







问题描述
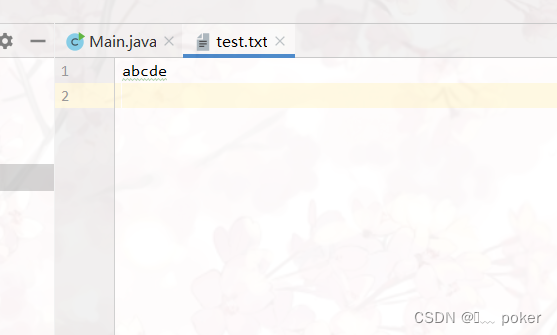
如图,新建一个txt文本文档,里面存储了abcde五个字母
使用如下代码依次读取
public static void main(String[] args) throws IOException {
FileInputStream fs = new FileInputStream("C:\\Program Files\\idea\\ideaProject\\test\\test.txt");
byte[] bytes = new byte[2];
int len = -1;
while ((len = fs.read(bytes)) != -1){
System.out.print(len + " -> ");
String text = new String(bytes, 0, len);
System.out.println(text);
}
}在大多数常见的字符编码中,如ASCII、UTF-8等,基本的字母、数字和一些特殊字符通常都是一个字节,而我们每次读取两个字节预期结果应该是刚好能读取三次,ab、cd、e
然而读取结果如下:
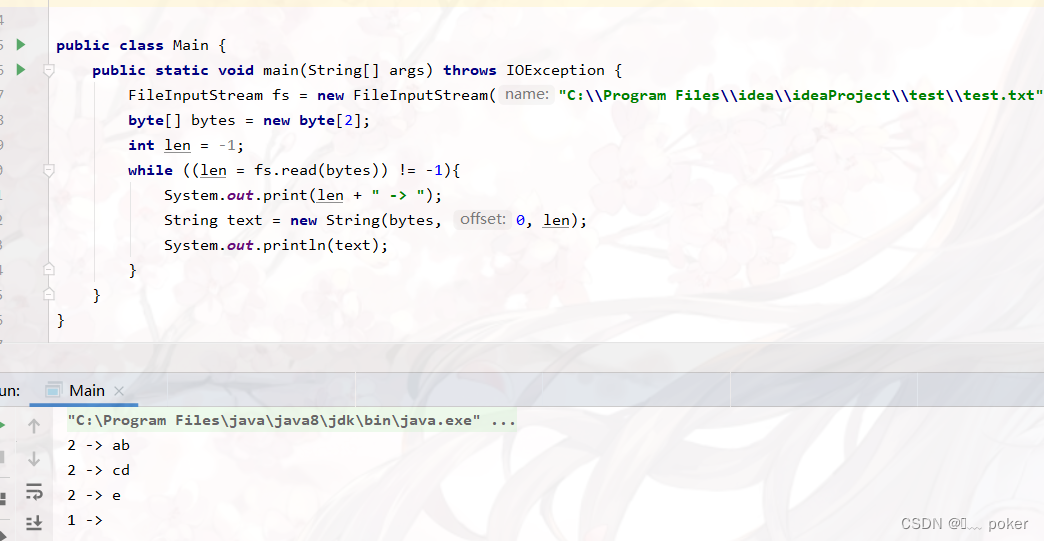
第三次读取的字节长度为2,并且读取了四次?为什么会产生这样的结果呢?
结果解释
使用文本编辑器,记事本、notepad++、vscode、idea等等编辑文本文档之后,通常在文件的最后会有一个空字符('\0')或换行符('\n'),这是因为大多数文本编辑器会自动在文件的末尾添加一个换行字符。这个字符不是文件内容的一部分,只是用于表示文件的结束。
不同的操作系统在文本文件的结束符上可能有所不同。在Unix/Linux系统中,通常只使用换行符('\n')表示行的结束,而在Windows系统中,通常使用回车符('\r')和换行符('\n')的组合("\r\n")来表示行的结束。
而'\r\n'占两个字节,并且为不可见字符,因此此时文件内容共有7个字节所以能读取4次,并且第4次读取的字节长度为1
验证
也很好验证,将末尾字符的编码打印出来
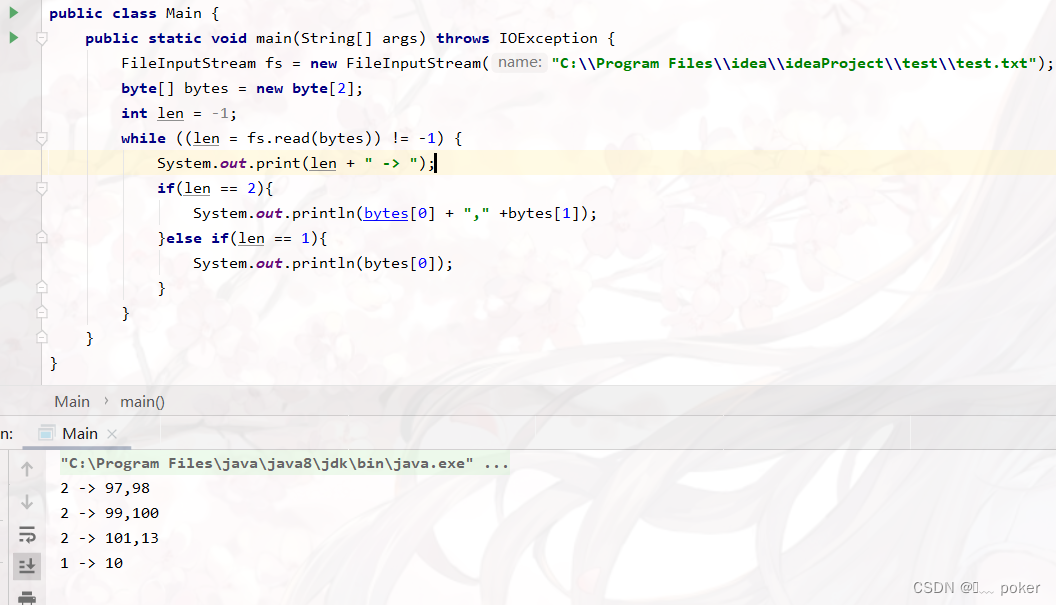
查阅编码得知,13和10分别对应'\r'和'\n'


















 5万+
5万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









