






目录
- 什么是循环依赖
- 1、自身依赖
- 2、两个Bean之间的循环依赖
- 3、多个Bean之间的循环依赖
- 为什么会出现循环依赖
- 什么情况下的循环依赖可以被处理
- Spring三级缓存是怎样解决循环依赖问题的
- 为什么二级缓存不行
- @Trasaction会导致三级缓存失效!!!!!
什么是循环依赖
1、自身依赖
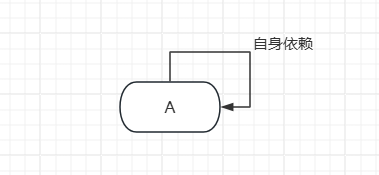
@Component
public class SelfDependencyBean {
@Autowired
private SelfDependencyBean selfDependencyBean;
public void doSomething() {
selfDependencyBean.doSomething();
}
}2、两个Bean之间的循环依赖
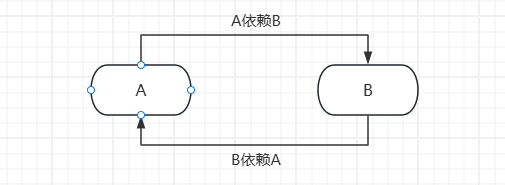
@Component
public class BeanA {
@Autowired
private BeanB beanB;
public void doSomething() {
beanB.doSomething();
}
}
@Component
public class BeanB {
@Autowired
private BeanA beanA;
public void doSomething() {
beanA.doSomething();
}
}3、多个Bean之间的循环依赖
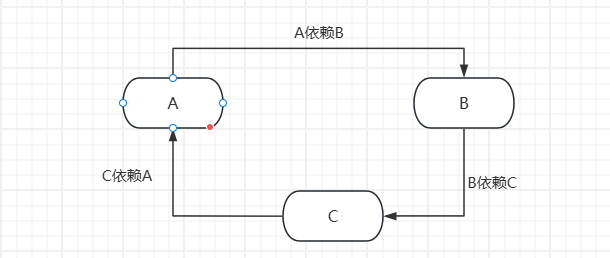
@Component
public class BeanA {
@Autowired
private BeanB beanB;
public void doSomething() {
beanB.doSomething();
}
}
@Component
public class BeanB {
@Autowired
private BeanC beanC;
public void doSomething() {
beanC.doSomething();
}
}
@Component
public class BeanC {
@Autowired
private BeanA beanA;
public void doSomething() {
beanA.doSomething();
}
} 循环依赖是依赖注入框架(如Spring)中常见的问题,可能导致Bean创建失败或运行时错误,一般会抛出BeanCurrentlyInCreationException异常。
为什么会出现循环依赖
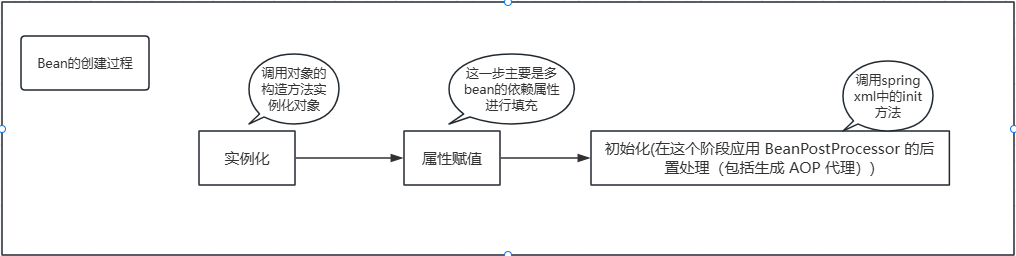
以AB相互循环依赖(字段注入方式)为例:
①首先A进行实例化,然后进行属性赋值,发现A依赖于B,遂先去创建B
②然后B进行实例化,然后也会进行属性赋值,发现B又依赖于A,然后发现此时A是一个半成品状态,但是B需要一个完整的A,但是此时A在等待B,所以就出现了循环问题
③Spring 无法继续推进 A,B 的初始化,最终抛出BeanCurrentlyInCreationException,表示检测到循环依赖
什么情况下的循环依赖可以被处理
Spring解决循环依赖是有前置条件的:
①Bean必须是单例的
② 依赖注入的方式不能全是构造器注入
为什么都是构造器注入的时候,Spring无法解决循环依赖问题?
@Component
public class A {
//构造器注入
public A(B b) {
}
}
@Component
public class B {
//构造器注入
public B(A a){
}
}
因为构造器注入必须在实例化时完成依赖注入,无法提前暴露Bean引用,
而Spring解决循环依赖问题依靠的三级缓存在属性注入阶段,
也就是说调用构造函数时还未能放入三级缓存中,所以无法解决构造器注入的循环依赖问题。
Spring三级缓存是怎样解决循环依赖问题的
首先在Springboot2.6版本以上三级缓存是默认被关闭的,如需打开:
# application.yml
spring:
main:
allow-circular-references: true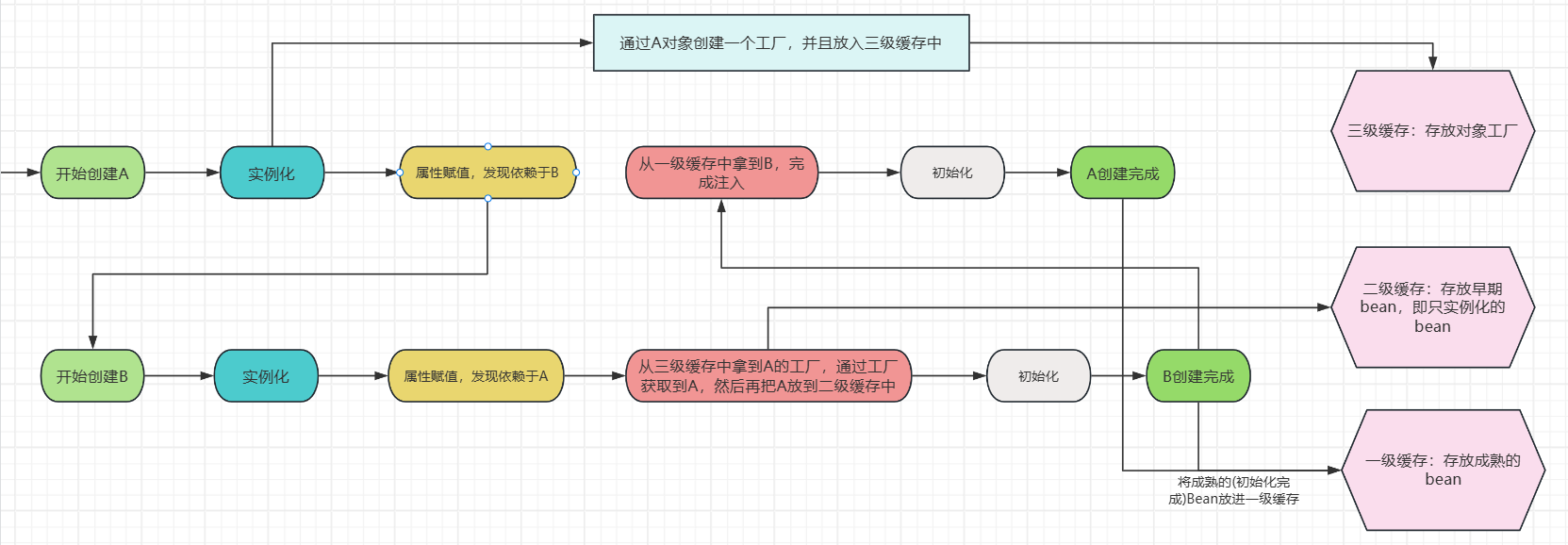
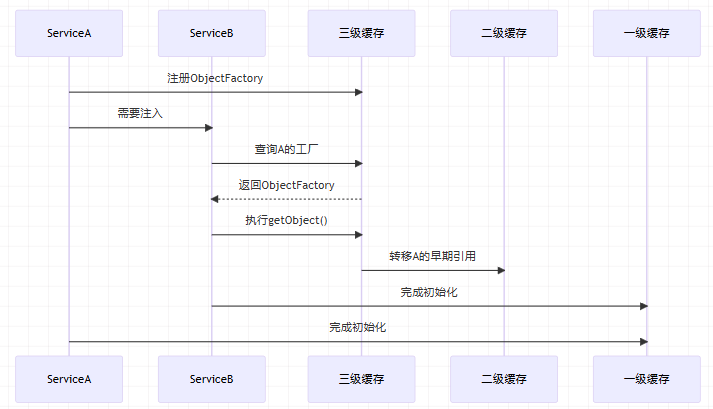
①开始创建A-->实例化并且通过ObjectFactory暴露在三级缓存中-->属性填充B
②此时B还没有创建,所以要先创建B-->实例化B-->属性注入A,此时发现一级缓存中并没有A并且A还在创建过程中,所以就去三级缓存中找到工厂创建出一个半成品A-->把A放进二级缓存中-->B完成属性注入-->B初始化创建完成放入一级缓存中
③又回到创建A的过程-->继续属性填充B,此时一级缓存中有B-->初始化创建完成放入一级缓存,清空二级和三级缓存。
B中提前注入了一个没有经过初始化的A类型对象不会有问题吗?答:不会,虽然在创建B时会提前给B注入了一个还未初始化的A对象,但是在创建A的流程中一直使用的是注入到B中的A对象的引用,之后会根据这个引用对A进行初始化,所以这是没有问题的。
为什么二级缓存不行
不是二级缓存不行,如果Bean都不要AOP代理,二级缓存确实可以解决循环依赖问题。但在实际场景中,Spring必须支持AOP代理
①当Bean没有AOP代理的需求的时候,二级缓存是可以解决循环依赖的。

②当Bean需要AOP代理的时候,二级缓存会导致代理对象和原始对象引用不一致问题

③三级缓存就可以完美解决以上问题

如果要使用二级缓存解决循环依赖,意味着所有Bean在实例化后就要完成AOP代理,这样违背了Spring设计的原则,Spring在设计之初就是通过AnnotationAwareAspectJAutoProxyCreator这个后置处理器来在Bean生命周期的最后一步来完成AOP代理,而不是在实例化后就立马进行AOP代理。
记一次项目中的问题
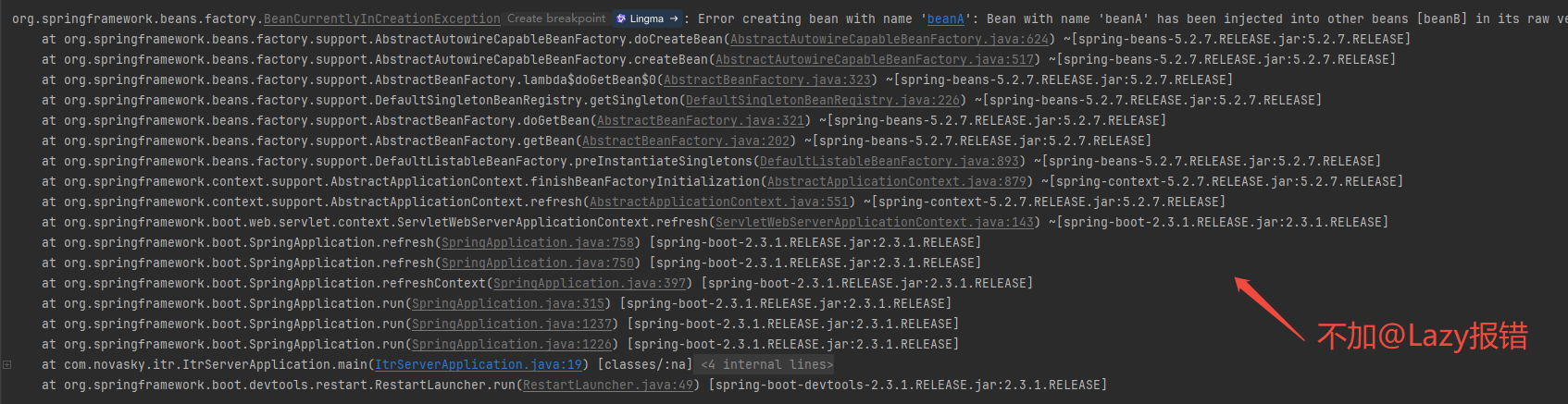
在SpringBoot2.3版本下,正常的循环依赖可以完美解决,但是当在方法上加@Transaction后就会启动报错。但是加上@Lazy之后,又正常启动。

@Service
public class BeanB {
@Autowired
private BeanA beanA;
@Transactional
public void Test(){
System.out.println("222222");
}
}
@Service
public class BeanA {
@Autowired
private BeanB beanB;
@Transactional
public void Test(){
System.out.println("222222");
}
}
@Service
public class BeanB {
@Lazy
@Autowired
private BeanA beanA;
@Transactional
public void Test(){
System.out.println("222222");
}
}
@Service
public class BeanA {
@Lazy
@Autowired
private BeanB beanB;
@Transactional
public void Test(){
System.out.println("222222");
}
}
//加了就正常启动
而在SpringBoot2.6版本下,方法上直接加@Transaction也是可以正常启动。


本人实在没有找到明确的原因,只能看一下AI的回答



















 1457
1457

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









