




目录
一、项目概述
1.1 项目介绍
本项目基于拉勾网 2019 年 11 月初至 12 月初的岗位数据(lagou01.csv和lagou02.xlsx),原始数据集总量为3142条,标签为10个。按照数据分析标准流程完成数据合并、预处理及可视化分析。核心目标包括:分析岗位需求趋势、热门城市 Top10、不同城市薪资水平及学历要求,最终通过图表直观呈现分析结果。
1.2 核心结论
需求趋势:2019 年 11 月下旬至 12 月初,数据分析师岗位需求快速上升。
热门城市:北京、成都、武汉需求最高,均超 400 个岗位。
薪资水平:北京平均薪资最高(约 21k),上海、杭州次之。
学历要求:本科学历需求占比 67.9%,是主流学历门槛。
1.3 处理后数据集预览

二、环境准备与数据加载
2.1 依赖库安装与导入
# 安装必要库(若未安装)
# !pip install pandas numpy matplotlib openpyxl
# 导入库
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
# 使用Windows自带中文字体(微软雅黑/宋体)便于图表中文正常显示
plt.rcParams['font.sans-serif'] = ['Microsoft YaHei', 'SimSun', 'SimHei'] # 多个字体备选,避免缺失
plt.rcParams['axes.unicode_minus'] = False # 解决负号显示问题2.2 数据加载
加载两个数据源并查看基础信息,确保数据完整性:
# 加载CSV文件时指定encoding='gbk'
df_csv = pd.read_csv('lagou01.csv', encoding='gbk')
df_xlsx = pd.read_excel('lagou02.xlsx')
# 查看数据基本信息
print("=== CSV文件基础信息 ===")
print(f"数据形状:{df_csv.shape}")
print(f"列名:{list(df_csv.columns)}")
print("\n=== Excel文件基础信息 ===")
print(f"数据形状:{df_xlsx.shape}")
print(f"列名:{list(df_xlsx.columns)}")三、数据合并与预处理
3.1 数据合并
两个文件列标题相同,保留与分析目标相关的字段(城市、薪资、学历、发布时间等)后进行合并:
# 定义核心字段(与分析目标相关)
core_columns = ['city', 'companyFullName', 'salary', 'companySize', 'district',
'education', 'firstType', 'positionAdvantage', 'workYear', 'createTime']
# 筛选核心字段(处理列名可能的差异,取交集)
common_columns = list(set(df_csv.columns) & set(df_xlsx.columns) & set(core_columns))
df_csv_filtered = df_csv[common_columns].copy()
df_xlsx_filtered = df_xlsx[common_columns].copy()
# 合并数据
df_merged = pd.concat([df_csv_filtered, df_xlsx_filtered], ignore_index=True)
print(f"\n合并后数据形状:{df_merged.shape}")
print(f"缺失值统计:\n{df_merged.isnull().sum()}")3.2 数据预处理
# 删除重复行并重置索引
df_merged = df_merged.drop_duplicates().reset_index(drop=True)
print(f"删除重复值后数据形状:{df_merged.shape}")
df_merged['district'] = df_merged['district'].fillna('未知')
print(f"缺失值处理后:\n{df_merged.isnull().sum()}")
def calculate_avg_salary(salary_str):
"""将薪资范围转换为平均薪资"""
if pd.isna(salary_str):
return np.nan
# 提取数字(处理"k"和"-")
import re
nums = re.findall(r'\d+', salary_str)
if len(nums) == 2:
return (int(nums[0]) + int(nums[1])) / 2
return np.nan
# 应用薪资转换函数
df_merged['avg_salary'] = df_merged['salary'].apply(calculate_avg_salary)
# 查看薪资分布
print(f"\n薪资统计(单位:k):\n{df_merged['avg_salary'].describe()}")
df_merged['createTime'] = pd.to_datetime(df_merged['createTime'], errors='coerce')
# 提取日期(忽略时间)
df_merged['publish_date'] = df_merged['createTime'].dt.date四、数据分析与可视化实现
4.1 数据分析师岗位需求趋势(折线图)
统计每日岗位发布数量,展示需求变化趋势:
# 统计每日岗位数量
daily_demand = df_merged.groupby('publish_date').size().reset_index(name='demand_count')
# 创建折线图
plt.figure(figsize=(12, 6))
plt.plot(daily_demand['publish_date'], daily_demand['demand_count'],
marker='o', linewidth=2, color='#2E86AB')
plt.title('数据分析师岗位需求趋势(2019.11-2019.12)', fontsize=14, pad=20)
plt.xlabel('发布日期', fontsize=12)
plt.ylabel('岗位数量', fontsize=12)
plt.grid(True, alpha=0.3)
plt.xticks(rotation=45)
plt.tight_layout()
plt.savefig('岗位需求趋势.png', dpi=300)
plt.show()
# 趋势结论
print("需求趋势结论:从11月下旬开始,岗位需求呈快速上升趋势")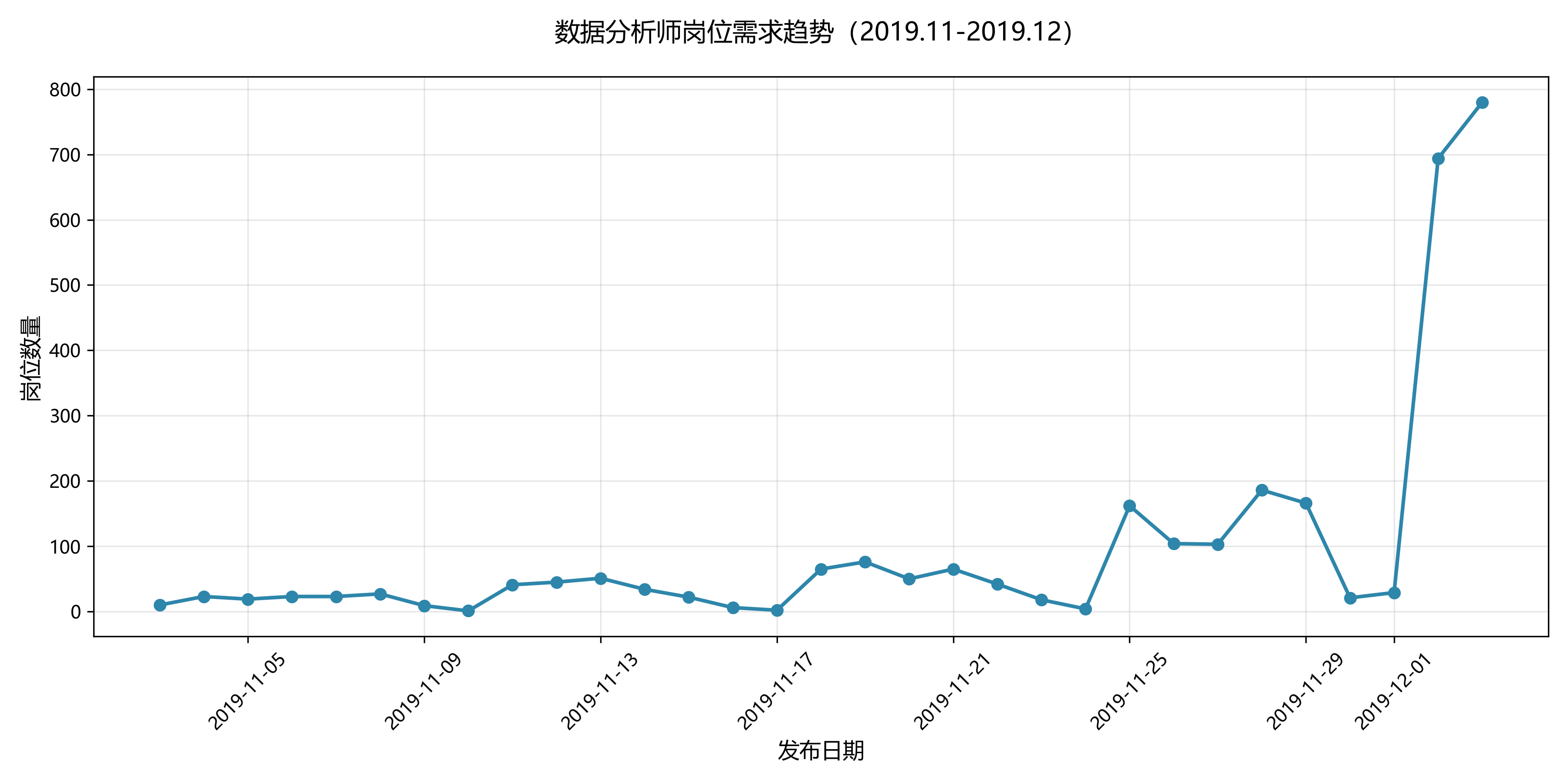
4.2 热门城市 Top10(柱形图)
统计各城市岗位数量,展示需求前 10 的城市:
# 统计各城市岗位数量并取Top10
city_demand = df_merged.groupby('city').size().sort_values(ascending=False).head(10).reset_index(name='demand_count')
# 创建柱形图
plt.figure(figsize=(12, 6))
bars = plt.bar(city_demand['city'], city_demand['demand_count'], color='#A23B72')
plt.title('数据分析师岗位热门城市Top10', fontsize=14, pad=20)
plt.xlabel('城市', fontsize=12)
plt.ylabel('岗位数量', fontsize=12)
plt.xticks(rotation=45)
# 在柱形上方添加数值标签
for bar in bars:
height = bar.get_height()
plt.text(bar.get_x() + bar.get_width()/2., height + 5,
f'{int(height)}', ha='center', va='bottom', fontsize=10)
plt.grid(True, alpha=0.3, axis='y')
plt.tight_layout()
plt.savefig('热门城市Top10.png', dpi=300)
plt.show()
# 热门城市结论
print(f"需求最高的三个城市:{city_demand.iloc[0]['city']}({city_demand.iloc[0]['demand_count']}个)、{city_demand.iloc[1]['city']}、{city_demand.iloc[2]['city']}")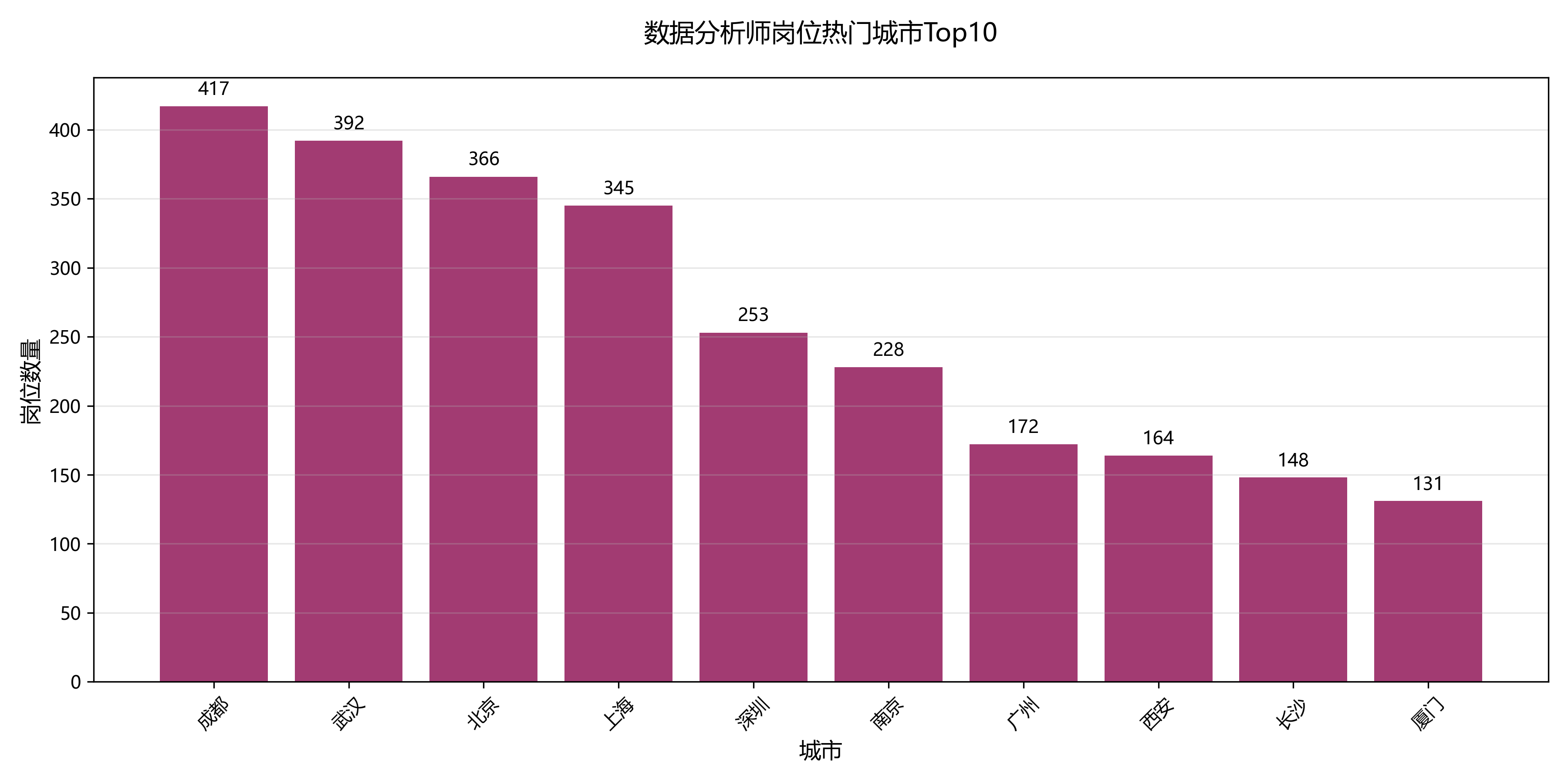
4.3 不同城市薪资水平(柱形图)
计算热门城市的平均薪资,对比薪资差异:
# 计算Top10热门城市的平均薪资
city_salary = df_merged[df_merged['city'].isin(city_demand['city'])]
city_salary_avg = city_salary.groupby('city')['avg_salary'].mean().sort_values(ascending=False).reset_index()
# 创建柱形图
plt.figure(figsize=(12, 6))
bars = plt.bar(city_salary_avg['city'], city_salary_avg['avg_salary'], color='#F18F01')
plt.title('不同城市数据分析师岗位平均薪资', fontsize=14, pad=20)
plt.xlabel('城市', fontsize=12)
plt.ylabel('平均薪资(k)', fontsize=12)
plt.xticks(rotation=45)
# 添加数值标签
for bar in bars:
height = bar.get_height()
plt.text(bar.get_x() + bar.get_width()/2., height + 0.2,
f'{height:.1f}k', ha='center', va='bottom', fontsize=10)
plt.grid(True, alpha=0.3, axis='y')
plt.tight_layout()
plt.savefig('不同城市薪资水平.png', dpi=300)
plt.show()
# 薪资结论
print(f"平均薪资最高的城市:{city_salary_avg.iloc[0]['city']}({city_salary_avg.iloc[0]['avg_salary']:.1f}k)")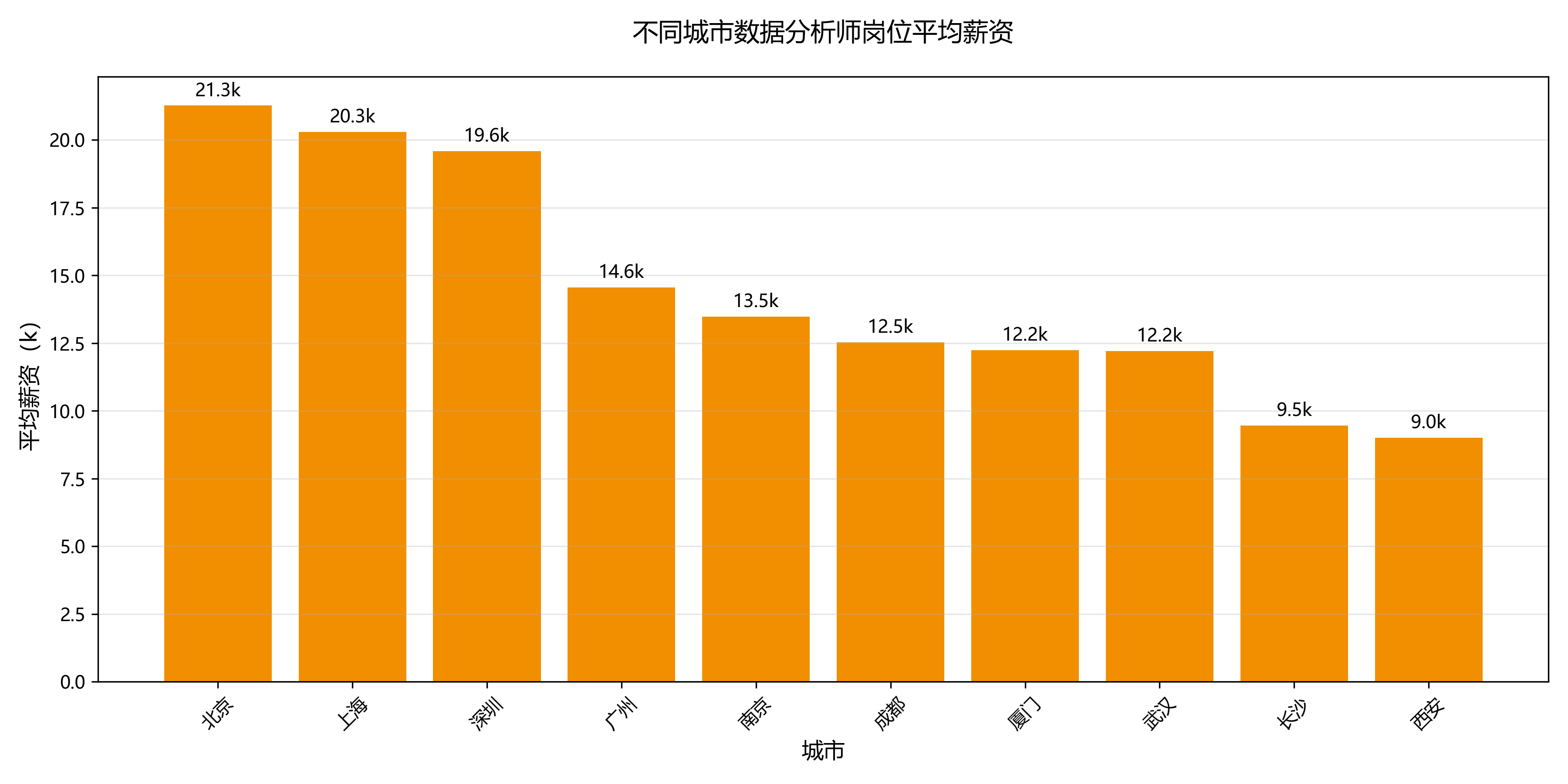
4.4 岗位学历要求(饼图)
统计不同学历要求的占比,展示学历需求分布:
# 统计学历要求占比
education_ratio = df_merged.groupby('education').size().reset_index(name='count')
education_ratio['percentage'] = (education_ratio['count'] / education_ratio['count'].sum() * 100).round(2)
# 创建饼图
plt.figure(figsize=(10, 8))
colors = ['#C73E1D', '#2E86AB', '#A23B72', '#F18F01', '#6A994E']
wedges, texts, autotexts = plt.pie(education_ratio['count'],
labels=education_ratio['education'],
autopct='%1.2f%%',
colors=colors,
startangle=90,
textprops={'fontsize': 12})
plt.title('数据分析师岗位学历要求分布', fontsize=14, pad=20)
plt.axis('equal') # 保证饼图为正圆形
plt.tight_layout()
plt.savefig('学历要求分布.png', dpi=300)
plt.show()
# 学历结论
print(f"需求最高的学历:{education_ratio.iloc[0]['education']}({education_ratio.iloc[0]['percentage']}%)")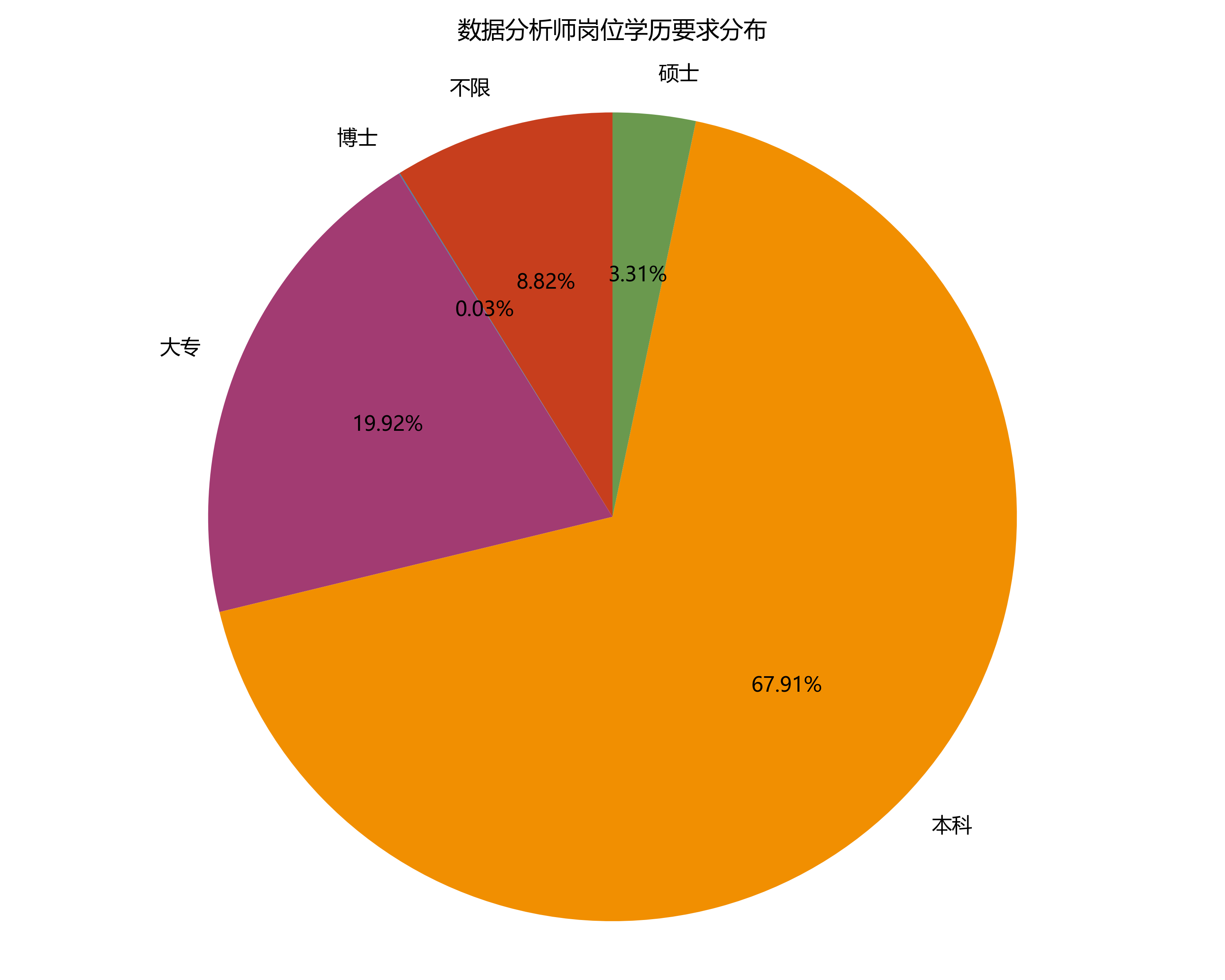

















 4567
4567

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









