







JAVA进阶学习 —面向对象高级
Part01 Static 与 继承
static 即静态,可以修饰成员变量、成员方法
static
变量有无static修饰分为
-
类变量:
有static修饰,属于类,在计算机里只有一份,会被类的全部对象共享
类名.类变量(推荐) 对象.类变量(不推荐)
不同对象访问时,访问的是同一个变量
-
实例变量*(对象的变量):
属于每个变量的
对象.实例变量();
类变量应用场景
在开发中,某个数据只需要一份,且希望可以被共享(访问、修改)
案例:用户类可以记住自己创建多少个用户对象了.
public class User {
public static int number;
public User(){
User.number++;
}
}
方法有无static修饰分为
-
类方法:有static修饰,属于类
类名.类方法(推荐) 对象名.类方法(不推荐)
-
实例方法:无static修饰,属于对象
对象.实例方法()
类方法应用场景
最常见方法是用来做工具类
工具类是什么?每个方法都用来完成一个功能,工具类是给开发人员共同使用
- 提高代码复用
- 调用方便
- 提高开发效率
注意事项
- 类方法中可以直接访问类的成员,但不可以直接访问实例成员
- 实例方法中可以直接访问类成员,也可以直接访问实例成员
- 实例方法中可以出现this关键字,类方法中不可以出现实例关键字
static应用知识:代码块
代码块是类的五大成分之一:成员变量 构造器 方法 代码块 内部类
-
静态代码块
-
格式:static{}
-
特点:类加载时自动执行,类只会加载一次,静态代码块也只会执行一次
-
作用:完成类的初始化
public class User { static int number = 80; static { System.out.println("静态代码块执行了~"); } }public class Test { public static void main(String[] args) { System.out.println(User.number); } }
-
-
实例代码块
-
格式:{}
-
特点:创建对象时,执行实例代码块,并在构造器前执行
-
作用:用来初始化对象(不建议实例代码块进行初始化赋值,会使对象的值一样)
-
常见方法有:记录对象创建日志
public class User { static int number = 80; { System.out.println("实例代码块执行力"); } public User(){ System.out.println("无参构造器"); } public User(int number){ System.out.println("有参构造器"); } }public class Test { public static void main(String[] args) { User s1=new User(); User s2=new User(15); } }
-
static应用知识:单例设计模式(架构师知识技术 开发框架)
什么是设计模式?
解决问题的最优解法
- 解决什么问题
- 怎么写
单例设计模式
- 确保一个类只有一个对象
- 饿汉式单例:拿对象时,对象早就创建好了
- 懒汉式单例:拿对象时,才开始创建对象
饿汉式单例:
- 把类的构造器私有
- 定义一个类变量记住类的一个对象
- 定义一个类方法,返回对象
public class A {
// 1.定义一个类变量记住类的一个对象
private static A a = new A();
// 2.私有A的构造器
private A() {
}
// 3.定义一个类方法返回类的对象
public static A getObject() {
return a;
}
}
应用场景:
Runime
任务管理器:无论启动多少次,都只有一个窗口
懒汉式单例设计模式
- 拿对象时,才开始创建对象
写法
-
把类的构造器私有
-
定义一个类变量用于存储对象
-
提供一个类方法,保证返回的是同一个对象
public class B { private static B b; private B(){ } public static B getInstance(){ if (b==null){ System.out.println("第一次创建对象~~"); b = new B(); } return b; } }
继承 extends
- 特点:子类能够继承父类的非私有成员
- 继承后对象是由子类、父类共同完成的
public class Father {
public int i;
private int j;
public void printi() {
System.out.println("======Printi======");
}
private void printj() {
System.out.println("======Printj======");
}
}
public class Son extends Father{
public void print() {
printi();
printj();//报错
}
}
继承状态下,Son创建对象时由Son和Father俩个类共同构成
继承的好处与应用场景
减少重复代码的编写
校园管理系统:
老师:姓名,工号,所教学科,所带班级
同学:姓名,学号,所在班级
继承的相关注意事项
-
权限修饰符
修饰符 在本类中 同一个包下的其他类里 任意报下的子类里 任意包下的任意类里 private √ 缺省 √ √ protected √ √ √ public √ √ √ √ public>protecte>缺省
-
单继承 object类
Java是单继承的,一个类只能继承一个直接父类,Java不支持多继承,但可以多层继承
Object类是Java中所有类的祖宗
-
方法重写
声明不变,重新实现
- 使用Override注解,指定java编译器检查我们的重写是否正确
- 子类重写父类方法,访问权限必须大于或者等于父类的该方法权限
- 重写的方法返回值类型,必须与被重写的方法的返回值类型一致,或者范围更小
- 私有方法、静态方法不能被重写
public class Father { public int i; private int j; public void printi() { System.out.println("======Printi======"); } }public class Son extends Father{ @Override public void printi(){ System.out.println("重写i"); } } -
子类中访问其他成员的特点
-
子类中访问其他成员,依照就近原则
-
想要访问父类的关键字 使用supergu关键字
public class Son extends Father{ String name="子类name"; public void print(){ String name="局部name"; System.out.prinln(name); //局部名称 System.out.prinln(this.name); //子类成员变量 System.out.prinln(super.name); //父类成员变量 } }
-
-
子类构造器特点
- 子类的全部构造器,都会先调用父类构造器,再来执行子类构造器内容;
-
子类构造器的常见应用场景
补充知识:this(…)调用兄弟构造器
-
任意类的构造器中,是可以通过调用this(…)去调用该类的其他构造器的
-
在一个构造器中,无法同时使用this括号与super括号
public class test2 { public static void main(String[] args) { Student s1=new Student("李四",26,"beiking"); System.out.println(s1.toString()); // 需求:如果学生没有填写学校,学校默认为tjut; Student s2=new Student("zhangsan",22); System.out.println(s2.toString()); } } class Student{ private String name; private int age; private String schoolName; public Student() { } public Student(String name, int age) { this(name,age,"tjut"); } public Student(String name, int age, String schoolName) { this.name = name; this.age = age; this.schoolName = schoolName; } @Override public String toString() { return "Student{" + "name='" + name + '\'' + ", age=" + age + ", schoolName='" + schoolName + '\'' + '}'; } public String getName() { return name; } public void setName(String name) { this.name = name; } public int getAge() { return age; } public void setAge(int age) { this.age = age; } public String getSchoolName() { return schoolName; } public void setSchoolName(String schoolName) { this.schoolName = schoolName; } }
Part02 多态 、抽象类、 接口
多态:
- **什么是多态?**多态是在继承/实现情况下的一种现象,表现为:对象多态,行为多态
- **多态的前提?**有继承/实现关;存在父类引用子类对象/存在方法重写
- 多态注意事项:对象、行为多态,Java中的成员变量不谈多态
import javax.lang.model.element.NestingKind;
public class people {
public String name="People";
public void run(){
System.out.println("跑步~~~~");
}
}
public class Student extends people{
public String name="Student";
@Override
public void run() {
System.out.println("学生跑的快");
}
}
public class Teacher extends people{
public String name="Teacher";
@Override
public void run(){
System.out.println("老师跑的慢");
}
}
public class test {
public static void main(String[] args) {
// 对象多态
people p1=new Student();
people p2=new Teacher();
// 行为多态 编译看左边,运行看右边
p1.run();
p2.run();
// 变量没有多态
System.out.println(p1.name);
System.out.println(p2.name);
}
}
多态的好处与问题:
-
多态形式下,右边对象是解耦合的,更便于拓展和维护
-
定义方法时,使用父类类型的形参,可以接收一切子类对象,拓展性更强,更便利
-
**产生问题:**多态下不能使用子类的独有功能
原因:编译看左边,运行看右边
解决方法:类型转换
多态下的类型转换
- 自动类型转换:父类 变量名=new 子类();
- 强制类型转换:子类 变量名=(子类)父类变量;
可能存在问题:
编译阶段有继续或者实现关系就可以强制转换,但是运行时可能出现类型转换异常
运行时,如果发现对象的真是类型与强转后的类型不同,就会报错类型转换异常ClassCastException的错误出来
**强转前建议:**使用 instanceof关键字,判断当前对象的真实性后,在进行强转
p instanceof Student
Final
- final关键字是最终的意思,可以修饰 类、方法、变量
- 修饰类:该类被称为最终类,特点是不能被继承
- 修饰方法:该方法被称为最终方法,特点是不能被重写了
- 修饰变量:该变量只能被赋值一次
常量
- 使用了static final修饰的成员变量称为常量
- 作用:通常用于记录系统的配置信息
- 优势:代码可读性更好,可维护性也更好
抽象类
关键字 abstract 用来修饰类、成员,就是抽象类、抽象方法
public abstract class abstractDemo {
// 抽象方法:必须用abstract修饰,只有方法签名,没有方法体
public abstract void run();
}
注意:
- 抽象类中不一定有抽象方法,有抽象方法一定是抽象类
- 类该有的成员抽象类都有(成员变量、方法、构造器)
- 抽象类不能创建对象,仅作为一种特殊的父类,让子类继承并实现
- 一个类继承抽象类,必须重写完抽象类的全部抽象方法,否则这个类也必须定义为抽象类
抽象类的场景和好处:
-
父类知道每个子类都要做某个行为,但每个子类要做的行为不一样,可以更好的支持多态
-
案例需求:筹物游戏,需要管理猫和狗,猫的数据有:名字,行为是:喵喵的叫;狗的数据有:名字,行为是:汪汪的叫;
public abstract class Animal { private String name; public abstract void cry(); public String getName() { return name; } public void setName(String name) { this.name = name; } }public class Dog extends Animal{ @Override public void cry() { System.out.println(getName()+"汪汪汪~"); } }public class Cat extends Animal{ @Override public void cry() { System.out.println(getName()+"喵喵喵~~~"); } }public class test { public static void main(String[] args) { Animal a=new Cat(); a.setName("叮当猫"); a.cry(); } }
常见应用场景:模板方法设计模式
- 解决方法中重复代码的问题
- 场景:学生、老师要写一段作文:开头结尾一致,中间内容自由
原先:有大量的重复代码
public class Student {
public void write(){
System.out.println("\t\t\t\t\t\t\t作文");
System.out.println("作文开头");
System.out.println("学生作文内容");
System.out.println("作文结尾");
}
}
public class Teacher {
public void write(){
System.out.println("\t\t\t\t\t\t\t作文");
System.out.println("作文开头");
System.out.println("老师作文内容");
System.out.println("作文结尾");
}
}
修改使用模板方法设计模式:
- 定义一个抽象类
- 定义一个模板方法:把相同的代码放里面去
- 定义一个抽象方法:具体实现交给子类方法
import javax.lang.model.element.NestingKind;
public abstract class people {
//模板方法
public final void write(){
System.out.println("\t\t\t\t\t\t\t作文");
System.out.println("作文开头");
System.out.println(zhengwen());
System.out.println("作文结尾");
}
//抽象方法
public abstract String zhengwen();
}
public class Student extends people {
@Override
public String zhengwen() {
return "学生作文内容";
}
}
public class Teacher extends people{
@Override
public String zhengwen() {
return "老师作文内容";
}
}
建议:使用final关键字修饰模板方法,禁止方法被子类重写,防止方法失效
接口
关键字interfa,用来定义一个接口
public interface 接口名{
//成员变量 (常量)
//成员方法 (抽象方法)
//接口中只有成员变量和成员方法,不能创建对象
}
接口不能创建对象,接口是用来被类实现(implements)的,实现接口的类称为实现类
修饰符 class 实现类 implements 接口1,接口2,接口3........{
}
一个类可以实现多个接口,实现类实现多个接口,必须全部重写接口的全部抽象方法
接口的好处
- 弥补类单继承的不足,一个类可以同时实现多个接口
- 让程序可以面向接口编程,这样程序员就可以灵活方便的切换各种业务实现
public class test{
public static void main(String[] args){
String s=new A();
}
}
class A extends Student implements Driver,Singer{
}
class Student{
}
interface Driver{
}
interface Singer{
}
JDK8之后开始,接口中新增的三种方法:
-
// 默认方法,必须使用default修饰,默认会被public修饰 //实例方法:对象的方法,必须使用实现类的对象来访问 public default void test1(){ System.out.rintln("===默认方法==="); } -
// 私有方法,必须使用private修饰(JDK9以上) //实例方法,对象的方法,只能在接口内被调用 private void test2(){ System.out.rintln("===私有方法==="); } -
//静态方法,必须使用static修饰 //类本身持有,使用接口名调用 public static void test3(){ System.out.rintln("===静态方法==="); } -
为什么要新增这些方法?
- 增强接口功能
- 降低维护项目成分
接口的多继承
public interface C extends A,B{
}
//一个接口可以同时继承多个接口
- 便于实现类去实现
- 一个接口继承多个接口,如果多个接口中存在签名冲突,则不能支持多继承
- 一个类实现多个接口,如果多个接口中存在方法签名冲突,则此时不支持多实现
- 一个类继承了父类,又同时实现了接口,父类和接口中又同名的默认方法,实现类会优先用父类
- 一个类实现了多个接口,多个接口中存在同名的默认方法,可以不冲突,这个类重写该方法即可
接口应用案例:班级学生信息管理模块的开发
需求:
- 学生数据有:姓名、性别、成绩
- 功能:打印全班学生信息;打印全班学生平均成绩
student类
public class Student{
private String name;
private char sex;
private double score;
public Student() {
}
public Student(String name, char sex, double score) {
this.name = name;
this.sex = sex;
this.score = score;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public char getSex() {
return sex;
}
public void setSex(char sex) {
this.sex = sex;
}
public double getScore() {
return score;
}
public void setScore(double score) {
this.score = score;
}
}
class类
import java.util.ArrayList;
public class Class {
private ArrayList<Student> students=new ArrayList<>();
private StudentOperator studentOperator=new StudentOperator1();
public Class(){
students.add(new Student("刘宁",'男',99.5));
students.add(new Student("刘烨",'男',9150.5));
students.add(new Student("刘样",'男',999));
}
public void printInfo(){
studentOperator.printAllInfo(students);
}
public void printScore(){
studentOperator.printAverageScore(students);
}
}
StudentOPerator接口
import java.util.ArrayList;
public interface StudentOperator {
void printAllInfo(ArrayList<Student> students);
void printAverageScore(ArrayList<Student> students);
}
StudentOperator1实现类
import java.util.ArrayList;
public class StudentOperator1 implements StudentOperator{
@Override
public void printAllInfo(ArrayList<Student> students) {
System.out.println("------全班全部学生信息------");
for (int i = 0; i < students.size(); i++) {
Student s=students.get(i);
System.out.println("学生姓名:"+s.getName()+"\t性别:"+s.getSex()+"\t成绩:"+s.getScore());
}
}
@Override
public void printAverageScore(ArrayList<Student> students) {
double all=0.0;
for (int i = 0; i < students.size(); i++) {
Student s=students.get(i);
all+=s.getScore();
}
System.out.println("平均分:"+(all/students.size()));
}
}
StudentOperator2实现类
import java.util.ArrayList;
public class StudentOperator2 implements StudentOperator {
@Override
public void printAllInfo(ArrayList<Student> students) {
System.out.println("------全班全部学生信息------");
int count1=0;
int count2=0;
for (int i = 0; i < students.size(); i++) {
Student s=students.get(i);
System.out.println("学生姓名:"+s.getName()+"\t性别:"+s.getSex()+"\t成绩:"+s.getScore());
if (s.getSex()=='男')
count1++;
if (s.getSex()=='女')
count2++;
System.out.println("班内女生人数:"+count2+"班级男生人数:"+count1);
System.out.println("班级总人数:"+students.size());
}
}
@Override
public void printAverageScore(ArrayList<Student> students) {
double max=students.get(0).getScore();
double min=students.get(0).getScore();
double all=0.0;
for (int i = 0; i < students.size(); i++) {
Student s=students.get(i);
if (s.getScore()>max) max=s.getScore();
if (s.getScore()<min) min=s.getScore();
all+=s.getScore();
}
System.out.println("学生最高分:"+max);
System.out.println("学生最低分:"+min);
all=all-min-max;
System.out.println("平均分:"+(all/(students.size()-2)));
}
}
Part03 内部类 、枚举、泛型、java.lang包下的常用API
内部类:
如果一个类定义在另一个的内部,这个类就是内部类
- 场景:一个类的内部,包含了一个完整的事物,且这事物没有必要单独设计时,就可以把这个事物设计成内部类
- 四种形式:成员、静态、局部、匿名
成员内部类
-
类中的普通成员,类似我们之前学过的成员方法,成员变量
public class Outer{ public class Inner{ //类有的 成员内部类都可以有 //JDK16开始支持定义静态成员 //不能直接new成员内部类 } } -
定义时,先new外部类,再 .new内部类
静态内部类
- 有static修饰的内部类,属于外部类自己持有
- 在访问时,直接使用外部类名.内部类名new出来的
局部内部类
- 鸡肋语法
匿名内部类(重点):
-
一种特殊的局部内部类;所谓匿名,指的就是程序员不需要为这个类声明名字
new 类或接口(参数值....){ 类体(一般方法重写); }new Animal(){ @Override public void cry(){ } }; -
特点:匿名内部类本质就是一个子类,并会立即创建出一个子类对象
-
作用:用于更方便的创建一个子类对象
-
应用场景:作为一个参数传输给方法
public class TEst { public static void main(String[] args) { // Swimming s1= new Swimming(){ // @Override // public void Swim(){ // System.out.println("狗飞快`~~~"); // } // }; // go(s1); go(new Swimming() { @Override public void Swim() { System.out.println("有的飞快"); } }); } //go函数 public static void go(Swimming swimming){ System.out.println("开始--------"); swimming.Swim(); } } //系统中猫狗都要参加游泳比赛 interface Swimming{ void Swim(); } -
匿名内部类在开发中的真实使用场景
import javax.swing.*; import java.awt.event.ActionEvent; import java.awt.event.ActionListener; public class Main { public static void main(String[] args) { // GUI编程 // 创建窗口 JFrame win=new JFrame("登录界面"); JPanel panel=new JPanel(); win.add(panel); JButton btn=new JButton("登录"); panel.add(btn); // 给按钮绑定单击事件监听器 btn.addActionListener(new ActionListener() { @Override public void actionPerformed(ActionEvent e) { // 调用别人写好的匿名内部类 JOptionPane.showMessageDialog(win,"登录一下"); } }); win.setSize(400,400); win.setLocationRelativeTo(null); win.setDefaultCloseOperation(WindowConstants.EXIT_ON_CLOSE); win.setVisible(true); } }
枚举
-
枚举是一种特殊的类
修饰符 enum 枚举类名{ 名称1,名称2.....; 其他成员 } -
第一行只能写一些合法的名称
-
本质上为常量,每个常量都是记住枚举类的一个对象的
-
枚举类构造器为私有,枚举类不能对外创建对象
-
枚举类都是最终类,不能被继承
-
枚举类中,从第二行开始,可以定义类的其他各种成员
常见应用场景:
-
表示一组信息,然后作为参数进行传输
-
用户进入应用时选择男女信息,展示不同内容
//原先 public class provideinfo { public static void main(String[] args) { sexinfo(1); } public static void sexinfo(int sex){ switch (sex){ case 0: // 男生 System.out.println("男生频道"); break; case 1: // 女生 System.out.println("女生频道"); break; } } } -
//使用枚举 public enum Constant { Boy,Girl; } public class provideinfo { public static void main(String[] args) { sexinfo(Constant.Boy); } public static void sexinfo(Constant sex){ switch (sex){ case Boy: // 男生 System.out.println("男生频道"); break; case Girl: // 女生 System.out.println("女生频道"); break; } } }
泛型
- 定义类、接口、方法时,同时声明了一个或者多个类型变量,称为泛型类,泛型接口,泛型方法,他们统称为泛型
- ArrayList就是典型的泛型类
定义泛型:
修饰符 class 类名 <类型变量,类型变量,......>{
}
public interface Date<T>{
void add(T t);
ArryList<T> getByName(String name);
}
修饰符 <类型变量,类型变量......> 返回值类型 方法名(形参列表){
}
- 泛型是工作在编译阶段的,一旦程序编译成class文件,class文件就不存在泛型了,这就是泛型擦除
- 泛型不支持基本数据类型,只能支持对象类型
Part04 常用API
Object类
-
object类是java所有类的祖宗,java中所有类的对象都可以直接使用object中提供的一些方法
import java.util.Objects; //Cloneable 标记接口 public class Student implements Cloneable{ private String name; private int age; @Override public boolean equals(Object o) { if (this == o) return true; if (o == null || getClass() != o.getClass()) return false; Student student = (Student) o; return age == student.age && Objects.equals(name, student.name); } @Override protected Object clone() throws CloneNotSupportedException { return super.clone(); } @Override public String toString() { return "Student{" + "name='" + name + '\'' + ", age=" + age + '}'; } public Student(String name, int age) { this.name = name; this.age = age; } public String getName() { return name; } public void setName(String name) { this.name = name; } public int getAge() { return age; } public void setAge(int age) { this.age = age; } }import java.lang.reflect.Array; import java.util.ArrayList; public class demo1 { public static void main(String[] args) throws CloneNotSupportedException { Student s1= new Student("刘宁",21); // toString 返回对象的字符串表示形式 // 开发中一般会在类中重写 System.out.println(s1.toString()); // equals 判断俩个对象是否相等 默认比较地址 // 开发中一般会重写 Student s2=new Student("刘宁",21); System.out.println(s2.equals(s1)); System.out.println(s2 == s1); // protected Object clone(): 对象克隆 // 当某个对象调用该这个方法时,这个方法会复制一个一摸一样的新对象返回 // alt+回车 添加到异常签名 Student s3=(Student) s1.clone(); System.out.println(s3.toString()); } }- 浅克隆:拷贝出的新对象,与原对象中的数据一摸一样,(引用类型拷贝的只是地址)
- 深克隆:对象中基本类型的数据直接拷贝,字符串数据拷贝的还是地址,还包含的其他对象,不会拷贝地址,会创建新的对象
-
// equals 先做非空判断,再比较俩个对象 String ss1="heiheihei"; String ss2="heiheihei"; ss1.equals(ss2); System.out.println(Objects.equals(ss1, ss2)); // isNull 判断对象是否为null 为null返回true,反之false // noNull
包装类
-
包装类就是把基本类型的数据包装成为对象
基本数据类型 对应的包装类 byte Byte short Short int Integer long Long char Character float Float double Double boolean Boolean // 以Integer为例 //已经过时 public Integer(int value) //合适 public static Integer valueOf(int i) Integer a2=Integer.valueOf(12); //自动装箱 Integer a3=12; //自动拆箱:自动把包装类型的对象转换成对应的基本数据类型 int a4=a3; -
泛型和集合不支持基本数据类型,之恶能支持引用数据类型,需要使用包装类
-
ArrayList <Integer> list = new ArrayList<>(); list.add(12); int rs=list.get(0); //发生自动拆箱 -
包装类其他常见操作
-
可以把基本类型的数据转换成为字符串类型
public static String toString(double d) public String toString()Integer a=23; String rs1=Integer.toString(a); //"23" System.out.println(rs1+1);//231 String rs2=a.toString(); -
可以把字符串类型的数值转换成数值本身对应的数据类型
public static int parseInt(String s) publci static Integer valueOf(String s)String ageStr="29";//不能参与运算 //int agei=Integet.parseInt(ageStr); int agei=Integet.valueOf(ageStr); agei=agei+1;//30 String scoreStr="99.5"; //double score=Double.parseDouble(scoreStr);//99.5 double score=Double.valueOf(scoreStr);//99.5
-
StringBuilder
- 代表可变字符串对象,相当于一个容器,它里面装的字符串是可以改变的,就是用来操作字符串的
- 好处:StringBuilder比String更适合做字符串的修改操作,效率会更高,代码也会更简洁
//可以创建空白,也可以创建指定
StringBuilder ss=new StringBuilder(); //ss ""
StringBuilder s=new StringBuilder("zhenhao");//ss "zhenhao"
//拼接内容 append 添加对象并返回对象本身
s.append(12);
//返回字符串长度
s.length();
//反转操作
s.reverse();
//把StringBuilder转换成String
s.toString();
StringBuilder与StringBuffer操作一摸一样
但是StringBuilder线程不安全 StringBuffer线程安全
StringJoiner
StringBuilder一样,也可以看作容器
不仅能提高字符串的操作效率,在有些场景下
//构造器
public StringJoiner(间隔符号) //创建一个对象,指定拼接时的间隔符号
public StringJoiner(间隔符号,开始符号,结束符号)//
//方法
public StringJoiner add(添加的内容) //添加数据 返回对象本身
public int length() //返回长度
public String toString() //返回字符串
Math
-
代表数学,是一个工具类,里面提供的都是对数据进行操作的一些静态方法
public class Main { public static void main(String[] args) { // public static int abs(int a) // public static double abs(double a) // 取绝对值 System.out.println(Math.abs(-12)); //12 System.out.println(Math.abs(123)); //123 System.out.println(Math.abs(-3.14)); //3.14 // public static double ceil(double a) // 向上取整 System.out.println(Math.ceil(4.0001)); //5.0 System.out.println(Math.ceil(4.0)); //4.0 // public static double floor(double a) // 向下取整数 System.out.println(Math.floor(4.999)); //4.0 System.out.println(Math.floor(4.0)); //4.0 // public static long round(double a) // 四舍五入 System.out.println(Math.round(4.4999)); //4 // public static int max(int a,int b) // public static int min(int a,int b) // 取较大值和较小值 System.out.println(Math.max(10,20));//20 System.out.println(Math.min(10,20));//10 // public static double pow(double a,double b) // 取次方 System.out.println(Math.pow(2,3)); //2的三次方 // public static double random() // 取随机数【0.0,1.0) System.out.println(Math.random()); } }
System
-
代表程序所在的系统,也是一个工具类
public class Main { public static void main(String[] args) { // public static void exit(int status) // 中止当前运行的Java虚拟机 // 该参数使用状态码,非零状态码表示异常终止 System.exit(0); // 人为终止虚拟机(不可使用) // public static long currentTimeMillis() // 获取当前系统时间 // 返回的是long类型的时间毫秒值,值从1970-1-1 0:0:0到现在的毫秒值,1s=1000ms long time =System.currentTimeMillis(); System.out.println(time); for (int i = 0; i < 1000000; i++) { System.out.println("输出了:"+i); } long time1=System.currentTimeMillis(); System.out.println("使用时间:"+((time1-time)/1000)+"s"); } }
Runtime
-
代表程序所在的运行环境
-
Runtime是一个单例类
import java.io.IOException; public class Main { public static void main(String[] args) throws IOException { // public static Runtime getRuntime() // 返回当前java应用程序关联的运行时对象 Runtime runtime=Runtime.getRuntime(); System.out.println(runtime); // public void exit(int status) // 终止当前运行的java虚拟机 runtime.exit(0); // public int availableProcessors() // 获取虚拟机额能够使用的处理器数量 System.out.println(runtime.availableProcessors()); // public long totalMemory() // 返回java虚拟机总的内存数量 System.out.println(runtime.totalMemory()/1024.0/1024.0+"MB"); // public long freeMemory() // 返回java虚拟机中的可用内存量 System.out.println(runtime.freeMemory()); // public Process exec(String command) // 启动某个程序,并返回代表该程序的对象 runtime.exec("D:\\QQNT\\QQ.exe"); Thread.sleep(5000);//程序暂停5s再进继续往下走 process.destroy(); //关闭程序 } }
BigDecimal
-
解决小数运算失真问题
import java.io.IOException; import java.math.BigDecimal; import java.math.RoundingMode; public class Main { public static void main(String[] args) throws IOException, InterruptedException { double a=0.1; double b=0.2; double c=a+b; //0.30000000000000004 System.out.println(c); // 构造器 // public BigDecimal (String val) // 把他们变成字符串再封装为BigDecimal对象来进行运算 BigDecimal a1=new BigDecimal(Double.toString(a)); // 推荐使用valueOf BigDecimal b1=new BigDecimal.valueOf(b); BigDecimal c1=a1.add(b1);//加法 BigDecimal c1=a1.subtract(b1);//减法 BigDecimal c1=a1.multiply(b1);//乘法 BigDecimal c1=a1.divide(b1);//除法 BigDecimal c1=a1.divide(b1,2, RoundingMode.HALF_UP);//除法 保留位数,舍入模式 double rs=c1.doubleValue(); //转换BigDecimal为double类型数据 System.out.println(rs); } }
Date日期
-
构造器
Date() Date(long date) -
方法
import java.io.IOException; import java.math.BigDecimal; import java.math.RoundingMode; import java.util.Date; public class Main { public static void main(String[] args) throws IOException, InterruptedException { // 创建date对象 Date date=new Date(); System.out.println(date); //当前系统时间 // 拿到时间毫秒值 long time = date.getTime(); System.out.println(time); // 把时间毫秒值转换成日期对象,2s之后的时间是多少 time+=2*1000; Date date1=new Date(time); System.out.println(date1); // 直接把日期对象的时间通过setTime方法进行修改 Date date2=new Date(); date2.setTime(time); System.out.println(date2); } }
SimpleDateFormat
-
代表简单日期格式化,可以用来把日期对象,时间毫秒值格式化成为我们想要的形式
////日期对象转换为字符串 import java.text.SimpleDateFormat; import java.util.Date; import java.util.SimpleTimeZone; public class Main { public static void main(String[] args) throws IOException, InterruptedException { Date date=new Date(); long time=date.getTime(); System.out.println(date); System.out.println(time); //Tue Feb 06 11:44:03 CST 2024 //1707191043425 SimpleDateFormat sdf=new SimpleDateFormat("yyyy-MM-dd HH:mm:ss EE a"); String Date=sdf.format(date); System.out.println(Date); //2024-02-06 11:44:03 周二 上午 String Date2=sdf.format(time); System.out.println(Date2); //2024-02-06 11:46:21 周二 上午 } }//字符串解析为对象 import java.text.SimpleDateFormat; import java.util.Date; import java.util.SimpleTimeZone; public class Main { public static void main(String[] args) throws IOException, InterruptedException, ParseException { String dateStr="2024-2-6 12:12:12"; // 指定时间格式与被解析时间格式一摸一样 SimpleDateFormat sdf2=new SimpleDateFormat("yyyy-MM-dd HH:mm:ss"); Date d2=sdf2.parse(dateStr); System.out.println(d2); } }
秒杀活动
import java.text.ParseException;
import java.text.SimpleDateFormat;
import java.util.Date;
public class demo {
public static void main(String[] args) throws ParseException {
String start="2024年11月11日 0:0:0";
String end="2024年11月11日 0:10:0";
String xj="2024年11月11日 0:01:18";
String xp="2024年11月11日 0:04:18";
// 解析为日期对象
SimpleDateFormat sdf=new SimpleDateFormat("yyyy年MM月dd日 HH:mm:ss");
Date Start=sdf.parse(start);
Date End=sdf.parse(end);
Date Xj=sdf.parse(xj);
Date Xp=sdf.parse(xp);
// 判断是否秒杀成功 将对象转换为时间毫秒值来进行判断
long sT=Start.getTime();
long eT= End.getTime();
long jT=Xj.getTime();
long pT= Xp.getTime();
if (jT>=sT&&jT<=eT){
System.out.println("小贾秒杀成功");
}else {
System.out.println("小贾秒杀失败");
}
if (pT>=sT&&pT<=eT){
System.out.println("小皮秒杀成功");
}else {
System.out.println("小皮秒杀失败");
}
}
}
Calendar
- 需求:将2024年2月新增加一个月
- 代表系统此刻时间对应的日历
- 通过它可以单独获取、修改时间中的年、月、日、时、分、秒
import java.util.Calendar;
import java.util.Date;
import java.util.SimpleTimeZone;
public class Main {
public static void main(String[] args) throws IOException, InterruptedException, ParseException {
// 得到系统此刻时间对应的日历对象
Calendar now=Calendar.getInstance();
System.out.println(now);
// 获取日历中的某个信息
now.get(Calendar.YEAR);
now.get(Calendar.DAY_OF_YEAR);
// 拿到日历中记录的日期对象
Date d=now.getTime();
// 拿到时间毫秒值
long Time=now.getTimeInMillis();
// 修改日历中的某个信息
now.set(Calendar.YEAR,9);//修改年份为10
// 为某个信息增加或减少指定值
now.add(Calendar.YEAR,100);
}
}
- 他是可变对象,一旦修改后其对象本身表示的时间会产生变化
JDK8新增日期、时间
-
代替Calendar
-
LocalDate:年月日
import java.time.LocalDate; public class NewDate { public static void main(String[] args) { // 获取本地日期对象 使用的时now方法 LocalDate localDate=LocalDate.now(); System.out.println(localDate); // 获取日期对象中的信息 int year=localDate.getYear();//年 int month= localDate.getMonthValue();//月 int day=localDate.getDayOfMonth();//日 int dayOfYear=localDate.getDayOfYear();//一年中的第几天 int dayOfWeek=localDate.getDayOfWeek().getValue();//星期几 // 直接修改某个信息 会返回一个新的对象 LocalDate localDate1=localDate.withYear(2077); System.out.println(localDate1); // 把某个信息加/减多少 LocalDate localDate2=localDate.plusDays(11); LocalDate localDate3=localDate.minusDays(111); // 获得指定日期的LocalDate对象 LocalDate localDate4=LocalDate.of(2077,12,12); // 判断俩个日期是否相等 localDate1.equals(localDate2); localDate1.isBefore(localDate4); localDate1.isAfter(localDate4); } } -
LocalTime:时分秒
方法与LocalDate方法类似 -
LocalDateTime:年月日时分秒
//其他方法: //可以将LocalDateTime对象转换成为LocalDate和LocalTime LocalDate ld=ldt.toLocalDate(); LocalTime lt=ldt.toLocalTime(); LocalDateTime ldt=LocalDateTime.of(ld,lt); -
ZoneId:时区
-
ZonedDateTime:带时区的时间
import java.time.Clock; import java.time.LocalDate; import java.time.ZoneId; import java.time.ZonedDateTime; public class NewDate { public static void main(String[] args) { // public static ZoneId systemDefault() 获取默认时区 ZoneId zoneId=ZoneId.systemDefault(); System.out.println(zoneId);// Asia/Shanghai // public static Set<String> getAvailableZoneIds():获取java支持的全部时区id System.out.println(ZoneId.getAvailableZoneIds()); // public static ZoneId of(String zoneId) 把某个时区id封装成ZoneId对象 ZoneId zoneId1=ZoneId.of("America/New_York"); // public static ZoneDateTime now(ZoneId zone):获取某个时区的ZoneDateTime对象 ZonedDateTime now=ZonedDateTime.now(zoneId1); System.out.println(now);//该时区时间 // 世界标准时间 ZonedDateTime now1=ZonedDateTime.now(Clock.systemUTC()); System.out.println(now1); // 获取系统默认时区的ZoneDateTime对象 ZonedDateTime now3=ZonedDateTime.now(); // 一些方法几乎通用 } }
-
-
代替Date
-
Instant 时间线上的某个时刻/时间戳
通过获取Instant的对象可以拿到此刻的时间,该时间由俩部分组成:从1970-01-01 00:00:00开始走到此刻的总秒数+不够1s的纳秒数
import java.time.*; //通常用来作性能分析 //用来记录用户操作某个事件的时间点 public class NewDate { public static void main(String[] args) { // 创建Instant对象,获得此刻时间信息 Instant instant=Instant.now(); // 获得总秒数 long second= instant.getEpochSecond(); // 不够1s的纳秒数 int nano=instant.getNano(); // 加/减多少s Instant instant1=instant.plusNanos(11); Instant instant1=instant.minusNanos(11); // 前面的常用方法同样适用 } }
-
-
代替SimpleDateFormate
DateTimeFormatter:格式化器,用于时间的格式化、解析
(线程安全)
import java.time.*; import java.time.format.DateTimeFormatter; public class NewDate { public static void main(String[] args) { // 获取格式化器对象 DateTimeFormatter dateTimeFormatter=DateTimeFormatter.ofPattern("yyyy年MM月dd日 HH:mm:ss"); // 对时间进行格式化 LocalDateTime localDateTime=LocalDateTime.now(); String rs=dateTimeFormatter.format(localDateTime); System.out.println(rs); // 另一种方法 String st=localDateTime.format(dateTimeFormatter); // 解析时间一般使用LocalDateTime提供的解析方法来进行解析 LocalDateTime ldt=LocalDateTime.parse(rs,dateTimeFormatter); System.out.println(ldt); } } -
其他补充:
-
Period:计算日期间隔(年月日)(LocalDate对象)
-
Duration:计算时间间隔(时分秒纳秒)
import java.time.*; import java.time.format.DateTimeFormatter; public class NewDate { public static void main(String[] args) { // 创建period对象 LocalDate startt=LocalDate.of(202,8,12); LocalDate endd=LocalDate.of(201,11,30); Period period=Period.between(startt,endd); period.getDays(); period.getMonths(); period.getYears(); // 创建Duration对象 // 支持LocalDateTime,LocalTime,Instant Duration duration=Duration.between(startt,endd); // 获取俩个时间对象间隔信息 duration.toDays(); duration.toHours(); duration.toMinutes(); duration.toMillis(); duration.toNanos(); } }
-
Arrays类
用来操作数组的一个工具类
import java.util.Arrays;
import java.util.function.IntToDoubleFunction;
public class arrays {
public static void main(String[] args) {
// public static String toString(类型[] arr)
// 返回数组内容
int[] arr={10,20,30,40,50,60};
Arrays.toString(arr);
// public static int[] copyOfRange(类型[] arr,起始索引,结束索引)
// 拷贝数组,包前不包后
int[] arr1=Arrays.copyOfRange(arr,1,4);
System.out.println(arr1);
// public static copyOf(类型[] arr, int newLength)
// 拷贝数组,可以指定新数组的长度
int[] arr2=Arrays.copyOf(arr,10);
// public static setAll(double array,IntToDoubleFunction generator)
/// 把数组中的原数据改为新数据又存进去
// 打折促销
double[] prices={66.6,77.7,88.8};
Arrays.setAll(prices, new IntToDoubleFunction() {
@Override
public double applyAsDouble(int value) {
return prices[vlaue]*0.8;
}
});
// public static void sort(类型[] arr)
// 对数组进行排序 默认为升序
Arrays.sort(prices);
}
}
如果数组中存储为对象,如何进行排序?
-
方法一:让该对象的类实现Comparable(比较规则)接口,然后重写compareTo方法,自己来制定比较规则
public int compareTo(Student o){ //约定1:左边对象大于右边对象 返回正整数 //约定2:左边对象小于右边对象 返回负整数 //约定3;左边对象等于右边对象 返回0 /* if(this.age>o.age){ return 1; }else if(this.age<0.age){ return -1; } return 0; */ //可等价替换为 //升序 return this.age-o.age; //降序 return o.age-this.age; } -
方法二:使用下面这个sort方法,创建Comparator比较器接口的匿名内部类对象,然后自己制定比较规则
public static <T> void sort(T[] arr,Comparator<?super T>c)Arrays.sort(students, new Comparator<Object>() { @Override public int compare(Student o1, Student o2) { // 制定比较规则 // 规则约定与Comparator一致 // 注意double类型不可以直接减法 /* if(o1.score>o2.score){ return 1; }else if(o1.score<o2.score){ return -1; } return 0; */ //double类型比较可等价替换为: return Double.compare(o1.score,o2.score); } });
Lambda
-
用于简化匿名内部类的代码写法
-
格式
(被重写方法的形参列表)->{ 被重写方法的方法体代码 }public class lambda { public static void main(String[] args) { Animal a=new Animal() { @Override public void run() { System.out.println("狗跑的快"); } }; a.run(); // 前提:Lambda并不能简化全部匿名内部类,只能简化函数式接口 Swimming b=()->{ System.out.println("学生游泳"); }; b.swim(); } } interface Swimming{ void swim(); } abstract class Animal{ public abstract void run(); }- 什么是函数式接口?
- 有且仅有一个抽象方法的接口
- 将来我们见到的大部分函数式接口,上面都可能会有一个@Functionallnterface的注解
- 什么是函数式接口?
-
Lambda表达式省略规则
- 参数类型可以省略不写
- 如果只有一个参数,参数类型可以省略,小括号也可以省略
- 如果方法体代码只有一行代码,可以省略大括号、分号、return
Arrays.setAll(prices, new IntToDoubleFunction() { @Override public double applyAsDouble(int value) { return prices[vlaue]*0.8; } }); Arrays.setAll(prices,(int value)->{ return prices[value]0.8; }); Arrays.setAll(prices,(value)->{ return prices[value]*0.8; }); Arrays.setAll(prices,value->{ return prices[value]*0.8; }); Arrays.setAll(prices,vale->prices[value]*0.8);
正则表达式
作用一:用来校验数据格式是否合法
-
需求:检验QQ号是否正确,要求全部是数字,长度为6-10位,不能以0为开头
-
package text; public class text1 { public static void main(String[] args) { System.out.print(checkqq(null)); System.out.print(checkqq("25142546")); System.out.print(checkqq("01142546")); System.out.print("-----------------"); System.out.print(checkqq1("01142546")); System.out.print(checkqq(null)); } public static boolean checkqq(String qq) { if (qq == null||qq.startsWith("0")||qq.length()<6||qq.length()>10) { return false; } for (int i = 0; i < qq.length(); i++) { char ch = qq.charAt(i); if (ch<'0'||ch>'9') { return false; } } return true; } //对比 public static boolean checkqq1(String qq) { return qq != null && qq.matches("[1-9]\\d{5,9}"); } } -
书写规则:
.matches[abc] a或bc [^abc]除abc \w 单词字符a-z A-Z 0-9 贪婪量词 ?一次或根本不一次 * 零次或多次 + 一次或多次 {n}正好n次 {n,}至少n次 {n,m}至少n但不超过m次 -
应用
public class checkphone {
public static void main(String[] args){
checkphone();
}
public static void checkphone(){
while (true) {
System.out.println("请输入您的联系方式:\n");
Scanner sc = new Scanner(System.in);
String phone = sc.nextLine();
if (phone.matches("(1[3-9]\\d{9})|(0\\d{2,7}-?[1-9]\\d{4,19})")){
System.out.println("您输入的号码格式正确");
break;
}else {
System.out.println("您输入的号码格式不正确");
}
}
}
}
作用二:一段文本中查找满足要求的内容
- 需求:将下面文本中的电话,邮箱,座机号码爬取出来
public static void main(String[] args){
paqu();
}
public static void paqu{
String data = "天津理工大学信息安全刘宁\n" +
"电话:12345678754\n" +
"邮箱:liuning@123.com\n" +
"座机:010-123456";
//1.定义爬取规则
String regex="(1[3-9]\\d{9})|(0\\d{2,7}-?[1-9]\\d{4,19})|(\\w{2,}@(\\w{2,20}(\\.\\w{2,10}){1,2}))";
//2.把正则表达式封装为对象
Pattern pattern = Pattern.compile(regex);
//3.通过pattern对象去获取查找内容的匹配器对象
Matcher matcher = pattern.matcher(data);
//4.定义一个循环开始爬取信息
while(matcher.find()){
System.out.println(matcher.group());
}
作用三:搜索替换、分割内容
//搜索替换内容
public String replaceALL(String regex,String newStr);
//分割内容并返回字符串
public String[] split(String regex);
-
需求:替换非中文字符为—
public class text1 { public static void main(String[] args) { String s1 = "中文1234很好aaa123学习"; System.out.println(s1.replaceAll("\\w+", "-")); } } -
需求:将口吃的人说的话优化
public class text1 { public static void main(String[] args) { String s1 = "我我我我我我喜喜喜喜欢欢欢编程"; System.out.println(s1.replaceAll("(.)\\1+", "$1")); //(.)一组 .匹配任意字符 //\\1 为这个组声明一个组号 // +必须是重复的字 //$1 取到第一个字符 } }Part 05 集合进阶概述
俩大体系
- 单列集合:以Collection为代表,每个元素只包含一个值
- 双列集合:以Map为代表,每个元素包含俩个值(键值对)
Collection
- List:添加的元素是有序、可重复、有索引的
- ArryList、LinekList:有序、可重复、有索引
- Set:添加的元素的无序的、不重复的、无索引的
- HashSet:无序、不重复、无索引
- LinkedHashSet:有序,不重复,无索引
- TreeSet:按照大小默认升序排序、不重复、无索引
public static void main(String[] args) {
ArrayList<String> list = new ArrayList<>();// 有序可重复有索引
list.add("java1");
list.add("java2");
list.add("java1");
list.add("java2");
System.out.println("ArrayList:" + list);
HashSet<String> set = new HashSet<>();
set.add("java1");
set.add("java2");
set.add("java1");
set.add("java3");
System.out.println("HashSet:"+set);
}
//结果
ArrayList:[java1, java2, java1, java2]
HashSet:[java3, java2, java1]
Collection常用方法(单列集合的祖宗)
public static void main(String[] args) {
Collection<String> c=new ArrayList<>();
//1-add方法 添加成功返回true,失败返回false
c.add("java1");
c.add("java2");
System.out.println("add:"+c);
//2-clear 清空元素集合
c.clear();
System.out.println("clear:"+c);
//3-isEmpty()判断集合是否为空 空为true 非空为false
System.out.println(c.isEmpty());
c.add("java2");
System.out.println(c.isEmpty());
//4-size() 集合大小
System.out.println(c.size());
//5-contains() 判断是否包含某个元素
c.add("java1");
c.contains("java1");
//6-remove() 删除某个元素,如有多个删除第一个
c.add("java1");
c.remove("java1");
System.out.println("remove:"+c);
//7-toArray() 把集合转变为数组
Object[] object=c.toArray();
System.out.println(Arrays.toString(object));
System.out.println("------------------------");
//8-把一个集合的全部数据导入到另一个集合中去
Collection<Object> c1=new ArrayList<>();
c1.add("java1");
c1.add("java2");
Collection<Object> c2=new ArrayList<>();
c2.add("java3");
c2.add("java4");
c1.addAll(c2);
System.out.println("addAll:"+c1);
}
//结果:
add:[java1, java2]
clear:[]
true
false
1
remove:[java2, java1]
[java2, java1]
------------------------
addAll:[java1, java2, java3, java4]
Collection遍历方式
迭代器
迭代器是专门用来遍历集合的专用方式(数组没有迭代器),在java中迭代器的代表是Iterator;
获取迭代器方法:
Iterator<E> iterator() 返回集合中的迭代器对象,该迭代器对象默认指向当前集合的第一个元素
常用方法:
boolean hasNext() 询问当前位置是否有元素存在,存在返回true,不存在返回false
E next() 获取当前位置的元素,并同时将迭代器对象指向下一个元素处
public static void main(String[] args) {
Collection<String> collection = new ArrayList<>();
collection.add("nobody");
collection.add("zmjjkk");
collection.add("simon");
collection.add("chichoo");
collection.add("smoggy");
System.out.println(collection);
//迭代器遍历
Iterator<String> it= collection.iterator();
while (it.hasNext()) {
String stp=it.next();
System.out.println(stp);
}//如果迭代器移动次数多于数据量,会有报错信息
}
结果显示:
[nobody, zmjjkk, simon, chichoo, smoggy]
nobody
zmjjkk
simon
chichoo
smoggy
增强for循环(数组或集合)
迭代器遍历集合的简化写法
格式:
for(元素的数据类型 变量名:数组或者集合){
}
public class text1 {
public static void main(String[] args) {
Collection<String> collection = new ArrayList<>();
collection.add("nobody");
collection.add("zmjjkk");
collection.add("simon");
collection.add("chichoo");
collection.add("smoggy");
System.out.println(collection);
//增强for遍历
for (String str : collection) {
System.out.println(str);
}
}
lambda表达式(遍历map尤为明显简洁)
方法名称
default void forEach(Consumer<? super T>action) 集合lambda遍历集合
public class text1 {
public static void main(String[] args) {
Collection<String> collection = new ArrayList<>();
collection.add("nobody");
collection.add("zmjjkk");
collection.add("simon");
collection.add("chichoo");
collection.add("smoggy");
System.out.println(collection);
//复杂
collection.forEach(new Consumer<String>() {
@Override
public void accept(String s) {
System.out.println(s);
}
});
// 最终简化
collection.forEach(System.out::println);
}
遍历案例:展示多部电影信息
-
需求:展示多部电影信息
-
分析
-
每部电影是一个对象,多部电影要用集合装起来
-
遍历集合中的三个电影对象,输出每部电影详情信息
public class movie { private String name; private double score; private String actor; public String getName() { return name; } public void setName(String name) { this.name = name; } public double getScore() { return score; } public void setScore(double score) { this.score = score; } public String getActor() { return actor; } public void setActor(String actor) { this.actor = actor; } public movie(String name, double score, String actor) { this.name = name; this.score = score; this.actor = actor; } public movie() { } }public class text1 { public static void main(String[] args) { Collection<movie> movies = new ArrayList<>(); movies.add(new movie("肖申克的救赎",9.7,"罗宾斯")); movies.add(new movie("霸王别姬",9.6,"张国荣")); movies.add(new movie("阿甘正传",9.5,"汉克斯")); System.out.println(movies); //集合存储对象地址 for(movie m : movies){ System.out.println("电影名:"+m.getName()); System.out.println("电影评分:"+m.getScore()); System.out.println("主演:"+m.getActor()); } } //结果: [text.movie@b4c966a, text.movie@2f4d3709, text.movie@4e50df2e] 电影名:肖申克的救赎 电影评分:9.7 主演:罗宾斯 电影名:霸王别姬 电影评分:9.6 主演:张国荣 电影名:阿甘正传 电影评分:9.5 主演:汉克斯
-
main方法在栈内存中执行,创建arrlist在堆内存中创建容器对象
创建电影对象在堆内存中,然后将堆内存中对象的地址给到movies集合位置
集合中存储的是元素的地址信息!!!!
List集合
特点及特有方法
- 有序,可重复,有索引
- ArrayList:有序,可重复,有索引
- LinkedList:有序,可重复,有索引
- 支持索引,多了很多索引相关的方法
- void add(int index,E element) 在此集合中的指定位置插入指定元素
- E remove(int index) 删除指定索引处的元素,返回被删除元素
- E set(int index,E element) 修改指定索引处的元素,返回被修改的元素
- E get(int index) 返回指定索引处的元素
- E set (int index,E element) 修改索引处位置,返回原先数据
public static void main(String[] args) {
List<String> list = new ArrayList<String>();
list.add("蜘蛛精");
list.add("至尊宝");
list.add("至尊宝");
list.add("紫霞仙子");
list.add("青霞仙子");
System.out.println(list);
list.add(1,"红孩儿");
System.out.println(list);
list.remove(2);
System.out.println(list);
System.out.println(list.get(1));
System.out.println(list.set(2,"牛夫人"));
System.out.println(list);
}
//结果:
[蜘蛛精, 至尊宝, 至尊宝, 紫霞仙子, 青霞仙子]
[蜘蛛精, 红孩儿, 至尊宝, 至尊宝, 紫霞仙子, 青霞仙子]
[蜘蛛精, 红孩儿, 至尊宝, 紫霞仙子, 青霞仙子]
红孩儿
至尊宝
[蜘蛛精, 红孩儿, 牛夫人, 紫霞仙子, 青霞仙子]
遍历方法
public static void main(String[] args) {
List<String> list = new ArrayList<String>();
list.add("蜘蛛精");
list.add("至尊宝");
list.add("紫霞仙子");
list.add("青霞仙子");
//for循环遍历
for(String s:list){
System.out.println(s);
}
//迭代器
Iterator<String> iterator = list.iterator();
while(iterator.hasNext()){
System.out.println(iterator.next());
}
//lamada
list.forEach(System.out::println);
}
//结果:
蜘蛛精
至尊宝
紫霞仙子
青霞仙子
ArrayList集合的底层原理:
-
基于数组实现
-
特点:
- 查询速度快:查询数据通过地址值和索引定位
- 删除效率低:可能需要把后面很多的数据向前移动
- 添加效率极低:可能需要把很多数据后移,或者也可能需要进行数据的扩容
-
构造方式:
- 使用无参构造器创建的集合,会在底层创建一个默认长度为0的数组
- 添加一个元素时,底层会创建一个新的长度为10的数组
- 存满时,会扩容1.5倍
- 如果一次添加多个元素,1.5倍还放不下,新创建数组的长度以实际为准
-
使用场景:
- 根据索引查询数据,数据量不是很大
- 数据量很大,频繁进行增删操作
LinkedList底层原理
-
基于双链表实现
-
特点:
-
查询慢,增删相对较快,但对首尾元素进行怎删改查的速度是极快的
-
新增了很多首尾操作的特有方法
-
public void addFirst(E e) 在列表开头插入指定数据 Public void addLast(E e) 在指定的元素追加到此列表的末尾 public E getFirst() public E getLast() public E removeFirst() public E removeLast()
-
-
应用场景:
-
可以用来设计队列(叫号系统,排队系统)
public static void main(String[] args) { LinkedList<String> queue = new LinkedList<>(); //入队 queue.addLast("第一号人"); queue.addLast("第二号人"); queue.addLast("第三号人"); System.out.println(queue); //出队 System.out.println(queue.removeFirst()); System.out.println(queue.removeFirst()); System.out.println(queue.removeFirst()); } // 结果: [第一号人, 第二号人, 第三号人] 第一号人 第二号人 第三号人 -
可以用来设计栈
public static void main(String[] args) { LinkedList<String> stack = new LinkedList<>(); //入栈 stack.push("第一号人"); stack.push("第二号人"); stack.push("第三号人"); System.out.println(stack); //出栈 System.out.println(stack.pop()); System.out.println(stack.pop()); System.out.println(stack.pop()); } //结果: [第一号人, 第二号人, 第三号人] 第三号人 第二号人 第一号人 -
set集合
特点及特有方法:
-
添加元素无序,不重复,无索引
- Hashset:无序,不重复,无索引
- LinkedHashSet:有序,不重复,无索引
- TreeSet:排序(默认升序),不重复,无索引
public static void main(String[] args) { //创建hashset集合对象 //接口不能new对象,要找实现类 //经典代码 //只会无序一次 Set<Integer> set = new HashSet<>(); set.add(666); set.add(555); set.add(555); set.add(777); set.add(888); System.out.println(set); Set<Integer> set1 = new LinkedHashSet<>(); set1.add(666); set1.add(555); set1.add(555); set1.add(777); set1.add(888); System.out.println(set1); Set<Integer> set2= new TreeSet<>(); set2.add(666); set2.add(555); set2.add(555); set2.add(777); set2.add(888); System.out.println(set2); } //结果: [888, 777, 666, 555] [666, 555, 777, 888] [555, 666, 777, 888] -
几乎无特有方法
HashSet集合底层原理
前置知识:
哈希值:int 类型的数值,java中每个对象都有一个哈希值
java中的所有对象,都可以调用hashcode方法,返回自己的哈希值
特点:
同一对象多次调用hashcode方法返回的哈希值是相同的
不同对象,他们的哈希值一般不相同,但也与可能对相同(哈希碰撞)
-
基于哈希表实现
-
特点:
- 增删改查性能都较好的数据结构
- jdk8之前:数组+链表///jdk8之后:数组+链表+红黑树
-
构造方法
-
第一次创建默认长度为16的数组,默认加载因子为0.75,数组名table
-
使用元素的哈希值对数组的长度求余计算出应存入的位置
-
判断当前位置是否为null,如果是null,则直接存入
-
如果不为null,调用equals方法比较:如果相等,不存入,否则存入
-
新元素会直接挂在老元素下面(jdk8之后)
-
新元素存入数组,占用老元素位置,老元素挂下面(jdk8之前)
-
当链表长度超过8,且数组长度>=64时,自动将链表转为红黑树
-
Hashset去重复机制:hash值+equals
-
LinkedHashSet底层原理
- 依然是基于哈希表实现
- 多了一个双链表机制记录前后元素的位置
TreeSet底层原理
-
不重复,无索引,可排序(按元素大小默认升序排序)
-
底层基于红黑树实现排序
-
对于自定义类型对象,TreeSet无法直接使用排序
- 自定义排序规则一:实现Comparable接口,重写compareTo方法来指定比较规则
- 通过TreeSet集合有参数构造器,可以设置Comparator对象(比较器对象,用于指定比较规则)
补充知识:
集合的并发修改异常问题
-
使用迭代器遍历集合时,又同时在删除集合中的数据,程序就是出现错误异常
-
使用迭代器的it.remove()来删除
-
for (int i=0 ;i<list.size();i++){ String name =list.get(i); if(name.contaions(“李”)){ lsit.remove(name); i--; } }
-
可变参数:
- 一种特殊形参,定义在方法,构造器的形参列表里,格式是数据类型…参数名称;
- 特点:可以不传参,也可以同时传多个参数
Collections(工具类)
-
一个用来操作集合的工具类
方法名称 说明 public static boolean addAll(Collection <?super T>c,T…elemetns) 给集合批量添加元素 public static void shuffle(List <?> list) 打乱List集合中的元素数据 public static void sort(List list) 对List集合中的元素进行升序排序 public static void sort(List list ,Comparator<? super T> c) 对List集合中的元素,按照比较器对象指定的规则及逆行排序 public static void main(String[] args) { //1.批量添加数据 List<String> names = new ArrayList<>(); List<String> ages = new ArrayList<>(); Collections.addAll(names,"张三","王五","李四","牛二"); System.out.println(names); //2.打乱元素顺序 只能List Collections.shuffle(names); System.out.println(names); //3.升序排序 只能list,一般不能对对象直接排序,需要重写compareTo方法 Collections.addAll(ages,"2","1","3"); Collections.sort(ages); System.out.println(ages); //4.comparator Collections.sort(students, new Comparator<Student>() { @Override public int compare(Student s1,Student s2){ return Double.compare(s1.getage(),s2.getage()); } });
项目实战:斗地主游戏开发
业务需求:
- 总共有54张牌
- 点数3,4,5,6,7,8,9,10,J,Q,K,A,2
- 花色:♣,♠,♥,♦
- 大小王:👨,👩
- 斗地主:发出51张牌,剩下三张作为底牌
分析实现:
- 在启动游戏后,应该提前准备好54张牌
- 接着,完成洗牌,发牌,对牌排序,看牌等操作
Card类:
package popker;
public class Card {
private String Number;
private String Color;
private int Size; //每张牌的大小
@Override //重写toString
public String toString() {
return getColor() + getNumber() + "----》" + getSize();
}
public Card() {//无参构造器
}
public Card(String number, String color, int size) {//有参构造器
Number = number;
Color = color;
Size = size;
}
public String getColor() {
return Color;
}
public void setColor(String color) {
Color = color;
}
public int getSize() {
return Size;
}
public void setSize(int size) {
Size = size;
}
public String getNumber() {
return Number;
}
public void setNumber(String number) {
Number = number;
}
}
Room类
package popker;
import java.util.ArrayList;
import java.util.Collections;
import java.util.Comparator;
import java.util.List;
public class Room {//创建一个房间,内有一副牌
//必须有一副牌
private List<Card> allCards = new ArrayList<Card>();
//无参构造器
public Room(){
//1.做出54张牌,存入带allCards中
//点数、个数、类型确定
String[] numbers={"3","4","5","6","7","8","9","10","J","Q","K","A","2"};
//花色
String[] Colors={"♣","♠","♥","♦"};
int size=0;
//先遍历点数,再遍历花色
for (String number : numbers) {
size++;
for (String color : Colors) {
Card card = new Card(number,color,size);
allCards.add(card);
}
}
Card c1=new Card("","\uD83D\uDC68",++size);
Card c2=new Card("","\uD83D\uDC69",++size);
Collections.addAll(allCards,c1,c2);
System.out.println("这是一副新牌:");
System.out.println(allCards);
}
//牌排序算法
private void sortCards(List<Card> cards) {
Collections.sort(cards,new Comparator<Card>() {
@Override
public int compare(Card o1, Card o2) {
return o1.getSize()-o2.getSize();
}
});
}
public void start() {
//1.洗牌
Collections.shuffle(allCards);
System.out.println("洗牌");
System.out.println(allCards);
//2.发牌 首先定义三个玩家,使用集合代替玩家List<ArrayList>
List<Card> Player1 = new ArrayList<>();
List<Card> Player2 = new ArrayList<>();
List<Card> Player3 = new ArrayList<>();
// 依次发51张牌,剩余三张底牌
for (int i = 0; i <allCards.size()-3; i++) {
if(i%3==0){
Player1.add(allCards.get(i));
}else if(i%3==1){
Player2.add(allCards.get(i));
}else if(i%3==2){
Player3.add(allCards.get(i));
}
}
List<Card> last3 = allCards.subList(allCards.size()-3,allCards.size());
System.out.println("last3:\n"+last3);
//叫地主环节
// 对三个玩家的牌进行排序
sortCards(Player1);
sortCards(Player2);
sortCards(Player3);
// 看牌
System.out.println("Player1:\n"+Player1);
System.out.println("Player2:\n"+Player2);
System.out.println("Player3:\n"+Player3);
}
}
Test类
package popker;
public class test {
public static void main(String[] args) {
//1.牌类
//2.房间
Room m = new Room();
//3.启动游戏
m.start();
}
}
运行结果展示:
这是一副新牌:
[♣3----》1, ♠3----》1, ♥3----》1, ♦3----》1, ♣4----》2, ♠4----》2,……]
洗牌
[♣3----》1, 👨----》14, ♣4----》2, ♦9----》7, ♥8----》6, ♥2----》13, ……]
last3:
[♦K----》11, ♣J----》9, ♥4----》2]
Player1:
[♣3----》1, ♦3----》1, ♥3----》1, ♦4----》2, ♥5----》3, ♣7----》5, ……]
Player2:
[♦5----》3, ♣5----》3, ♥6----》4, ♣6----》4, ♠6----》4, ♠7----》5, ……]
Player3:
[♠3----》1, ♣4----》2, ♠4----》2, ♠5----》3, ♦6----》4, ♦7----》5,……]
Map系列集合
- 是一个接口 双列集合 每个元素包含俩个值,一次需要存储一对数据作为一个元素
- Map集合的每个元素“key=value”称为一个键值对
- 所有键是不允许重复的,但值可以重复,键和值是一一对应的,每一个键只能找到自己对应的值
- 常见业务:购物车,夫妻关系,一 一对应的场景
interface Map <K,V>
特点:
注意:Map系列集合的特点都是由键决定的,值只是一个附属品,值是不做要求的
- HashMap:无序,不重复,无索引(用最多)
- LInkedHashMap:有序,不重复,无索引
- TreeMap:按照大小默认升序排序,不重复,无索引
Map常用方法:
public static void main(String[] args) {
Map<String, Integer> map = new HashMap<>();
map.put("手机", 1);
map.put("电脑",2);
map.put("手表",3);
map.put(null, null);
System.out.println(map);
// 1.public int size();获取集合大小
System.out.println(map.size());
// 2.public void clear();清空集合
map.clear();
System.out.println(map.size());
// 3.public booolean isEmpty():判断是否为空 空返回true
boolean stp= map.isEmpty();
System.out.println(stp);
map.put("手机", 1);
map.put("电脑",2);
map.put("手表",3);
map.put(null, null);
// 4.public V get(Object key) 根据键获取值
System.out.println(map.get("手机"));
// 5.public V remove(Object key)根据键删除整个元素,会返回键的值
System.out.println(map.remove(null));
System.out.println(map);
// 6.public boolean containsKey(Object Key) 判断是否包含某个键 包含则返回true
System.out.println(map.containsKey("test"));
// 7.public boolean containsValue(Object value)判断是否包含某个值
System.out.println(map.containsValue(3));
// 8.public Set<K> keySet():获取Map集合的全部键
System.out.println(map.keySet());
// 9.public Collection<V> values();获取Map集合的全部值
System.out.println(map.values());
}
//结果:
{null=null, 手表=3, 电脑=2, 手机=1}
4
0
true
1
null
{手表=3, 电脑=2, 手机=1}
false
true
[手表, 电脑, 手机]
[3, 2, 1]
-
拓展:
public static void main(String[] args) { // 10.拓展:把其他map集合的数据导入到自己的集合中来 Map<String,Integer> map1 = new HashMap<>(); map1.put("java1",1); map1.put("c1",2); Map<String,Integer> map2 = new HashMap<>(); map1.put("java2",1); map1.put("c2",2); map1.putAll(map2); System.out.println(map1); } // 结果: {java2=1, java1=1, c1=2, c2=2}
Map集合遍历方式
键找值
- 先获取Map集合全部的键,再通过遍历键来找值(keyset get方法)
public static void main(String[] args) {
// 键找值
Map<String, Double> map = new HashMap<>();
map.put("张三", 162.5);
map.put("李四",169.8);
map.put("张三",162.8);
map.put("至尊宝", 171.3);
System.out.println(map);
Set<String> s= map.keySet();
System.out.println(s);
for (String key : s) {
double value=map.get(key);
System.out.println(key +"===>"+value);
}
}
//结果:
{李四=169.8, 张三=162.8, 至尊宝=171.3}
[李四, 张三, 至尊宝]
李四===>169.8
张三===>162.8
至尊宝===>171.3
键值对
Set <Map.Entry<K,V>> entrySet() //获取所有键值对的集合
public static void main(String[] args) {
// 键值对
Map<String, Double> map = new HashMap<>();
map.put("张三", 162.5);
map.put("李四",169.8);
map.put("张三",162.8);
map.put("至尊宝", 171.3);
System.out.println(map);
for (Map.Entry<String, Double> entry : map.entrySet()) {
System.out.println(entry.getKey() + "\t" + entry.getValue());
}
}
Lambda
defalt void forEach(BiConsumer<? super K ,?super V> action) //结合lambda遍历Map集合
public static void main(String[] args) {
// lambda
Map<String, Double> map = new HashMap<>();
map.put("张三", 162.5);
map.put("李四",169.8);
map.put("张三",162.8);
map.put("至尊宝", 171.3);
System.out.println(map);
map.forEach((k, v) -> {
System.out.println(k+"--->"+v);
});
}
//结果:
{李四=169.8, 张三=162.8, 至尊宝=171.3}
李四 169.8
张三 162.8
至尊宝 171.3
应用案例—统计投票人数
-
需求:某个班级80名学生,现在需要组织秋游活动,班长提供了ABCD四个景点,每个学生只能选择一个景点,统计出哪个景点想去的 人最多
-
public static void main(String[] args) { // 1.把80个同学选择的景点数据拿到程序中来 List<String> data = new ArrayList<>(); String[] selects={"A","B","C","D"}; Random r=new Random(); for (int i = 0; i <= 80; i++) { int index = r.nextInt(4); data.add(selects[index]); } System.out.println(data); // 2.开始统计每个景点投票人数 Map<String,Integer> map=new HashMap<>(); for (String s : data) { if (map.containsKey(s)) { map.put(s,map.get(s)+1); } else { map.put(s,1); } } System.out.println(map); } //结果: [B, D, A, B, D, A, D, D, A, D, B, A, C, C, D, D, A, B, D, D, A, D, C, B, D, D, B, B, B, C, A, A, C, C, D, B, D, D, B, B, D, D, C, A, A, A, C, B, C, B, D, A, A, A, D, B, C, A, B, D, C, D, B, C, B, C, B, C, C, B, B, A, D, D, A, B, A, A, A, B, B] {A=20, B=23, C=15, D=23}
HashMap
- 特点:无序,不重复,无索引
底层原理:
- 同HashSet一模一样,都是基于哈希表实现
实际上,原来学的Set系列集合的底层原理就是基于Map实现的,知识Set集合中的元素只要键数据,不要值数据
LinkedHashMap
-
有序,不重复,无索引
-
同LinkedHashSet
TreeMap
- 按照键大小默认升序排序、不重复,无索引
- 同TreeSet
集合补充知识:嵌套
- 集合中的元素又是一个集合
案例:
要求在程序中记住一下省份信息,记录成功后,要求可以查询出省份的信息
-
需求:要求在程序中记住一下省份信息,记录成功后,要求可以查询出省份的信息
江苏省=南京市,扬州市,苏州市,无锡市,常州市
湖北省=武汉市,孝感市,十堰市,宜昌市,鄂州市
河北省:石家庄市,唐山市,邢台市,保定市,张家口市
-
分析:
- 定义一个map集合,键用省份,值表示城市名称
- 展示值即可
public static void main(String[] args) {
Map<String,List<String>> Province = new HashMap<>();
List<String> City1 = new ArrayList<>();
Collections.addAll(City1,"南京市","扬州市","苏州市","无锡市","常州市");
Province.put("江苏省",City1);
List<String> City2 = new ArrayList<>();
Collections.addAll(City2,"石家庄","唐山市","邢台市","保定市","张家口市");
Province.put("河北省",City2);
List<String> City3 = new ArrayList<>();
Collections.addAll(City3,"武汉市","孝感市","十堰市","宜昌市","鄂州市");
Province.put("湖北省",City3);
System.out.println(Province);
System.out.println(Province.get("湖北省"));
}
//结果:
{江苏省=[南京市, 扬州市, 苏州市, 无锡市, 常州市], 湖北省=[武汉市, 孝感市, 十堰市, 宜昌市, 鄂州市], 河北省=[石家庄, 唐山市, 邢台市, 保定市, 张家口市]}
[武汉市, 孝感市, 十堰市, 宜昌市, 鄂州市]
Part06 Stream流
- jdk8开始新增的一套API,可以用于操作集合或者数组的数据
- 优势:Stream流大量的结合了Lambda的语法风格来编程,提供了更加强大,更加简单的方式操作集合或者数组中的数据,代码更简洁,可读性更好
- 流只能收集一次!!!!!
案例1 体验Stream流
需求:把集合中所有以“张”开头,且是三个字的元素存储到另一个新的结合中
public static void main(String[] args) {
List<String> list = new ArrayList<>();
list.add("张无极");
list.add("张三丰");
list.add("张强");
list.add("周芷若");
// 1.原方法
List<String> list1 = new ArrayList<>();
for (String s : list) {
if (s.startsWith("张")&&s.length()==3){
list1.add(s);
}
}
System.out.println(list1);
// 2.Stream流
List<String> list2= list.stream().filter(s -> s.startsWith("张"))
.filter(s -> s.length()==3).collect(Collectors.toList());
System.out.println(list2);
}
//结果:
[张无极, 张三丰]
[张无极, 张三丰]
使用步骤:
- 数据源
- 获取stream流
- 中间方法
- 调用流水线的各种方法对数据进行处理
- 获取处理结果
- 调用常见终结方法
常见方法
获取Stream流
public static void main(String[] args) {
// 获取List集合Stream流
List<String> list = new ArrayList<>();
Collections.addAll(list, "张三丰", "张无忌", "周芷若", "赵敏", "张强");
Stream<String> stream1 = list.stream();
// 获取Set集合Stream流
Set<String> set = new HashSet<>();
Collections.addAll(set, "刘德华","张曼玉","蜘蛛精","玛德","德玛西亚");
Stream<String> stream2 = set.stream();
stream2.filter(s -> s.contains("德")).forEach(s -> System.out.println(s));
// 获取Map集合Stream流
Map<String, Double> map = new HashMap<>();
map.put("古力娜扎",172.3);
map.put("迪丽热巴",168.3);
map.put("马儿扎哈",166.3);
map.put("卡尔扎巴",168.3);
Set<String> key = map.keySet();
Stream<String> stream3 = key.stream();
Collection<Double> values = map.values();
Stream<Double> vs = values.stream();
Set<Map.Entry<String,Double>> entries=map.entrySet();
Stream<Map.Entry<String,Double>> kvs=entries.stream();
kvs.filter(e -> e.getKey().contains("巴"))
.forEach(e->System.out.println(e.getKey()+"---->"+e.getValue()));
// 获取数组Stream流
String[] names = {"张翠山","东方不败","唐大山","孤独求败"};
Stream<String> stream4=Arrays.stream(names);
Stream<String> stream5=Stream.of(names);
}
中间方法
public static void main(String[] args) {
List<Double> scores = new ArrayList<>();
Collections.addAll(scores,88.5,100.1,20.2,99.0,121.0);
// 需求1:找出成绩大于60,升序排序并输出
scores.stream().filter(s -> s>=60).sorted().forEach(s -> System.out.println(s));
List<Student> students = new ArrayList<>();
Student s1 = new Student("蜘蛛精",26,172.5);
Student s2 = new Student("蜘蛛精",26,172.5);
Student s3 = new Student("紫霞",23,167.5);
Student s4 = new Student("白晶晶",25,169.5);
Student s5 = new Student("牛魔王",35,179.5);
Collections.addAll(students,s1,s2,s3,s4,s5);
// 2.找出年龄大于等于23,小于30的学生,按照年龄降序输出
students.stream().filter(s-> s.getAge()>=23&&s.getAge()<=30)
.sorted((o1,o2)->o2.getAge() - o1.getAge())
.forEach(s -> System.out.println(s));
System.out.println();
// 3. 取出升高最高三名学生,并输出
students.stream().sorted((o1,o2)-> Double.compare(o2.getHeight() ,o1.getHeight()))
.limit(3).forEach(s -> System.out.println(s));
// 4.找出最矮俩个学生,并输出
students.stream().sorted((o1,o2)-> Double.compare(o2.getHeight() ,o1.getHeight()))
.skip(students.size()-2).forEach(s -> System.out.println(s));
System.out.println();
// 5.找出超过168的学生叫什么名字,去除重名后,输出
students.stream().filter(s->s.getHeight()>=168).map(s -> s.getName())
.distinct().forEach(s -> System.out.println(s));
// 6.concat 合并流
Stream<String> st1 =Stream.of("张三","李四");
Stream<String> st2 =Stream.of("王五","小六");
Stream<Object> st3=Stream.concat(st1,st2);
st3.forEach(System.out::println);
}
//结果:
88.5
99.0
100.1
121.0
Student{name='蜘蛛精', age=26, height=172.5}
Student{name='蜘蛛精', age=26, height=172.5}
Student{name='白晶晶', age=25, height=169.5}
Student{name='紫霞', age=23, height=167.5}
Student{name='牛魔王', age=35, height=179.5}
Student{name='蜘蛛精', age=26, height=172.5}
Student{name='蜘蛛精', age=26, height=172.5}
Student{name='白晶晶', age=25, height=169.5}
Student{name='紫霞', age=23, height=167.5}
蜘蛛精
白晶晶
牛魔王
张三
李四
王五
小六
- 拓展:distinct只会针对map后的数据,map前的数据不会认为是一致的
public static void main(String[] args) {
List<Student> students = new ArrayList<>();
Student s1 = new Student("蜘蛛精",26,172.5);
Student s2 = new Student("蜘蛛精",26,172.5);
Student s3 = new Student("紫霞",23,167.5);
Student s4 = new Student("白晶晶",25,169.5);
Student s5 = new Student("牛魔王",35,179.5);
Collections.addAll(students,s1,s2,s3,s4,s5);
students.stream().filter(s->s.getHeight()>=168)
.distinct().forEach(s -> System.out.println(s));
}
//结果:
Student{name='蜘蛛精', age=26, height=172.5}
Student{name='蜘蛛精', age=26, height=172.5}
Student{name='白晶晶', age=25, height=169.5}
Student{name='牛魔王', age=35, height=179.5}
- 解决办法:重写Student类的equals方法:
Student{name='蜘蛛精', age=26, height=172.5}
Student{name='白晶晶', age=25, height=169.5}
Student{name='牛魔王', age=35, height=179.5}
终结方法:
public static void main(String[] args) {
List<Student> students = new ArrayList<>();
Student s1 = new Student("蜘蛛精",26,172.5);
Student s2 = new Student("蜘蛛精",26,172.5);
Student s3 = new Student("紫霞",23,167.5);
Student s4 = new Student("白晶晶",25,169.5);
Student s5 = new Student("牛魔王",35,179.5);
Collections.addAll(students,s1,s2,s3,s4,s5);
// 1.foreach
// 2.count 计算身高超过168学生数目
long num= students.stream().filter(s -> s.getHeight()>=168).count();
System.out.println(num);
// 3.max 身高最高学生,并输出
Student ss= students.stream().max((o1, o2) -> Double.compare(o1.getHeight(),o2.getHeight())).get();
System.out.println(ss);
// 4.min 同理
}
// 结果:
4
Student{name='牛魔王', age=35, height=179.5}
-
收集Stream流:把Stream流操作后的结果转回到集合或者数组中去
-
Stream流:是方便操作集合数组的手段//////集合和数组才是开发中的目的
public static void main(String[] args) { List<Student> students = new ArrayList<>(); Student s1 = new Student("蜘蛛精",26,172.5); Student s2 = new Student("蜘蛛精",26,172.5); Student s3 = new Student("紫霞",23,167.5); Student s4 = new Student("白晶晶",25,169.5); Student s5 = new Student("牛魔王",35,179.5); Collections.addAll(students,s1,s2,s3,s4,s5); // 1.collect 找出身高高于170学生,并在新集合返回 List<Student> ll = students.stream().filter(s->s.getHeight()>=170).collect(Collectors.toList()); System.out.println(ll); Set<Student> lll = students.stream().filter(s->s.getHeight()>=170).collect(Collectors.toSet()); System.out.println(lll); // 存入map集合 身高170以上的学生名字加身高<不能自动去重,徐要调用distinct> Map<String,Double> sss=students.stream().filter(s ->s.getHeight()>=170) .distinct().collect(Collectors.toMap(a ->a.getName(),a ->a.getHeight())); System.out.println(sss); // 把流输入到数组中 Student[] arr =students.stream().filter(a ->a.getHeight()>170).toArray(s -> Student); System.out.println(Arrays.toString(arr)); } //结果: [Student{name='蜘蛛精', age=26, height=172.5}, Student{name='蜘蛛精', age=26, height=172.5}, Student{name='牛魔王', age=35, height=179.5}] [Student{name='牛魔王', age=35, height=179.5}, Student{name='蜘蛛精', age=26, height=172.5}] {蜘蛛精=172.5, 牛魔王=179.5} [Student{name='蜘蛛精', age=26, height=172.5}, Student{name='蜘蛛精', age=26, height=172.5}, Student{name='牛魔王', age=35, height=179.5}]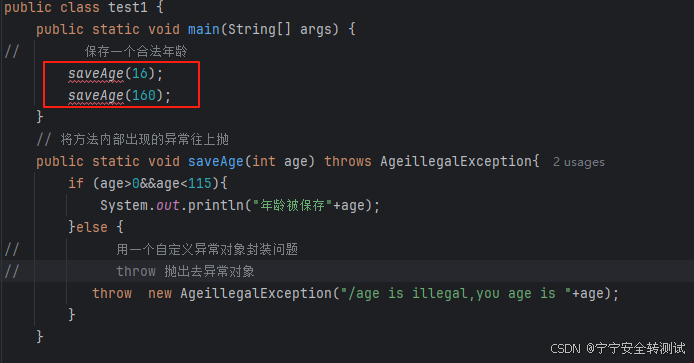
异常处理方法:

- 方法A捕获异常,记录异常相应给合适信息给用户 <举例bilibili>,如果没有异常,则会404
- 捕获异常,并尝试重新修复
Part08 File、IO流
File:代表文本
- 存储数据方案:变量、数组、对象、集合(都是内存中的数据容器,断电,程序终止时会丢失)
- 长久保存方法:文件file存储在硬盘中,断电程序终止数据不会丢失
- File是java.io包下的类,File类的对象,用于代表当前操作系统的文件
- File类只能对文件本身操作,不能读写文件内存储的数据
IO流:读写数据
- 可以用于读写数据的内存
File:
文件和目录路径名的抽象表示
创建对象
| 构造器 | 说明 |
|---|---|
| public File(String pathname) | 根据文件路径创建文件对象 |
| public File(String parent,String child) | 根据父路径和子路径名字创建文件对象 |
| public FIle(File parent,String child) | 根据父路径对应文件对象和子路径名字创建文件对象 |
带盘符为绝对路径
public static void main(String[] args) {
// 1.创建file对象,指代某个具体吻技安
File f1 = new File("C:\\Users\\liu\\Desktop\\Study\\ab.txt.txt");
// 2.返回字节个数
System.out.println(f1.length());
// 定位文件夹
File f2 = new File("C:\\Users\\liu\\Desktop\\Study");
// 可以指向不存在的文件路径 exists :判断是否存在 存在true
File f3 = new File("C:\\Users\\liu\\Desktop\\Play");
System.out.println(f3.exists());
// 我现在要定位的文件在模块中,应该怎么定位呢?
File f4 = new File("C:\\Users\\liu\\Desktop\\Study\\Doctor\\file-io\\src\\it.txt");
}
开发规范使用相对路径:默认直接去工程下寻找文件
// 我现在要定位的文件在模块中,应该怎么定位呢?
File f4 = new File("file-io\\src\\it.txt");
}
判断文件类型,获取文件信息
public static void main(String[] args) {
// 1.创建file对象,指代某个具体文件
File f1 = new File("C:\\Users\\liu\\Desktop\\Study\\ab.txt.txt");
// 2. public boolean exist(); 判断文件是否存在,存在返回true
System.out.println(f1.exists());
// 3.public boolean ifFile():判断路径下是否指代文件,是返回true
System.out.println(f1.isFile());
// 4.public Boolean ifDictionary:判断当前文件对象指代是否为文件夹
System.out.println(f1.isDirectory());
// 5.public String getName():获取文件名字,包含后缀
System.out.println(f1.getName());
// 6.public long length();获取文件大小,返回字节个数
System.out.println(f1.length());
// 7.public long lastModified():获取文件最后修改时间
long time = f1.lastModified();
SimpleDateFormat stp = new SimpleDateFormat("yyyy/MM/dd/ HH:mm:ss");
System.out.println(stp.format(time));
// 8.public String getPath():获取创建文件夹时使用的路径
File f2 = new File("file-io\\src\\it.txt");
System.out.println(f2.getPath());
System.out.println(f1.getPath());
// 9.public String getAbsolutePath() 获取绝对路径
System.out.println(f2.getAbsolutePath());
}
//结果:
true
true
false
ab.txt.txt
0
2024/11/19/ 12:24:02
file-io\src\it.txt
C:\Users\liu\Desktop\Study\ab.txt.txt
C:\Users\liu\Desktop\Study\Doctor\file-io\src\it.txt
创建文件、删除文件方法
public static void main(String[] args) throws IOException {
// 1.public boolean creatNewFile():创建新文件(文件内容为空),创建成功返回true
File f1 = new File("C:\\Users\\liu\\Desktop\\Study\\Doctor\\file-io\\src\\it1.txt");
System.out.println(f1.createNewFile());
// 2.public boolean mkdir():创建文件夹,只能创建一级文件夹
File f2 = new File("C:\\Users\\liu\\Desktop\\Study\\liu") ;
System.out.println(f2.mkdir());
// 3.public boolean mkdirs():创建多级文件夹
File f3 = new File("C:\\Users\\liu\\Desktop\\Study\\aaa\\bbb\\ccc");
System.out.println(f3.mkdirs());
// 4.public boolean delete(): 删除文件、空文件夹
System.out.println(f1.delete());
System.out.println(f2.delete());
System.out.println(f3.delete());
}
遍历文件夹
public static void main(String[] args) throws IOException {
// 1. public String[] list(): 获取当前文件夹下所有一级文件名称到一个字符串组中去
File f1 =new File("E:\\");
String[] names=f1.list();
for (String name : names) {
System.out.println(name);
}
// 2.public File[] listFiles(): 重点:将目录下所有的一级文件对象到数组中返回
File[] files=f1.listFiles();
for (File file : files) {
System.out.println(file.getAbsolutePath());
}
}
listFiles注意事项
- 主调是文件,或者路径不存在时,返回null
- 主调是空文件夹,返回一个长度为0的数组
- 主调是一个有内容的文件夹,将里面所有以及文件和文件夹的路径放在File数组中返回
- 当主调是一个文件夹,里面有隐藏文件时,将里面所有文件和文件夹路径放在File数组中返回,包含隐藏文件
- 当主调是一个文件夹,但是灭有权限访问该文件夹时,返回null
前置知识:递归
- 什么是方法递归?
- 递归是一种算法,在程序设计语言中广泛应用
- 从形式上说,方法调用自身的形式成为方法递归
- 递归的形式
- 直接递归:自己调用自己
- 间接递归:方法调用其他方法,其他方法又调用自己
public class recursion {
public static void main(String[] args) {
test1();
test2();
}
//直接方法递归
//会导致栈内存溢出
public static void test1() {
System.out.println("------");
test1();
}
//间接递归
public static void test2() {
System.out.println("--test2---");
test3();
}
public static void test3() {
test2();
}
}
Exception in thread "main" java.lang.StackOverflowError
没有设置好跳出递归的条件,会导致栈溢出
案例导学:计算n的阶乘
public static void main(String[] args) {
System.out.println("5的阶乘:"+fn(5));
}
public static int fn(int n){
if(n==1){
return 1;
}
else {
return fn(n-1)*n;
}
}
应用搜索:
需求:从D盘中,搜索:“Overwatch Launcher.exe”文件,找到后输出其位置
分析:
- 先找出D盘下所有一级文件对象
- 遍历一遍文件对象,判断是否是文件
- 如果是文件,判断是不是自己想要的
- 如果是文件夹,需要继续进入到该文件夹,重复上述过程
public static void main(String[] args) {
fun(new File("D://"),"Overwatch Launcher.exe");
}
// dir 目录 name:搜素文件名称
public static void fun(File dir,String name) {
// 1.非法情况拦截
if(dir == null || !dir.exists()||!dir.isDirectory()) {
return;//无法搜素
}
// 2.dir 存在且为目录
File[] files = dir.listFiles();
// 3.判断目录下是否存在一级文件对象,以及是否可以拿到一级文件对象
if (files != null && files.length>0) {
for (File file : files) {
if (file.isFile()) {
if (name.equals(file.getName())) {
System.out.println("文件已经找到了!"+file.getAbsolutePath());
//alt +enter 将问题上抛后,可以直接运行文件
Runtime runtime = Runtime.getRuntime();
runtime.exec(file.getAbsolutePath());
}
}else {
fun(file,name);
}
}
}
}
前置知识:字符集
常见字符集:
- ASCII码:
- 美国信息交换标准代码,包括英文、符号等
- 一个字节存储一个字符,首位是0,总共表示128个字符
- GBK
- 汉字编码字符集,包含2w多个汉字等字符,一个中文字符编码成2个字节
- GBK兼容了ASCII字符集
- GBK规定:汉字的第一个字节的第一位必须是1
- Unicode(统一码,万国码)
- 国际组织制定,可以容纳世界上所有文字,符号的字符集
- UTF-32 四个字节表示一个字符 有容乃大
- UTF - 8
- 采取可变长编码方案,共分为4个长度区:1个字节,2个字节,3个字节,4个字节
- 英文,数字只占1个字节,汉字字符占用3个字节
- 一个字节:0开头
- 俩个字节:110开头 10开头
- 三个字节:1110开头 10开头 10开头
- 四个字节:11110开头 10开头 10开头 10开头
java代码完成编码解码:
public static void main(String[] args) throws UnsupportedEncodingException {
// 1.对字符进行编码:
String data = "a我b";
byte[] bytes = data.getBytes();// 默认按照平台字符集
System.out.println(Arrays.toString(bytes));
// 2.按照指定字符集进行编码
byte[] bytes1 = data.getBytes("GBK");
System.out.println(Arrays.toString(bytes1));
// 3.解码:
String s1= new String(bytes);
System.out.println(s1);
String s2 = new String (bytes1,"GBK");
System.out.println(s2);
}
// 结果
[97, -26, -120, -111, 98]
[97, -50, -46, 98]
a我b
a我b
IO流
- I指input,称为输入流:负责把数据读到内存中去
- O指Output,称为输出流:负责把数据写出去
按方向分类:
- 输入流:
- 输出流:
按流中最小数据单位:
- 字节流:所有类型文件(音频,图片,视频)
- 字符流:纯文本文件(读写txt,java文件)
总体来分:
- 字节输入流:InputStream(抽象类) FileInputStream
- 字节输出流:OutputStream(抽象类)FileOutputStream
- 字符输入流:Reader(抽象类)FileReader
- 字符输出流:Writer(抽象类)FileWriter
文件字节输入流:
- 作用:以内存为基准,可以把磁盘文件中的数据,以字节的形式读入到内存中去
- 每次读取一个字节读取性能差,读取汉字输出会出现乱码
public static void main(String[] args) throws IOException {
// 1.创建文件字节输入流管道,与源文件接通
InputStream is = new FileInputStream("file-io\\src\\it.txt");
// public int read() 每次读取一个字节并返回
// 2.开始读取文件字节数据(read 每次读取一个字节)
int b1 = is.read();
System.out.println((char)b1);
//流使用完毕后,必须关闭,释放系统资源
is.close();
} // 如果已经读取完毕无数据可读,会返回-1
//结果:
a
-
每次读取多个字节:
public static void main(String[] args) throws IOException { // 1.创建文件字节输入流管道,与源文件接通 InputStream is = new FileInputStream("file-io\\src\\it.txt"); // 2.开始读取文件字节数据:每次读取多个字节 byte[] buffer = new byte[3]; int len = is.read(buffer); String rs = new String(buffer); System.out.println(rs); System.out.println("当此读取字节数量:"+len); len = is.read(buffer); String rs2 = new String(buffer); System.out.println(rs2); System.out.println("当此读取字节数量:"+len); // 读取多少,倒出多少: rs2 = new String(buffer,0,len); System.out.println(rs2); System.out.println("当此读取字节数量:"+len); } //结果:“ aba 当此读取字节数量:3 dba 当此读取字节数量:1 d 当此读取字节数量:1 -
一次性全部读取完
public static void main(String[] args) throws IOException {
// 1.创建文件字节输入流管道,与源文件接通
InputStream is = new FileInputStream("file-io\\src\\it.txt");
// 2.public byte[] readAllBytes() 直接的将当前字节输入流对应的文件对象的字节数据装到一个字节数组返回
byte[] buffer = is.readAllBytes();
System.out.println(new String(buffer));
}
文件字节输出流
- 写一个字节进入
public static void main(String[] args) throws IOException {
// 1.创建文件字节输入流管道,与源文件接通 每次写时会把原先数据清空
OutputStream is = new FileOutputStream("file-io\\src\\is.txt");
//public FileOutputStream (String filepath,boolean append);
OutputStream os = new FileOutputStream("file-io\\src\\is.txt",true);
//这个管道就是追加数据
// 2.开始写字节数据出去
//一个字节
is.write(97);
is.write('b');
is.write('宁');//文件中出现乱码
//一个字节数组
byte[] bytes = "我爱你中国123".getBytes();
is.write(bytes);
is.write(bytes,0,15);
// 换行符:
is.write("\r\n".getByes[])
}
字节流应用:文件复制
public static void main(String[] args) throws IOException {
// 1.创建文件字节输入输出流管道,与源文件接通
InputStream in =new FileInputStream("file-io\\src\\is.txt");
OutputStream out = new FileOutputStream("file-io\\src\\is2.txt");
// 2.buffer 字节数组读取is文件全部内容
byte[] buffer = in.readAllBytes();
// 3.写入is全部内容
out.write(buffer);
}
释放资源方式
方法一:try-catch-finally(可能有些臃肿)
try{
}catch(IOException e){
e.printStackTrace();
}finally{
}
- 无论try总代码执行与否,finally中的代码一定会执行一次
- 不可在finally中return数据
- 一般在程序执行完成后进行资源的释放操作
方法二:try-with-resource
try(定义资源1;定义资源2;。。。){
可能出现异常的代码
}catch(异常类名 变量名){
异常的处理代码
}
try(
InputStream in =new FileInputStream("file-io\\src\\is.txt");
OutputStream out = new FileOutputStream("file-io\\src\\is2.txt");
){
}catch(IOException e){
e.printStackTrace();
}
- ( )中只能放置资源,否则报错
- 资源一般指实现了AutoCloseable接口
文件字符输入流:
- 每次读取一个字符, 性能较差
public static void main(String[] args) {
try (
Reader fr= new FileReader("file-io\\src\\is.txt");
){
int c; // 记住每次读取的字符编号
while((c= fr.read())!=-1){
System.out.print((char)c);
}
} catch (Exception e) {
throw new RuntimeException(e);
}
}
- 每次读取多个字符
public static void main(String[] args) {
try (
Reader fr= new FileReader("file-io\\src\\is.txt");
){
char[] buffer = new char[3];
int len;// 记住每次读取的字符编号
while((len= fr.read(buffer))!=-1){
System.out.print((new String(buffer,0,len)));
}
} catch (Exception e) {
throw new RuntimeException(e);
}
}
文件字符输出流:
public static void main(String[] args) {
try (
Writer fr1= new FileWriter("file-io\\src\\is1.txt");//不可追加
Writer fr2= new FileWriter("file-io\\src\\is2.txt",true)//可追加
){
// 1. public void write(int c):写一个字符出去
fr1.write(17);
fr2.write('宁');//可以完成、
// 2.public void write(String c):写一个字符串出去
fr1.write("我爱你中国");
fr2.write("我爱你中国abc",0,5);//第0个到第5个
// 3.public void write(char[] buffer):写一个字符数组出去
char[] buffer = {'a','b','c','d'};
fr1.write(buffer);
fr2.write(buffer,0,2);
//换行
fr1.write("\r\n");
} catch (Exception e) {
throw new RuntimeException(e);
}
}
注意事项:
字符输出流写出数据后,必须刷新流,或者关闭流,写出去的数据才会生效
fr1.flush()//刷新流
缓冲流:
对原始流进行包装,提升原始流读写性能
字节缓冲流:
提升字节流读写数据的性能(减少系统调用次数)
public static void main(String[] args) {
try (
InputStream is= new FileInputStream("file-io\\src\\is.txt");
// 1.定义一个字节缓冲输入流包装原始字节输入流
InputStream bis = new BufferedInputStream(is,8192);
OutputStream bos = new FileOutputStream("file-io\\src\\os.txt");
// 2.定义一个字节缓冲输出流包装原始字节输入流
OutputStreamWriter osw = new BufferedOutputStream(os, "utf-8",8192);
){
byte[] buffer = new byte[1024];
int len;
while ((len = bis.read(buffer)) != -1) {
bos.write(buffer, 0, len);
}
System.out.println("复制完成!");
} catch (Exception e) {
throw new RuntimeException(e);
}
}
字符缓冲流:
- 输入流
public static void main(String[] args) {
try (
Reader f1 = new FileReader("file-io\\src\\is.txt");
// 1.创建字符输入缓冲流包装原始流
BufferedReader br1 = new BufferedReader(f1);
){
// char [] buffer = new char[3];
// int len;
// while ((len = br1.read(buffer)) != -1) {
// System.out.println(new String(buffer, 0, len));
// }
//新功能:按行读取,不能使用多态定义
System.out.println(br1.readLine());
System.out.println(br1.readLine());
} catch (Exception e) {
throw new RuntimeException(e);
}
}
- 输出流:
public static void main(String[] args) {
try (
Wroter f1 = new FileWriter("file-io\\src\\is.txt",true);
// 1.创建字符输出缓冲流包装原始流
BufferedWriter bw = new BufferedWriter(f1);
){
bw.write('a');
bw.write('b');
bw.write('c');
bw.newLine();//换行 新功能
} catch (Exception e) {
throw new RuntimeException(e);
}
}
原始流、缓冲流性能分析:
测试用例:
- 分别使用原始的字节流,以及字节缓冲流复制一个很大的视频
测试步骤:
- 使用低级的字节流按照一个一个字节的形式复制文件
- 使用低级的字节流按照字节数组形式复制文件
- 使用高级的缓冲字节流一个一个字节的形式复制文件
- 使用高级的缓冲字节流按照字节数组形式复制文件
public class FileTest1 {
// 复制的视频路径
private static final String SRC_FILE = "C:\\Users\\liu\\Documents\\Overwatch\\videos\\overwatch\\ow.mp4";
// 复制到哪个地址
private static final String DEST_FILE = "C:\\Users\\liu\\Desktop";
public static void main(String[] args) {
// test01();//实在太慢,直接淘汰
test02();
test03();
test04();
System.out.println("测试结束");
}
// 测试用例1
private static void test01() {
long startTime = System.currentTimeMillis();
try (
InputStream is = new FileInputStream(SRC_FILE);
OutputStream os = new FileOutputStream(DEST_FILE + "1.mp4");
){
int b;
while ((b = is.read()) != -1) {
os.write(b);
}
} catch (Exception e) {
throw new RuntimeException(e);
}
long endTime = System.currentTimeMillis();
System.out.println("测试用例1:"+(endTime - startTime)/1000.0+"s");
}
// 测试用例2
private static void test02() {
long startTime = System.currentTimeMillis();
try (
InputStream is = new FileInputStream(SRC_FILE);
OutputStream os = new FileOutputStream(DEST_FILE + "2.mp4");
){
byte[] buffer = new byte[1024];
int length;
while ((length = is.read(buffer)) != -1) {
os.write(buffer, 0, length);
}
} catch (Exception e) {
throw new RuntimeException(e);
}
long endTime = System.currentTimeMillis();
System.out.println("测试用例2:"+(endTime - startTime)/1000.0+"s");
}
// 测试用例3
private static void test03() {
long startTime = System.currentTimeMillis();
try (
InputStream is = new FileInputStream(SRC_FILE);
BufferedInputStream bis = new BufferedInputStream(is);
OutputStream os = new FileOutputStream(DEST_FILE + "3.mp4");
BufferedOutputStream bos = new BufferedOutputStream(os);
){
int b;
while ((b = bis.read()) != -1) {
bos.write(b);
}
} catch (Exception e) {
throw new RuntimeException(e);
}
long endTime = System.currentTimeMillis();
System.out.println("测试用例3:"+(endTime - startTime)/1000.0+"s");
}
// 测试用例4
private static void test04() {
long startTime = System.currentTimeMillis();
try (
InputStream is = new FileInputStream(SRC_FILE);
BufferedInputStream bis = new BufferedInputStream(is);
OutputStream os = new FileOutputStream(DEST_FILE + "4.mp4");
BufferedOutputStream bos = new BufferedOutputStream(os);
){
byte[] buffer = new byte[1024];
int length;
while ((length = bis.read(buffer)) != -1) {
bos.write(buffer, 0, length);
}
} catch (Exception e) {
throw new RuntimeException(e);
}
long endTime = System.currentTimeMillis();
System.out.println("测试用例4:"+(endTime - startTime)/1000.0+"s");
}
}
//结果:
测试用例2:0.101s
测试用例3:0.531s
测试用例4:0.031s
测试结束
- 字节数组是越大越好,但大到一定程度的时候不会更加明显
转换流:
- 如果代码编码和被读取的文本文件编码不一致时,会出现乱码
public static void main(String[] args) {
try (// 1.创建文件字符输入流与源文件接通:
Reader is = new FileReader("file-io\\src\\GBK.txt");
BufferedReader br = new BufferedReader(is);
){
String line;
while ((line = br.readLine()) != null) {
System.out.println(line);
}
} catch (Exception e) {
throw new RuntimeException(e);
}
}
//结果:
23�ҿ�������a
字符输入转换流:
public static void main(String[] args) {
try (// 1.创建文件字符输入流与源文件接通:
InputStream is = new FileInputStream("file-io\\src\\GBK.txt");
Reader isr = new InputStreamReader(is,"GBK");
BufferedReader br = new BufferedReader(isr);
){
String line;
while ((line = br.readLine()) != null) {
System.out.println(line);
}
} catch (Exception e) {
throw new RuntimeException(e);
}
}
// 结果:
23我可以想你a
字符输出转换流(使用少)
控制写出去的字符集使用xxx字符集编码
- 调用String提供的getBytes方法
- 使用“字符输出转换流”
打印流
- 方便高效的打印出去,实现打印啥出去就是啥出去
PrintStream打印流(字节)
| 构造器 | 说明 |
|---|---|
| public PrintStream(OutputStream/File/String) | 打印直接通向字节输出流/文件/文件路径 |
| public PrintStream(String fileName,Charset charset) | 指定字符编码 |
| public PrintStream(OutputStream out,boolean autoFlush) | 指定自动刷新 |
| public PrintStream(OutputStream out, boolean autoFLush,String encoding) | 指定自动刷新,并指定字符编码 |
| 方法 | 说明 |
|---|---|
| public void println(xxx) | |
| public void write(int) |
public static void main(String[] args) {
try (// 1.创建文件字符输入流与源文件接通:
PrintStream ps = new PrintStream("file-io\\src\\is.txt");
){
ps.println(97);
ps.println('a');
} catch (Exception e) {
throw new RuntimeException(e);
}
}
PrintWriter打印流(字符)
| 构造器 | 说明 |
|---|---|
| public PrintWriter(OutputStream/File/String) | 打印直接通向字节输出流/文件/文件路径 |
| public PrintWriter(String fileName,Charset charset) | 指定字符编码 |
| public PrintWriter(OutputStream out,boolean autoFlush) | 指定自动刷新 |
| public PrintWriter(OutputStream out, boolean autoFLush,String encoding) | 指定自动刷新,并指定字符编码 |
应用:输出语句的重定向
- 把输出语句的打印位置改到某个文件中去
public static void main(String[] args) {
System.out.println("老骥伏枥");
System.out.println("志在千里");
try (PrintStream ps=new PrintStream("file-io\\src\\shi.txt");
){
System.setOut(ps);//把系统默认的打印流改成自己设置的打印流
System.out.println("烈士暮年");
System.out.println("壮心不已");
} catch (Exception e) {
throw new RuntimeException(e);
}
}
数据流:
DataoutPutStream:
允许把数据和其类型一并写出去
| 构造器 | 说明 |
|---|---|
| public DataOutputStream(OutputStream out) | 创建数据输出包装基础的字节输出流 |
| 方法 | 说明 |
|---|---|
| public final void writeByte(int v) throws IOException | 将byte类型数据写入基础的字节输出流 |
| public final void writeInteresting(int v) throws IOException | 将int类型数据写入基础的字节输出流 |
| public final void writeDouble(double v) throws IOException | 将double类型数据写入基础的字节输出流 |
| public final void writeUTF(String str) throws IOException | 将字符串类型数据以utf-8编码成字节写入基础字节输出流 |
DataInputStream
读取dataoutputstream写出去的数据(看着像乱码实际不是)
| 构造器 | 说明 |
|---|---|
| public DataInputStream(InputStream is) | 创建数据输入包装基础的字节输出流 |
| 方法 | 说明 |
|---|---|
| public final void readByte(int v) throws IOException | 读取字节数据返回 |
| public final void readInteresting(int v) throws IOException | 读取int类型数据返回 |
| public final void readDouble(double v) throws IOException | 读取double类型数据返回 |
| public final void readUTF(String str) throws IOException | 读取字符串数(UTF-8)返回 |
序列化流:
-
对象序列化:把java对象写入到文件中去
-
反序列化:把文件里的java对象读出来
ObjectOutoputStream:
将java对象进行序列化
必须实现接口Serializable
| 构造器 | 说明 |
|---|---|
| public ObjectOutputStream(OutputStream out) | 创建字节对象输出流,包装基础的字节输出流 |
| 方法 | 说明 |
|---|---|
| public final void writeObject(object c) throws IOExceptio | 把对象写出去 |
public static void main(String[] args) {
user u = new user("admin","admin",13);
// 1.创建对象字节输出流
try (
OutputStream out = new FileOutputStream("file-io\\src\\user.txt");
ObjectOutputStream oos = new ObjectOutputStream(out);
){
// 2.序列话对象到文件中 必须让对象类实现Serializable接口
oos.writeObject(u);
System.out.println("序列化成功");
} catch (Exception e) {
throw new RuntimeException(e);
}
}
}
//看似乱码,实则对象和对象类型都存入了
ObjectInputStream
| 构造器 | 说明 |
|---|---|
| public ObjectInputStream(InputStream out) | 创建字节对象输入流,包装基础的字节输出流 |
| 方法 | 说明 |
|---|---|
| public final void readObject(object c) | 把存储在文件中的java对象读出来 |
public static void main(String[] args) {
// 1.创建对象字节输出流
try (
InputStream out = new FileInputStream("file-io\\src\\user.txt");
ObjectInputStream ois = new ObjectInputStream(out);
){
// 2.序列话对象到文件中 必须让对象类实现Serializable接口
user u = (user)ois.readObject();
System.out.println("反序列化成功"+u);
} catch (Exception e) {
throw new RuntimeException(e);
}
}
- 不想对某个对象进行序列化:加修饰符 transient
- 一次序列化多个对象:用ArrayList集合存储多个对象,对集合进行序列化
IO框架
- 解决某类问题,编写的一套类、接口等,可以理解为一个半成品
- 好处:在框架基础上开发,可以得到优秀的软件架构
- 框架形式:一般是把类、接口等编译成class形式,压缩成一个.jar结尾的 文件发出去
- 什么是IO框架?
- 封装了java提供的对文件,数据进行操作的代码,对外提供了更简单的方式来对文件进行操作
- Commons-io:apache开源基金组织提供的小框架

part09 特殊文件和日志技术
- 为什么使用特殊文件?
- 存储有关系的数据,作为系统的配置文件
- 作为信息进行传输
- 主要学习什么??
- 特点、作用
- 如何使用程序读取里面的数据
- 使用程序把数据存储到这些文件中
properties(属性):
特点
- 都只能是键值对
- 键不能重复
- 文件后缀一般是.properties
读写数据:
-
Properties集合
- 是一个map集合
- 核心作用:Properties是用来代表属性文件的,通过Properties可以读写属性文件中的内
构造器 说明 public Properties() 构建Properties集合对象
读取
| 常用方法 | 说明 |
|---|---|
| public void load(Input Stream is) | 通过字节输入流,读取属性文件中的键值对数据 |
| public void load(Reader reader) | 通过字符输入流,读取属性文件中的键值对数据 |
| public (String getProperty(String key)) | 根据键获取值 |
| public Set stringPropertyNames() | 获取全部键的集合 |
写入
| 常用方法 | 说明 |
|---|---|
| public Object setProperty(String key,String value) | 保存键值对数据到properties对象中去 |
| public void store(OutputStream ps,String comments) | 把键值对数据,通过字节输出流写出到属性文件中去 |
| public void store(Writer w,String comments) | 把键值对数据,通过字符输出流写出到属性文件中去 |
public static void main(String[] args) throws IOException {
// 1.创建properties对象
Properties pro = new Properties();
pro.setProperty("刘宁","123456");
pro.setProperty("刘叶","1234");
pro.setProperty("刘杨","123");
// 2.加载属性文件中的键值对数据到properties中去
pro.store(new FileWriter("part09\\src\\file.properties"
),"i saved many users");
}
XML(可拓展标记语言):
特点:
- XML中“<标签名>”称为一个标签或一个元素,一般是成对出现
- XML文件中的标签名可以自己定义,但是必须正确嵌套
- XML中只能有一个根标签
- XML中的标签可以有自己的属性
- 文件中放置的是XML格式的数据,这个文件就是XML文件,后缀一般写 .xml
- 经常用来作为系统的配置文件(用户名密码);或者作为一种特殊数据结构,在网络中传输
<?xml version="1.0" encoding="UTF-8" ?>
<!--注释:以上抬头声明必须第一行,否则报错-->
<!--根标签只能有一个-->
<users>
<user id=" 1">
<name>张无忌</name>
<sex>男</sex>
<password>123465</password>
<!--并不是什么数据写入都可以 比如< >
< 代替<
> 代替>
或者 输入CD 回车 内部可以输入任意内容
-->
</user>
<user id = "2">
<name>赵敏</name>
<sex>女</sex>
<password>654321</password>
</user>
</users>
读写数据
-
有开源的解析XML的框架,最知名的是:Dom4j
-
dom4j解析XML文件思想:文档对象模型,通过ASXReader解析器,将XML文件解析为文档
| 构造器/方法 | 说明 |
|---|---|
| public SAXReader() | 构建Dom4j解析器对象 |
| public Document read(String url) | 把XML文件读成Document文档 |
| public Document read(Input Stream is) | 通过字节输入流读取xml文件 |
| Element getRootELement() | 获得根元素对象 |
| public String getName() | 获得元素名字 |
| public List elements() | 得到当前元素下的所有子元素 |
| public List elements(Stirng name) | 得到当前元素下指定名字的子元素返回集合 |
| public Element element (String name) | 得到当前元素下指定名字的子元素,如果有很多相同,返回第一个 |
| public String attributeValue(String name) | 通过属性名直接得到属性值 |
| public String elementText(子元素名) | 得到指定名称的子元素的文本 |
| public String getText() | 得到文本 |
读取数据
public static void main(String[] args) throws DocumentException {
// 1.创建解析器对象
SAXReader sax = new SAXReader();
// 2.使用saxReader对象把xml文件读成一个Document对象
Document doc= sax.read("part09\\src\\helloworld.xml");
// 3.从文档对象中解析xml全部数据
// 解析思想为自上而下的,从父到子的 一级一级解析
Element root = doc.getRootElement();
System.out.println(root.getName());
// 4.获取根元素下的全部一级子元素
List<Element> elements = root.elements();
// 指定获取user
// List<Element> elements = root.elements("user");
for (Element e : elements) {
System.out.println(e.getName());
}
// 5.获取当前元素下的某个子元素
Element user = root.element("user");
System.out.println(user.getText());
//如果下面有很多子元素,默认第一个
System.out.println(user.elementText("name"));
// 6.获取元素属性信息
System.out.println(user.attributeValue("sex"));
Attribute id = user.attribute("sex");
System.out.println(id.getName());
System.out.println(id.getValue());
List<Attribute> attributes = user.attributes();
for (Attribute attribute : attributes) {
System.out.println(attribute.getName()+":"+attribute.getValue());
// 7.如何获取全部文本内容
System.out.println(user.elementText("name"));
System.out.println(user.attributeValue("sex"));
Element data =user.element("password");
System.out.println(data.getText());
System.out.println(data.getTextTrim());//去除空格
}
}
写入数据
把程序中的数据拼接成xml文件格式,使用IO流写入
约束xml文件:
-
限制xml文件只能按照某种格式进行书写
-
约束文档:专门用来限制xml书写格式的文档:限制表现,属性应该怎么写
-
DTD文档
-
不能约束具体的数据类型(int String等)
-
编写DTD约束文档,后缀必须是 .dtd
-
<!ElEMENT 书架(书+)> <!ElEMENT 书(书名,作者,售价)> <!ElEMENT 书名(#PCDATA)> <!ElEMENT 作者(#PCDATA)> <!ElEMENT 售价(#PCDATA)> -
需要编写的xml文件中导入DTD约束文档
<!DOCTYPE xx SYSTEM 'xxxx.dtd'>
-
-
Schema文档
- 后缀.xsd
- 导入schema文档
-
日志技术
- 记录某些数据是被谁操作的
- 分析用户浏览系统的具体情况
- 当前系统在开发中或者上线后出现了bug,奔溃了,通过日志去分析,定位bug
- 可以将系统执行的信息,方便的记录到指定的位置
- 可以随时以开关的形式控制日志的启停,无需侵入到源代码中去修改
日志体系结构:
- 日志框架:
- JUL
- Log4j
- Logback
- 日志接口:设计日志框架的一套标准,日志框架需要实现这些
- Simple Logging Facade for Java
- Commons
- 公司主要使用的是Logback框架
- logback-core:基础模块,是其他俩个模块依赖的基础
- logback-classic :完整实现了slf4j api的模块
- logback-access:与tomcat和jetty等Servlet容器集成,以提供Http访问日志的功能
- 至少需要在项目中整合如下三个模块
- slf4j-api:日志接口
- logback-core
- logback-classic
Logback快速入门
-
将三个包导入到项目中
-
将Logback框架核心配置文件logback.xml直接拷贝到src目录下(必须)
-
<?xml version="1.0" encoding="UTF-8"?> <configuration> <!-- CONSOLE :表示当前的日志信息是可以输出到控制台的。 --> <appender name="CONSOLE" class="ch.qos.logback.core.ConsoleAppender"> <!--输出流对象 默认 System.out 改为 System.err--> <target>System.out</target> <encoder> <!--格式化输出:%d表示日期,%thread表示线程名,%-5level:级别从左显示5个字符宽度 %msg:日志消息,%n是换行符--> <pattern>%d{yyyy-MM-dd HH:mm:ss.SSS} [%-5level] %c [%thread] : %msg%n</pattern> </encoder> </appender> <!-- File是输出的方向通向文件的 --> <appender name="FILE" class="ch.qos.logback.core.rolling.RollingFileAppender"> <encoder> <pattern>%d{yyyy-MM-dd HH:mm:ss.SSS} [%thread] %-5level %logger{36} - %msg%n</pattern> <charset>utf-8</charset> </encoder> <!--日志输出路径--> <!--可以自己配置路径--> <file>D:/log/itheima-data.log</file> <!--指定日志文件拆分和压缩规则--> <rollingPolicy class="ch.qos.logback.core.rolling.SizeAndTimeBasedRollingPolicy"> <!--通过指定压缩文件名称,来确定分割文件方式--> <fileNamePattern>D:/log/itheima-data-%i-%d{yyyy-MM-dd}-.log.gz</fileNamePattern> <!--文件拆分大小--> <maxFileSize>1MB</maxFileSize> </rollingPolicy> </appender> <!-- 1、控制日志的输出情况:如,开启日志,取消日志 --> <root level="debug"> <appender-ref ref="CONSOLE"/> <appender-ref ref="FILE" /> </root> </configuration>
-
-
创建Logback框架提供的Logger对象,然后用Logger对象调用其提供的方法就可以记录系统的日志
public class test { // 1.创建一个日志对象 public static final Logger LOGER = LoggerFactory.getLogger("LogBackTest"); public static void main(String[] args) { try { LOGER.info("chu方法开始执行"); chu(10, 0); LOGER.info("chu方法执行成功"); } catch (Exception e) { LOGER.error("chu方法执行失败,出现bug"); } } public static void chu(int a, int b){ LOGER.debug("参数a:"+a); LOGER.debug("参数b:"+b); int c = a / b; LOGER.info("结果是:"+c); } }
Logback设置日志级别
-
日志级别指的是日志信息的类型,日志都会分级,常见的日志级别如下:(优先级一次提升)
日志级别 说明 trace 追踪,指明程序运行轨迹 debug 调试,实际应用中一般作为最低级别,trace一般很少用 info 输出重要的运行信息,数据连接,网络连接,io操作等 warn 警告信息,可能会发生问题,使用较多 error 错误信息,较多使用 -
只有日志的级别是大于或等于核心配置文件配置的日志级别,才会被记录,否则不记录

















 1948
1948

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









