






 本文详细介绍了选择排序和冒泡排序的基本原理、实现过程,以及它们在小规模数据排序中的应用。尽管这两种算法简单明了,但因其时间复杂度为O(n^2),在处理大规模数据时效率较低,适合用在特定场景,如教学或数据量不大的情况。作者还提到了更高效的排序算法如快速排序和归并排序作为替代选择。
本文详细介绍了选择排序和冒泡排序的基本原理、实现过程,以及它们在小规模数据排序中的应用。尽管这两种算法简单明了,但因其时间复杂度为O(n^2),在处理大规模数据时效率较低,适合用在特定场景,如教学或数据量不大的情况。作者还提到了更高效的排序算法如快速排序和归并排序作为替代选择。
在计算机科学中,排序算法是一种重要的基本操作,它能够对一组数据进行按照特定顺序重新排列。选择排序和冒泡排序是两种简单但常用的排序算法。本文将介绍这两种排序算法的原理和实现,并通过示例代码演示它们的运行过程。
选择排序:挑选最小值
选择排序是一种简单直观的排序算法,其基本思想是每次从未排序的数据中选择最小(或最大)的元素,放到已排序序列的末尾。具体实现过程如下:
#include <stdio.h>
int main() {
int array[] = {99, 534, 32, 66, 433, 32, 66, 11, 889};
int i, j, tmp;
int len = sizeof(array) / sizeof(array[0]);
for (i = 0; i < len - 1; i++) {
for (j = i + 1; j < len; j++) {
if (array[i] > array[j]) {
tmp = array[i];
array[i] = array[j];
array[j] = tmp;
}
}
}
for (i = 0; i < len; i++) {
printf("%d ", array[i]);
}
return 0;
}

冒泡排序:逐步交换
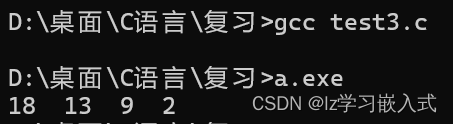
冒泡排序是一种简单直观的排序算法,其基本思想是依次比较相邻的两个元素,如果它们的顺序不对就交换位置,直到整个序列有序。具体实现过程如下:
#include <stdio.h>
int main() {
int array[] = {13, 2, 18, 9};
int i, j, tmp;
int len = sizeof(array) / sizeof(array[0]);
for (i = 0; i < len - 1; i++) {
for (j = 0; j < len - i - 1; j++) {
if (array[j] > array[j + 1]) {
tmp = array[j];
array[j] = array[j + 1];
array[j + 1] = tmp;
}
}
}
for (i = 0; i < len; i++) {
printf("%d ", array[i]);
}
return 0;
}
总结
选择排序和冒泡排序虽然简单,但在某些场景下仍然具有一定的实用价值。它们的实现原理清晰易懂,适用于小规模数据的排序。但需要注意的是,选择排序和冒泡排序的时间复杂度都为O(n^2),因此在处理大规模数据时可能效率较低。在实际应用中,我们可以根据具体情况选择更高效的排序算法,如快速排序、归并排序等,以满足不同的需求。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









