



卷积操作
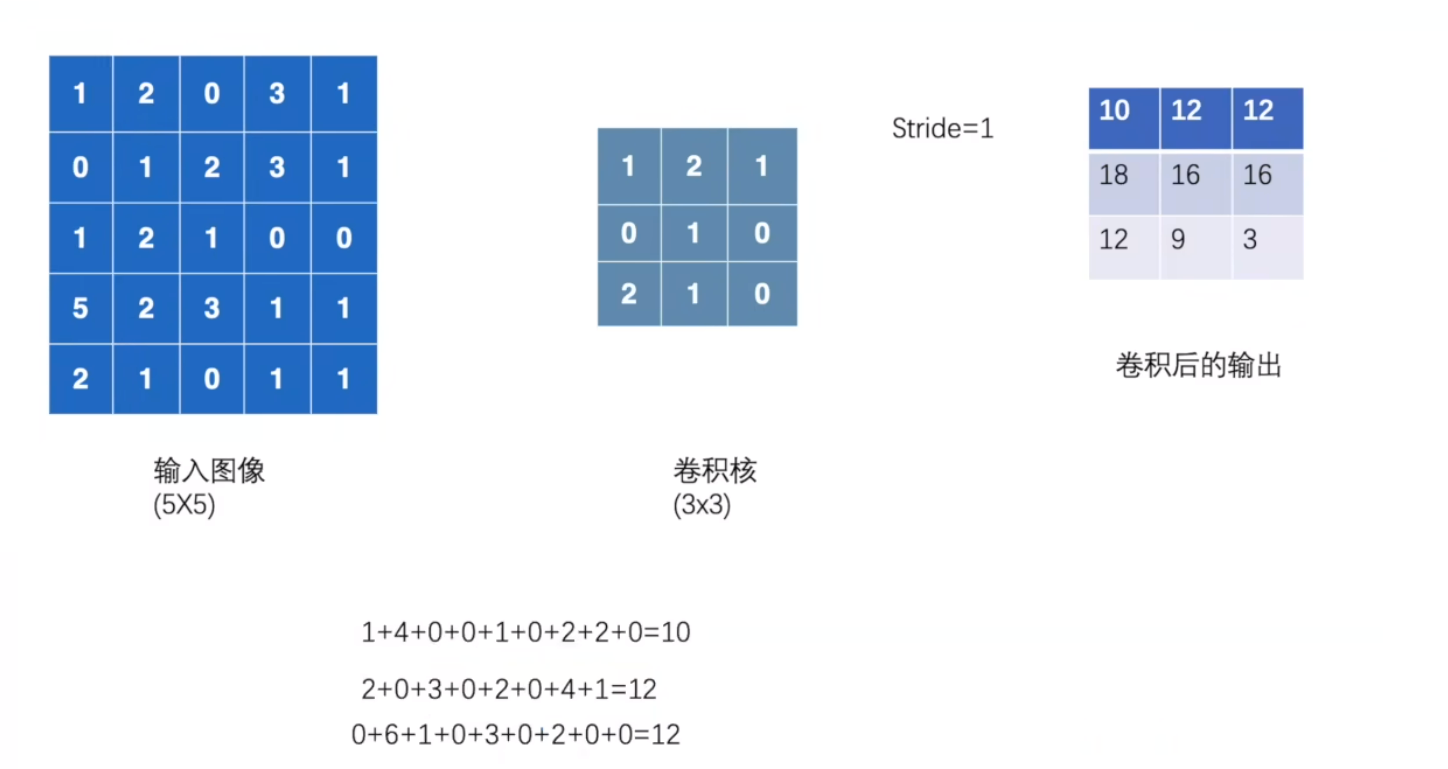
输出值 = 输入图像与卷积核对应位置数值相乘再相加
卷积核的具体数值(权重参数)是通过模型训练学习得到的,而非人工设定,过程如下:
- 初始化:网络创建时,卷积核的数值会被随机初始化(例如服从正态分布或均匀分布)。
- 训练学习:通过反向传播算法,根据模型的预测误差(损失函数)不断调整卷积核的数值,最终使得卷积核能有效提取输入数据的特征(如边缘、纹理等)。
# 导入PyTorch库,用于张量操作和神经网络功能
import torch
# 导入PyTorch的nn.functional模块,简称为F,包含各类函数式神经网络操作(如卷积、激活函数等)
import torch.nn.functional as F
# 定义输入特征图(二维张量),模拟一个5x5的单通道特征图
# 数值仅为示例,可理解为图像的像素值或中间层特征
input = torch.tensor([[1, 2, 0, 3, 1],
[0, 1, 2, 3, 1],
[1, 2, 1, 0, 0],
[5, 2, 3, 1, 1],
[2, 1, 0, 1, 1]])
# 定义卷积核(二维张量),模拟一个3x3的卷积核
# 卷积核是提取特征的"过滤器",数值决定了对输入特征的加权方式
kernel = torch.tensor([[1, 2, 1],
[0, 1, 0],
[2, 1, 0]])
# 调整输入特征图的形状为4维张量:(N, C, H, W)
# N(batch size):批量大小,此处为1(单张输入)
# C(in_channels):输入通道数,此处为1(单通道)
# H(height):特征图高度,此处为5
# W(width):特征图宽度,此处为5
# 原因:F.conv2d要求输入必须是4维张量,符合PyTorch默认的NCHW格式
input = torch.reshape(input, (1, 1, 5, 5))
# 调整卷积核的形状为4维张量:(O, C, K_H, K_W)
# O(out_channels):输出通道数,此处为1(单通道输出)
# C(in_channels):输入通道数,必须与输入特征图的C一致(此处为1)
# K_H(kernel height):卷积核高度,此处为3
# K_W(kernel width):卷积核宽度,此处为3
kernel = torch.reshape(kernel, (1, 1, 3, 3))
# 打印调整形状后的输入特征图(验证维度是否正确)
print(input)
# 打印调整形状后的卷积核(验证维度是否正确)
print(kernel)
# 1. 执行二维卷积操作(步长stride=1,无填充padding=0)
# F.conv2d函数参数说明:
# - input:输入特征图,格式为(N, C, H, W)
# - weight:卷积核,格式为(O, C, K_H, K_W)
# - stride:步长,控制卷积核每次滑动的距离(默认1),可设为单值(如1)或 tuple(如(1,1)),表示H和W方向的步长
# 输出形状计算:
# 输出高度H_out = (H - K_H) / stride + 1 = (5 - 3)/1 + 1 = 3
# 输出宽度W_out = (W - K_W) / stride + 1 = (5 - 3)/1 + 1 = 3
# 因此输出形状为(1, 1, 3, 3)
output = F.conv2d(input, kernel, stride=1)
print(output) # 打印卷积结果
# 2. 执行二维卷积操作(步长stride=2,无填充padding=0)
# stride=2:卷积核每次沿H和W方向滑动2个单位
# 输出形状计算:
# H_out = (5 - 3)/2 + 1 = 2/2 + 1 = 2
# W_out = (5 - 3)/2 + 1 = 2/2 + 1 = 2
# 因此输出形状为(1, 1, 2, 2)
output2 = F.conv2d(input, kernel, stride=2)
print(output2) # 打印卷积结果
# 3. 执行二维卷积操作(步长stride=1,填充padding=1)
# padding:在输入特征图的边缘填充像素(默认0),此处padding=1表示H和W方向各填充1圈0
# 填充后输入特征图尺寸变为:H_pad = 5 + 2*1 = 7,W_pad = 5 + 2*1 = 7
# 输出形状计算:
# H_out = (7 - 3)/1 + 1 = 4 + 1 = 5
# W_out = (7 - 3)/1 + 1 = 4 + 1 = 5
# 因此输出形状为(1, 1, 5, 5)(与原始输入尺寸一致,这是padding的常见用途)
output3 = F.conv2d(input, kernel, stride=1, padding=1)
print(output3) # 打印卷积结果
卷积层实战
# 导入PyTorch核心库,用于张量操作和神经网络构建
import torch
# 导入torchvision库,包含常用数据集、图像转换工具等
import torchvision
# 从torch中导入nn模块,用于构建神经网络层
from torch import nn
# 从nn模块中导入Conv2d类,用于创建二维卷积层
from torch.nn import Conv2d
# 从torch.utils.data导入DataLoader,用于批量加载数据集
from torch.utils.data import DataLoader
# 从torch.utils.tensorboard导入SummaryWriter,用于TensorBoard可视化
from torch.utils.tensorboard import SummaryWriter
# 加载CIFAR10测试数据集
# 参数说明:
# "./official_dataset":数据集保存路径
# train=False:加载测试集(非训练集)
# transform=torchvision.transforms.ToTensor():将图像转为PyTorch张量(格式为CHW,像素值归一化到[0,1])
# download=False:不自动下载数据集(假设已提前下载)
dataset = torchvision.datasets.CIFAR10("./official_dataset", train=False, transform=torchvision.transforms.ToTensor(),
download=False)
# 创建DataLoader,用于批量处理数据集
# 参数说明:
# dataset:要加载的数据集(此处为CIFAR10测试集)
# batch_size=64:每次加载64张图像作为一个批次
# 注:变量名"dataloador"存在拼写错误,正确应为"dataloader"
dataloador = DataLoader(dataset, batch_size=64)
# 定义自定义神经网络类MyNetwork,继承自nn.Module(PyTorch中所有神经网络的基类)
class MyNetwork(nn.Module):
def __init__(self):
# 调用父类nn.Module的构造函数,确保基类初始化
super(MyNetwork, self).__init__()
# 定义一个二维卷积层conv1
# 参数说明:
# in_channels=3:输入图像的通道数(CIFAR10为RGB三通道)
# out_channels=6:卷积输出的通道数(6个不同的卷积核)
# kernel_size=3:卷积核的尺寸为3x3
# stride=1:卷积核每次滑动的步长为1
# padding=0:不进行边缘填充
# 输入图像通道数与卷积核通道数一致
# 输出图像通道数与卷积核个数一致
self.conv1 = Conv2d(in_channels=3, out_channels=6, kernel_size=3, stride=1, padding=0)
# 定义前向传播方法,描述数据在网络中的流动
def forward(self, x):
# 将输入x通过conv1卷积层,得到输出x
x = self.conv1(x)
return x
# 创建自定义网络的实例
mynetwork = MyNetwork()
# 创建SummaryWriter实例,日志文件保存到"logs"目录,用于TensorBoard可视化
writer = SummaryWriter("logs")
# 初始化步长计数器,用于TensorBoard区分不同批次的图像
step = 0
# 遍历DataLoader,每次获取一个批次的数据
for data in dataloador:
# 从批次数据中分离出图像和标签(CIFAR10的每条数据包含图像和对应的类别标签)
imgs, targets = data
# 将图像输入网络,得到卷积后的输出
output = mynetwork(imgs)
# 打印输入图像和输出特征图的形状,用于验证卷积效果
# imgs.shape:[64, 3, 32, 32](批量大小64,3通道,32x32像素)
# output.shape:[64, 6, 30, 30](批量大小64,6通道,卷积后尺寸30x30,因32-3+1=30)
# 输出高度 = (输入高度 - 卷积核高度 + 2×padding) ÷ stride + 1
# 输出宽度 = (输入宽度 - 卷积核宽度 + 2×padding) ÷ stride + 1
print(imgs.shape)
print(output.shape)
# 调整输出特征图的形状,以适配TensorBoard的可视化要求(需3通道)
# torch.reshape(output, (-1, 3, 30, 30)):
# -1:保持批量大小不变(仍为64)
# 3:将6通道转为3通道(实际是将6通道按顺序合并为2组3通道,方便可视化)
# 30,30:保持特征图的高和宽不变
output = torch.reshape(output, (-1, 3, 30, 30))
# 将输入图像批量写入TensorBoard,标签为"input",步长为当前step
# add_images用于批量图像可视化,支持NCHW格式(64,3,32,32)
writer.add_images("input", imgs, step)
# 将调整形状后的输出特征图批量写入TensorBoard,标签为"output",步长为当前step
writer.add_images("output", output, step)
# 步长计数器递增,用于区分下一个批次
step = step + 1


















 1081
1081

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









