



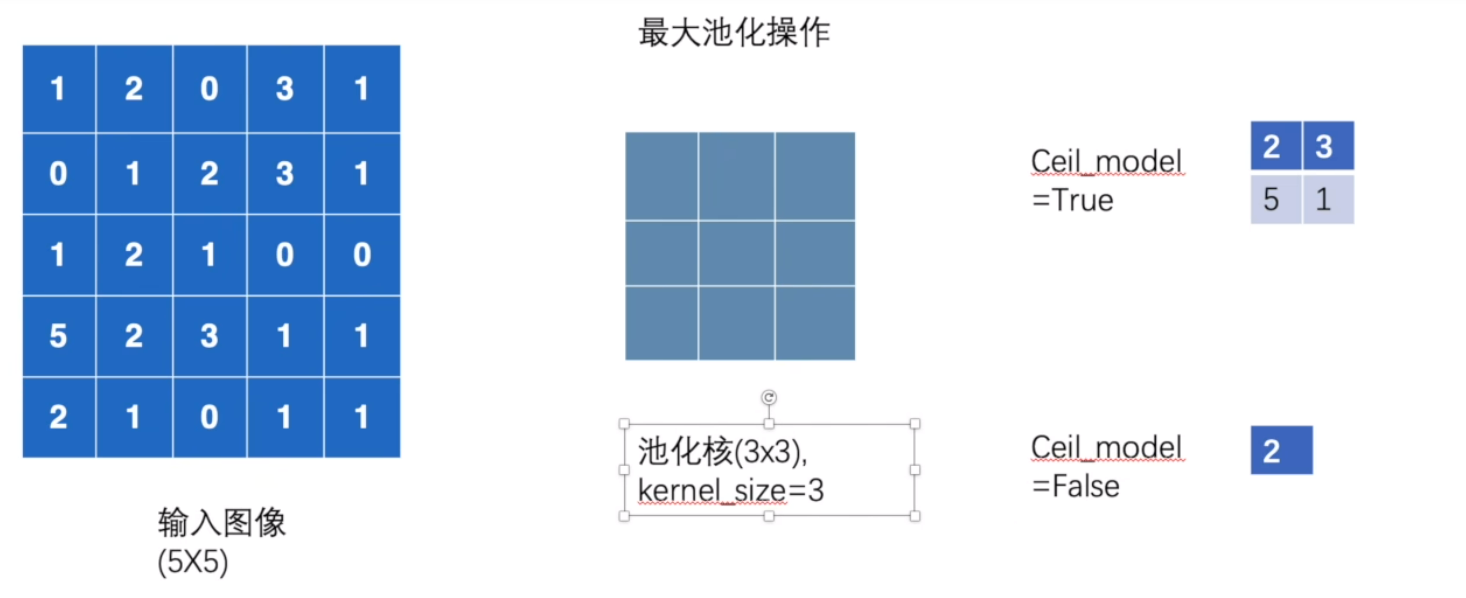
最大池化的使用
卷积:通过可学习的卷积核对输入进行局部加权求和,核心是提取并转换特征。
最大池化:通过固定窗口取最大值,核心是对特征降维并增强鲁棒性。
# 导入PyTorch核心库,用于张量操作和神经网络功能的基础支持
import torch
# 导入torchvision的datasets模块,用于加载预设的图像数据集(如CIFAR10)
import torchvision.datasets
# 从torch中导入nn模块,包含构建神经网络的基础组件(如层、激活函数等)
from torch import nn
# 从nn模块中导入MaxPool2d类,用于创建二维最大池化层(下采样操作)
from torch.nn import MaxPool2d
# 从torch.utils.data导入DataLoader,用于批量加载数据集并支持并行处理
from torch.utils.data import DataLoader
# 从torch.utils.tensorboard导入SummaryWriter,用于将数据写入TensorBoard进行可视化
from torch.utils.tensorboard import SummaryWriter
# 定义一个5x5的二维张量,模拟单通道特征图(数值为示例,用于演示池化操作的输入格式)
# 注:该张量在后续实际处理CIFAR10数据时未被使用,仅作为格式参考
input = torch.tensor([[1, 2, 0, 3, 1],
[0, 1, 2, 3, 1],
[1, 2, 1, 0, 0],
[5, 2, 3, 1, 1],
[2, 1, 0, 1, 1]])
# 调整上述模拟张量的形状为4维:(N, C, H, W),符合PyTorch对特征图的输入格式要求
# 参数说明:
# -1:自动计算批量大小(N),确保总元素数不变(此处N=1,因原始张量共25个元素:1*1*5*5=25)
# 1:通道数(C,单通道)
# 5,5:特征图的高度(H)和宽度(W)
# 注:该操作仅为演示格式,后续实际处理的是CIFAR10数据,故该input未参与网络计算
input = torch.reshape(input, (-1, 1, 5, 5))
# 打印调整形状后的模拟张量,验证维度是否正确(预期输出:torch.Size([1, 1, 5, 5]))
print(input)
# 加载CIFAR10测试数据集
# 参数说明:
# "./official_dataset":数据集保存路径
# train=False:加载测试集(非训练集)
# download=False:不自动下载数据集(假设已提前下载到指定路径)
# transform=torchvision.transforms.ToTensor():将图像转为PyTorch张量(格式为CHW,像素值归一化到[0,1])
dataset = torchvision.datasets.CIFAR10("./official_dataset", train=False, download=False,
transform=torchvision.transforms.ToTensor())
# 创建DataLoader,用于批量加载CIFAR10数据集
# 参数说明:
# dataset:要加载的数据集(此处为CIFAR10测试集)
# batch_size=64:每次加载64张图像作为一个批次
dataloader = DataLoader(dataset, batch_size=64)
# 定义自定义神经网络类MyNetwork,继承自nn.Module(PyTorch中所有神经网络的基类)
class MyNetwork(nn.Module):
def __init__(self):
# 调用父类nn.Module的构造函数,确保基类被正确初始化
super(MyNetwork, self).__init__()
# 定义一个最大池化层maxpool1
# 参数说明:
# kernel_size=3:池化核的尺寸为3x3(每次对3x3的区域进行池化)
# 池化核滑动步长默认与池化核尺寸一致 该案例步长为3
# ceil_mode=False:当池化窗口滑动到边缘无法完整覆盖时,采用向下取整(丢弃不完整窗口)
# 最大池化的核心作用:从池化窗口中取最大值,实现特征降维(减少数据量)和特征抽象(增强鲁棒性)
self.maxpool1 = MaxPool2d(kernel_size=3, ceil_mode=False)
# 定义前向传播方法,描述数据在网络中的流动过程
def forward(self, input):
# 将输入数据通过最大池化层,得到池化后的输出特征图
output = self.maxpool1(input)
return output
# 创建自定义网络的实例(加载定义好的最大池化层)
mynetwork = MyNetwork()
# 以下部分为注释掉的代码,用于演示对上述模拟张量的池化操作(未参与实际数据集处理)
# output = mynetwork(input) # 将模拟张量传入网络,执行池化
# print(output) # 打印池化结果,观察尺寸和数值变化
# 创建SummaryWriter实例,日志文件将保存到"logs"目录,用于TensorBoard可视化
writer = SummaryWriter("logs")
# 初始化步长计数器,用于在TensorBoard中区分不同批次的图像
step = 0
# 遍历DataLoader,每次获取一个批次的CIFAR10数据
for data in dataloader:
# 从批次数据中分离出图像(imgs)和对应的标签(target)
imgs, target = data
# 将当前批次的输入图像写入TensorBoard,标签为"Input",步长为当前step
writer.add_images("Input", imgs, step)
# 将输入图像传入网络,通过最大池化层得到输出特征图
output = mynetwork(imgs)
# 将池化后的输出特征图写入TensorBoard,标签为"Output",步长为当前step
# 注:CIFAR10图像为3通道,池化不改变通道数,故output仍为3通道,可直接可视化
writer.add_images("Output", output, step)
# 步长计数器递增,用于区分下一个批次
step = step + 1
# 关闭SummaryWriter,确保所有日志数据被写入文件
writer.close()
效果展示


非线性激活
简单说:没有激活函数,网络是 “一根直线”,只能画直线;有了激活函数,网络能 “画曲线”,才能描绘现实世界的复杂规律。
# 导入PyTorch核心库,用于张量操作和神经网络基础功能
import torch
# 导入torchvision的datasets模块,用于加载预设图像数据集(如CIFAR10)
import torchvision.datasets
# 从torch中导入nn模块,包含构建神经网络的基础组件(层、激活函数等)
from torch import nn
# 从nn模块中导入常用非线性激活函数:ReLU和Sigmoid
from torch.nn import MaxPool2d, ReLU, Sigmoid
# 从torch.utils.data导入DataLoader,用于批量加载数据集并支持并行处理
from torch.utils.data import DataLoader
# 从torch.utils.tensorboard导入SummaryWriter,用于将数据写入TensorBoard可视化
from torch.utils.tensorboard import SummaryWriter
# 定义一个2x2的二维张量,模拟单通道特征图(包含正负值,用于演示激活函数效果)
input = torch.tensor([[1, -0.5],
[-1, 3]])
# 调整输入张量形状为4维:(N, C, H, W),符合PyTorch对网络输入的格式要求
# -1:自动计算批量大小(此处N=1,因总元素数为4=1×1×2×2)
# 1:通道数(C=1,单通道)
# 2,2:特征图的高度(H)和宽度(W)
input = torch.reshape(input, (-1, 1, 2, 2))
# 打印调整后的张量形状(预期输出:torch.Size([1, 1, 2, 2]))
print(input.shape)
# 加载CIFAR10测试数据集
# 参数说明:
# "./official_dataset":数据集保存路径
# train=False:加载测试集(非训练集)
# download=False:不自动下载(假设已提前下载)
# transform=...ToTensor():将图像转为PyTorch张量(格式CHW,像素值归一化到[0,1])
dataset = torchvision.datasets.CIFAR10("./official_dataset", train=False, download=False,
transform=torchvision.transforms.ToTensor())
# 创建DataLoader,用于批量加载CIFAR10数据
# 参数:dataset=上述数据集,batch_size=64(每次加载64张图像)
dataloader = DataLoader(dataset, batch_size=64)
# 定义自定义神经网络类MyNetwork,继承自nn.Module(PyTorch所有网络的基类)
class MyNetwork(nn.Module):
def __init__(self):
# 调用父类构造函数,确保基类初始化
super(MyNetwork, self).__init__()
# 定义ReLU激活函数(用于后续可能的切换,当前未使用)
self.relu1 = ReLU()
# 定义Sigmoid激活函数(当前网络使用的激活函数)
self.sigmoid1 = Sigmoid()
# 定义前向传播:描述数据在网络中的流动
def forward(self, input):
# 将输入通过Sigmoid激活函数处理,输出范围被映射到[0,1]
output = self.sigmoid1(input)
return output
# 创建网络实例(加载定义的激活函数)
mynetwork = MyNetwork()
# 创建SummaryWriter,日志保存到"logs"目录,用于TensorBoard可视化
writer = SummaryWriter("logs")
# 初始化步长计数器,用于区分TensorBoard中的不同批次数据
step = 0
# 遍历DataLoader,每次获取一个批次的CIFAR10数据
for data in dataloader:
# 分离图像(imgs)和标签(target),imgs形状为(64,3,32,32)
imgs, target = data
# 将原始输入图像写入TensorBoard,标签为"Input"
writer.add_images("Input", imgs, step)
# 将图像输入网络,通过Sigmoid激活函数处理
output = mynetwork(imgs)
# 将激活函数处理后的输出写入TensorBoard,标签为"Output"
writer.add_images("Output", output, step)
# 步长递增,准备下一批次
step = step + 1
# 关闭SummaryWriter,确保日志数据写入完成
writer.close()
对比效果



















 1081
1081

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









