







目录
三、知识库(Knowledge Base)—— 专业能力的基石
在当今快速发展的人工智能领域,LangChain 已成为连接大语言模型(LLM)与实际应用的最流行框架之一。本文将从架构师视角,深度解析 LangChain 的核心工作流程,帮助开发者掌握构建智能应用的系统方法论。
一、LangChain 整体架构概览
LangChain 的工作流程可以形象地理解为一条"智能流水线",主要由以下三大核心模块构成:
-
处理链(Chains):问题处理的中枢神经系统
-
知识库(Knowledge Base):长期记忆存储系统
-
记忆(Memory):短期对话状态保持
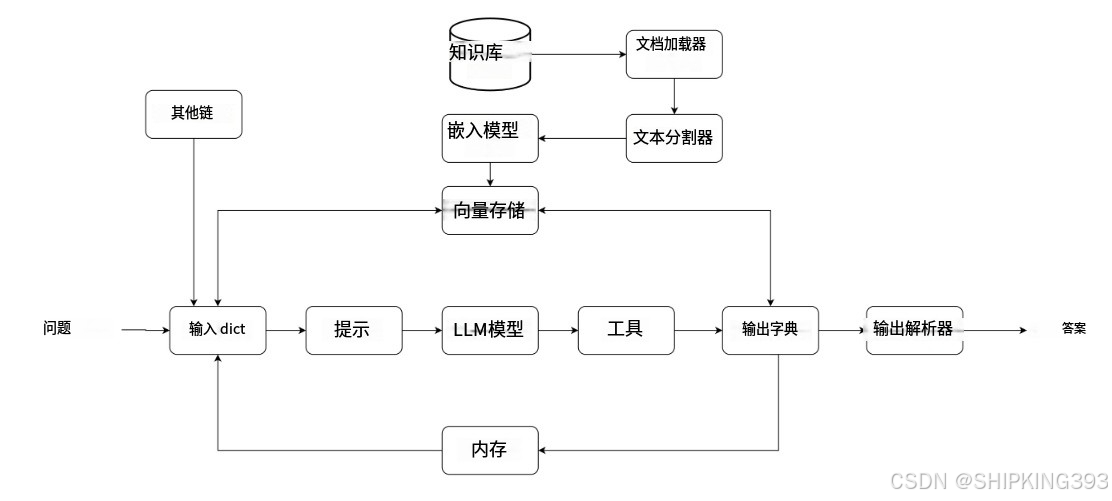
二、处理链(Chains)—— 智能处理的核心引擎
1. 输入处理阶段
# 典型输入处理代码示例
from langchain.schema import HumanMessage
input_dict = {
"question": "公司年假政策是什么?",
"context": "当前用户是入职2年的工程师"
}-
问题规范化:将原始输入转换为结构化字典
-
提示工程:通过PromptTemplate构建高质量提示
from langchain.prompts import PromptTemplate
prompt = PromptTemplate(
template="作为{role},请回答:{question}",
input_variables=["role", "question"]
)2. 模型推理阶段
# 支持的主流LLM接入
from langchain.llms import OpenAI, HuggingFaceHub
llm = OpenAI(temperature=0.7) # 或 HuggingFaceHub(repo_id="google/flan-t5-xl")-
多模型支持:OpenAI、Anthropic、HuggingFace等
-
参数调控:temperature、max_tokens等精细控制
3. 工具集成
# 工具调用示例
from langchain.tools import Tool
calculator = Tool(
name="Calculator",
func=lambda x: eval(x),
description="用于数学计算"
)-
外部工具:计算器、API调用、数据库查询等
-
自动选择:Agent可自动选择合适工具
4. 输出解析
# 结构化输出解析
from langchain.output_parsers import StructuredOutputParser
parser = StructuredOutputParser.from_response_schemas([
ResponseSchema(name="answer", description="回答内容"),
ResponseSchema(name="source", description="政策依据")
])-
标准化输出:JSON、XML等格式
-
后处理:结果过滤、敏感信息处理
三、知识库(Knowledge Base)—— 专业能力的基石
1. 文档加载
# 多格式文档加载
from langchain.document_loaders import PyPDFLoader, WebBaseLoader
loader = PyPDFLoader("employee_handbook.pdf")
documents = loader.load()-
支持PDF、HTML、Word、Markdown等
-
批量处理与增量更新机制
2. 文本处理
# 文本分块处理
from langchain.text_splitter import RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=1000,
chunk_overlap=200
)
splits = text_splitter.split_documents(documents)-
智能分块:保持语义完整性
-
重叠处理:避免边界信息丢失
3. 向量存储
# 向量数据库接入
from langchain.embeddings import OpenAIEmbeddings
from langchain.vectorstores import FAISS
embeddings = OpenAIEmbeddings()
db = FAISS.from_documents(splits, embeddings)-
嵌入模型:OpenAI、Cohere、HuggingFace等
-
向量检索:FAISS、Chroma、Pinecone等
四、记忆(Memory)—— 持续对话的关键
1. 对话记忆
# 对话历史管理
from langchain.memory import ConversationBufferMemory
memory = ConversationBufferMemory()
memory.chat_memory.add_user_message("年假怎么计算?")
memory.chat_memory.add_ai_message("根据手册,员工享有15天年假")-
短期记忆:维护对话上下文
-
长期记忆:用户偏好记录
2. 记忆类型
-
缓冲记忆:保存最近N轮对话
-
摘要记忆:自动生成对话摘要
-
实体记忆:重点信息特别记忆
五、实战:构建企业知识问答系统
1. 完整流程示例
from langchain.chains import RetrievalQA
qa_chain = RetrievalQA.from_chain_type(
llm=OpenAI(),
chain_type="stuff",
retriever=db.as_retriever(),
memory=ConversationBufferMemory()
)
response = qa_chain.run("项目经理的审批权限有哪些?")2. 性能优化技巧
-
混合检索:结合关键词与向量检索
-
分级响应:简单问题直接匹配,复杂问题LLM生成
-
缓存机制:对常见问题缓存回答
六、LangChain 最佳实践
-
提示工程:
-
使用少样本提示(Few-shot Prompting)
-
实现多步骤推理(Chain-of-Thought)
-
-
知识更新:
# 知识库增量更新
def update_knowledgebase(new_docs):
db.add_documents(new_docs)
db.save_local("updated_faiss_index")-
监控评估:
-
记录用户反馈
-
定期测试准确率
-
结语
LangChain 通过模块化设计,将大语言模型转化为真正的生产力工具。掌握其工作流程后,开发者可以:
✅ 快速构建企业级AI应用
✅ 实现知识的有效管理和利用
✅ 创造自然流畅的对话体验
随着LangChain生态的持续发展,我们正站在智能应用开发的新纪元。建议读者从官方文档入手,结合实际业务需求,开启自己的LLM应用开发之旅。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









