







目录
DataFrame
基础
import pandas as pd
import numpy as np
t1=pd.DataFrame(np.arange(12).reshape(3,4),index=["a","b","c"],columns=list('wxyz'))
print(t1)

字典
d1={"name":["马化腾","马云"],"age":[50,52],"tel":[10086,10085]}
t2=pd.DataFrame(d1)
print(t2) 
列表
d2=[{"name":"马化腾","age":50,"tel":10086},{"name":"马云","age":52,"tel":10085}]
t3=pd.DataFrame(d2)
print(t3)
排序
df=df.sort_values(by='人气值',ascending=False)
by表示需要排序的内容,ascending为true默认升序排序
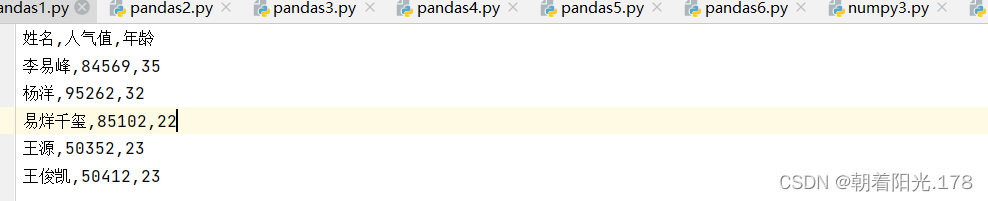
df=pd.read_csv("D:\\python\\5.数据分析\\test")
df=df.sort_values(by='人气值',ascending=False)
df=pd.DataFrame(df)
print(df)

索引
print(df[:2]) #取行
print(df["年龄"])#取列
print(df[(25<df["年龄"])&(df["年龄"]<35)])
print(df[df["姓名"].str.len()>2]) 


print(t1.loc["a","Z"])#取一个值
loc与iloc
loc[]:通过标签索引行数据,iloc[]:通过位置索引行数据
t1=pd.DataFrame(np.arange(12).reshape(3,4),index=list("abc"),columns=["W","X","Y","Z"])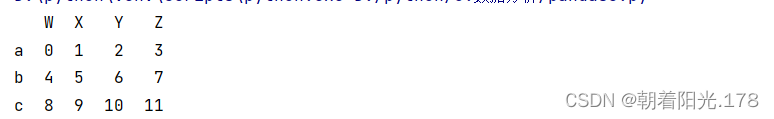
print(t1.loc["a","Z"])#取一个值,结果为3print(t1.loc["a"]) #取一行print(t1.loc[:"b"]) #取多行print(t1.loc["a":"c",["W","Z"]]) #从a列到c列print(t1.iloc[:,[2,1]])
print(t1.iloc[1:,:2]) 
nan值

判断nan
#判断nan
t1.iloc[[1,2],[2,3]]=np.nan
print(pd.isnull(t1))

删除nan
#删除nan
print(t1.dropna(axis=0,how="any",inplace=False)) #any表示该行有nan就删除这一行,
print(t1.dropna(axis=0,how="all",inplace=False)) #inplace是True就直接替换t1

替换nan
#替换nan
t1["Y"]=t1["Y"].fillna(t1["Y"].mean())
print(t1)
t1=t1.fillna(t1.mean())
print(t1)



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









