






目录
TfidfVectorizer
作用:统计中文词出现的频率,频率最大的词即为该文本重要的词语
进行文本特征抽取:

data4=['我是陈冠希,我现在遇到了一帮很坏很坏的人。','我需要你们转帐300块,不,是300亿啊!']
data_newnew=[]
for sent in data4:
data_newnew.append(cut_words(sent))
transfer=TfidfVectorizer()
data_final=transfer.fit_transform(data_newnew)
print(data_final.toarray())
print("特征名字:",transfer.get_feature_names_out())

特征预处理 processing:
定义:
通过一些转换函数将特征数据转化成更加符合算法模型的数据
归一化 minmaxscaler:
定义:
通过对原始数据进行变换把数据映射到0,1之间
作用:
特征的单位或大小相差较大,使得方差偏移较多,容易支配目标结果
计算原理:

代码实现:
#定义:通过一些转换函数将特征数据转化成更加符合算法模型的数据
import pandas as pd
from sklearn.preprocessing import MinMaxScaler
'''归一化:通过对原始数据进行变换把数据映射到0,1之间'''
data=pd.read_csv("归一化数据")
data=data.iloc[:,:3]
print(data)
#2.实例一个转换器类
transfer=MinMaxScaler(feature_range=(1,2)) #将数据进行调节,默认在0,1之间
#3.调用fit_transform
data_new=transfer.fit_transform(data)
print(data_new)

缺点:
健壮性较差,容易受到较大值和较小值的影响,只适合小规模数据的操作
标准化 StandardScale
定义:
通过对原始数据进行变换把数据变换到均值为0,标准差为1范围内
计算原理:

代码实现:
data=pd.read_csv("归一化数据")
data=data.iloc[:,:3]
print(data)
#2.实例一个转换器类
transfer=StandardScaler()#将数据进行调节,默认在0,1之间
#3.调用fit_transform
data_new=transfer.fit_transform(data)
print(data_new) 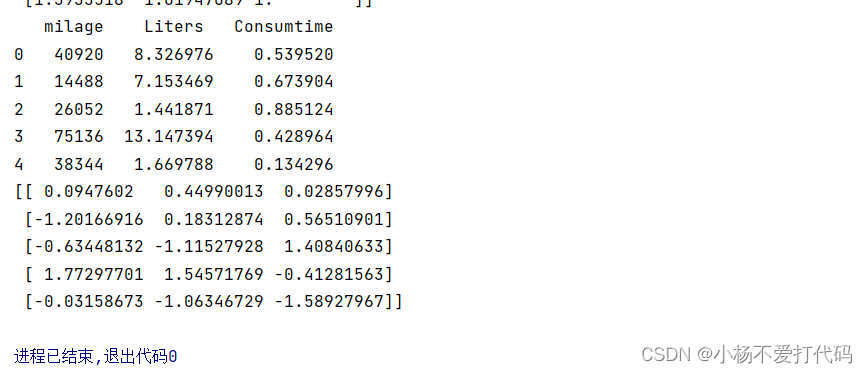
标准化与归一化比较
●对于归一化来说:如果出现异常点,影响了最大值和最小值,那么结果显
然会发生改变
●对于标准化来说:如果出现异常点,由于具有一定数据量,少量的异常点
对于平均值的影响不大,从而方差改变较小。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









