和维度描述,故确定采样周期和维度后即可确定粒度。
采样周期通常选择每日。
维度可根据统计指标决定,例如指标为统计每个仓库中每种商品的库存,则可确定维度为仓库和商品。
2)确认事实
事实也可根据统计指标决定,例如指标为统计每个仓库中每种商品的库存,则事实为商品库存
3、累计(积)型快照事实表
累计快照事实表是基于一个业务流程中的多个关键业务过程联合处理而构建的事实表,如交易流程中的下单、支付、发货、确认收货业务过程。
累积型快照事实表通常具有多个日期字段,每个日期对应业务流程中的一个关键业务过程(里程碑)。
累积型快照事实表主要用于分析业务过程(里程碑)之间的时间间隔等需求。例如前文提到的用户下单到支付的平均时间间隔,使用累积型快照事实表进行统计,就能避免两个事务事实表的关联操作,从而变得十分简单高效。
设计流程
累积型快照事实表的设计流程同事务型事实表类似,也可采用以下四个步骤,下面重点描述与事务型事实表的不同之处。
选择业务过程→声明粒度→确认维度→确认事实。
1)选择业务过程
选择一个业务流程中需要关联分析的多个关键业务过程,多个业务过程对应一张累积型快照事实表。
回顾:一个业务过程对应一张事务型事实表
2)声明粒度
精确定义每行数据表示的是什么,尽量选择最小粒度。
3)确认维度
选择与各业务过程相关的维度,需要注意的是,每个业务过程均需要一个日期维度。
4)确认事实
选择各业务过程的度量值。

















 4万+
4万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









