







 本文详细介绍了C++中的set(无重复)、multiset(允许重复)和map(键值对)容器的插入、删除操作,以及它们在数据结构中的应用,如二叉搜索树特性、去重和排序。重点讲解了set的find与erase方法,以及map的pair结构、插入方式和迭代器操作。
本文详细介绍了C++中的set(无重复)、multiset(允许重复)和map(键值对)容器的插入、删除操作,以及它们在数据结构中的应用,如二叉搜索树特性、去重和排序。重点讲解了set的find与erase方法,以及map的pair结构、插入方式和迭代器操作。
容器
序列式容器:vector/list…
关联式容器:map/set…
set
set一般是key的模型,像车进小区,看你车牌号在不在系统里

插入删除主要是insert和erase
set像是二叉搜索树,走中序就是有序的
insert:
//排序+去重
set<int> s;
s.insert(1);
s.insert(4);
s.insert(6);
s.insert(9);
s.insert(3);
s.insert(8);
s.insert(9);
//插入一个值的时候,如果这个值已经有了就返回false
s.insert(4);
//it获取第一个位置的迭代器
set<int>::iterator it = s.begin();
while (it != s.end())
{
cout << *it << " ";
it++;
}
cout << endl;
for (auto e : s)
{
cout << e << " ";
}
cout << endl;
**erase:**重载了三个版本

//erase删值和删位置的区别
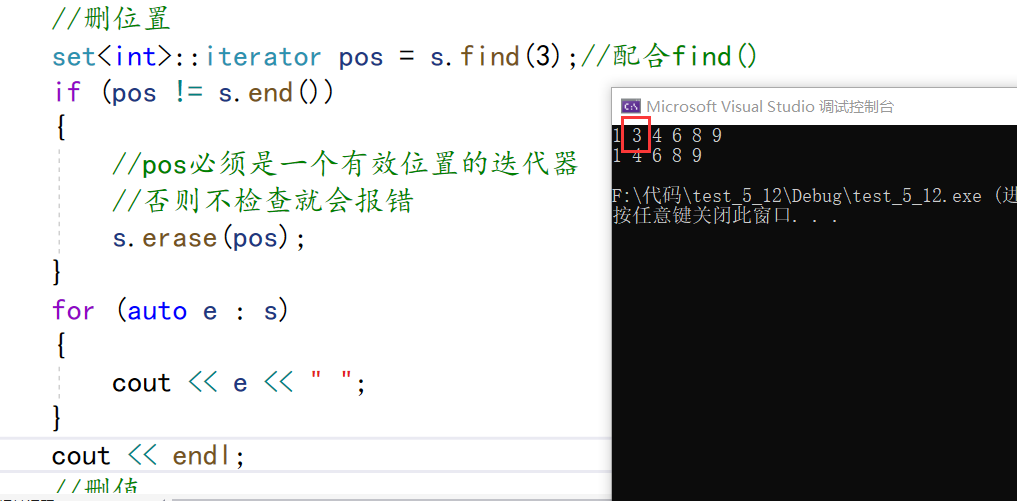
//删位置
set<int>::iterator pos = s.find(3);//配合find(),find找到就返回那个位置的迭代器,找不出就返回end()
if (pos != s.end())
{
//pos必须是一个有效位置的迭代器
//否则不检查就会报错
s.erase(pos);
}
for (auto e : s)
{
cout << e << " ";
}
cout << endl;
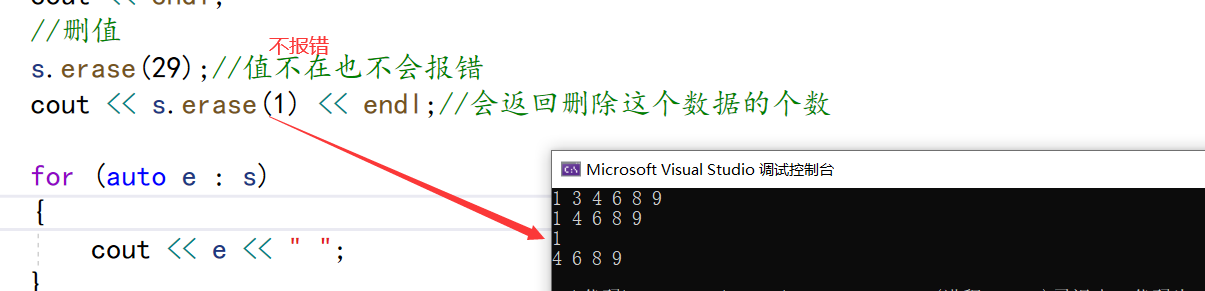
//删值
s.erase(29);//值不在也不会报错
cout << s.erase(1) << endl;//会返回删除这个数据的个数
multiset
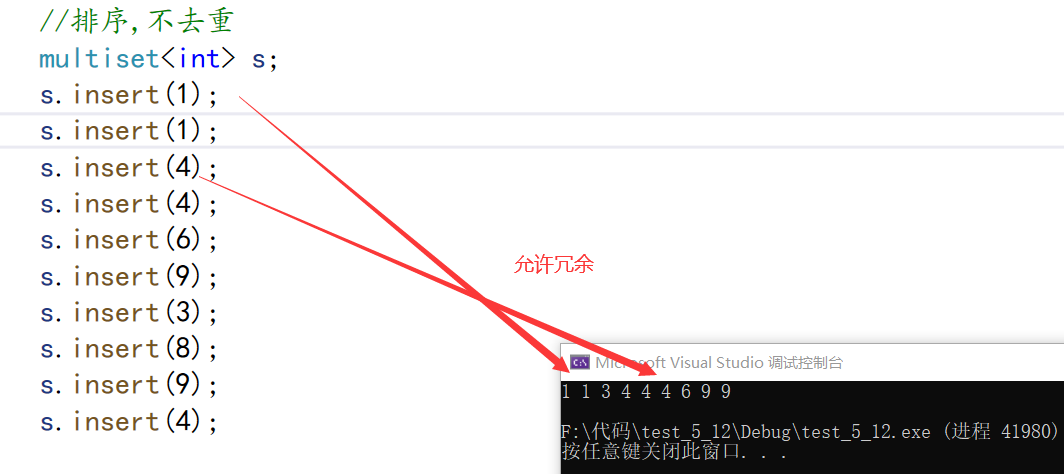
multiset和set功能几乎是一样的,但是真正的区别是multiset允许key值冗余,排序+不去重
set和multset不可以通过迭代器修改
//排序,不去重
multiset<int> s;
s.insert(1);
s.insert(1);
s.insert(4);
s.insert(4);
s.insert(6);
s.insert(9);
s.insert(3);
s.insert(8);
s.insert(9);
s.insert(4);
//find的val有多个值,返回中序第一个(最左 )val值所在节点的迭代器
multiset<int>::iterator pos = s.find(4);
//删位置,想要删除4要多次删除
/*while (pos != s.end())
{
s.erase(pos);
pos = s.find(4);
}*/
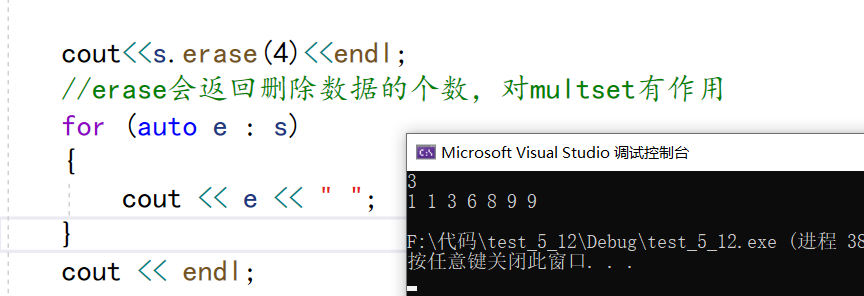
cout<<s.erase(4)<<endl;
//erase会返回删除数据的个数,对multset有作用
for (auto e : s)
{
cout << e << " ";
}
cout << endl;
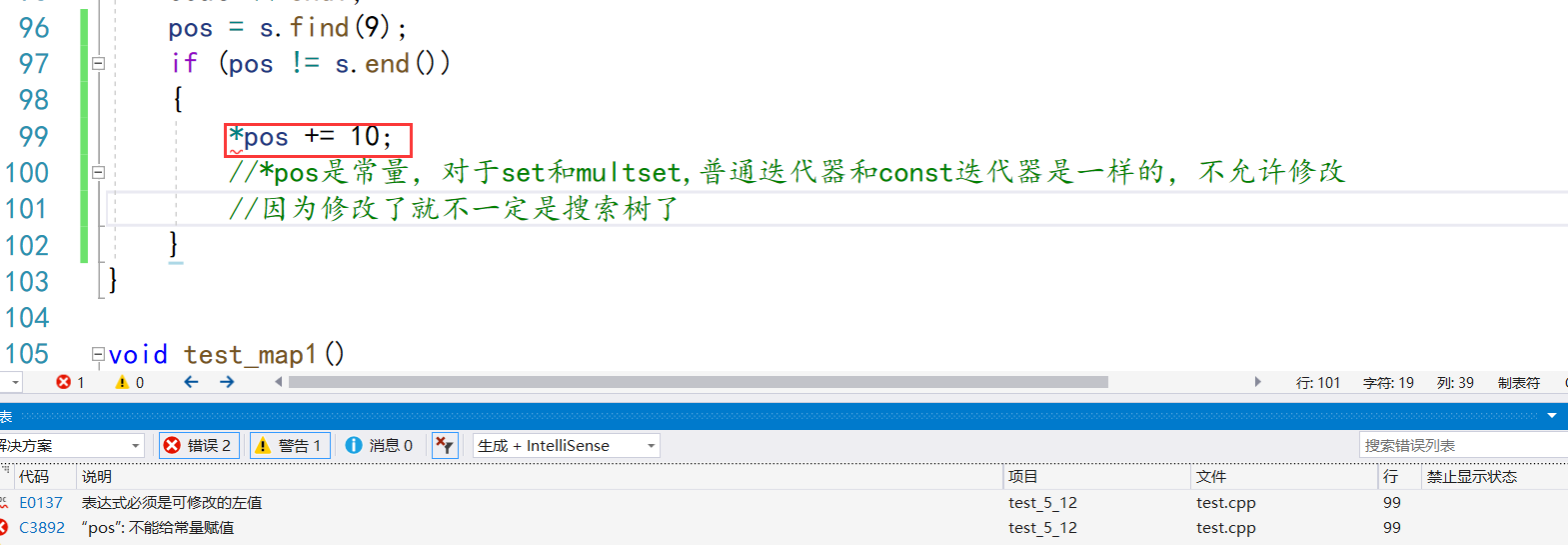
//pos = s.find(9);
//if (pos != s.end())
//{
// *pos += 10;
// //*pos是常量,对于set和multset,普通迭代器和const迭代器是一样的,不允许修改
// //因为修改了就不一定是搜索树了
//}
map
map还是搜索树,每个节点的不仅存了key还有value
它把key和value封装到一个类结构pair里


value_type是 pair<const key_type,mapped_type>;
map<string, string> dict;
pair<string, string> kv1("sort", "排序");//pair的构造函数
//insert的是value_type,插入map的三种方式
//方式一
dict.insert(kv1);
//方式二
dict.insert(pair<string, string>("string", "字符串"));//(匿名对象)
//方式三 make_pair自动推导类型
dict.insert(make_pair("test", "测试"));//最常用

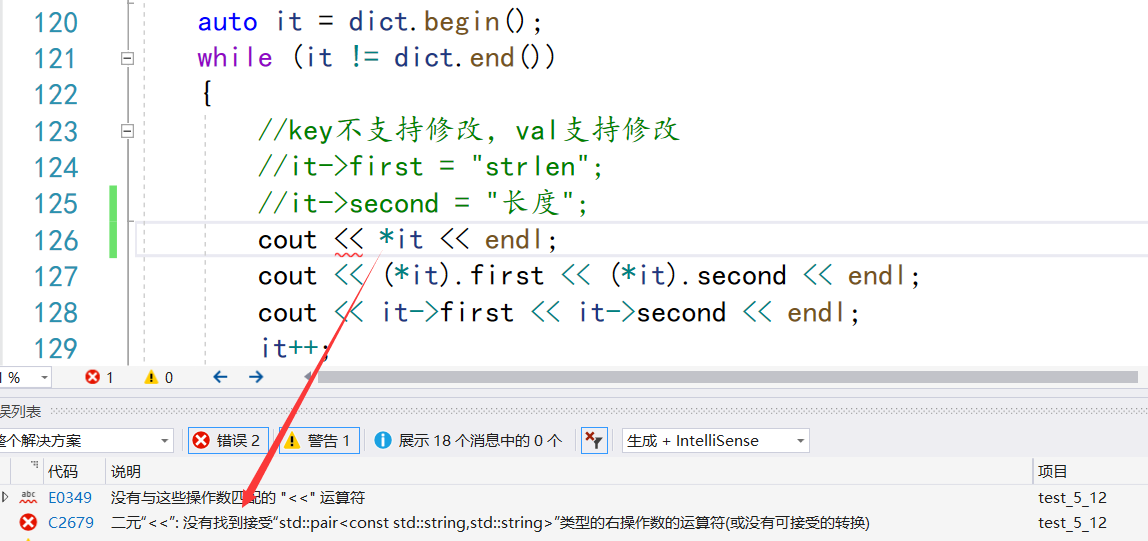
pair不支持流插入和流提取,没有重载这两个运算符
*it返回一个pair,pair里有两个值,pair是struct的,可以认为这个pair类里的东西都是公有的
//map的遍历
//map<string, string>::iterator it = dict.begin();
auto it = dict.begin();
while (it != dict.end())
{
//key不支持修改,val支持修改
//it->first = "strlen";//不支持,因为会改变搜索树的结构(按key比较大小)
//it->second = "长度";//支持,不会改变搜索树的结构
//cout << *it << endl;//不支持
//cout << (*it).first << (*it).second << endl;//.的优先级高于*,所以要加()
cout << it->first << it->second << endl;//最常用
it++;
}
cout << endl;
//kv相当于pair
for (auto& kv : dict)//每个对象是pair,相当于把*it给kv
{
cout << kv.first << ":" << kv.second << endl;
}

map统计次数
方式1:先查找如果第一次出现插入map,不是第一次出现就让value++
for (auto& str : arr)
{
auto ret = countMap.find(str);
//如果是第一次出现就插入搜索树map
if (ret == countMap.end())//找不到就是第一次出现
{
countMap.insert(make_pair(str, 1));
}
//如果不是第二次出现,val就++
else
{
ret->second++;
}
}
方式2:迭代器
for (auto& str : arr)
{
auto kv = countMap.insert(make_pair(str, 1));
表示水果已经出现过了,插入无论成功,失败都会返回key位置的迭代器
if (kv.second == false)
{
kv.first->second++;//first就是迭代器
}
}
方式3:[],[]的功能:1.插入 ;2.查找 ;3.修改(value的引用)
1.水果第一次出现,插入+修改
2.水果不是第一次出现,查找+修改



for (auto& str : arr)
{
countMap[str]++;
}
map的[]的作用
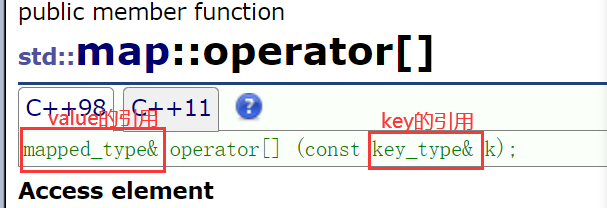

红色代码是简化过的
mapped_type()是value类型的缺省值(string就是匿名对象,int就是0)
插入它不管成功还是失败,都会返回节点的迭代器ret.first,要返回ret.first->second(value)的引用
如果第一次出现就先插入,这时的value是0,返回的时候++,value就变成一次
[]的功能
1.插入
2.查找value
3.修改value
void test_map3()
{
map<string, string> dict;
dict.insert(make_pair("sort", "排序"));
dict.insert(make_pair("left", "左边"));
dict.insert(make_pair("left", "剩余"));//left有就不会插入
dict["left"] = "剩余";//查找的作用,查找返回val的引用,val是引用达到修改
dict["test"];//充当插入
cout << dict["sort"] << endl;//查找
dict["string"] = "字符串";//插入+修改因为string不在搜索树里
}
count:看map里有几个key
multimap
注意:multimap不支持[],允许冗余,其他操作几乎一致
使用map的topk例题
想统计前k个最喜欢的水果
- 利用map,key是水果名,value是个数

2.两种方法,1.sort; 2.multimap;如果再用map,让key是个数,这样会有问题:要是其他水果个数相同,就插入不了了,所以用multimap
sort的第一个方法:利用vector
struct CountVal//仿函数的作用是为了让sort以value排序
{
bool operator()(const pair<string, int>& l, const pair<string, int>& r)
{
return l.second > r.second;
}
};
void GetFavorite(const vector<string>& fruits, size_t k)
{
map<string, int> countMap;
for (auto& str : fruits)
{
countMap[str]++;
}
//不想比key,想比value
//数据量不大
// sort利用的是快排(三数取中),所以sort要求随机迭代器
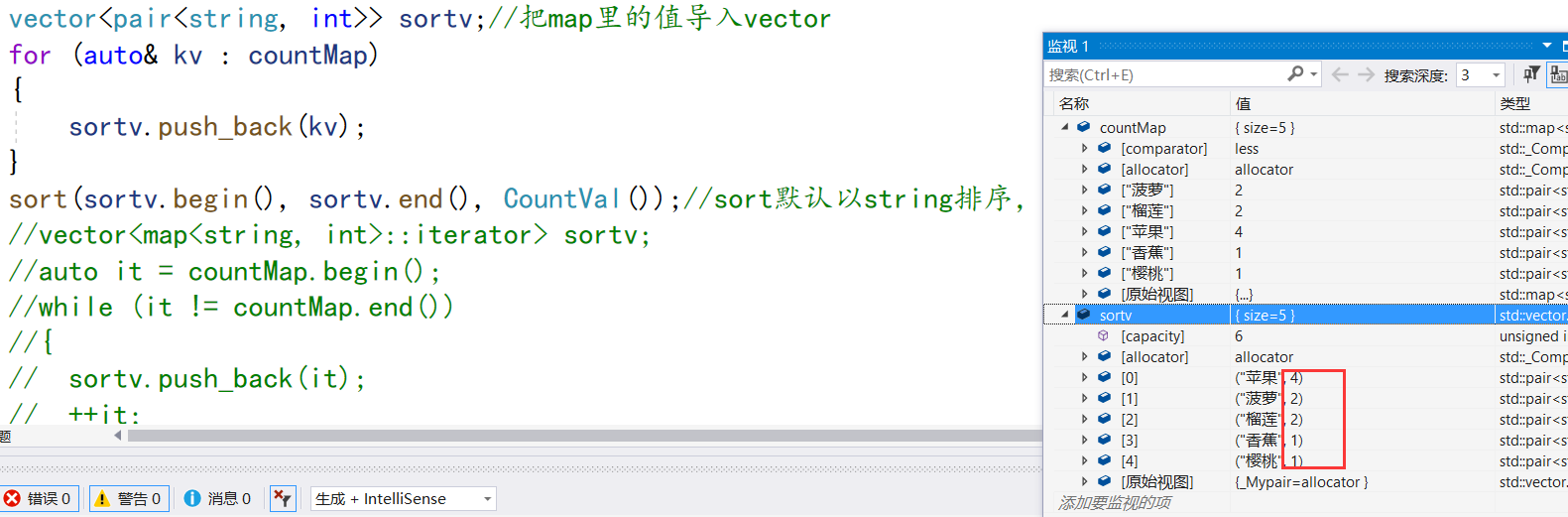
vector<pair<string, int>> sortv;//把map里的值导入vector
for (auto& kv : countMap)
{
sortv.push_back(kv);
}
sort(sortv.begin(), sortv.end(), CountVal());//sort默认以string排序,所以我们要写仿函数
//统计前k个
for (int i = 0; i < k; i++)
{
cout << sortv[i].first << endl;
}
}
sort的第二个方法拷贝迭代器,节省空间
struct CountIterator//sort仿函数,通过map的迭代器进行比较
{
bool operator()(const map<string, int>::iterator& l, map<string, int>::iterator& r)
{
return l->second > r->second;
}
};
//这里只拷贝了迭代器,内存要要比pair的拷贝小很多
vector<map<string, int>::iterator> sortv;//存map的迭代器
auto it = countMap.begin();
while (it != countMap.end())
{
sortv.push_back(it);
++it;
}
//sort通过仿函数比较迭代器指向的value
sort(sortv.begin(), sortv.end(),CountIterator());
for (int i = 0; i < k; i++)
{
//迭代器用->
cout << sortv[i]->first << ":" << sortv[i]->second << endl;
}
cout << endl;
}
利用multimap实现:
void GetFavorite1(const vector<string>& fruits, size_t k)
{
map<string, int> countMap;
for (auto& str : fruits)
{
countMap[str]++;
}
multimap<int, string,greater<int>> sortMap;//greator控制降序
for (auto& kv : countMap)
{
//把map的second当成multimap的first
sortMap.insert(make_pair(kv.second, kv.first));
}
}
前k个高频单词链接
class Solution {
public:
vector<string> topKFrequent(vector<string>& words, int k) {
map<string,int> CountMap;//map控制字典序,并且统计个数
for(auto& str : words)
{
CountMap[str]++;
}
multimap<int,string,greater<int>> sortv;//greater<int>控制降序
for(auto& kv:CountMap)//multimap控制次数的排序
{
sortv.insert(make_pair(kv.second,kv.first));
}
auto it=sortv.begin();//利用迭代器遍历
vector<string> v;//接收前k个单词
while(k)
{
v.push_back(it->second);//it->second是单词,it->first是次数
it++;
k--;
}
return v;
}
};

















 1568
1568

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









