






一 、 实验题目
实验五:王者荣耀数据处理
二 、 实验目的和要求
实验五:
1 、 目的: 掌握基础语法
2 、要求: 掌握pandas以及numpy的基本用法
三 、 实验内容
- 代码
import pandas as pd
import numpy as np
# # 案例分析: 王者荣耀英雄特点分析
# 本案例中我们将利用王者荣耀英雄数据集进行分析,训练Pandas库的使用
# #### 使用 `pd.read_csv` 导入数据
df = pd.read_csv('data/type_hero.csv')
# 1.一共有多少个英雄
print(df.shape[0])
# 2.每个英雄有多少个属性
print(df.shape[1]-2)
# 3.血最多的英雄
maxblood=df.agg({"最大生命":np.max})
print(maxblood)
n=df[df['最大生命'].values==maxblood.values]
n1=n[['英雄名称']]
print(n1)
# 4. 找出孙悟空初始攻击力的排名
# df1=df.sort_values(by=["物理攻击"],ascending=False)
df['排名']=df['物理攻击'].rank(ascending=0,method='dense')
p=df[df['英雄名称'].values=='孙悟空']
k1=p[['排名','英雄名称','物理攻击']]
print(k1)
# <div class="alert alert-info alert-dismissible">根据上述数据集完成下列问题<span class="label label-warning">时间10分钟</span>
# </div>
#
# 1. 每种英雄的平均属性(取两位小数)
avgs = df[['最大生命','最大法力','物理攻击','法术攻击','物理防御','物理减伤率','法术防御','法术减伤率','物理护甲穿透','法术护甲穿透','攻速加成','暴击几率','暴击效果','物理吸血','法术吸血','冷却缩减','攻击范围','韧性','生命回复','法力回复']].mean(numeric_only=True)
print(np.around(avgs, 2))
# 2. 近程英雄和远程英雄数量
print(df['攻击范围'].value_counts())
# 3. 每一种英雄生命回复排名
df['rank']=df['生命回复'].rank(ascending=0,method='dense')
m1=df[['rank','英雄名称','生命回复']]
print(m1)
# In[ ]:
- 运行结果截图:
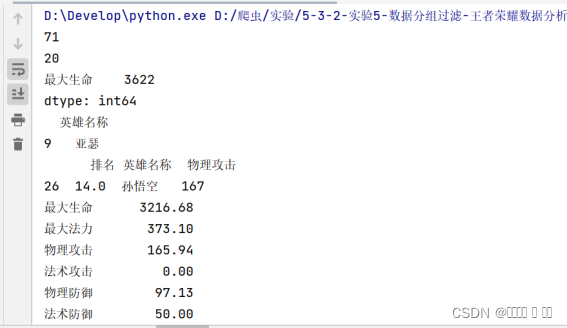
图 1
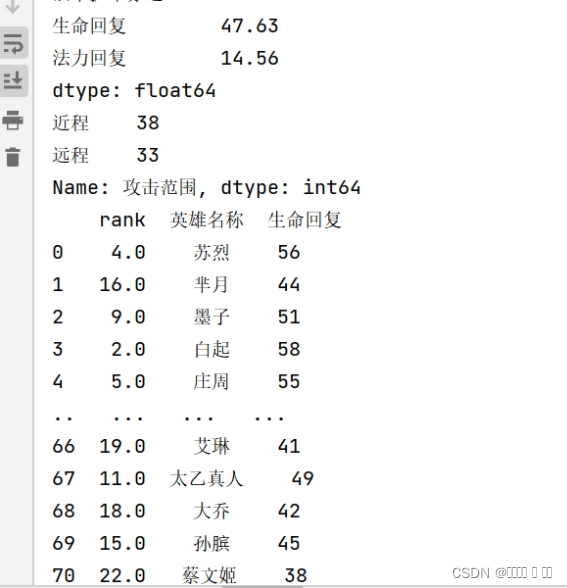
图 2


















 1617
1617

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











