







Generating Adversarial Examples with Adversarial Networks
本文 “Generating Adversarial Examples with Adversarial Networks” 提出 AdvGAN,利用生成对抗网络生成对抗样本,在半白盒和黑盒攻击场景下均有出色表现,生成的对抗样本攻击成功率高、感知质量好,为改进对抗训练防御方法提供了新方向。
摘要-Abstract
Deep neural networks (DNNs) have been found to be vulnerable to adversarial examples resulting from adding small-magnitude perturbations to inputs. Such adversarial examples can mislead DNNs to produce adversary-selected results. Different attack strategies have been proposed to generate adversarial examples, but how to produce them with high perceptual quality and more efficiently requires more research efforts. In this paper, we propose AdvGAN to generate adversarial examples with generative adversarial networks (GANs), which can learn and approximate the distribution of original instances. For AdvGAN, once the generator is trained, it can generate perturbations efficiently for any instance, so as to potentially accelerate adversarial training as defenses. We apply AdvGAN in both semi-whitebox and black-box attack settings. In semi-whitebox attacks, there is no need to access the original target model after the generator is trained, in contrast to traditional white-box attacks. In black-box attacks, we dynamically train a distilled model for the black-box model and optimize the generator accordingly. Adversarial examples generated by AdvGAN on different target models have high attack success rate under stateof-the-art defenses compared to other attacks. Our attack has placed the first with 92.76% accuracy on a public MNIST black-box attack challenge.
研究发现,深度神经网络(DNNs)容易受到对抗样本的影响,这些对抗样本是通过在输入中添加微小扰动产生的。这类对抗样本会误导深度神经网络产生攻击者选定的结果。虽然已经提出了不同的攻击策略来生成对抗样本,但如何更高效地生成感知质量高的对抗样本,仍有待进一步研究。在本文中,我们提出了AdvGAN,利用生成对抗网络(GANs)生成对抗样本,该网络能够学习并近似原始实例的分布。对于AdvGAN而言,一旦生成器完成训练,它就能为任何实例高效地生成扰动,这有可能加快作为防御手段的对抗训练。我们将AdvGAN应用于半白盒和黑盒攻击场景。在半白盒攻击中,与传统的白盒攻击不同,生成器训练完成后无需再访问原始目标模型。在黑盒攻击中,我们为黑盒模型动态训练一个蒸馏模型,并相应地优化生成器。与其他攻击方式相比,AdvGAN在不同目标模型上生成的对抗样本,在当前最先进的防御措施下,具有更高的攻击成功率。我们的攻击方法在MNIST黑盒攻击任务中以92.76%的准确率位居榜首 。
引言-Introduction
该部分主要介绍研究背景、目的、方法及贡献,指出深度神经网络易受对抗样本影响,现有攻击算法存在不足,提出AdvGAN用生成对抗网络生成对抗样本,在半白盒和黑盒攻击场景下进行实验,结果表明其生成的对抗样本攻击成功率高。
- 研究背景:深度神经网络(DNNs)在众多应用领域取得显著成果,但易受对抗扰动影响。攻击者在输入中添加微小扰动生成对抗样本,可误导DNNs分类,导致学习系统将其错误分类为恶意选择的目标类(目标性攻击)或与真实类别不同的类(非目标性攻击)。目前已提出多种生成对抗样本的算法,如快速梯度符号法(FGSM)和基于优化的方法(Opt.),但大多依赖简单像素空间度量的优化方案,在高效生成感知上更真实的对抗样本方面有待提升。
- 研究目的与方法:提出AdvGAN,利用生成对抗网络(GANs)生成对抗样本。AdvGAN训练前馈网络生成扰动,同时使用判别器网络确保生成的样本真实。在半白盒攻击中,生成器训练完成后无需访问目标模型;在黑盒攻击中,通过动态训练蒸馏模型优化生成器。
- 研究贡献:与基于优化的方法不同,AdvGAN训练条件对抗网络直接生成对抗样本,生成的样本感知真实且攻击成功率高,生成过程更高效;能通过训练蒸馏模型攻击黑盒模型,动态训练蒸馏模型实现高黑盒攻击成功率和目标性的黑盒攻击,克服基于可迁移性黑盒攻击的局限;在当前防御方法下,AdvGAN生成的对抗样本攻击成功率更高;在MNIST挑战中取得优异成绩,半白盒设置下准确率达88.93%,黑盒设置下达92.76%,位居榜首。
相关工作-Related Work
该部分主要回顾了对抗样本、黑盒攻击和生成对抗网络三个方面的相关研究,指出AdvGAN在生成对抗样本上的独特优势,具体内容如下:
- 对抗样本:在白盒攻击场景下,已有诸多生成对抗样本的策略。如 FGSM 通过损失函数的一阶近似构建对抗样本;基于优化的方法(Opt)能在满足特定约束下针对目标攻击优化对抗扰动,但优化过程缓慢且每次只能针对一个特定实例进行。与这些方法不同,AdvGAN使用前馈网络生成对抗样本,在攻击不同防御时成功率更高且速度更快。此外,虽然也有其他研究用前馈网络或GAN生成对抗样本,但目的和方式与AdvGAN不同,例如Baluja和Fischer通过结合重排序损失和 L 2 L_{2} L2 范数损失约束生成的对抗实例,而AdvGAN使用深度神经网络作为判别器提升样本感知质量;Hu和Tan利用GAN为恶意软件生成对抗样本,而AdvGAN专注于为图像生成感知真实的对抗样本。
- 黑盒攻击:当前学习系统因安全原因通常不允许白盒访问模型,因此黑盒攻击分析需求迫切。多数黑盒攻击策略基于可迁移性现象,即先训练本地模型生成对抗样本,期望这些样本能攻击其他模型,但依赖可迁移性存在局限。虽然有研究利用GANs为恶意软件构建逃避实例,或训练本地替代模型生成对抗样本,但仍未摆脱对可迁移性的依赖。AdvGAN则可在不依赖可迁移性的情况下进行黑盒攻击。
- 生成对抗网络(GANs):GANs在图像生成和处理方面成果显著,图像到图像的条件GANs进一步提升了合成结果的质量。AdvGAN采用类似的对抗损失和网络架构,学习从原始图像到扰动输出的映射,使扰动图像难以与原始类别的真实图像区分开来,且生成的结果不仅视觉上真实,还能误导目标学习模型。
使用对抗网络生成对抗样本-Generating Adversarial Examples with Adversarial Networks
问题定义-Problem Definition
这部分主要定义了在生成对抗样本场景下的相关概念和目标,具体内容如下:
- 基础定义:设特征空间 X ⊆ R n X \subseteq R^{n} X⊆Rn,其中 n n n 为特征数量。训练集中的第 i i i 个实例为 ( x i , y i ) (x_{i}, y_{i}) (xi,yi), x i ∈ X x_{i} \in X xi∈X 是根据未知分布 x i ∼ P d a t a x_{i} \sim P_{data} xi∼Pdata 生成的特征向量, y i ∈ Y y_{i} \in Y yi∈Y 是对应的真实类别标签。学习系统旨在从域 x x x 中学习一个分类器 f : X → Y f: X \to Y f:X→Y,其中 ∣ Y ∣ \vert Y \vert ∣Y∣ 表示可能的分类输出数量。
- 攻击目标:对于给定的实例 x x x,攻击者的目标是生成对抗样本 x A x_{A} xA. 在非目标性攻击中,需使 f ( x A ) ≠ y f(x_{A}) \neq y f(xA)=y,其中 y y y 为 x x x 的真实标签;在目标性攻击中,则要让 f ( x A ) = t f(x_{A}) = t f(xA)=t, t t t 为指定的目标类别。同时, x A x_{A} xA 需要在 L 2 L_{2} L2 或其他距离度量下与原始实例 x x x 接近,以此确保对抗样本在改变分类结果的同时,尽量保持与原始样本的相似性,增加攻击的隐蔽性和有效性。
AdvGAN框架-AdvGAN Framework
该部分详细介绍了AdvGAN的框架结构、各部分功能及相关损失函数,核心是通过多部分协作与损失函数优化,生成高质量对抗样本,具体如下:
- 框架构成:AdvGAN主要由生成器
G
G
G、判别器
D
D
D 和目标神经网络
f
f
f 组成。生成器
G
G
G 以原始样本
x
x
x 为输入,生成扰动
G
(
x
)
G(x)
G(x),
x
+
G
(
x
)
x + G(x)
x+G(x) 被送入判别器
D
D
D,判别器
D
D
D 用于区分生成的数据和原始实例
x
x
x. 目标神经网络(f)则用于计算对抗损失,以衡量生成的对抗样本对目标模型的欺骗效果。
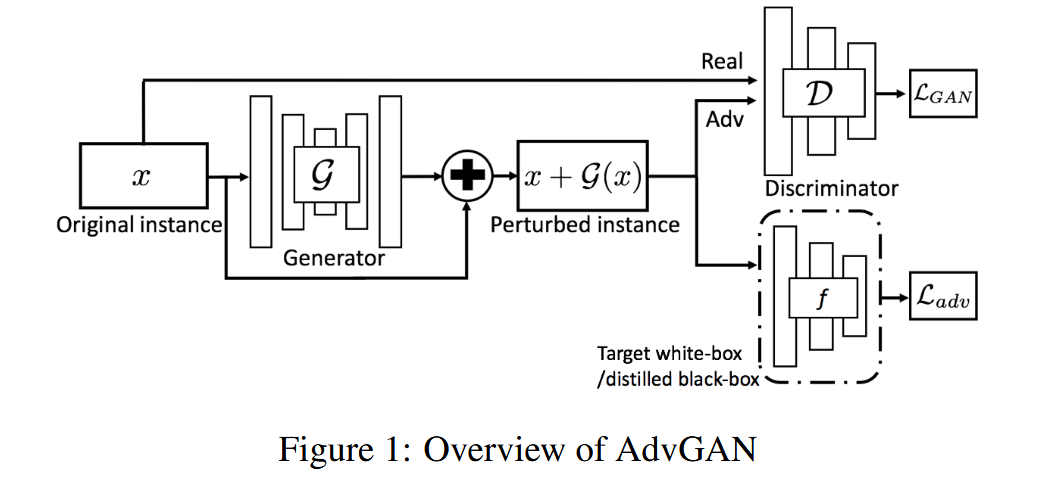
图1:AdvGAN概述 - 损失函数
- 对抗损失: L G A N = E x log D ( x ) + E x log ( 1 − D ( x + G ( x ) ) ) \mathcal{L}_{GAN}=\mathbb{E}_{x} \log \mathcal{D}(x)+\mathbb{E}_{x} \log (1 - \mathcal{D}(x+\mathcal{G}(x))) LGAN=ExlogD(x)+Exlog(1−D(x+G(x))),判别器 D D D 旨在区分扰动数据(x + G(x))与原始数据(x) ,通过该损失函数鼓励生成的实例接近原始类的数据。
- 愚弄目标模型损失(目标性攻击): L a d v f = E x ℓ f ( x + G ( x ) , t ) \mathcal{L}_{adv }^{f}=\mathbb{E}_{x} \ell_{f}(x+\mathcal{G}(x), t) Ladvf=Exℓf(x+G(x),t), t t t 为目标类, ℓ f \ell_{f} ℓf 是用于训练原始模型 f f f 的损失函数(如交叉熵损失),该损失函数促使扰动后的图像被误分类为目标类 t t t. 本文主要关注目标性攻击,非目标性攻击可通过最大化预测与真实标签之间的距离实现。
- 扰动幅度约束损失: L h i n g e = E x max ( 0 , ∥ G ( x ) ∥ 2 − c ) \mathcal{L}_{hinge }=\mathbb{E}_{x} \max \left(0,\| \mathcal{G}(x)\| _{2}-c\right) Lhinge=Exmax(0,∥G(x)∥2−c), c c c 是用户指定的界限,通过添加此软铰链损失约束扰动的幅度,稳定GAN的训练。
- 总损失函数: L = L a d v f + α L G A N + β L h i n g e \mathcal{L}=\mathcal{L}_{adv }^{f}+\alpha \mathcal{L}_{GAN }+\beta \mathcal{L}_{hinge } L=Ladvf+αLGAN+βLhinge, α \alpha α 和 β \beta β 控制各目标的相对重要性。通过求解极小极大博弈 arg min G max D L \arg \min _{G} \max _{D} L argminGmaxDL 得到生成器 G G G 和判别器 D D D,训练好的生成器 G G G 可用于为任何输入样本生成扰动,进行半白盒攻击。
利用对抗网络的黑盒攻击-Black-box Attacks with Adversarial Networks
这部分内容主要介绍了如何利用AdvGAN在黑盒攻击场景下进行攻击,提出了静态蒸馏和动态蒸馏两种方法,具体如下:
- 静态蒸馏:在黑盒攻击场景中,假设攻击者对训练数据和模型本身没有先验知识。为实现黑盒攻击,先基于黑盒模型 b b b 的输出构建蒸馏网络 f f f. 通过最小化蒸馏网络 f f f 与黑盒模型 b b b 输出之间的交叉熵损失 arg min f E x H ( f ( x ) , b ( x ) ) \arg \min _{f} \mathbb{E}_{x} \mathcal{H}(f(x), b(x)) argminfExH(f(x),b(x)),使蒸馏模型 f f f 的行为与黑盒模型 b b b 相近。得到蒸馏网络 f f f 后,采用与白盒攻击相同的策略(基于总损失函数 L \mathcal{L} L 优化生成器和判别器)对其进行攻击。但训练蒸馏模型 f f f 时使用所有类别的数据,这与仅使用原始类真实数据训练判别器 D D D 不同。
- 动态蒸馏:仅用所有原始训练数据训练蒸馏模型是不够的,因为不清楚黑盒模型和蒸馏模型在生成的对抗样本(未出现在训练集中)上的表现差异。所以提出一种交替最小化方法,在每次迭代中动态查询并联合训练蒸馏模型
f
f
f 和生成器
G
G
G.
具体分为两步:
一是在固定网络 f i − 1 f_{i - 1} fi−1 的情况下更新 G i G_{i} Gi,按照白盒攻击设置训练生成器和判别器;
二是在固定生成器 G i G_{i} Gi 的情况下更新 f i f_{i} fi,利用生成的对抗样本 x + G i ( x ) x + G_{i}(x) x+Gi(x) 和原始训练图像,基于查询结果更新蒸馏模型 f i f_{i} fi.
实验对比发现,动态蒸馏同时更新 G G G 和 f f f 能产生更高的攻击性能。
实验结果-Experimental Results
这部分主要对AdvGAN在不同攻击场景、不同数据集和模型下的性能进行了实验评估,并与其他攻击方法对比,验证了AdvGAN在生成对抗样本方面的有效性和优越性。

表1:与最先进的攻击方法的比较。运行时间是在测试期间生成1000个对抗样本的耗时。Opt.代表基于优化的方法,Trans.表示基于可迁移性的黑盒攻击。
- 实验设置
- 评估场景与数据集:在半白盒和黑盒攻击场景下,对MNIST、CIFAR-10和ImageNet数据集进行实验。为保证公平对比,不同攻击方法生成对抗样本时,MNIST数据集的 L ∞ L_{\infty} L∞ 约束为0.3,CIFAR-10数据集为8。
- 模型与参数设置:MNIST实验选用3种模型,CIFAR-10实验选用ResNet-32和Wide ResNet-34。生成器和判别器采用与图像到图像转换文献类似的架构,使用特定损失函数,设置批大小为128、学习率为0.001,GAN训练采用最小二乘目标函数。
- 半白盒攻击实验结果
- 攻击成功率与样本质量:在MNIST和CIFAR-10数据集上,AdvGAN对不同模型的半白盒攻击成功率高。生成的对抗样本在视觉上接近原始图像,且针对同一原始实例生成不同目标类别的对抗样本时,视觉质量稳定。
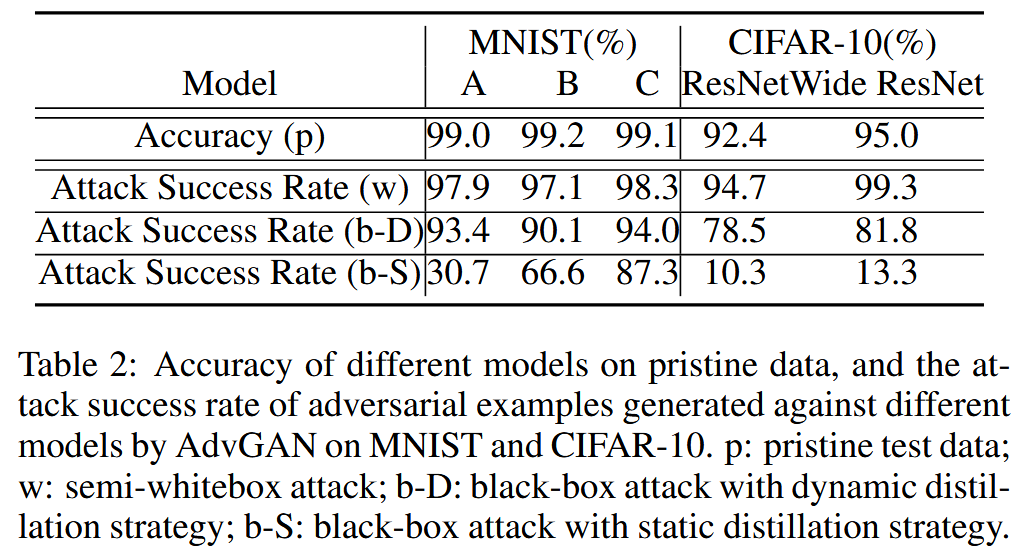
表2:不同模型在原始数据上的准确率,以及AdvGAN在MNIST和CIFAR-10数据集上针对不同模型生成的对抗样本的攻击成功率。p:原始测试数据;w:半白盒攻击;b-D:采用动态蒸馏策略的黑盒攻击;b-S:采用静态蒸馏策略的黑盒攻击。

图2:AdvGAN在MNIST数据集上针对同一原始图像生成的不同目标的对抗样本。第一行:半白盒攻击;第二行:黑盒攻击。从左到右依次为模型A、B和C。对角线上展示的是原始图像,顶部的数字表示目标类别。

图3:AdvGAN在CIFAR10数据集上生成的对抗样本,(a)为半白盒攻击,(b)为黑盒攻击。每个类别的图像都被扰动成其他不同类别的图像。对角线上展示的是原始图像。 - 损失函数影响:在MNIST数据集上,替换完整损失函数后,攻击成功率降低,证明AdvGAN所用完整损失函数的有效性。
- 攻击成功率与样本质量:在MNIST和CIFAR-10数据集上,AdvGAN对不同模型的半白盒攻击成功率高。生成的对抗样本在视觉上接近原始图像,且针对同一原始实例生成不同目标类别的对抗样本时,视觉质量稳定。
- 黑盒攻击实验结果:基于动态蒸馏策略,AdvGAN在MNIST和CIFAR-10数据集上生成的对抗样本攻击成功率大幅高于静态蒸馏。生成的对抗样本感知质量高,与原始实例相似(表2、图2和图3)。
- 防御下的攻击有效性评估
- 威胁模型:考虑较弱的威胁模型,即攻击者不知道防御措施,直接攻击原始学习模型。在此模型下评估攻击策略的鲁棒性。
- 半白盒攻击结果:使用三种对抗训练防御方法训练不同模型,AdvGAN生成的对抗样本在半白盒攻击下,对不同模型的攻击成功率高于FGSM和基于优化的方法(Opt.)。
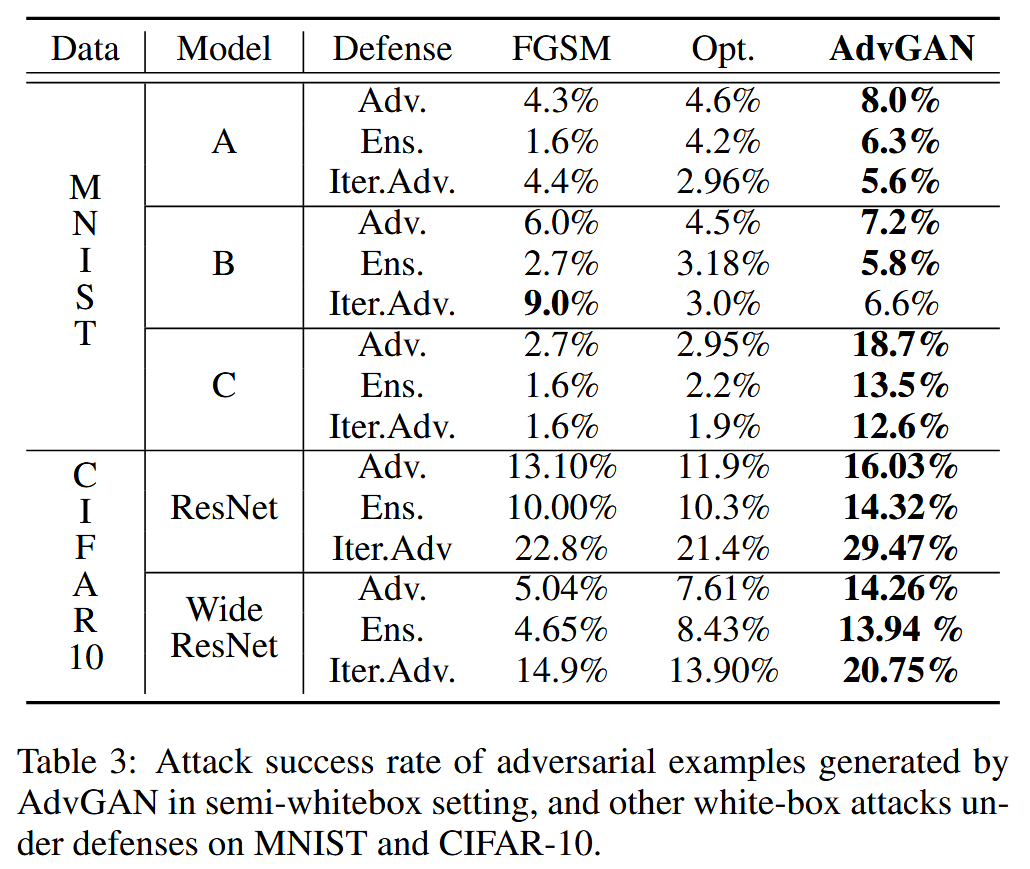
表3:MNIST和CIFAR-10数据集上,AdvGAN在半白盒设置下生成的对抗样本,以及其他白盒攻击在防御措施下的攻击成功率。 - 黑盒攻击结果:以不同模型作为黑盒模型进行实验,AdvGAN生成的对抗样本在黑盒攻击下,攻击成功率显著高于其他攻击方法。在MNIST挑战中,AdvGAN在白盒和黑盒设置下分别取得88.93%和92.76%的准确率,超越其他攻击策略。
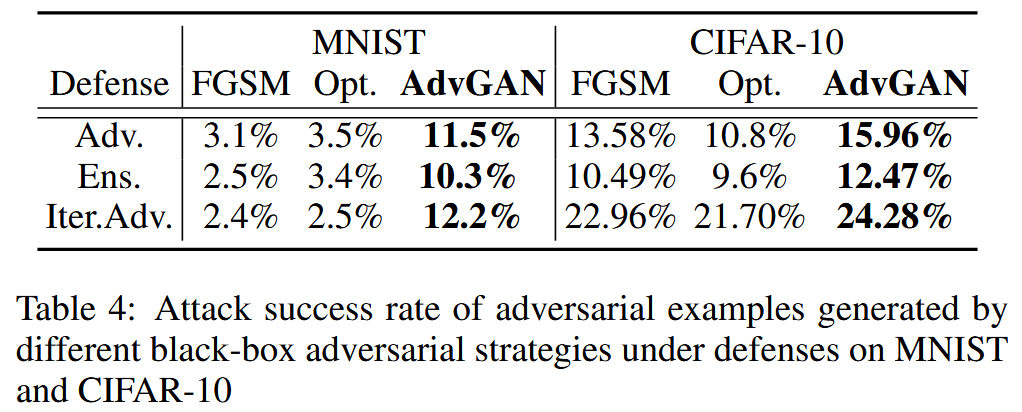
表4:MNIST和CIFAR-10数据集上,不同黑盒对抗策略生成的对抗样本在防御措施下的攻击成功率。

表5:MadryLab公开模型在白盒设置下遭受不同攻击时的准确率。此处AdvGAN表现最佳。
- 高分辨率对抗样本生成实验
- 实验设置与攻击成功率:对Inception_v3模型攻击,从特定数据集中选100张良性图像,生成
299
×
299
299×299
299×299 像素的对抗样本,
L
∞
L_{\infty}
L∞ 约束在0.01内,攻击成功率达100%。

图4:来自与ImageNet兼容的数据集的示例,标签表示相应的分类结果。左边:原始良性图像;右边:AdvGAN针对Inception_v3生成的对抗图像。 - 感知真实度评估:通过亚马逊土耳其机器人(AMT)进行用户研究,结果表明AdvGAN生成的高分辨率对抗样本与良性图像逼真度相当。
- 实验设置与攻击成功率:对Inception_v3模型攻击,从特定数据集中选100张良性图像,生成
299
×
299
299×299
299×299 像素的对抗样本,
L
∞
L_{\infty}
L∞ 约束在0.01内,攻击成功率达100%。
结论-Conclusion
这部分内容总结了AdvGAN的优势和潜在价值,强调了其在生成对抗样本、攻击能力以及对抗训练防御方面的重要意义。具体如下:
- 高效生成对抗扰动:AdvGAN借助生成对抗网络(GANs)生成对抗样本,训练好的前馈生成器能高效地为实例生成对抗扰动,在半白盒和黑盒攻击场景下都展现出高攻击成功率。
- 对抗样本质量高:在不了解防御措施的情况下,AdvGAN生成的对抗样本在不同模型上保持高感知质量。在面对当前先进的防御手段时,其生成的对抗样本攻击成功率比其他竞争方法更高。
- 潜在应用价值:上述特性使得AdvGAN成为改进对抗训练防御方法的有力候选方案。它在攻击和防御研究的平衡中,为提升神经网络的安全性和鲁棒性研究提供了新方向和思路。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











