






 该文介绍了如何使用Python的BeautifulSoup库解析HTML页面,包括提取head和body标签的内容,获取特定id的标签以及用正则表达式查找中文字符。在处理嵌套标签时,指出了soup.string的限制,并提供了替代的解决方法。
该文介绍了如何使用Python的BeautifulSoup库解析HTML页面,包括提取head和body标签的内容,获取特定id的标签以及用正则表达式查找中文字符。在处理嵌套标签时,指出了soup.string的限制,并提供了替代的解决方法。
前言
一、实验内容
假设有一个简单的HTML 页面如下所示,请保存为字符串,完成后面的计算要求。

二、实验要求
(1)打印head 标签的内容;
(2)获取body 标签的内容;
(3)获取id 为China 的标签对象
(4)获取并打印HTML 页面中的中文字符。
三、程序实现
1.代码
import re
from bs4 import BeautifulSoup
r='<html><head><title>simple test</title></head><body><p id="china">中国,<b>你好!</b>.</p><p id="world">世界,<b>大同!</b>.</p></body></html>'
soup=BeautifulSoup(r,"html.parser")
print(soup.head)
print(soup.body)
print(soup.find(id='china'))
list=[]
for i in r:
char =re.findall("[\u4e00-\u9fa5]+",i)
list+=char
print(list)
'''
如果想head标签和body标签想单纯输出文字就这样
data1=soup.find("head")
data2=soup.find("body")
print(data1.text)
print(data2.text)
如果最后也单纯想输出文字就这样
print(" ".join(list))
'''
2.实验结果(包括输入数据和输出结果)
1.打印标签内容
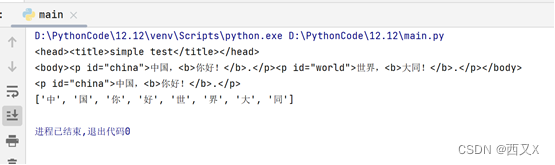
2.单纯输出标签中字符
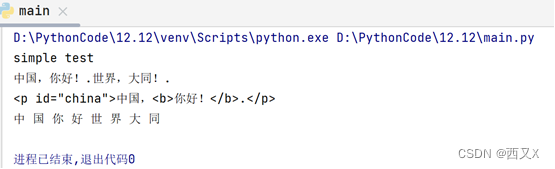
四、总结
- 问题:soup.string无法在标签嵌套的情况下获取相应的内容,只能返回none 因此如果需要获取并打印HTML 页面中的中文字符,只能通过其他方式获取
- 解决方法: 将字符串中所有内容通过for循环进行比对,找到对应需要内容并且输出。


















 3358
3358

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











