







 这段代码用于从豆瓣电影页面抓取指定类型的图片,并将其保存到本地的"picters"文件夹中。它首先获取电影照片页面,然后解析HTML,提取图片URL,逐张下载并保存。程序还能够自动遍历所有分页,抓取所有图片。
这段代码用于从豆瓣电影页面抓取指定类型的图片,并将其保存到本地的"picters"文件夹中。它首先获取电影照片页面,然后解析HTML,提取图片URL,逐张下载并保存。程序还能够自动遍历所有分页,抓取所有图片。
在douban上指定图片的网址.

import requests
from lxml import etree
url="https://movie.douban.com/subject/34867871/photos?type=W"
headers={"User-Agent":"mozilla/4.0 (compatible; MSIE 5.5; Windows NT)"}
page=requests.get(url=url,headers=headers).text
tree=etree.HTML(page)
num=tree.xpath('//div[@class="article"]//li')
a=1
for i in num:
name="picters/"+f"{a}"+".jpg"
path=i.xpath('.//img/@src')[0]
data=requests.get(url=path,headers=headers).content
f=open(name,"wb")
f.write(data)
f.close()
a+=1
print(name,"yes!!!")
url=tree.xpath('//span[@class="next"]/a/@href')
while url:
url=url[0]
page = requests.get(url=url, headers=headers).text
tree = etree.HTML(page)
num = tree.xpath('//div[@class="article"]//li')
for i in num:
name = "picters/" + f"{a}" + ".jpg"
path = i.xpath('.//img/@src')[0]
data = requests.get(url=path, headers=headers).content
f = open(name, "wb")
f.write(data)
f.close()
a += 1
print(name, "yes!!!")
url = tree.xpath('//span[@class="next"]/a/@href')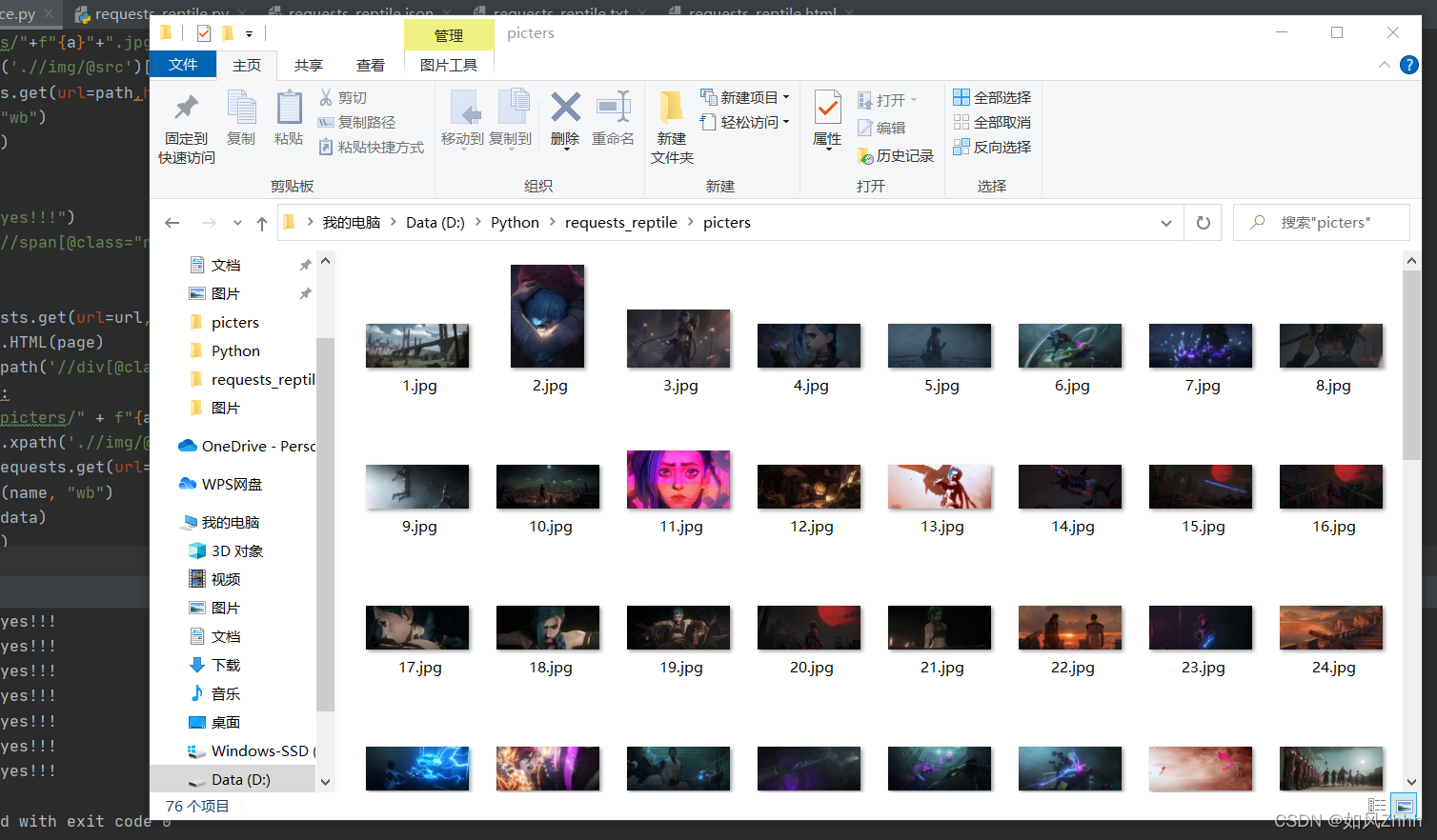


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









