







作者:没什么技术 | 原创文章,转载请注明出处
关键词:代码覆盖率、软件测试、质量保障
作为一名开发者,你是否经历过这样的场景?
👉 “这个PR行覆盖率只有65%,不能合并到release分支!”
👉 “测试报告显示新增代码覆盖不足80%,请补充用例!”
当我们抱怨这些规则时,是否真正理解企业强制要求行覆盖率背后的深层逻辑?今天,让我们拨开迷雾,探寻质量管控的底层逻辑。
一、行覆盖率:不只是冰冷的数字
1.1 从两起真实事故看覆盖率的价值
- 案例1:某电商平台促销活动崩溃
未覆盖的优惠券计算模块导致金额计算错误,直接损失超千万 - 案例2:金融系统日终批处理失败
数据库连接释放代码未被测试,引发内存泄漏
这两个典型案例的共同点:事故代码均未被测试覆盖。
1.2 覆盖率的三重防护作用
二、为什么企业如此执着于覆盖率指标?
2.1 风险量化管理
# 风险计算公式示例
def 风险值 = (未覆盖代码行数 × 缺陷密度) / 测试完备度
# 当覆盖率从70%提升至85%时:
risk_before = (3000*0.1)/0.3 # 1000
risk_after = (1500*0.1)/0.45 # 333
数据证明:覆盖率提升15%,潜在风险下降66%
2.2 构建测试文化
通过覆盖率卡点倒逼团队:
- 编写可测试的代码
- 实践TDD(测试驱动开发)
- 建立持续集成流水线
某互联网大厂实践数据:
强制执行覆盖率要求后,生产缺陷率下降42%,Hotfix发布减少68%
2.3 应对软件熵增定律
// 典型代码腐化过程
function processOrder() {
// 新增功能代码
if (isNewUser) { /* 未覆盖的分支 */ }
// 三年前遗留代码
const taxRate = 0.05; // 已废弃的税率计算
}
高覆盖率能有效遏制"代码腐化速度",保持系统健康度
三、超越数字:正确使用覆盖率的姿势
3.1 覆盖率陷阱:我们踩过的坑
- 虚假覆盖:执行但无断言的测试
@Test
public void testPayment() {
payment.process(); // 仅调用方法,未验证结果
}
- 路径覆盖盲区:未覆盖的异常分支
- 第三方代码干扰:自动生成的代码拉低覆盖率
3.2 最佳实践指南
-
分层覆盖策略
测试类型 目标覆盖率 关注重点 单元测试 80%+ 核心业务逻辑 集成测试 60%+ 模块交互 E2E测试 40%+ 关键用户旅程 -
智能增量检查
# 使用diff coverage检查新增代码
pytest --cov --cov-report=term-missing --cov-branch
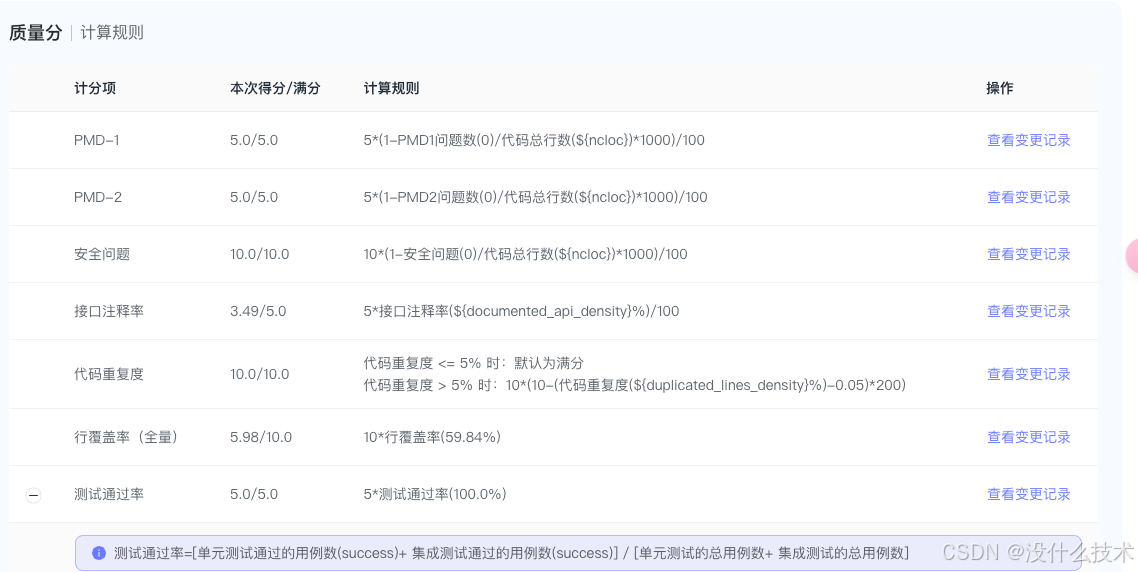
- 质量常见指标
四、面向未来的覆盖率演进
4.1 AI赋能的智能覆盖
- 基于历史缺陷的智能热点分析
- 自动生成边界条件测试用例
- 风险预测模型
4.2 开发者自检清单
- 新增代码是否达到覆盖要求?
- 关键分支是否有assertion?
- 异常处理逻辑是否被覆盖?
- 是否避免了过度Mock?
写在最后
覆盖率不是银弹,但确实是质量防线的重要一环。与其抱怨"形式主义",不如主动理解背后的工程价值。记住:覆盖率保护的不是代码,而是企业的核心业务价值。
互动话题:
你的团队如何平衡覆盖率要求与开发效率?遇到过哪些覆盖率相关的趣事?欢迎评论区分享讨论!



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









