






1.引言
1.1主题
本博客旨在通过一个具体的案例——使用scrapy框架采集电影网站内容,并存储mongoDB数据库中,来展示网络爬虫技术的实际应用。我们将探索如何使用爬虫技术来自动收集、处理和分析网络上的公开数据,以及如何将这些数据转化为有价值的信息。
2.数据来源
url:https://www.cupfox2025.com/vodshow/id/fenlei1/page/1.html
3.介绍scrapy框架
Scrapy是一个快速的、高层次的web抓取和网页爬虫框架,用于抓取web站点并从页面中提取结构化的数据。它提供了一套非常灵活的机制来抓取网站,并且可以用于各种用途,如数据挖掘、信息处理或历史存档。
以下是Scrapy框架的一些主要特点:
- 异步处理:Scrapy是基于Twisted异步网络框架构建的,这意味着它可以在不阻塞的情况下进行快速的网页请求。
- 高性能:Scrapy设计用于处理大量的并发请求,因此它非常适合大规模的抓取任务。
- 可扩展性:Scrapy允许用户通过编写扩展来增加额外的功能,这些扩展可以在抓取过程中的特定阶段被调用。
- 中间件支持:Scrapy提供了请求/响应中间件,用户可以自定义中间件来处理请求和响应。
- 选择器:Scrapy提供了XPath和CSS选择器,使得从HTML/XML响应中提取数据变得简单。
- 内置支持:Scrapy内置了对多种数据格式的支持,如JSON、CSV和XML。
- 命令行工具:Scrapy提供了一个命令行工具,可以通过命令行来运行爬虫、查看日志和执行其他任务。
- 项目结构:Scrapy项目通常包含一个项目文件、一个或多个爬虫文件、一个设置文件、一个中间件文件和一个管道文件。
- 管道(Pipelines):Scrapy允许定义管道来处理抓取到的数据,例如清洗、验证和存储。
- 去重:Scrapy内置了去重机制,可以避免重复抓取相同的页面。
- 支持代理:Scrapy支持使用代理服务器进行抓取,这对于绕过IP限制非常有用。
- 用户代理和Cookies:Scrapy可以模拟浏览器行为,包括设置用户代理和处理Cookies。
4.具体操作
4.1 命令行下载必要的库
pip install Scrapy # 注:windows平台需要依赖pywin32
pip install pypiwin32
pip install pymongo
4.2 创建项目
scrapy startproject myspider02
cd myspider02
scrapy genspider cupfox cupfox2025.com
4.3 全局设置-settings.py
# Scrapy 配置文件 for myspider02 项目
#
# 为了简化,此文件仅包含被认为是重要或
# 常见的配置。您可以通过咨询文档找到更多配置:
# 定义机器人名称
BOT_NAME = "myspider02"
# 指定蜘蛛模块所在的位置
SPIDER_MODULES = ["myspider02.spiders"]
# 新蜘蛛应保存在此模块中
NEWSPIDER_MODULE = "myspider02.spiders"
# 遵守 robots.txt 规则
ROBOTSTXT_OBEY = False
# 启用或禁用下载中间件
# 详见 https://docs.scrapy.org/en/latest/topics/downloader-middleware.html
DOWNLOADER_MIDDLEWARES = {
"myspider02.middlewares.Myspider02DownloaderMiddleware": 543,
"myspider02.middlewares.userAgentMiddleware": 542,
}
# 配置项目管道
# 详见 https://docs.scrapy.org/en/latest/topics/item-pipeline.html
ITEM_PIPELINES = {
"myspider02.pipelines.Myspider02Pipeline": 300,
}
# 将默认值已过时的设置设置为未来安全的值
REQUEST_FINGERPRINTER_IMPLEMENTATION = "2.7"
TWISTED_REACTOR = "twisted.internet.asyncioreactor.AsyncioSelectorReactor"
FEED_EXPORT_ENCODING = "utf-8"
4.4 User Agent中间件配置-middlewares.py
class userAgentMiddleware(object):
"""
该类用于在请求处理过程中,为每个请求随机选择一个User-Agent头部。
"""
def process_request(self, request, spider):
"""
处理请求的中间件方法。
参数:
- request: 当前的请求对象,用于修改其User-Agent头部。
- spider: 当前的爬虫实例,用于获取上下文信息。
该方法没有返回值。
"""
# 为请求设置随机的User-Agent头部,以增加请求的伪装性
request.headers['User-Agent'] = UserAgent().random
4.5 采集数据
import scrapy
class CupfoxSpider(scrapy.Spider):
# 爬虫名称
name = "cupfox"
# 允许的域名
allowed_domains = ["cupfox2025.com"]
# 起始URL
start_urls = ["https://www.cupfox2025.com/vodshow/id/fenlei1/page/1.html"]
def __init__(self):
# 初始化页面计数器
self.page_count = 0
def parse(self, response):
# 解析响应,提取详情页URL
detail_urls = response.xpath("//div[@class='module']/a/@href").extract()
# 构建完整的URL列表
complete_urls = [response.urljoin(url) for url in detail_urls]
for url in complete_urls:
# 对每个详情页发送请求
yield scrapy.Request(url, callback=self.parse_detail)
# 分页处理
self.page_count += 1 # 增加页面计数
# 获取下一页URL
next_page = response.xpath('//*[@id="page"]/a[7]/@href').get()
print(next_page)
# 如果有下一页且页数未超过限制,则继续请求下一页
if next_page and self.page_count < 5:
yield scrapy.Request(response.urljoin(next_page), callback=self.parse)
def parse_detail(self, response):
# 解析电影详情页
movie_title = response.xpath("//h1/text()").extract_first()
img_url = response.xpath("//div[1]/div[1]/div/div/img/@data-original").get()
# 构建完整的图片URL
complete_img_url = response.urljoin(img_url)
director = response.xpath("//div[@class='module-info-items']/div[4]/div/a/text()").get()
actors = response.xpath("//div[@class='module-info-items']/div[5]/div/a/text()").getall()
update_time = response.xpath("//p[@class='module-info-item-content']/text()").get()
# 清理更新时间字符串
update_time_cleaned = update_time.replace('\t','').replace('\n','')
brief_info = response.xpath("//div[@class='module-info-introduction-content show-desc']/p/text()").get()
# 构建并返回电影信息字典
yield {
'电影名称':movie_title,
'电影剧照':complete_img_url,
'导演':director,
'主演':actors,
'更新时间':update_time_cleaned,
'简介信息':brief_info
}
4.6 保存数据-pipelines.py
# 导入 pymongo 库,用于连接 MongoDB 数据库
import pymongo
# 导入 ItemAdapter,用于处理不同类型的 item,提供统一的接口
from itemadapter import ItemAdapter
class Myspider02Pipeline:
"""
定义了一个名为 Myspider02 的爬虫管道类,用于处理爬取的 item 数据并将其存储到 MongoDB 数据库中。
该类通过以下几个方法实现其功能:
- open_spider: 在爬虫开始时打开数据库连接。
- process_item: 处理每一个 item,并将其添加到数据库中。
- close_spider: 在爬虫结束时关闭数据库连接。
"""
def open_spider(self, spider):
"""
爬虫开始时调用,用于打开数据库连接。
参数:
- spider: 当前被运行的爬虫的实例。
"""
# 连接到本地的 MongoDB 数据库
self.client = pymongo.MongoClient(host='localhost', port=27017)
# 选择或创建名为 'dianyinku' 的数据库,并命名为 'movieee'
self.db = self.client.movieee.dianyinku
def process_item(self, item, spider):
"""
处理每一个 item 数据,将其插入到 MongoDB 数据库中。
参数:
- item: 爬取的数据项。
- spider: 当前被运行的爬虫的实例。
返回:
- item: 处理后的 item 数据项。
"""
# 将 item 数据插入到数据库中
self.db.insert_one(dict(item))
# 打印成功添加数据的消息
print('添加数据成功')
return item
def close_spider(self, spider):
"""
爬虫结束时调用,用于关闭数据库连接。
参数:
- spider: 当前被运行的爬虫的实例。
"""
# 关闭与数据库的连接
self.client.close()
4.7 验证结果
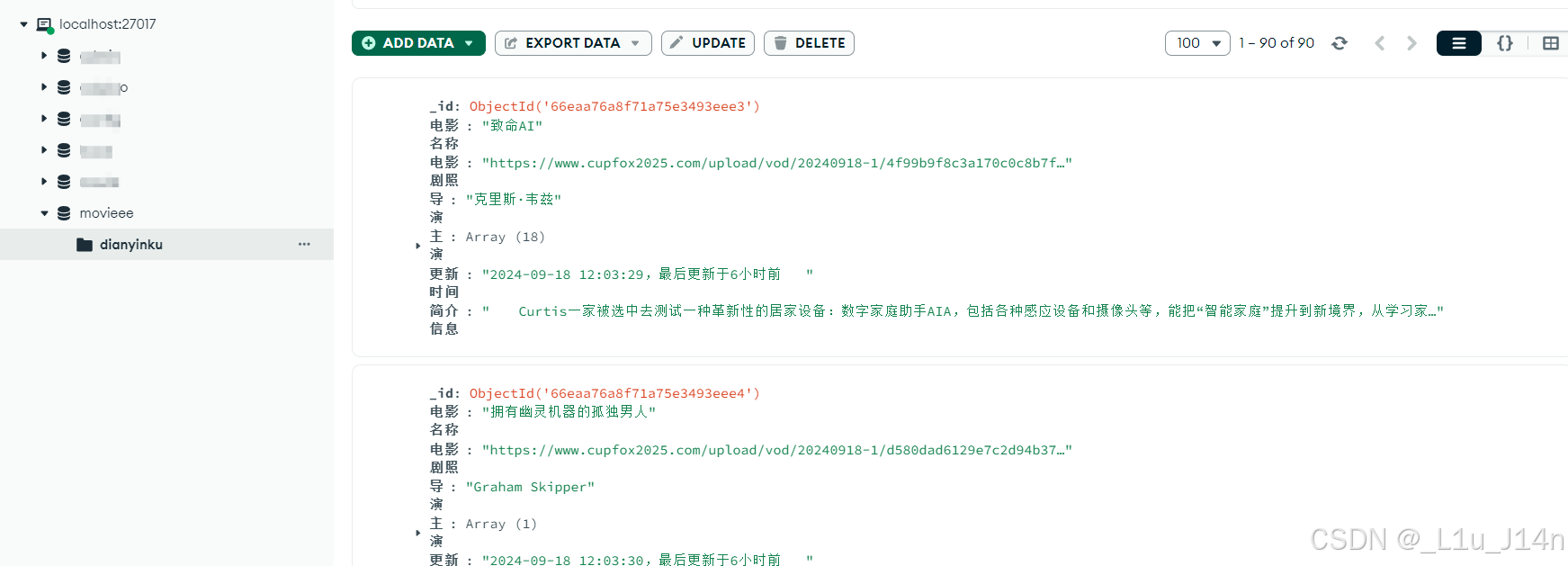
通过mongoDB的可视化工具—‘MongoDB compass’来连接本地MongoDB数据库进行结果的查看,入下图。
5 总结
在本博客中,我们通过一个实际案例——使用Scrapy框架采集电影网站内容并存储至MongoDB数据库,深入探讨了网络爬虫技术的应用。我们详细阐述了从数据采集到存储的整个流程,包括Scrapy框架的介绍、具体操作步骤、代码实现以及结果验证。
5.1 技术要点回顾
- Scrapy框架:我们介绍了Scrapy框架的核心特点,包括其异步处理能力、高性能、可扩展性、中间件支持等,这些都是Scrapy在网络爬虫领域广受欢迎的原因。
- 项目构建:通过命令行工具,我们创建了Scrapy项目和爬虫,展示了如何通过简单的命令快速搭建起一个爬虫项目。
- 中间件与管道:我们实现了自定义的User-Agent中间件,以模拟浏览器行为,避免被网站封锁。同时,通过管道(Pipelines),我们将抓取到的数据进行了清洗和存储。
- 数据采集与解析:在爬虫代码中,我们使用了XPath选择器来定位并提取网页中的电影信息,包括电影名称、剧照、导演、主演、更新时间和简介等。
- 数据存储:通过MongoDB,我们将采集到的数据存储到了非关系型数据库中,利用其灵活的数据模型来管理结构化数据。
5.2 结语
通过本博客的学习和实践,希望你能对Scrapy框架和网络爬虫技术有一个全面而深入的理解。网络爬虫技术是一个强大的工具,合理利用可以为我们的工作和生活带来极大的便利。不断学习和探索,将使你在这个领域更加游刃有余。

















 1899
1899

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









