







联合索引 abc 在等值条件过滤 abc 与 a 的性能差异
场景:表 t1 建立联合索引 (a, b, c),where a = ? and b = ? and c = ? 和 where a = ? 两者之间为什么有性能的差距。
理论分析
从理论上来说(不考虑其它的特殊情况,比如由于数据量或频繁回表等原因导致的优化器不使用索引过滤),这两条查询都会走联合索引 (a, b, c)。
🤔 前者比后者多了什么?
其实很好想到,where a = ? and b = ? and c = ? 相较于 where a = ? 多了两重的条件过滤。
🤔 多了两重的条件过滤可以做什么?
其实也很好想到,可以多过滤掉一些数据。
🤔 那什么时候两者会出现明显的性能差距呢?
其实也非常好想到:
- 如果 a 字段的索引区分度不高,那么
where a = ?就无法过滤掉大部分数据,特别是如果需要回表查询时,由于过滤后剩余索引记录还很多,导致了大量的回表查询,而一次回表查询就是一次随机 I/O。 - 再来点反差,如果 a 字段的索引区分度不高,但 b、c 字段的索引区分度很高,那么
where a = ? and b = ? and c = ?这个查询语句,即使 a 没办法过滤掉大部分数据,但 b、c 可以啊,这可以使过滤后剩余索引记录比较少,仅需少量的回表查询即可。
环境准备
为了验证上述结论,我们做一个实验:表 t1 建立联合索引 (a、b、c),实际记录中,a 字段的索引区分度不高,但 b、c 字段的索引区分度很高,共 100W 条记录。
DROP TABLE IF EXISTS t1;
CREATE TABLE t1 (
id INT AUTO_INCREMENT PRIMARY KEY,
`name` VARCHAR(255) NOT NULL DEFAULT '',
a INT NOT NULL,
b INT NOT NULL,
c INT NOT NULL,
INDEX idx_a_b_c(a, b, c)
);
DROP PROCEDURE IF EXISTS GenerateTestData;
DELIMITER $$
CREATE PROCEDURE GenerateTestData()
BEGIN
DECLARE i INT DEFAULT 0;
DECLARE batch_size INT DEFAULT 1000; -- 每批次插入量
DECLARE total_rows INT DEFAULT 1000000; -- 总数据量
DECLARE commit_counter INT DEFAULT 0;
SET autocommit = 0; -- 关闭自动提交以提升性能
WHILE i < total_rows DO
START TRANSACTION; -- 单批次插入数据
WHILE commit_counter < batch_size AND i < total_rows DO
INSERT INTO t1 (`name`, a, b, c)
VALUES (
CONCAT('User-', UUID()), -- 随机生成 name
FLOOR(RAND() * 5) + 1, -- a 的区分度低(1~5)
FLOOR(RAND() * 10000) + 1, -- b 区分度高(1~10000)
FLOOR(RAND() * 10000) + 1 -- c 区分度高(1~10000)
);
SET i = i + 1;
SET commit_counter = commit_counter + 1;
END WHILE;
COMMIT;
SET commit_counter = 0;
END WHILE;
SET autocommit = 1; -- 恢复自动提交
END$$
DELIMITER ;
CALL GenerateTestData();
调用存储过程:
CALL GenerateTestData();
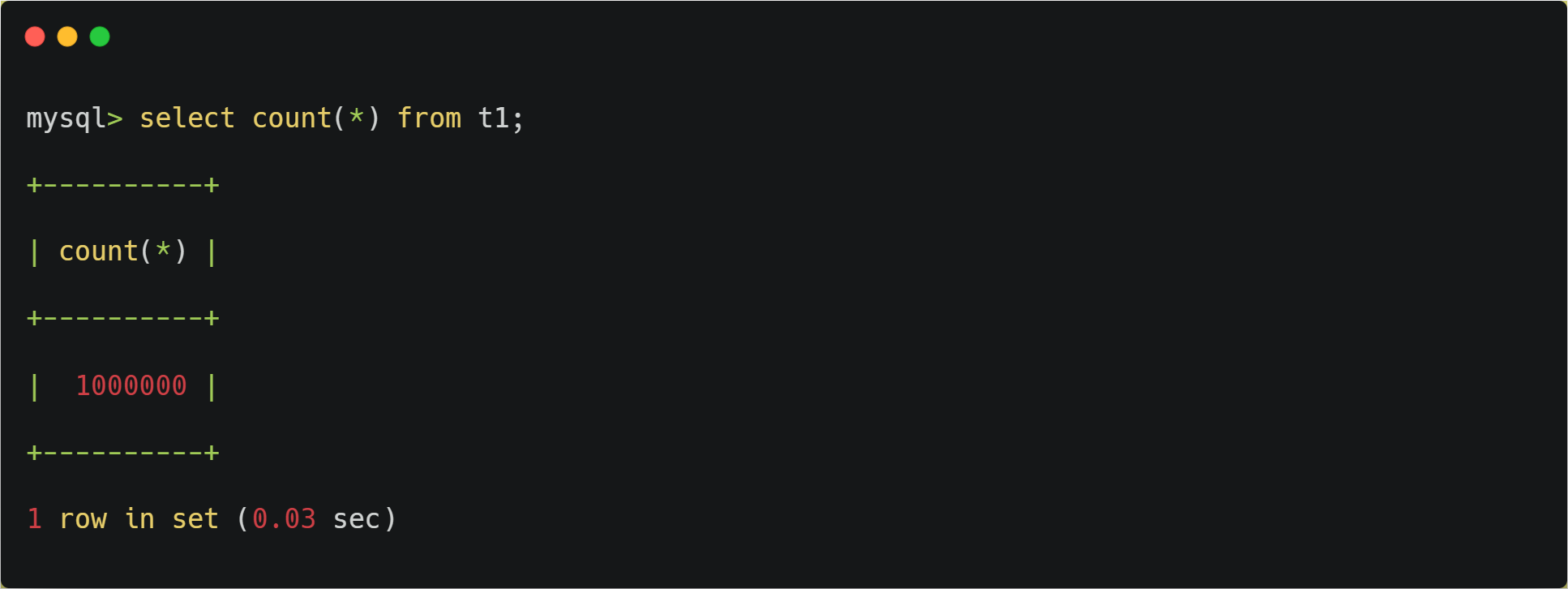
验证数据量:
select count(*) from t1;
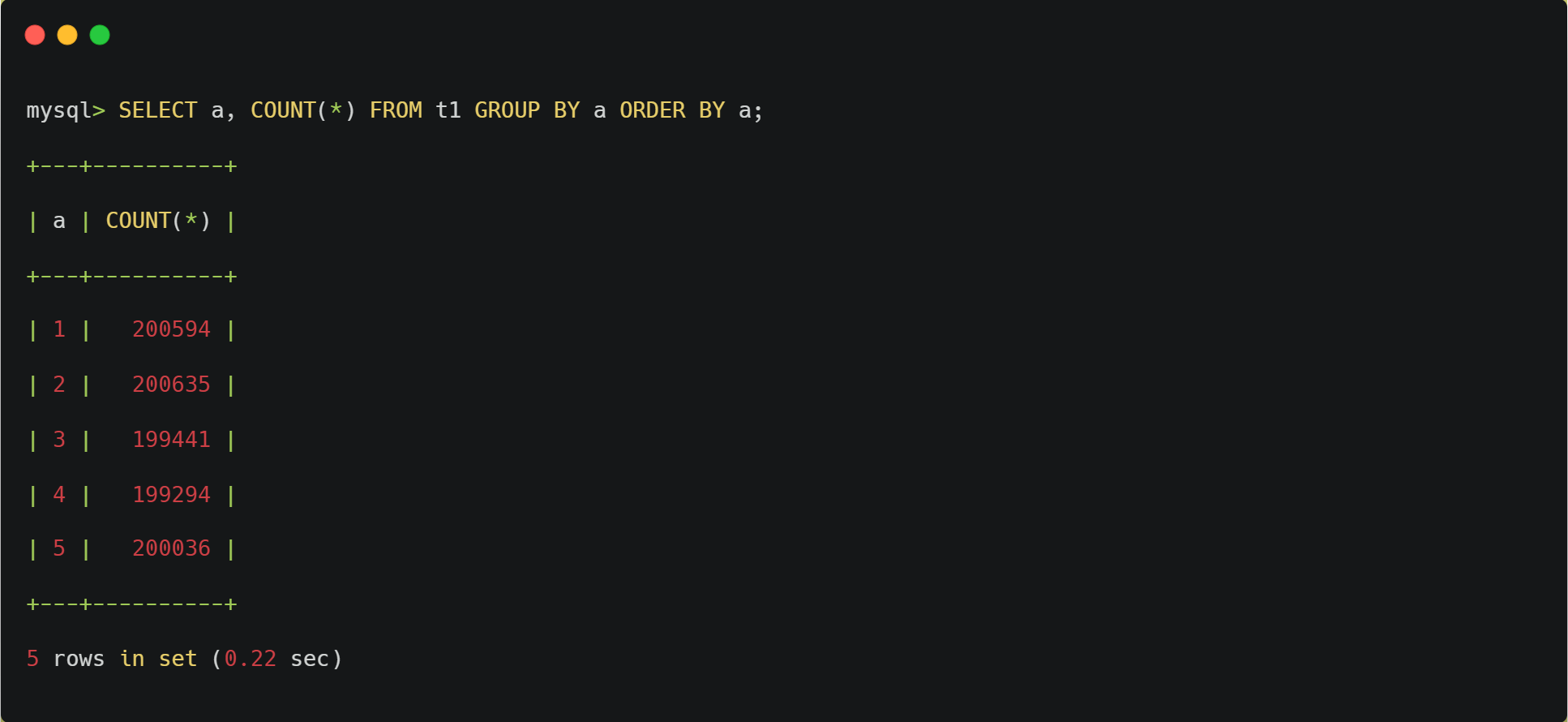
验证 a 的分布,应集中在 1~5:
SELECT a, COUNT(*) FROM t1 GROUP BY a ORDER BY a;
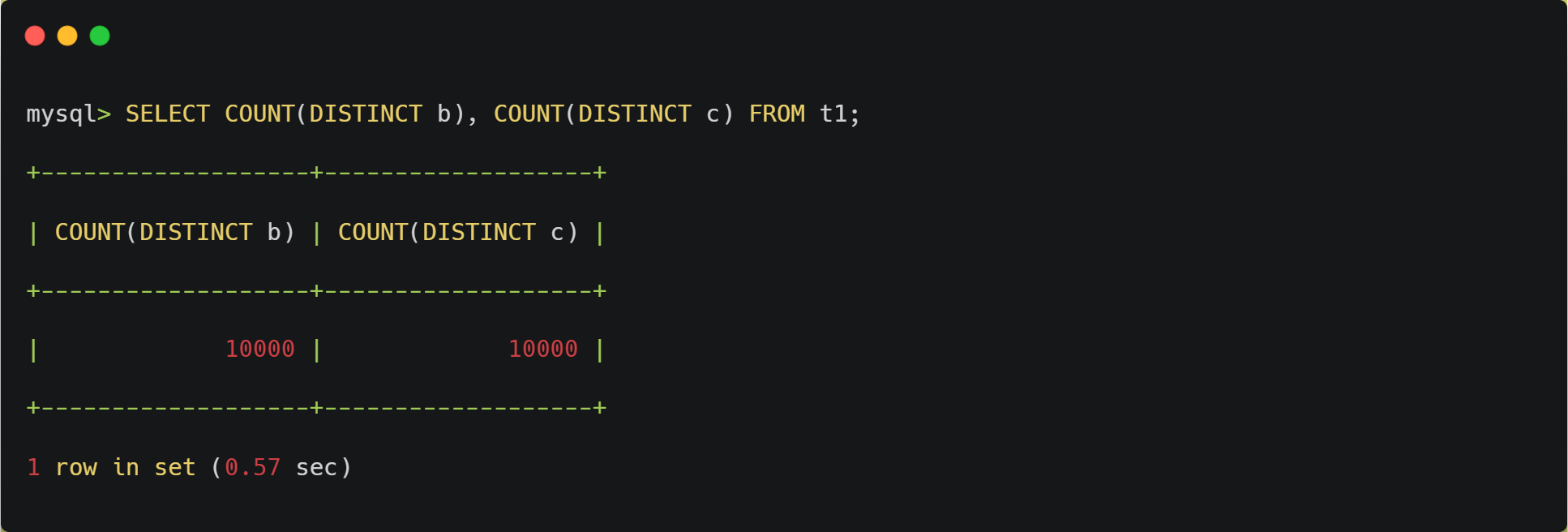
验证 b/c 的区分度,应有接近 10000 个不同值:
SELECT COUNT(DISTINCT b), COUNT(DISTINCT c) FROM t1;
SQL 测试
where a = ? and b = ? and c = ?
这里可以使用 EXPLAIN ANALYZE。EXPLAIN ANALYZE 是 MySQL 8.0.18 及以上版本引入的一个调试工具,用于分析 SQL 查询的实际执行过程。它不仅显示优化器预估的执行计划(类似常规的 EXPLAIN),还会实际执行查询并返回详细的运行时统计信息(如实际耗时、处理行数等),帮助开发者精准定位性能瓶颈。
EXPLAIN ANALYZE
SELECT *
FROM t1
WHERE a = 1;

可以看到,总耗时在 617 ms 左右。
where a = ?
EXPLAIN ANALYZE
SELECT *
FROM t1
WHERE a = 1 and b = 1024 and c = 4048;

可以看到,总耗时在 0.0095 ms 左右。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











