






基于scarpy框架的肯德基中国门店信息获取
一.项目流程
scrapy基础知识: https://blog.youkuaiyun.com/qq_44907926/article/details/119531324
1.创建scrapy项目:scrapy startproject <项目名>
2.在项目中生成一个爬虫: scrapy genspider <爬虫名字> <允许爬取的域名>
3.对爬虫文件进行编写
4.将数据通过管道进行储存

二.对爬虫文件进行编写
对此网站的详细爬取策略: https://blog.youkuaiyun.com/qq_62975494/article/details/136594118
url:https://www.kfc.com.cn/kfccda/storelist/index.aspx
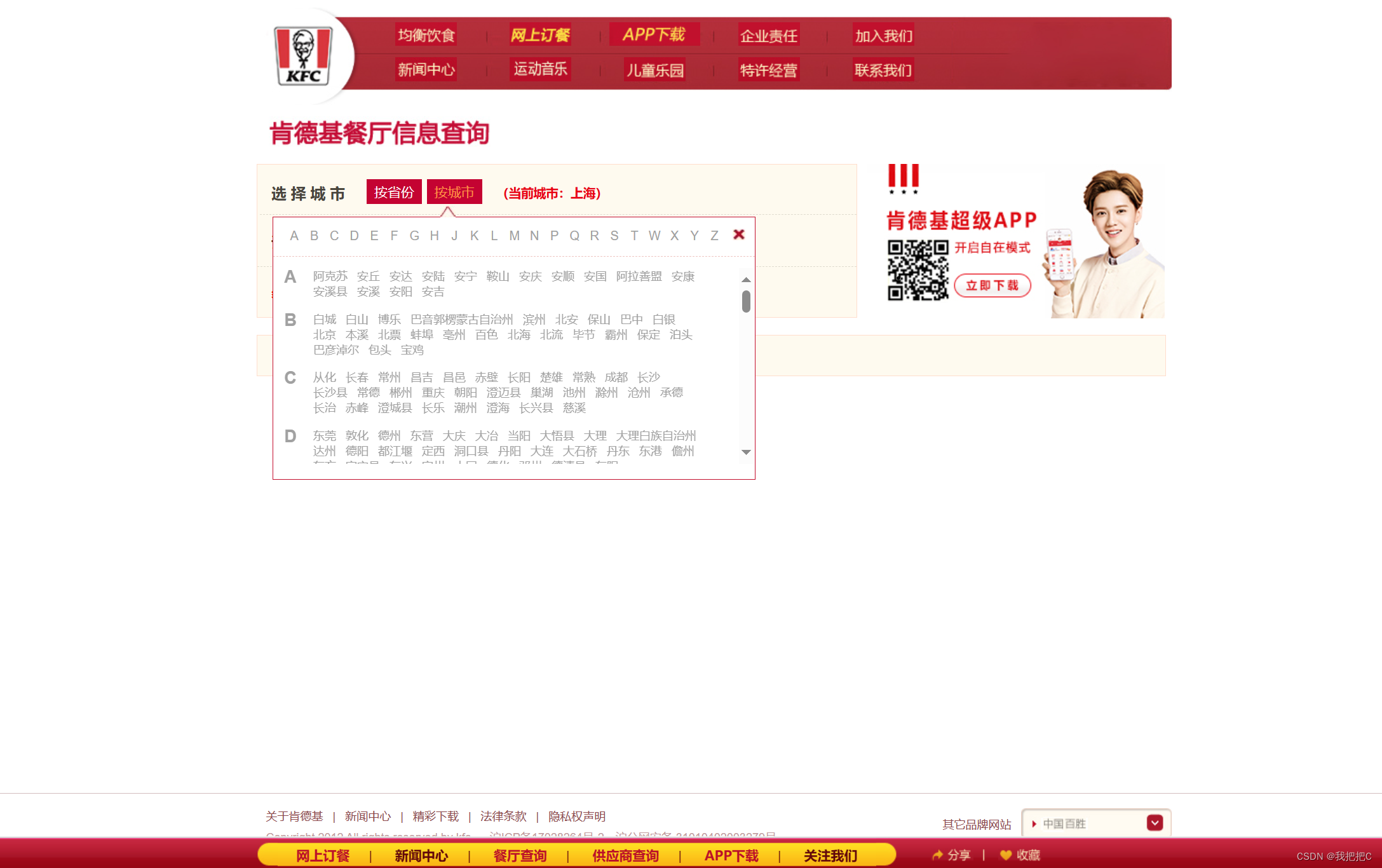
我们首先需要获取全部城市的名字然后依次对所有城市进行请求
import scrapy
from lxml import etree
from ..items import KfccityItem
class KfcpySpider(scrapy.Spider):
name = 'kfcpy'
allowed_domains = []
start_urls = ['http://www.kfc.com.cn/kfccda/storelist/index.aspx']
def parse(self, response):
res1 = response.text
tre = etree.HTML(res1)
sheng = tre.xpath('//*[@id="container"]/div[1]/div[2]/div/div[1]/div[1]/div/div[3]/ul/li/strong/text()')
# 得到页面源码
n = len(sheng)
item=KfccityItem()
for i in range(1, n + 1):
shi = tre.xpath(f'//*[@id="container"]/div[1]/div[2]/div/div[1]/div[1]/div/div[3]/ul/li[{i}]/div/a/text()')
# 使用xpath对信息获取
for s in shi:
item['city']=sheng[i - 1] + '-' + s
item['pipe']='KfccityPipeline'
yield item
data={
'cname': s,
'pid':'',
'pageIndex': '1',
'pageSize': '100'
}
yield scrapy.FormRequest(url='https://www.kfc.com.cn/kfccda/ashx/GetStoreList.ashx?op=cname',formdata=data,callback=self.xiangxi,method='POST',meta={'area':sheng[i - 1] + '-' + s})
def xiangxi(self,response):
item = KfccityItem()
item['area']=response.meta.get('area', 'default_value_if_not_found')
item['datas']=response.json()['Table1']
item['pipe'] ='xiangxiPipeline'
yield item
allowed_domains = []设置为空表示不对请求进行域名过滤
start_urls为起始url
我们首先通过对起始url的response进行解析得出所以的城市然后分别对每个城市再次进行请求然后解析其返回的response此处我们使用scrapy.FormRequest()callback为将结果返回给哪个方法
三.对管道进行编写
我们不仅要保存城市名单也要对每个城市的详细内容进行保存所以我们需要两条管道我们通过给item添加标志位来确定传回的数据需要使用哪条管道
items.py
Define here the models for your scraped items
#
# See documentation in:
# https://docs.scrapy.org/en/latest/topics/items.html
import scrapy
class KfccityItem(scrapy.Item):
# define the fields for your item here like:
city = scrapy.Field()
area=scrapy.Field()
datas = scrapy.Field()
pipe=scrapy.Field()#管道标志位
pass
pipelines.py
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html
import json
# useful for handling different item types with a single interface
from itemadapter import ItemAdapter
class KfccityPipeline:
fp = None
# 重写父类的一个方法:该方法只在开始爬虫的时候被调用一次
def open_spider(self, spider):
print('开启爬虫')
self.fp = open('./a.txt', 'w', encoding='utf-8')
# 用来处理item类型对象
# 该方法可以接收爬虫文件提交过来的item对象
# 该方法每接收到一个人item就会被调用一次
# 如果把打开关闭文件放这,则需要多次打开关闭文件,则另外创建函数,减少打开关闭文件次数
def process_item(self, item, spider): # item为item对象
if item['pipe']=='KfccityPipeline':
city = item['city']
self.fp.write( city+ '\n')
return item
else:
return item
def close_spider(self, spider):
print('结束爬虫')
self.fp.close()
class xiangxiPipeline:
fp = None
# 重写父类的一个方法:该方法只在开始爬虫的时候被调用一次
def open_spider(self, spider):
print('开使记录数据')
# 用来处理item类型对象
# 该方法可以接收爬虫文件提交过来的item对象
# 该方法每接收到一个人item就会被调用一次
# 如果把打开关闭文件放这,则需要多次打开关闭文件,则另外创建函数,减少打开关闭文件次数
def process_item(self, item, spider): # item为item对象
if item['pipe'] == 'xiangxiPipeline':
area=item['area']
with open(f'./ssh/{area}.json', 'w', encoding='utf-8') as fp:
datas = item['datas']
json.dump(datas, fp, indent=4)
fp.close()
return item
else:
return item
def close_spider(self, spider):
print('记录结束')



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











