







1. SVM简介
1.1 引入SVM
支持向量机(Support Vector Machine)于1995年首先提出,基本模型是的定义在特征空间上的间隔最大的线性分类器,SVM的学习策略就是间隔最大化。它在解决小样本、非线性及高维模式识别中表现出许多特有的优势,并能够推广应用到函数拟合等其他机器学习问题中。
- 小样本:SVM算法要求的样本数量相对较少
- 非线性:是指SVM擅长应付样本数据线性不可分的情况,主要通过松弛变量(也有人叫惩罚变量)和核函数技术来实现,这一部分是SVM的精髓。
- 高维模式识别:SVM 产生的分类器很简洁,用到的样本信息很少,擅长梳理高维度的数据。

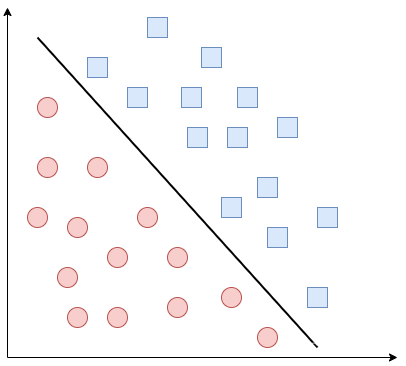
该坐标系中有两类点,途中画出了三个分类器的决策边界。凭借直观感受,我们认为H3的分类效果是最好的,首先H1不能把类别分开;H2可以,但分割线与最近的数据点只有很小的间隔,如果测试数据有一些噪声的话可能就会被H2错误分类(即对噪声敏感、泛化能力弱)。H3以较大间隔将它们分开,这样就能容忍测试数据的一些噪声而正确分类,是一个泛化能力不错的分类器。
1.2 SVM入门
线性分类器(一定意义上,也可以叫做感知机) 是最简单也很有效的分类器形式。在二维平面中,线性分类器的表示就是一条直线。如果一个线性函数能够将样本完全正确的分开,就称这些数据是线性可分的,否则称为非线性可分的。
什么叫线性函数呢?在一维空间里就是一个点,在二维空间里就是一条直线,三维空间里就是一个平面,可以如此想象下去,如果不关注空间的维数,这种线性函数还有一个统一的名称——超平面(Hyper Plane)!
一个线性函数是一个实值函数(即函数的值是连续的实数),而我们的分类问题需要离散的输出值,例如用1表示某个样本属于类别,而用0表示不属于,这时候只需要简单的在实值函数的基础上附加一个阈值即可。线性函数的公式通常如下:
g
(
x
)
=
w
T
x
+
b
g(x)=w^T x+b
g(x)=wTx+b
在Logistic算法中,我们通常将阈值设置为0,当 g(x) > 0 时,我们判断类别为1,小于0则判断类别为0,但是当 g(x) 的值接近0的时候,分类器就十分缺乏说服力了。
而在SVM算法中,通常将类别表示为1和-1,阈值设置为1和-1,如下公式:
{
if
w
T
x
i
+
b
>
1
,
y
i
=
1.
if
w
T
x
i
+
b
<
−
1
,
y
i
=
−
1.
\left\{\begin{array}{l} \text { if } \quad w^{T} x_{i}+b> \ 1, \ y_{i}=1. \\ \text { if } \quad w^{T} x_{i}+b<-1, \ y_{i}=-1. \end{array}\right.
{ if wTxi+b> 1, yi=1. if wTxi+b<−1, yi=−1.
根据1.1中的图片,为了使模型的泛化效果更好,我们希望找到一条能够很好的对点进行分割的超平面,大致体现为这个超平面不会挨着某些点很近。综上,我们希望寻找这样一个超片面:距离超平面最近的点到超平面的距离最远!
2. 分类间隔
需要有一个指标来衡量解决方案(即我们通过训练建立的分类模型)的好坏,而分类间隔是一个比较好的指标。首先,我们将数据集中的第 i 个数据表示为:
D
i
=
(
x
i
,
y
i
)
D_{i}=\left(x_{i}, y_{i}\right)
Di=(xi,yi)
首先,我们了解一下范式概念,范数是对向量长度的一种度量。我们常说的向量长度其实指的是它的2-范数,范数最一般的表示形式为p-范数,可以将写成如下表达式:
w
=
(
w
1
,
w
2
,
w
3
,
…
…
w
n
)
w=\left(w_{1}, w_{2}, w_{3}, \ldots \ldots w_{n}\right)
w=(w1,w2,w3,……wn)
那么这个向量的p-范式为
∥
ω
∥
p
=
ω
1
p
+
ω
2
p
+
ω
3
p
…
+
ω
n
p
p
\|\omega\|_{p}=\sqrt[p]{\omega_{1}^{p}+\omega_{2}^{p}+\omega_{3}^{p} \ldots+\omega_{n}^{p}}
∥ω∥p=pω1p+ω2p+ω3p…+ωnp
当p换成2时,就是传统的向量长度。通常当我们不指明p的时候,就忽略掉p值,以为不必关心p值,用几范数都可以。不过一般我们似乎会优先当作二范式,也就是代表向量长度。
在二维坐标系中,点到直线的距离公式为
d
=
∣
A
x
0
+
B
y
0
+
C
A
2
+
B
2
∣
d=\left|\frac{A x_{0}+B y_{0}+C}{\sqrt{A^{2}+B^{2}}}\right|
d=∣
∣A2+B2Ax0+By0+C∣
∣
将该公式映射到多维坐标系,结果便很明了,用范式表示如下:
d
=
∣
w
T
x
i
+
b
∣
∥
w
∥
d=\frac{\left|w^{T} x_{i}+b\right|}{\|w\|}
d=∥w∥∣
∣wTxi+b∣
∣
根据SVM的阈值公式,我们知道,在笛卡尔坐标系上,我们会有两个决策边界,公式如下所示。在二维和三维中,决策边界分别表示为直线和平面。
{
ω
T
x
i
+
b
+
1
=
0
ω
T
x
i
+
b
−
1
=
0
\left\{\begin{array}{l} {\omega}^{T} x_{i}+b+1=0 \\ {\omega}^{T} x_{i}+b-1=0 \end{array}\right.
{ωTxi+b+1=0ωTxi+b−1=0
那么我们该如何计算两个超平面之间的距离?根据上面的距离公式,我们能够很轻松地就推导得到,这倒是一个优雅美丽的公式。
d
=
2
∥
w
∥
d=\frac{2}{\|w\|}
d=∥w∥2
当然,我们的目的是希望离超平面最近的点到超平面的距离最远,这里也只是简单做了一下其它引申,我们更应该考虑的还是点到超平面的距离。结合SVM的阈值公式,我们对点到超平面的距离公式略作变形:
distance
=
1
∥
w
∥
y
i
(
w
T
x
i
+
b
)
\text { distance }=\frac{1}{\|w\|} y_{i}\left(w^{T} x_{i}+b\right)
distance =∥w∥1yi(wTxi+b)
3. 最优间隙分类器
那么我们的目标就是找到离超平面最近的数据点,然后让其距离超平面最远,并求出参数w,b。这就可以写作:
arg
max
w
,
b
{
min
i
(
y
i
⋅
(
ω
T
x
i
+
b
)
)
⋅
1
∥
w
∥
}
\arg \max _{w, b}\left\{\min _{i}\left(y_{i} \cdot\left(\omega^{T} x_{i}+b\right)\right) \cdot \frac{1}{\|w\|}\right\}
argw,bmax{imin(yi⋅(ωTxi+b))⋅∥w∥1}
通过控制 w 和 b 来使得距离最远,通过控制 xi选中离超平面最近的点。根据阈值的公式,显然可以知道:
y
i
⋅
(
ω
T
x
i
+
b
)
≥
1
y_{i} \cdot\left(\omega^{T} x_{i}+b\right) \geq 1
yi⋅(ωTxi+b)≥1
我们这里可以认为左边表达式的最小值可以取到1,原因是如果超平面可以正确分类样本,那么总存在这样一个放缩变换:
{
ζ
w
→
w
′
ζ
b
→
b
′
\left\{\begin{array}{l} \zeta w \ \rightarrow \ w^{\prime} \\ \zeta b \ \rightarrow \ b^{\prime} \end{array}\right.
{ζw → w′ζb → b′
使得等式的右边为1。因此,我们可以将目标式改写成:
m
a
x
w
,
b
1
∥
w
∥
m a x_{w, b} \frac{1}{\|w\|}
maxw,b∥w∥1
到现在,我们就将目标转化成了一个优化问题,对于优化问题,我们通常求解最小值;此外,我们有必要考虑到实际性的约束:使得每一个点都在超平面的两侧!那么,我们就需要加入约束方程。对目标函数稍作改变,我们得到这样一个优化问题,也就是SVM的最终目标。
{
min
w
,
b
1
2
∥
w
∥
2
s.t.
y
i
(
w
T
x
i
+
b
)
⩾
1
,
i
=
1
,
2
,
…
,
m
\left\{\begin{array}{l} \min _{w, b} \frac{1}{2}\|w\|^{2} \\ \text { s.t. } y_{i}\left(w^{T} x_{i}+b\right) \geqslant 1, i=1,2, \ldots, m \end{array}\right.
{minw,b21∥w∥2 s.t. yi(wTxi+b)⩾1,i=1,2,…,m
4. Lagrange Multiplier
4.1 凸优化
在动手求一个优化的解之前我们必须先考虑:这个问题是不是有解?如果有解,是否能找到?对于一般意义上的规划问题,两个问题的答案都是不一定,但凸二次规划让人喜欢的地方就在于,它有解,而且可以找到,当时算法不同收敛速度也会随之不同。
(1)凸集
什么是凸集,对于n维空间中点的集合C,如果对集合中的任意两点 x 和 y ,以及实数 0≤θ≤1 ,都有:
θ
x
+
(
1
−
θ
)
y
∈
C
\theta \mathrm{x}+(1-\theta) \mathrm{y} \in C
θx+(1−θ)y∈C
则称该集合称为凸集。如果把这个集合画出来,其边界是凸的,没有凹进去的地方。直观来看,把该集合中的任意两点用直线连起来,直线上的点都属于该集合。
(2)凸函数
在微积分中我们学习过凸函数的定义,下面来回忆一下。在函数的定义域内,如果对于任意的 x 和 y ,以及实数0≤θ≤1,都满足如下条件:
f
(
θ
x
+
(
1
−
θ
)
y
)
≤
θ
f
(
x
)
+
(
1
−
θ
)
f
(
y
)
f(\theta \mathrm{x}+(1-\theta) \mathrm{y}) \leq \theta f(\mathrm{x})+(1-\theta) f(\mathrm{y})
f(θx+(1−θ)y)≤θf(x)+(1−θ)f(y)
则函数为凸函数。这个不等式和凸集的定义类似。从图像上看,一个函数如果是凸函数,那么它是向下凸出去的。用直线连接函数上的任何两点A和B,线段AB上的点都在函数的上方。
(3)凸优化
有了凸集和凸函数的定义之后,我们就可以给出凸优化的定义。如果一个最优化问题的可行域是凸集,并且目标函数是凸函数,则该问题为凸优化问题。凸优化问题可以形式化的写成:
min
f
(
x
)
x
∈
C
\begin{array}{l} \min f(\mathrm{x}) \\ {\mathrm{x} \in C} \end{array}
minf(x)x∈C
从最一般的定义上说,一个求最小值的问题就是一个优化问题(也叫寻优问题,更文绉绉的叫法是规划——Programming),它同样由两部分组成,目标函数和约束条件,可以用下面的式子表示:
min
f
(
x
)
s
u
b
j
e
c
t
t
o
c
i
(
x
)
≤
0
i
=
1
,
2
,
…
,
p
c
j
(
x
)
=
0
j
=
p
+
1
,
p
+
2
,
…
,
p
+
q
\min f(x) \\ subject to c_{i}(x) \leq 0 \quad i=1,2, \ldots, p \\ \quad c_{j}(x)=0 \quad j=p+1, p+2, \ldots, p+q
minf(x)subjecttoci(x)≤0i=1,2,…,pcj(x)=0j=p+1,p+2,…,p+q
凸优化的特点:
- 有最优解,可以找到!
- 局部最优解就是全局最优解
4.2 拉格朗日乘数法
(1)等式约束
首先我们看一下存在等式约束的极值问题求法,比如下面的最优化问题:
min
w
f
(
w
)
s.t.
h
i
(
w
)
=
0
,
i
=
1
,
…
,
l
\begin{array}{cc} \min _{w} & f(w) \\ \text { s.t. } & h_{i}(w)=0, \quad i=1, \ldots, l \end{array}
minw s.t. f(w)hi(w)=0,i=1,…,l
目标函数是f(w),下面是等式约束。通常解法是引入拉格朗日算子,这里使用β来表示算子,得到拉格朗日公式为:
L
(
w
,
β
)
=
f
(
w
)
+
∑
i
=
1
l
β
i
h
i
(
w
)
\mathcal{L}(w, \beta)=f(w)+\sum_{i=1}^{l} \beta_{i} h_{i}(w)
L(w,β)=f(w)+i=1∑lβihi(w)
然后分别对 ω 和 β 求偏导,使得偏导数等于0,然后解出ω 和 βi。
(2)KKT条件
对于含有不等式约束的优化问题,如何求取最优值呢?常用的方法是KKT条件,同样地,把所有的不等式约束、等式约束和目标函数全部写为一个式子
L
(
a
,
b
,
x
)
=
f
(
x
)
+
a
g
(
x
)
+
b
h
(
x
)
L(a, b, x)=f(x)+a g(x)+b h(x)
L(a,b,x)=f(x)+ag(x)+bh(x)
KKT条件是说最优值必须满足以下条件:
- L(a, b, x)对x求导为零
- h(x) =0
- a*g(x) = 0
求取这些等式之后就能得到候选最优值。其中第三个式子非常有趣,因为g(x)<=0,如果要满足这个等式,必须a=0或者g(x)=0. 这是SVM的很多重要性质的来源,如支持向量的概念。
这些个条件也让我想起了在学习运筹学时看到的一句话:线性规划如果存在最优解,那必然可以在某一个边界处的交点上可以取到。
(3)不等式约束
在了解KKT条件以后,我们开始探讨有不等式约束的极值问题求法。
min
w
f
(
w
)
s.t.
g
i
(
w
)
≤
0
,
i
=
1
,
…
,
k
h
i
(
w
)
=
0
,
i
=
1
,
…
,
l
\begin{array}{cc} \min _{w} & f(w) \\ \text { s.t. } & g_{i}(w) \leq 0, \quad i=1, \ldots, k \\ & h_{i}(w)=0, \quad i=1, \ldots, l \end{array}
minw s.t. f(w)gi(w)≤0,i=1,…,khi(w)=0,i=1,…,l
我们定义一般的拉格朗日公式:
L
(
w
,
α
,
β
)
=
f
(
w
)
+
∑
i
=
1
k
α
i
g
i
(
w
)
+
∑
i
=
1
l
β
i
h
i
(
w
)
\mathcal{L}(w, \alpha, \beta)=f(w)+\sum_{i=1}^{k} \alpha_{i} g_{i}(w)+\sum_{i=1}^{l} \beta_{i} h_{i}(w)
L(w,α,β)=f(w)+i=1∑kαigi(w)+i=1∑lβihi(w)
求出的极值点满足KKT条件:
{
∂
L
∂
w
=
0
α
i
⩾
0
α
i
g
i
(
w
)
=
0
g
i
(
w
)
⩽
0
\left\{\begin{array}{l} \frac{\partial L}{\partial w}=0 \\ \alpha_i \geqslant 0 \\ \alpha_{i} g_{i}(w)=0 \\ g_{i}(w) \leqslant 0 \end{array}\right.
⎩
⎨
⎧∂w∂L=0αi⩾0αigi(w)=0gi(w)⩽0
根据这些限制条件,我们往往就可以找到极值点!
注意,我们这里的约束方程都是凸函数。KKT的总体思想是将极值会在可行域边界上取得,也就是不等式为0或等式约束里取得,而最优下降方向一般是这些等式的线性组合,其中每个元素要么是不等式为0的约束,要么是等式约束。
5. SVM的求解
基于上述的理论,我们首先构建拉格朗日函数。不过不要忘记了我们的目标:最小化下面这个函数,找到对应的的W和b。
L
(
W
,
b
,
α
)
=
1
2
∥
W
∥
2
−
∑
i
=
1
n
α
i
[
y
i
(
X
i
T
W
+
b
)
−
1
]
L(W, b, \alpha)=\frac{1}{2}\|W\|^{2}-\sum_{i=1}^{n} \alpha_{i}\left[y_{i}\left(X_{i}^{T} W+b\right)-1\right]
L(W,b,α)=21∥W∥2−i=1∑nαi[yi(XiTW+b)−1]
根据KKT条件,我们分别对W和b求偏导,并令其导函数为0,可以得到这样两个式子:
{
∣
W
∣
=
∑
i
=
1
n
α
i
x
i
y
i
∑
i
=
1
n
α
i
y
i
=
0
\left\{\begin{array}{l} {|W|}=\sum_{i=1}^{n} \alpha_{i} x_{i} y_{i} \\ \sum_{i=1}^{n} \alpha_{i} y_{i}=0 \end{array}\right.
{∣W∣=∑i=1nαixiyi∑i=1nαiyi=0
我们将这两个表达式代入到原函数,经过化简,最终可以得到这样一个简洁美丽的函数:
L
=
∑
i
=
1
n
α
i
−
1
2
∑
i
∑
j
α
i
α
j
y
i
y
j
x
i
x
j
L=\sum_{i=1}^{n} \alpha_{i}-\frac{1}{2} \sum_{i} \sum_{j} \alpha_{i} \alpha_{j} y_{i} y_{j} x_{i} x_{j}
L=i=1∑nαi−21i∑j∑αiαjyiyjxixj
这个时候,我们的目标函数已经不包含w和b了,而仅仅包含α,已经不是我们曾经的函数了。我们这里只能针对α做优化,实际上我们得到了一个原模型的对偶模型。在运筹学基础理论中,我们知道,原问题和对偶问题如果均存在最优解,那么两个模型的最优解带入函数得到的值是一样的。另外,对偶问题和原问题的最大化最小化目标是相反的!
因此下一步,我们便要建立一个“新的”优化模型,求出对应的α,而后一步一步回代求出w和b。此时待处理的优化模型为:
max
α
L
=
∑
i
=
1
n
α
i
−
1
2
∑
i
∑
j
α
i
α
j
y
i
y
j
x
i
x
j
.
s.t.
∑
α
i
y
i
=
0
\begin{array}{l} \max _{\alpha} \quad L=\sum_{i=1}^{n} \alpha_{i}-\frac{1}{2} \sum_{i} \sum_{j} \alpha_{i} \alpha_{j} y_{i} y_{j} x_{i} x_{j} . \\ \text { s.t. } \sum \alpha_{i} y_{i}=0 \end{array}
maxαL=∑i=1nαi−21∑i∑jαiαjyiyjxixj. s.t. ∑αiyi=0
而对于该模型的寻优,就需要通过SMO算法了,本文不做介绍。
why 支持向量?
当样本点 xi 没有落在虚线上,即:wx + b ≠ ±1 ,有 1 − y (wx + b) ≠ 0 ,此时根据KKT条件的第二条,必须要有 λi=0 。
当样本点 xi 落在虚线上,即:wx + b = 1或−1 ,有 1 − y (wx + b) = 0 ,此时根据KKT条件的第二条, λi 取值没有限制。
而我们的求解参数 w∗ 和 b∗ 是和 λi 息息相关(参考上面求导后的两个公式),如果样本点不落在虚线上,那么其λi=0,在累加 w∗时它的贡献值始终为0。也就是说,只有落在虚线上的点才对求解参数有影响,而这些点就被称为支持向量。
6. 核函数
6.1 升维映射
以上,我们使用SVM处理的都是线性问题,但如果是非线性的,我们的做法是通过核函数将非线性问题转化成线性问题,我们有这样一个数学结论:可以把一个非线性可分数据集映射到足够足够高的维度,使其线性可分。
针对到每一个数据,就是将其从低纬度向高纬度做映射。
x
i
→
φ
(
x
i
)
x_{i} \rightarrow \varphi_{\left(x_{i}\right)}
xi→φ(xi)
将映射后的数据带入函数中,得到:
L
=
Max
∑
i
=
1
m
α
i
−
1
2
∑
i
=
1
m
∑
14
m
α
i
y
i
α
j
y
j
φ
(
x
i
T
)
φ
(
x
j
)
L=\operatorname{Max} \sum_{i=1}^{m} \alpha_{i}-\frac{1}{2} \sum_{i=1}^{m} \sum_{14}^{m} \alpha_{i} y_{i} \alpha_{j} y_{j} \varphi\left(x_{i}^{T}\right) \varphi\left(x_{j}\right)
L=Maxi=1∑mαi−21i=1∑m14∑mαiyiαjyjφ(xiT)φ(xj)
另外,假设我们有这样的一组数据集:
d
i
=
(
x
1
i
x
2
i
)
d_{i}=\left(\begin{array}{l} x_{1}^{i} \\ x_{2}^{i} \end{array}\right)
di=(x1ix2i)
我们对数据进行升高维度的映射,需要满足这样子的基本性质:
φ
(
d
1
)
⊤
⋅
φ
(
d
2
)
=
(
d
1
⋅
d
2
)
2
\varphi\left(d_{1}\right)^{\top} \cdot \varphi\left(d_{2}\right) = \left(d_{1} \cdot d_{2}\right)^{2}
φ(d1)⊤⋅φ(d2)=(d1⋅d2)2
根据这条性质,再找到核函数以后,实际上又可以把数据从高维回溯到低维进行运算。我们令
K
(
x
i
,
x
j
)
=
φ
(
x
1
)
⊤
⋅
φ
(
x
2
)
K(x_i,x_j) = \varphi\left(x_{1}\right)^{\top} \cdot \varphi\left(x_{2}\right)
K(xi,xj)=φ(x1)⊤⋅φ(x2)
这里的K我们就称之为核函数!此时原函数就变为:
L
=
Max
∑
i
=
1
m
α
i
−
1
2
∑
i
=
1
m
∑
14
m
α
i
y
i
α
j
y
j
K
(
x
i
,
x
j
)
L=\operatorname{Max} \sum_{i=1}^{m} \alpha_{i}-\frac{1}{2} \sum_{i=1}^{m} \sum_{14}^{m} \alpha_{i} y_{i} \alpha_{j} y_{j} K(x_i,x_j)
L=Maxi=1∑mαi−21i=1∑m14∑mαiyiαjyjK(xi,xj)
6.2 常见核函数
(1)线性核函数
K
(
x
,
x
i
)
=
x
⋅
x
i
K(x,x_i)=x⋅x_i
K(x,xi)=x⋅xi
线性核,主要用于线性可分的情况,我们可以看到特征空间到输入空间的维度是一样的,其参数少速度快,对于线性可分数据,其分类效果很理想,因此我们通常首先尝试用线性核函数来做分类,看看效果如何,如果不行再换别的
(2)多项式核函数
K
(
x
,
x
i
)
=
(
(
x
⋅
x
i
)
+
1
)
d
K(x,x_i)=((x⋅x_i)+1)^d
K(x,xi)=((x⋅xi)+1)d
多项式核函数可以实现将低维的输入空间映射到高纬的特征空间,但是多项式核函数的参数多,当多项式的阶数比较高的时候,核矩阵的元素值将趋于无穷大或者无穷小,计算复杂度会大到无法计算。
(3)高斯核函数RBF
k
(
x
,
x
′
)
=
e
−
∥
x
−
x
′
∥
2
2
σ
2
k\left(x, x^{\prime}\right)=e^{-\frac{\left\|x-x^{\prime}\right\|^{2}}{2 \sigma^{2}}}
k(x,x′)=e−2σ2∥x−x′∥2
值得注意,根据泰勒公式,RBF实际上直接将数据映射到了无穷维度!
高斯径向基函数是一种局部性强的核函数,其可以将一个样本映射到一个更高维的空间内,该核函数是应用最广的一个,无论大样本还是小样本都有比较好的性能,而且其相对于多项式核函数参数要少,因此大多数情况下在不知道用什么核函数的时候,优先使用高斯核函数。
(4)核函数的选取
在选用核函数的时候,如果我们对我们的数据有一定的先验知识,就利用先验来选择符合数据分布的核函数;如果不知道的话,通常使用交叉验证的方法,来试用不同的核函数,误差最下的即为效果最好的核函数,或者也可以将多个核函数结合起来,形成混合核函数。
- 如果特征的数量大到和样本数量差不多,则选用LR或者线性核的SVM;
- 如果特征的数量小,样本的数量正常,则选用SVM+高斯核函数;
- 如果特征的数量小,而样本的数量很大,则需要手工添加一些特征从而变成第一种情况。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











