




 本文介绍了Hadoop集群增加和删除节点的操作步骤,增加节点需添加主机名、刷新节点等,删除节点要下线分区服务器、添加配置等。同时列举了集群操作中遇到的多个问题,如journalnode未格式化、cid不一致等,并给出了相应的解决办法。
本文介绍了Hadoop集群增加和删除节点的操作步骤,增加节点需添加主机名、刷新节点等,删除节点要下线分区服务器、添加配置等。同时列举了集群操作中遇到的多个问题,如journalnode未格式化、cid不一致等,并给出了相应的解决办法。
注意:本文章仅作为个人学习使用!如有错误,欢迎大家指出!
文章目录
journalnode中的cid也要注意保持一致!we expect txid xx,but got txid xx.
⑤live report和web界面为0,而节点全部启动?查看日志排除错误
⑦permanently added 'slave02,xxxxxx'(ECDSA) to the list of known host
增加节点:
- 将新节点的主机名添加到所有节点的/etc/hosts和hadoop文件路径下slaves文件中
- 在名称节点上刷新节点:hadoop dfsadmin -refreshNodes
- 在新节点上启动datanode进程:hadoop-daemon.sh start datanode
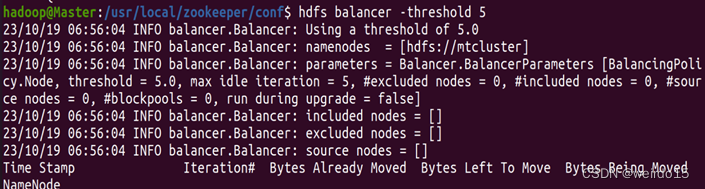
- 设置负载均衡并在任意节点执行:hdfs balancer -threshold 5(其中参数数值5表示集群内所有节点存储百分比差距要在5%以内)
- 增加Hbase分区(所有节点hbase文件路径下的regionservers 文件中添加新节点主机名)
- 在新增节点上调起HRegionserver进程:

- Web界面查看集群:http://master:50070
 http://master:60010
http://master:60010 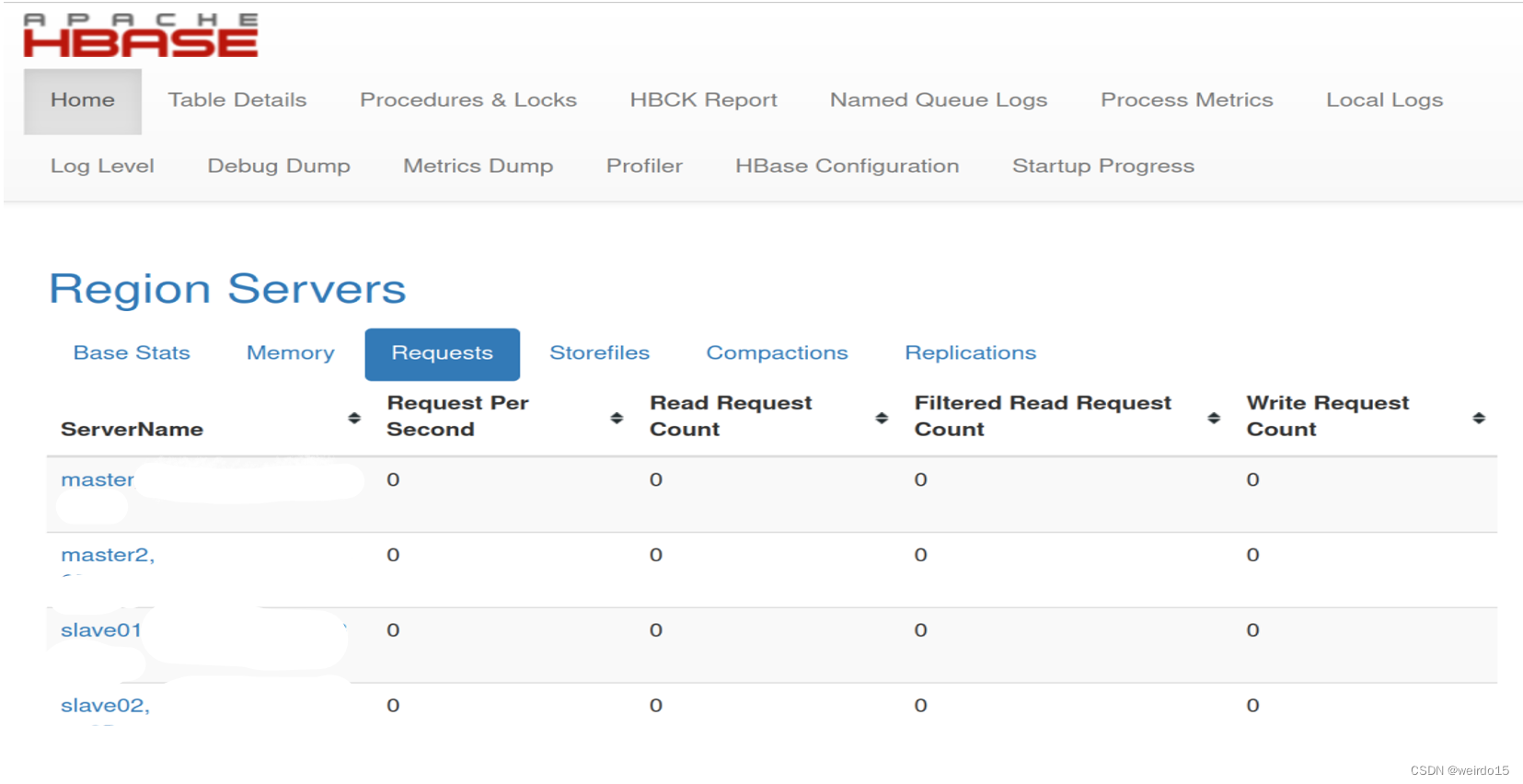
删除节点:
-
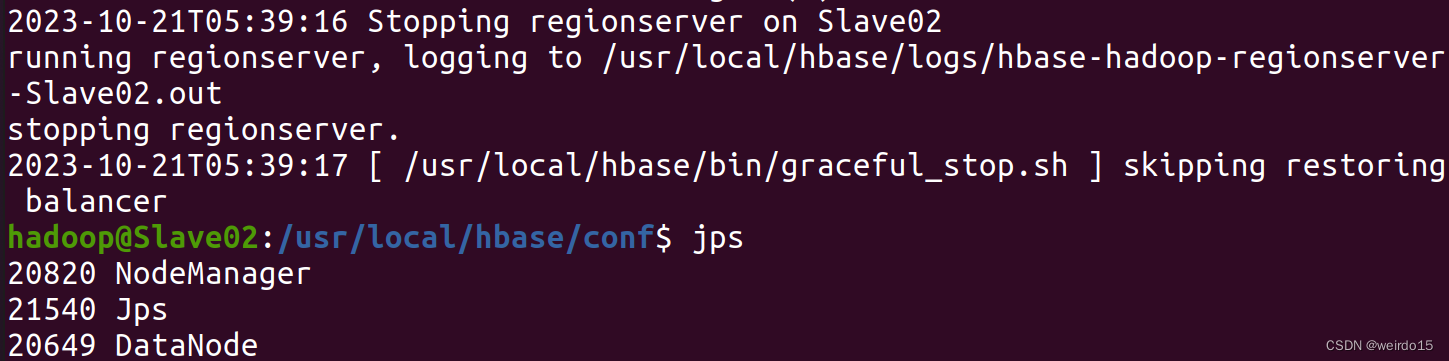
下线HBase分区服务器: 在新节点执行graceful_stop.sh +新增节点主机名:
-
在所有节点的hdfs-site.xml文件中添加exclude-slaves配置(需要重启)

-
在所有老节点中添加exclude-slaves文件,并在其中加入新节点的主机号
-
在名称节点调用节点刷新命令:hadoop dfsadmin -refreshNodes
-
清理新节点信息(先将slaves和exclude-slaves文件中的节点信息删除,每个老节点都执行)再执行一次节点刷新命令:
-
web界面查看:http://master:50070(可以看到新节点变成Decommissioned状态)
其中遇到的问题 :
①Journal Storage Directory /tmp/hadoop/dfs/journalnode/mtcluster notformatted ; journal id: mtcluster
原因:journalnode未完全同步
解决办法:删除data目录下的临时文件,除日志进程外其他进程关闭,启动hdfs name -initializeSharedEdits
②

namenode cid与 datanode cid不同
(注意路径下的current文件)
解决办法:查看namenode路径下的VSERION,保证其他节点上的datanode路径下的VSERION中的cid与其一致。
journalnode中的cid也要注意保持一致!we expect txid xx,but got txid xx.:
原因:standy同步丢失部分文件,注意在另一namenode节点实现 standy同步,否则容易出现got与expected不同
解决办法: 查看NN节点垃圾箱,找到 expected txid xx并还原
datanodeuuid的设置保证每个节点不同即可:参考⑧中的链接
[!!!不要随意格式化]
③

(namenode挂掉)
在yarn-site.xml文件中写入

④hadoop:datanode启动失败:errot org.apache.hadoop.hdfs.server.datanode.DataNode:Initialization failed for Block pool <registering> (Datanode Uuid e1dfcbe0-396b-48d7-93bb-eb4030d13eb8) service to Master/xxxxxx:xxxx。Exiting.java.io.IOException: All specified directories have failed to load.
原因是:namespaceID is incompatible with others.即是namenode和datanode的clusterID不一致导致datanode无法启动
解决办法:参考②
⑤live report和web界面为0,而节点全部启动?查看日志排除错误
⑥java.io.EOFException: End of File Exception between local host is: "Master2/xxxxxx" destination host is: "Master2":xxxxxx; :……
at org.apache.hadoop.ipc.ClientSConnection.run(Client.java:1098)2023-10-18 12:50:15,531 ERROR org.apache.hadoop.hdfs.server.datanode.DataNode: RCEIVED SIGNAL 15: SIGTERM
解决办法:可能是网络问题,检查重启一下。如果不行可以尝试hadoop dfsadmin refreshNodes
⑦permanently added 'slave02,xxxxxx'(ECDSA) to the list of known host
解决办法:在~/.ssh/config文件中添加UserKnownsFile ~/.ssh/known_hosts
⑧Hadoop集群DataNode成功启动,但网页没有显示
报错信息如下:
2023-10-19 02:05:15,764 WARN org.apache.hadoop.ipc.Client: Failed to connect to server: master1/xxxxx: retries get failed due to exceeded maximum allowed retries number: 0
解决办法:修改虚拟机的datanodeUuid即可,保证集群的每台机器不一样
参考链接:Hadoop集群DataNode成功启动,但网页没有显示_datanode存在,而web界面不显示-优快云博客
END

















 1929
1929



 到【灌水乐园】发言
到【灌水乐园】发言








