







1. (单选题,5.0分)代码片段:
import java.util.*; public class TestSet { enum Num {ONE, THREE, TWO} public static void main(String[] args) { Collection coll = new LinkedList(); coll.add(Num.THREE); coll.add(Num.ONE); coll.add(Num.THREE); coll.add(Num.TWO); coll.add(Num.TWO); Set set = new HashSet(coll); System.out.println(set); } }关于set变量的描述哪个选项是正确的?(B)
A.set变量包含了coll集合中的5个变量,但顺序无法确定。
B.set变量只包含了coll集合中的3个变量,但顺序无法确定。
C.set变量只包含了coll集合中的3个变量,并且顺序与coll里的相同。
D.set变量包含了coll集合中的5个变量,并且顺序与coll里的相同。
解析:
set集合的特点:
A:存入集合的顺序和取出集合的顺序不一致
B:没有索引
C:存入集合的元素没有重复
HashSet唯一性原理:
规则:新添加到HashSet集合的元素都会与集合中已有的元素一一比较
首先比较哈希值(每个元素都会调用hashCode()产生一个哈希值)
如果新添加的元素与集合中已有的元素的哈希值都不同,新添加的元素存入集合
如果新添加的元素与集合中已有的某个元素哈希值相同,此时还需要调用equals(Object obj)比较
如果equals(Object obj)方法返回true,说明新添加的元素与集合中已有的某个元素的属性值相同,那么新添加的元素不存入集合
如果equals(Object obj)方法返回false, 说明新添加的元素与集合中已有的元素的属性值都不同, 那么新添加的元素存入集合
map集合特点:
采用了 Key-value键值对映射的方式进行存储,key在Map里面是唯一的但是value可以重复,一个key对应一个value。key是无序、唯一的,value是无序不唯一的。
Map接口有两个集合HashMap和TreeMap及LinkedHashMap:
HashMap采用哈希表的存储结构所以里面的数据是无序但是唯一的。(实现唯一的方式就是重写 Hashcode和equals方法)
TreeMap采用的是二叉树的存储方式里面的数据是唯一而且有序的而且一般是按升序的方式排列 (要实现comparable接口并且重写compareTo的方法用来实现它的排序)
LinkedHashMap是HashMap的进化版它比HashMap速度更快而且还可以保证唯一性和有序性。(它的实现方式是哈希表和链表的结合)
2. (填空题,10.0分)
请写出SQL语句可以从t_table中得到每门课都大于80分的学生姓名
name course fenshu
小张 语文 81
小张 数学 75
小李 语文 76
小李 数学 90
小王 语文 81
小王 数学 100
小王 英语 90
答案:select name from grade group by name having min(score)>80;
解析:
第一步,查询姓名,最低分数。
select name,min(score) from student;
第二步,这里只能查询出最低分数的那个人。需要改进,根据用户名分组(group by name),这样就能查询出每个人的最低分数。
select name,min(score) from student group by name;
第三步,我们只需要得到最低分数大于80的学生的名字。通过having语句来筛选。
select name from grade group by name having min(score)>80;
3. (多选题,6.0分)下面的输出语句不会有编译错误的是(BCD)
public class NowCoder { public static void main(String[] args) { int a = 5, b = 5; System.out.println("a - b = " + a - b); System.out.println("a + b = " + a + b); System.out.println("a * b = " + a * b); System.out.println("a / i2 = " + a / b); } }
A.System.out.println("a - b = " + a - b);
B.System.out.println("a + b = " + a + b);
C.System.out.println("a * b = " + a * b);
D.System.out.println("a / i2 = " + a / b);
解析:
①"a+b=" + a - b
②"a+b=5" - b
前面为字符串类型,后面为整型,不能使用 - 法运算
4. (多选题,6.0分)在下列4条语句的前提下:
Integer i01 = -128; int i02 = -128; Integer i03 =Integer.valueOf(-128); Integer i04 = new Integer(-128);以下输出结果为true的是:(ABC)
A.System.out.println(i01 == i03);
B.System.out.println(i02 == i04);
C.System.out.println(i01 == i02);
D.System.out.println(i03 == i04);
解析:
1.128为整数,而要的是一个Integer的类型,要进行自动装箱
2.Integer类中,自动装箱的底层要调用静态的valueOf()方法
3.在静态的valueOf方法中有一个判断,判断输入的整数是否超过int的范围(-127~128)
4.超过范围会创建一个新的Integer对象,并返回,所以当比较的整数超过范围时,返回的是新创建的对象,即 Integer i5 = 128; i5接收的是一个新对象, Integer i6 = 128;i6接收的也是一个新对象,而==在引用类型中比较的是两个对象的地址是否相等,则可得出i5==i6的比较结果为false
5.若输入的整数没有超过范围,则返回(Integer类中的)静态方法IntegerCache()中的存在于静态代码块中的Integer类型的静态数组cache中的某个值。因为是静态方法而且静态数组cache在静态代码块中,所以在类加载的时候就执行。在静态代码块中,对cache数组进行赋值操作。
也就是说当输入的整数在范围内时会调用一个数组,而且数组的下标是输入的值+1计算出来的,而数组中的值,是在类加载的时候就已经存放好的。
5. (多选题,7.0分)表tg_user,主键为tg_id,tg_email是允许为空的列,下列能正确统计出该表记录数的语句是( BCD )
A.SELECT count( tg_email ) FROM `tg_user `
B.SELECT count(tg_id) FROM `tg_user`
C.SELECT count(*) FROM `tg_user`
D.SELECT count(1) FROM `tg_user`
解析:select count(1) from table 也是返回表中包括空行和重复行在内的行数,不会扫描所有列,1其实就是表示有多少个符合条件的行,但是此时没有where,所有没条件也就是返回总行数
6. (多选题,7.0分)关于where和having子句说法正确的有?( AE)
A.WHERE子句只能用于限制行。
B.HAVING子句不能在子查询中使用。
C.WHERE子句可用于限制行和组。
D.HAVING子句可用于限制行和组。
E.HAVING子句只能用于限制组。
F.如果查询使用HAVING子句,则不能在查询中使用WHERE子句。
解析:
WHERE子句只能用于限制行
HAVING子句只能用于限制组,HAVING子句可以在子查询中使用
如果查询使用HAVING子句,可以在查询中使用WHERE子句
7. (填空题,15.0分)请根据提示在程序空白处补全程序,使程序能够正确运行。
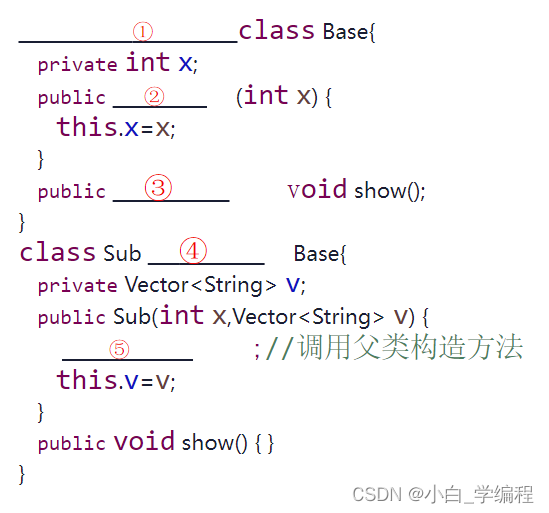
答案:
(1) abstract
(2) Base
(3) abstract
(4) extends
(5) super(x)
解析:(3)处是一个抽象方法,则①和③必是abstract,②是构造器,④明显是继承,⑤是调用父类的构造器初始化父类。

















 3655
3655

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









