






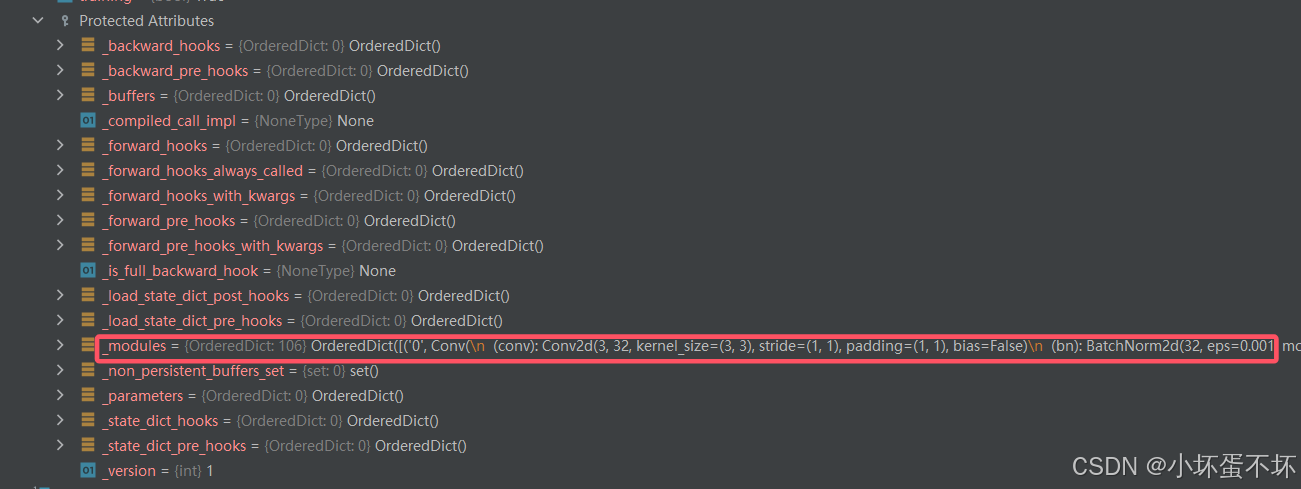
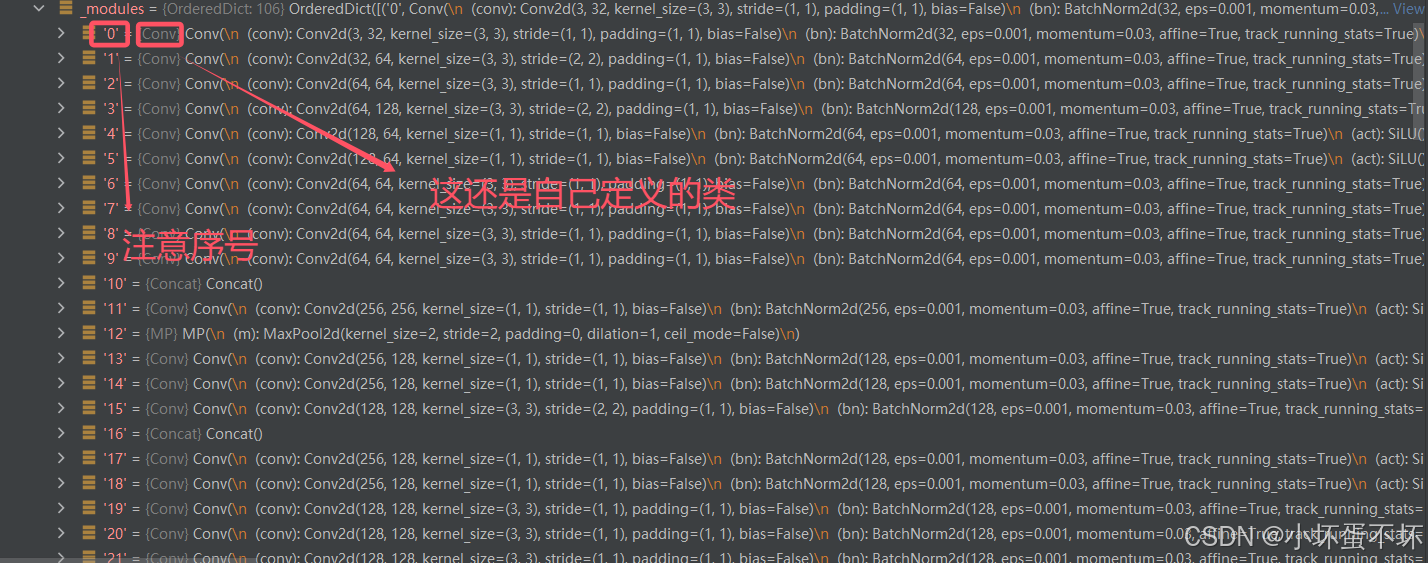
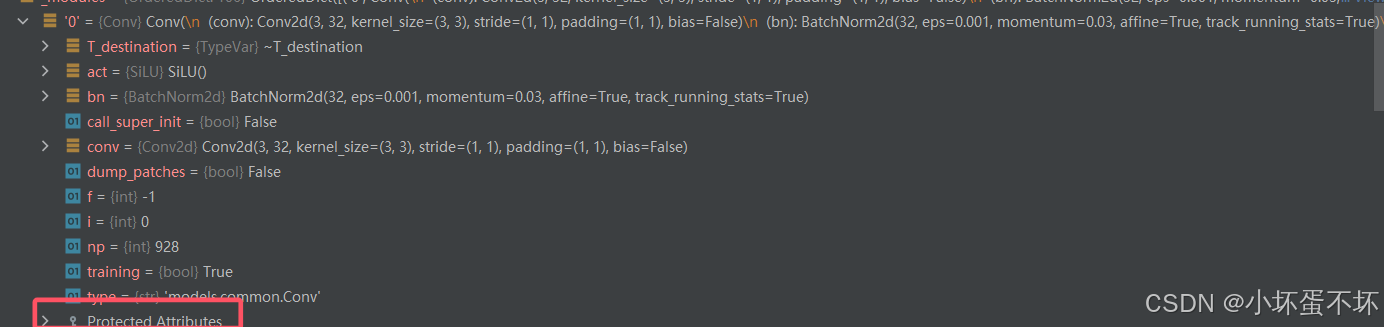
自定义Model类
model = Model(r"D:\Desktop\yolo\yolov7-main\cfg\training\yolov7.yaml",ch=3,nc=80).to(device="cuda")


*************************************************************************************
model = Model(r"D:\Desktop\yolo\yolov7-main\cfg\training\yolov7.yaml",ch=3,nc=80).to(device="cuda")也有相应的权重,但是参数未经训练
完整的加载过程
from models.yolo import Model
注意这里的自定义类必须提供实现,否则load序列化的时候
ckpt= torch.load(r"D:\Desktop\yolo\yolov7-main\yolov7.pt",map_location="cuda")
model = Model(r"D:\Desktop\yolo\yolov7-main\cfg\training\yolov7.yaml",ch=3,nc=80).to(device="cuda")
state_dict = ckpt['model'].float().state_dict()
model.load_state_dict(state_dict, strict=False)其中ckpt,是一个字典包含了

从ckpt提取

















 4809
4809

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









